

实际问题中如何使用机器学习模型
source link: https://breezedeus.github.io/2015/07/29/breezedeus-meituan-ml.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

美团技术博客里关于机器学习和推荐系统的不少博文写的都很好,这里我介绍其中的两篇12。这两篇博文的重点都是如何有效地利用机器学习模型来解决实际遇到的问题。下面我结合自己的理解,对这两篇文章的重要内容进行重组和加工。
看待问题的两种策略:整体求解 vs 分而治之
为了解决一个实际问题,我们通常有两种策略:
- 第一种是整体求解,即把这个问题看成一个不可分割的整体,直接进行求解。
- 第二种是分而治之,即分解这个问题,使之变成多个小问题,然后通过求解各个小问题来最后达到求解整个问题的目的。
这两种策略分别把原始问题转化为单个模型和多个模型进行求解1。 那么,什么问题使用什么策略呢?下面的表格给出了一些总结(在文章1的总结基础上有增删)。
| 策略 | 优点 | 缺点 | 何时使用 |
|---|---|---|---|
| 整体求解 | 1. 理论上可以获得最优预估(实际上很难) 2. 一次解决问题 |
1. 预估难度大 2. 风险比较高 |
1. 整个问题比较简单 2. 有足够多的数据用于支撑整个模型进行整体训练 |
| 分而治之 | 1. 单个子模型更容易实现比较准地预估 2. 可以调整子模型的融合方式,以达到最佳效果 |
1. 可能产生积累误差 2. 训练和应用成本高 |
1. 整个问题比较难 2. 没有足够多的数据用于支撑整个模型进行整体训练 3. 分解后多个模型之间的关系比较明确 |
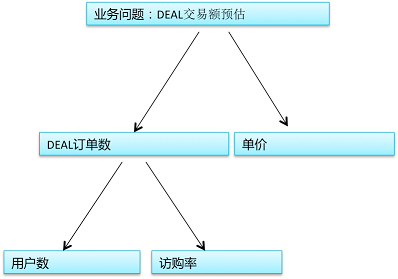
文章1给出的案例是美团对团购单(DEAL)的交易额预估问题(预估一个给定DEAL一段时间内能卖多少钱)。当然,解决这个问题可以使用上面介绍的两种策略:直接整体求解,预测交易额;或者把问题分解为下图所示的两个子问题:用户数预测和访购率预测(访问这个DEAL的用户最终会购买的比例)。
这里再举个佳缘用户推荐的案例。在佳缘做用户推荐时,我们的目标主要是异性用户收到信后的看信和回信量,而不只是用户的发信量。下面这个流程图(为男性推荐女性)说明了从展示到点击和发信,再到看信,以及回信的流程。具体说明可见我之前的总结3。
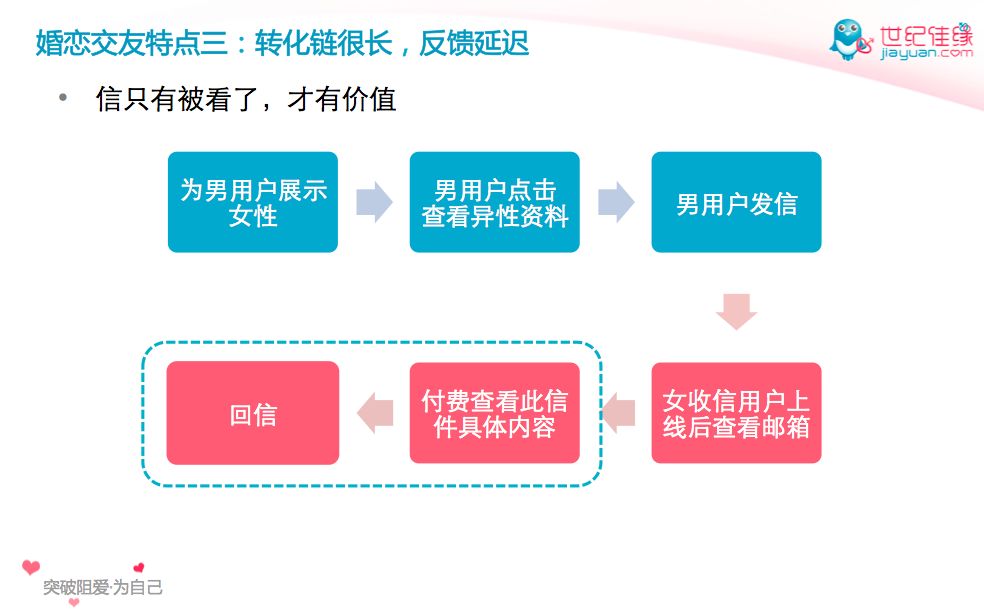
我们尝试了上面两种策略来最大化用户的回信量这个问题。首先我们尝试直接整体求解,但效果一直不佳。我们认为这其中主要有两个原因。第一个原因是这个问题本身很复杂:转化链很长,反馈延迟很严重。收到信的异性用户看没看信不只取决于她对发信人是否感兴趣,还取决于她有没有发现这封信(有些用户每天都能收到很多信),信是否要付费查看等。第二个原因是整体求解时,大部分用户的正样本(收到回信)太少,少到压根支撑不了使用个性化推荐模型。
所以,之后我们改为使用分而治之的策略。把到回信的问题切割为三个子问题:展示到发信、发信到看信、看信到回信,逐个使用模型进行优化。在展示到发信这步,我们有足够多的数据可以支撑较强的个性化模型。在后面两步,可用的用户行为数据较少,所以我们可以使用个性化不是那么强的模型进行优化。
融合多个子模型的结果
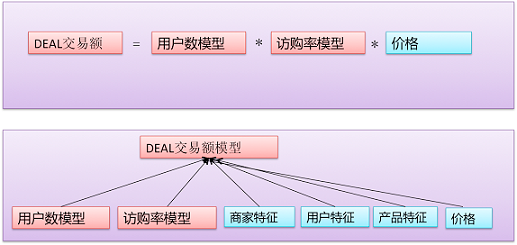
那么,在使用分而治之的策略时,获得的多个模型如何最终融合成我们整体问题的解呢?文章1中给出了两种常用方法:
- 依据业务上整体问题与子问题的关系进行加权求和(相乘可以理解为取对数后相加)或其他融合方式。
- 把各个子模型的预测结果作为特征,与其他特征一起输入到融合模型里进行模型训练获得融合方式。
下图给出了针对美团DEAL交易额预测问题的两种融合方法示意图1:
不同层级的特征
Deep Learning (DL)利用多层隐藏层来构建深度神经网络模型。训练完成后的DL模型的底层隐藏层可以用于抽取低层特征,而其高层隐藏层可以用于抽取高层特征。比如DL模型应用于人脸识别问题,抽取出的从低到高的各层特征分别代表了线条,独立的五官和整个人脸。
把特征按照层级进行划分的分类方法不仅限于DL,它其实早就存在于机器学习领域。
- 低层特征通常指的是那些比较原始的特征,每个底层特征的表达能力比较有限。
- 高层特征一般指通过对多个底层特征加工后而获得的表达能力更强的特征。
低层和高层特征是个相对概念,并没有什么严格的界限用来区分它们。低频样本的预测值主要受高层特征影响,高频样本的预测值主要受低层特征影响1。下面的表格给出了低层和高层特征在各个方面的一些比较(在文章1的总结基础上有增删)。
| 特点 | 低层特征 | 高层特征 |
|---|---|---|
| 覆盖面 | 小 | 大 |
| 数量 | 多 | 少 |
| 获取难度 | 易 | 难 |
| 可解释性 | 好 | 差 |
| 表达能力 | 差 | 好 |
| 泛化能力 | 差 | 好 |
| 适用模型 | 线性模型 | 非线性模型 |
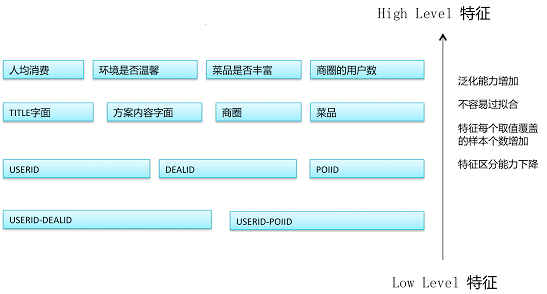
下面的图中给出了美团DEAL访购率预测(访问这个DEAL的用户最终会购买的比例)问题中不同层级对应的特征1,供大家参考。
模型的选取方式
好了,在已经确定使用何种策略(整体求解还是分而治之?)对问题进行求解后,接下来就是选用什么样的机器学习模型来具体求解对应的问题了。
模型的优化目标
首先,我们要从实际问题的具体业务背景出发,明确我们的业务目标。我们是要提升点击率,还是要提升购买率,或者延长用户的使用时长?然后,我们需要转化问题的业务目标为模型评价目标,进而再把模型评价目标转化为模型优化目标。下面是文章1中总结的“业务目标->模型评价目标->模型优化目标”的关系图:
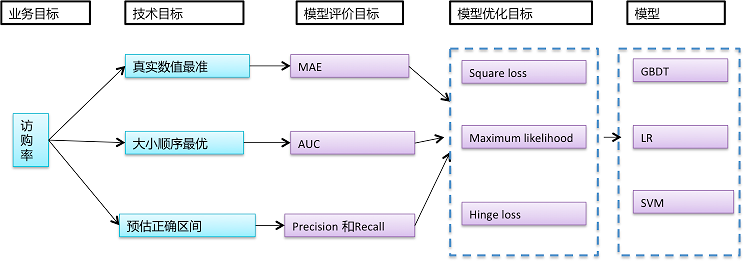
业务目标 –> 模型评价目标 –> 模型优化目标
线性模型 vs 非线性模型
好了,在选定模型的优化目标后,接下来就是决定具体选用优化此目标的什么机器学习模型了。模型按照是否线性可以分为线性模型和非线性模型。下面的表格给出了线性和非线性模型的一些特点(在文章1的基础上有增删)。
| 特点 | 线性模型 | 非线性模型 |
|---|---|---|
| 训练难易 | 易 | 难 |
| 训练速度 | 快 | 慢 |
| 训练支撑的数据规模 | 大/超大 | 小/中 |
| 可解释性 | 好 | 差 |
| 对特征的处理要求 | 高 | 低 |
| 偏好何种特征 | 低层特征 | 高层特征 |
实际问题通常不会在原始特征的空间里就线性可分。为了让线性模型能够表达非线性性,我们需要对原始特征进行加工,具体方法可参见我之前的文章4。
值得一提的是,
对于不同的模型,我们要考虑不同的特征。
在使用线性模型时,我们通常会把大部分连续特征进行离散化,以便线性模型能够表达非线性性。但这种离散化的处理方式并不一定适合非线性模型。所以,在线性模型里很有用的特征,未必在非线性模型里仍旧很有用。
以下是文章1中总结的经验,供大家参考:
- 如果训练数据少,高层特征多,则使用“复杂”的非线性模型(流行的GBDT、Random Forest等);
- 如果训练数据多,低层特征多,则使用“简单”的线性模型(流行的LR、Linear-SVM等)。
最后,总结下在实际问题中使用机器学习模型进行求解的步骤:
- 从具体问题出发,确定解决问题的大策略:是作为整体进行求解呢,还是分而治之;
- 依据“业务目标->模型评价目标->模型优化目标”的顺序,从业务目标出发推导出模型优化目标;
- 依据上面确定的模型优化目标,以及具有的数据和特征特点,选定合适的模型求解问题。
References
Recommend
-
100
404 | 百度EUX 页面搬家啦,点击此处跳转
-
135
Quora 已经变成了一个获取重要资源的有效途径。许多的顶尖研究人员都会积极的在现场回答问题。 以下是一些在 Quora 上有关 AI 的主题。如果你已经在 Quora 上面注册了账号,你可以订阅这些主题。 Computer-Science (5.6M followers) Machine-Learning (1.1M follow...
-
57
凤凰网科技-直击真相的科技媒体_凤凰网
-
32
程序员 - @szzhiyang - 不知是谁带起的风气,很多涉及软件配置技巧的博文似乎都喜欢在标题中使用这个词,但我总觉得应该用「调校」「优化」等更妥当和正式的词替代它,你们的看法是?
-
15
一、问题发现 对于XXE问题,大家都不陌生。对于XXE的防御(修复),很多安全从业者也都知道,最安全的手段就是禁用DTD实体。文献【1】给出了各种语言下各类XML库的安全编码方式。在甲方环境下,笔者也曾参考此...
-
6
在这篇文章中,我将逐步讲解如何使用 TensorFlow 创建一个简单的机器...
-
5
在这篇文章中,我将逐步讲解如何使用 TensorFlow 创建一个简单的机器学习...
-
2
V2EX › 分享发现 从技术难题中学习 bmpidev2019...
-
6
之前写过一篇如何学习一门技术的文章,介绍了我在学习新技术的一些经验。不过这种按计划的学习方式效率可能并不高,真正高效的学习方式是在解决问题中实践所学的知识。作为工程技术人员...
-
3
如何将深度学习模型部署到实际工程中?(分类+检测+分割) 工...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK