

【置顶】导引——nlp论文集合
source link: https://daiwk.github.io/posts/links-navigation-nlp.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
参考清华机器翻译组整理的https://github.com/THUNLP-MT/MT-Reading-List
10篇必读
A Tensorized Transformer for Language Modeling
多头注意力机制限制了模型的发展,使得模型需要较大的算力支持。为了解决这一问题,基于张量分解和参数共享的思想,本文提出了多头线性注意力(Multi-linear attention)和Block-Term Tensor Decomposition(BTD)。研究人员在语言建模任务及神经翻译任务上进行了测试,与许多语言建模方法相比,多头线性注意力机制不仅可以大大压缩模型参数数量,而且提升了模型的性能。
分解那块参考的Tensor decompositions and applications和Decompositions of a higher-order tensor in block terms—part ii: Definitions and uniqueness,后者好像没有pdf可以下载。。
nnlm综述
阅读理解综述
ACL2019预训练语言模型
nlp综述
A Survey of the Usages of Deep Learning in Natural Language Processing
过去数年,深度学习模型的爆炸式使用推动了自然语言处理领域的发展。在本文中,研究者简要介绍了自然语言处理领域的基本情况,并概述了深度学习架构和方法。然后,他们对近来的研究进行了筛选,对大量相关的文献展开总结。除了诸多计算机语言学的应用之外,研究者还分析研究了语言处理方面的几个核心问题。最后他们讨论了当前 SOTA 技术和方法并对该领域未来的研究提出了建议。
nlp路线图
https://github.com/graykode/nlp-roadmap
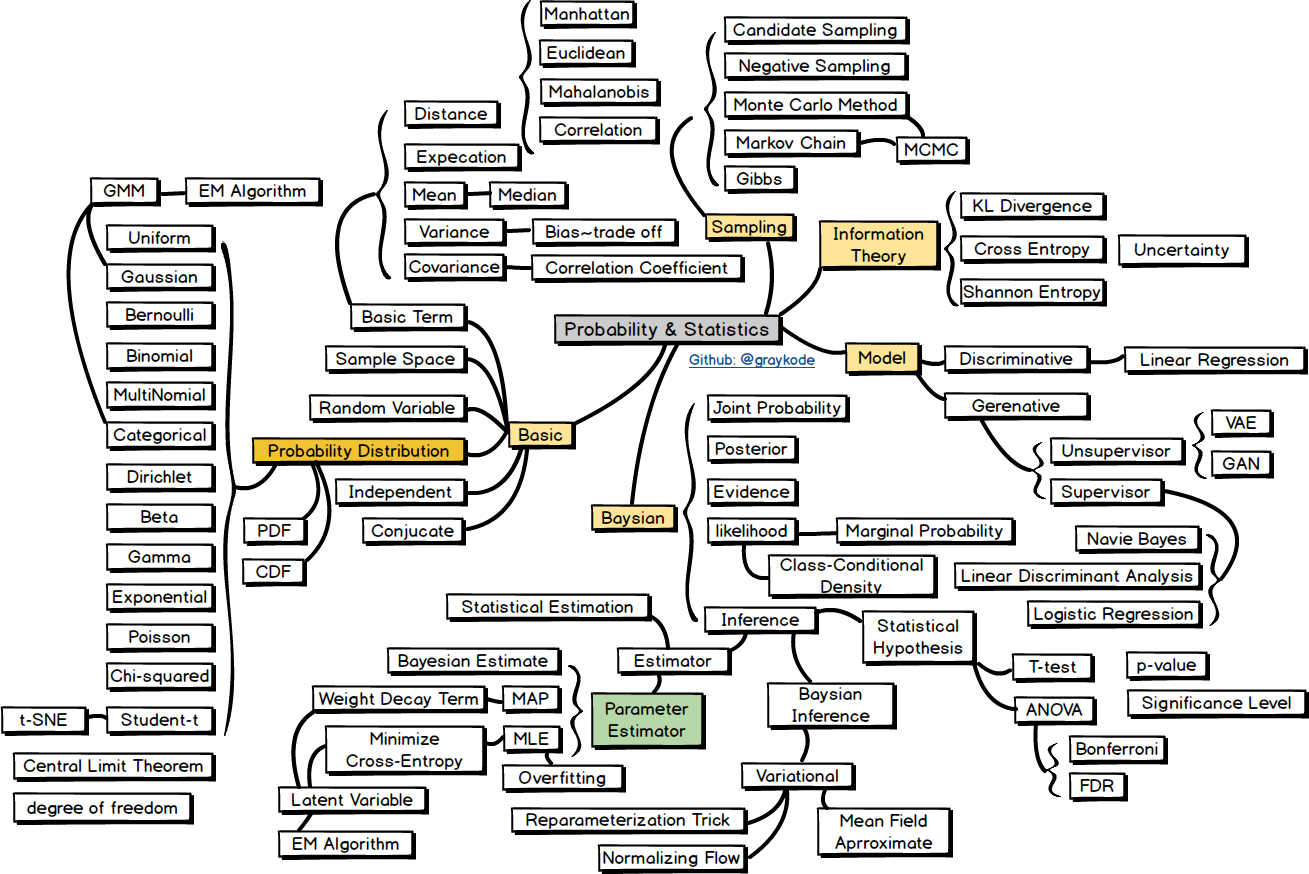
Probability & Statistics
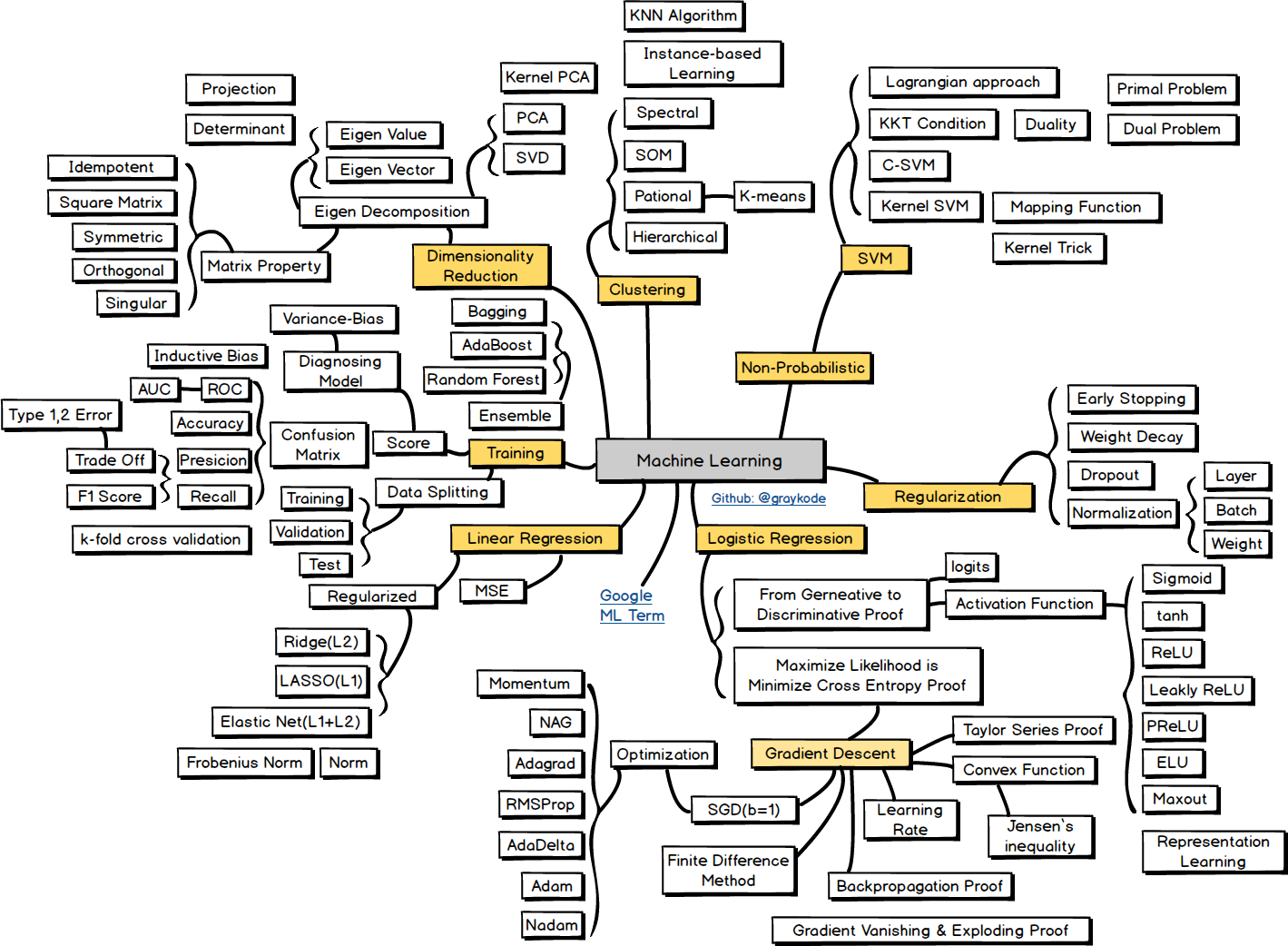
Machine Learning
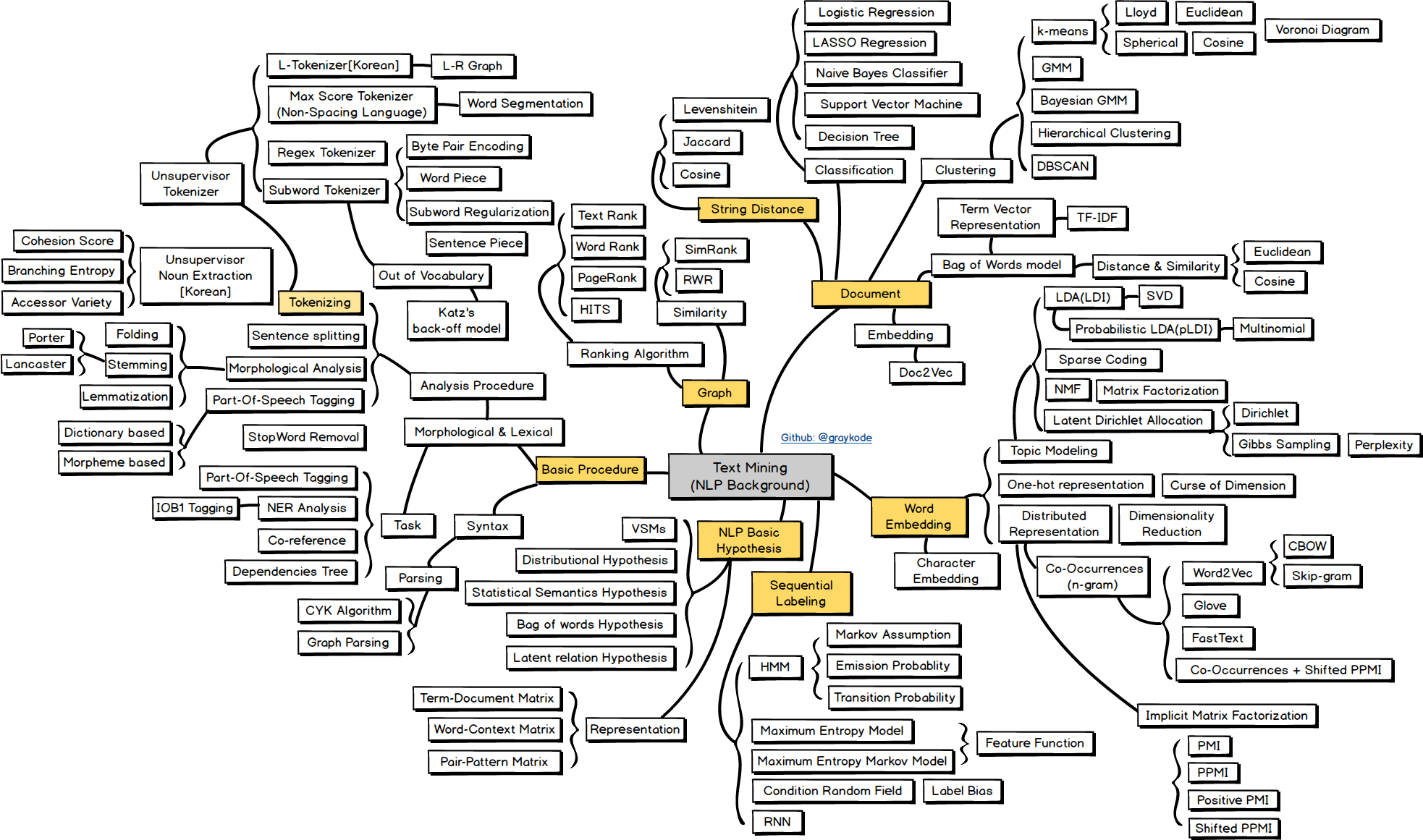
Text Mining
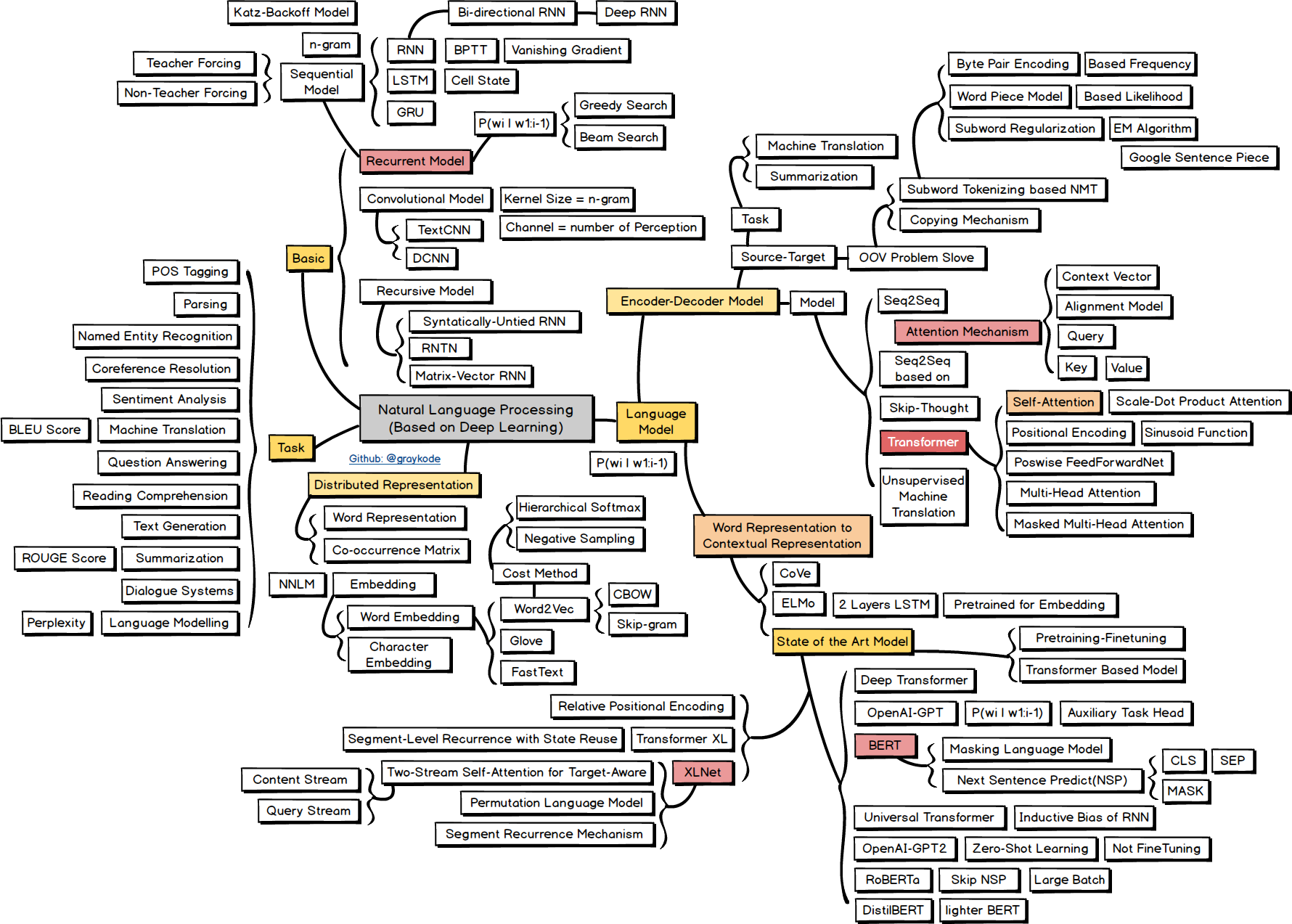
Natural Language Processing
teacher forcing
参考https://zhuanlan.zhihu.com/p/93030328
Teacher Forcing 是一种用于序列生成任务的训练技巧,与Autoregressive模式相对应,这里阐述下两者的区别:
Autoregressive 模式下,在tt时刻decoder模块的输入是t−1t−1时刻的输出yt−1yt−1。这时候我们称 yt−1yt−1 为当前预测步的context;
Teacher-Forcing 模式下,在tt时刻decoder模块的输入是Ground-truth语句中位置的y∗t−1yt−1∗单词。这时候我们称 y∗t−1yt−1∗为当前预测步的context;
Teacher-Forcing 技术之所以作为一种有用的训练技巧,主要是因为:
- Teacher-Forcing能够在训练的时候矫正模型的预测,避免在序列生成的过程中误差进一步放大。
- Teacher-Forcing能够极大的加快模型的收敛速度,令模型训练过程更加快&平稳。
- Teacher-Forcing技术是保证Transformer模型能够在训练过程中完全并行计算所有token的关键技术。
Teacher Forcing的问题(后面两个是acl2019最佳论文提出的):
- 最常见的问题就是Exposure Bias了。由于训练和预测的时候decode行为的不一致, 导致预测单词(predict words)在训练和预测的时候是从不同的分布中推断出来的。而这种不一致导致训练模型和预测模型直接的Gap,就叫做Exposure Bias。
- Teacher-Forcing技术在解码的时候生成的字符都受到了 Ground-Truth 的约束,希望模型生成的结果都必须和参考句一一对应。这种约束在训练过程中减少模型发散,加快收敛速度。但是一方面也扼杀了翻译多样性的可能。
- Teacher-Forcing技术在这种约束下,还会导致一种叫做Overcorrect(矫枉过正)的问题,导致生成的语句不通顺。
参考ACL2019最佳论文冯洋:Teacher Forcing亟待解决 ,通用预训练模型并非万能
Bridging the Gap between Training and Inference for Neural Machine Translation
提出了使用 Oracle 词语,用于替代 Ground Truth 中的词语,作为训练阶段约束模型的数据。
选择 Oracle Word 的方法有两种,一种是选择 word-level oracle,另一种则是 sentence-level oracle。
word-level oracle 的选择方法,在时间步为 j 时,获取前一个时间步模型预测出的每个词语的预测分数。为了提高模型的鲁棒性,论文在预测分数基础上加上了 Gumbel noise,最终取分数最高的词语作为此时的 Oracle Word。
sentence-level oracle 的选择方法则是在训练时,在解码句子的阶段,使用集束搜索的方法,选择集束宽为 k 的句子(即 top k 个备选句子),然后计算每个句子的 BLEU 分数,最终选择分数最高的句子。
当然,这会带来一个问题,即每个时间步都需要获得该时间步长度上的备选句子,因此集束搜索获得的句子长度必须和时间步保持一致。如果集束搜索生成的实际句子超出或短于这一长度该怎么办?这里研究人员使用了「Force Decoding」的方法进行干预。而最终选择的 Oracle Word 也会和 Ground Truth 中的词语混合,然后使用衰减式采样(Decay Sampling)的方法从中挑选出作为约束模型训练的词。
机器之心:我们知道,这篇论文的基本思想是:不仅使用 Ground Truth 进行约束,在训练过程中,也利用训练模型预测出的上一个词语作为其中的备选词语,这样的灵感是从哪里得到的呢?
冯洋:我们很早就发现了这样一个问题——训练和测试的时候模型的输入是不一样的。我们希望模型在训练过程中也能够用到预测出的词语。看到最近一些周边的工作,我们慢慢想到,将 Ground Truth 和模型自己预测出的词一起以 Sampling 的方式输入进模型。
机器之心:刚才您提到有一些周边的工作,能否请您谈谈有哪些相关的论文?
冯洋:这些周边的论文在 Related Work 中有写到,这些工作的基本思想都是一样的,都是希望将预测出的词语作为模型输入。比如说,根据 DAD(Data as Demonstrator)的方法。这一方法将预测出的词语和后一个词语组成的词语对(word-pair)以 bigram 的方式输入作为训练实例加入。另一种是 Scheduled Sampling 的方式,也是用 Sampling 的方式,把预测出的词语作为输入加入到模型训练中。
机器之心:论文使用了两种方法实现将预测词语作为训练的输入,一种是在 Word-level 选择 Oracle Word,另一种是在 Sentence-level 选择 Oracle Sentence,能否请您详细介绍下 Sentence-level 的方法?
冯洋:Sentence-level 的方法可以简单理解为进行了一次解码。我们从句子中取出前 k 个候选译文。这里的 k 我们选择了 3,即 Top3 的句子。然后在这些句子中再计算他们的 BLEU 分数,并选择分数最高的句子,作为 Oracle Sentence。
机器之心:我们知道,论文中,在选择 Oracle Sentence 的过程中会进行「Force Decoding」。需要强制保证生成的句子和原有的句子保持一致的长度。您认为这样的方法会带来什么样的问题?
冯洋:这是强制模型生成和 Ground Truth 长度一样的句子。这样模型可能会生成一些原本并不是模型想生成的结果,这可能会带来一些问题。但是对于 Teacher Forcing 来说这是必须的,因为 Teacher Forcing 本身要求每一个词都要对应。所以说,虽然看起来我们干预了句子的生成,但是在 Teacher Forcing 的场景下,这种干预不一定是坏的。
机器之心:为什么说这样的干预不一定是坏的?
冯洋:我们需要留意的是,Force Decoding 的方法是在训练阶段进行的,如果训练中这样做了,模型就会逐渐地适应这个过程。另一方面,Force Decoding 可以平衡一些极端的生成结果。比如说,当句子长度为 10,但模型只生成了仅有 2 个词的句子,或者是模型生成了有 20 个词的句子,所以说 Force Decoding 也可以平衡这样的极端情况。在 Teacher Forcing 的场景下,这是一种折中的方法,不能完全说这样的方法是不好的。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK