

ES 和 Clickhouse 查询能力对比,实践结果根本料不到……
source link: https://dbaplus.cn/news-160-4437-1.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

ES 和 Clickhouse 查询能力对比,实践结果根本料不到……
Elasticsearch 是一个实时的分布式搜索分析引擎,它的底层是构建在Lucene之上的。简单来说是通过扩展Lucene的搜索能力,使其具有分布式的功能。ES通常会和其它两个开源组件logstash(日志采集)和Kibana(仪表盘)一起提供端到端的日志/搜索分析的功能,常常被简称为ELK。
Clickhouse是俄罗斯搜索巨头Yandex开发的面向列式存储的关系型数据库。ClickHouse是过去两年中OLAP领域中最热门的,并于2016年开源。
ES是最为流行的大数据日志和搜索解决方案,但是近几年来,它的江湖地位受到了一些挑战,许多公司已经开始把自己的日志解决方案从ES迁移到了Clickhouse,这里就包括:携程,快手等公司。
一、架构和设计的对比
ES的底层是Lucenc,主要是要解决搜索的问题。搜索是大数据领域要解决的一个常见的问题,就是在海量的数据量要如何按照条件找到需要的数据。搜索的核心技术是倒排索引和布隆过滤器。ES通过分布式技术,利用分片与副本机制,直接解决了集群下搜索性能与高可用的问题。

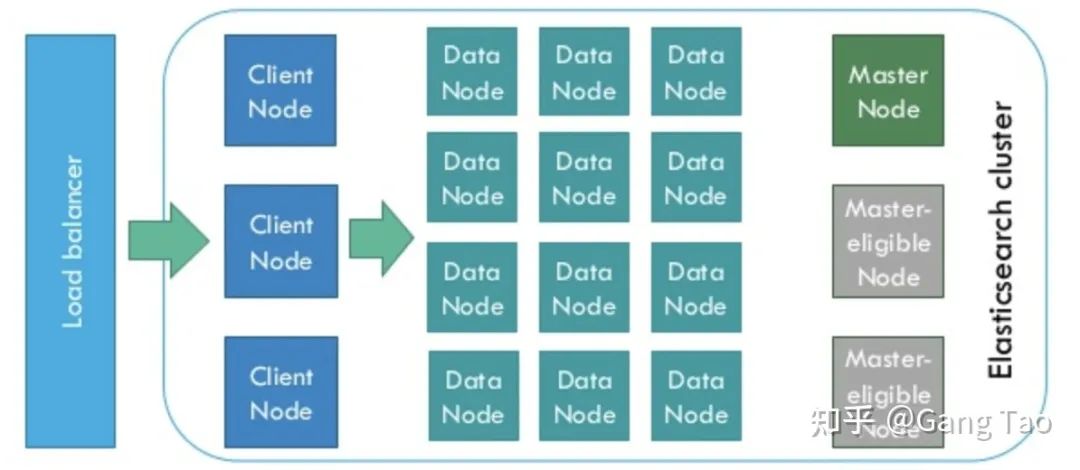
ElasticSearch是为分布式设计的,有很好的扩展性,在一个典型的分布式配置中,每一个节点(node)可以配制成不同的角色,如下图所示:
-
Client Node,负责API和数据的访问的节点,不存储/处理数据。
-
Data Node,负责数据的存储和索引。
-
Master Node,管理节点,负责Cluster中的节点的协调,不存储数据。
ClickHouse是基于MPP架构的分布式ROLAP(关系OLAP)分析引擎。每个节点都有同等的责任,并负责部分数据处理(不共享任何内容)。ClickHouse 是一个真正的列式数据库管理系统(DBMS)。在 ClickHouse 中,数据始终是按列存储的,包括矢量(向量或列块)执行的过程。让查询变得更快,最简单且有效的方法是减少数据扫描范围和数据传输时的大小,而列式存储和数据压缩就可以帮助实现上述两点。Clickhouse同时使用了日志合并树,稀疏索引和CPU功能(如SIMD单指令多数据)充分发挥了硬件优势,可实现高效的计算。Clickhouse 使用Zookeeper进行分布式节点之间的协调。
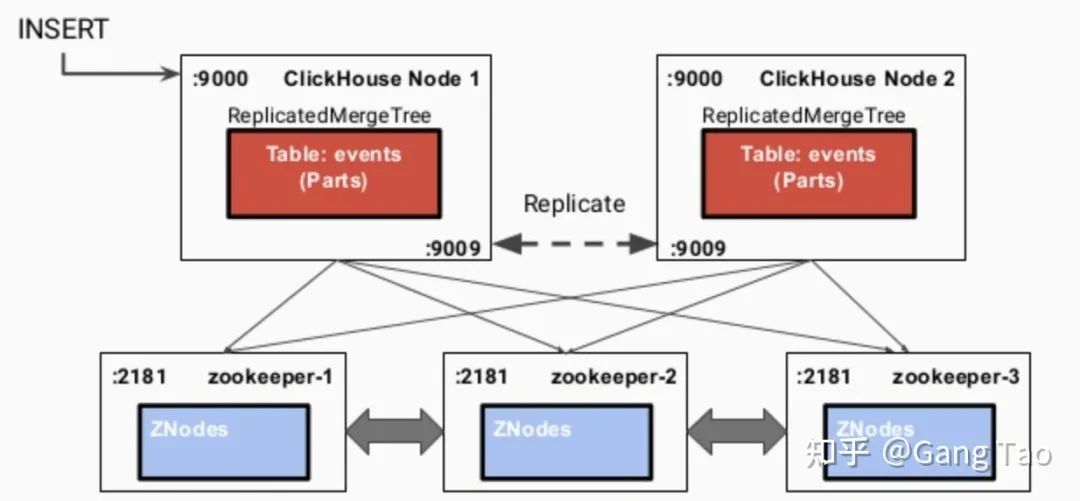
为了支持搜索,Clickhouse同样支持布隆过滤器。
二、查询对比实战
为了对比ES和Clickhouse的基本查询能力的差异,我写了一些代码来验证。
这个测试的架构如下:

架构主要包括四个部分。
1、ES stack
ES stack有一个单节点的Elastic的容器和一个Kibana容器组成,Elastic是被测目标之一,Kibana作为验证和辅助工具。部署代码如下:
version: '3.7'services:elasticsearch:image: docker.elastic.co/elasticsearch/elasticsearch:7.4.0container_name: elasticsearchenvironment:- xpack.security.enabled=false- discovery.type=single-nodeulimits:memlock:soft: -1hard: -1nofile:soft: 65536hard: 65536cap_add:- IPC_LOCKvolumes:- elasticsearch-data:/usr/share/elasticsearch/dataports:- 9200:9200- 9300:9300deploy:resources:limits:cpus: '4'memory: 4096Mreservations:memory: 4096Mkibana:container_name: kibanaimage: docker.elastic.co/kibana/kibana:7.4.0environment:- ELASTICSEARCH_HOSTS=http://elasticsearch:9200ports:- 5601:5601depends_on:- elasticsearchvolumes:elasticsearch-data:driver: local
2、Clickhouse stack
Clickhouse stack有一个单节点的Clickhouse服务容器和一个TabixUI作为Clickhouse的客户端。部署代码如下:
version: "3.7"services:clickhouse:container_name: clickhouseimage: yandex/clickhouse-servervolumes:- ./data/config:/var/lib/clickhouseports:- "8123:8123"- "9000:9000"- "9009:9009"- "9004:9004"ulimits:nproc: 65535nofile:soft: 262144hard: 262144healthcheck:test: ["CMD", "wget", "--spider", "-q", "localhost:8123/ping"]interval: 30stimeout: 5sretries: 3deploy:resources:limits:cpus: '4'memory: 4096Mreservations:memory: 4096Mtabixui:container_name: tabixuiimage: spoonest/clickhouse-tabix-web-clientenvironment:- CH_NAME=dev- CH_HOST=127.0.0.1:8123- CH_LOGIN=defaultports:- "18080:80"depends_on:- clickhousedeploy:resources:limits:cpus: '0.1'memory: 128Mreservations:memory: 128M
3、数据导入 stack
数据导入部分使用了Vector.dev开发的vector,该工具和fluentd类似,都可以实现数据管道式的灵活的数据导入。
4、测试控制 stack
测试控制我使用了Jupyter,使用了ES和Clickhouse的Python SDK来进行查询的测试。
用Docker compose启动ES和Clickhouse的stack后,我们需要导入数据,我们利用Vector的generator功能,生成syslog,并同时导入ES和Clickhouse,在这之前,我们需要在Clickhouse上创建表。ES的索引没有固定模式,所以不需要事先创建索引。
创建表的代码如下:
CREATE TABLE default.syslog(application String,hostname String,message String,mid String,pid String,priority Int16,raw String,timestamp DateTime('UTC'),version Int16) ENGINE = MergeTree()PARTITION BY toYYYYMMDD(timestamp)ORDER BY timestampTTL timestamp + toIntervalMonth(1);
创建好表之后,我们就可以启动vector,向两个stack写入数据了。vector的数据流水线的定义如下:
[sources.in]type = "generator"format = "syslog"interval = 0.01count = 100000[transforms.clone_message]type = "add_fields"inputs = ["in"]fields.raw = "{{ message }}"[transforms.parser]# Generaltype = "regex_parser"inputs = ["clone_message"]field = "message" # optional, defaultpatterns = ['^<(?P<priority>\d*)>(?P<version>\d) (?P<timestamp>\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}\.\d{3}Z) (?P<hostname>\w+\.\w+) (?P<application>\w+) (?P<pid>\d+) (?P<mid>ID\d+) - (?P<message>.*)$'][transforms.coercer]type = "coercer"inputs = ["parser"]types.timestamp = "timestamp"types.version = "int"types.priority = "int"[sinks.out_console]# Generaltype = "console"inputs = ["coercer"]target = "stdout"# Encodingencoding.codec = "json"[sinks.out_clickhouse]host = "http://host.docker.internal:8123"inputs = ["coercer"]table = "syslog"type = "clickhouse"encoding.only_fields = ["application", "hostname", "message", "mid", "pid", "priority", "raw", "timestamp", "version"]encoding.timestamp_format = "unix"[sinks.out_es]# Generaltype = "elasticsearch"inputs = ["coercer"]compression = "none"endpoint = "http://host.docker.internal:9200"index = "syslog-%F"# Encoding# Healthcheckhealthcheck.enabled = true
这里简单介绍一下这个流水线:
-
http://source.in 生成syslog的模拟数据,生成10w条,生成间隔和0.01秒。
-
transforms.clone_message 把原始消息复制一份,这样抽取的信息同时可以保留原始消息。
-
transforms.parser 使用正则表达式,按照syslog的定义,抽取出application,hostname,message ,mid ,pid ,priority ,timestamp ,version 这几个字段。
-
transforms.coercer 数据类型转化。
-
sinks.out_console 把生成的数据打印到控制台,供开发调试。
-
sinks.out_clickhouse 把生成的数据发送到Clickhouse。
-
sinks.out_es 把生成的数据发送到ES。
运行Docker命令,执行该流水线:
docker run \-v $(mkfile_path)/vector.toml:/etc/vector/vector.toml:ro \-p 18383:8383 \timberio/vector:nightly-alpine
数据导入后,我们针对一下的查询来做一个对比。ES使用自己的查询语言来进行查询,Clickhouse支持SQL,我简单测试了一些常见的查询,并对它们的功能和性能做一些比较。
-
返回所有的记录
# ES{"query":{"match_all":{}}}# Clickhouse"SELECT * FROM syslog"
-
匹配单个字段
# ES{"query":{"match":{"hostname":"for.org"}}}# Clickhouse"SELECT * FROM syslog WHERE hostname='for.org'"
-
匹配多个字段
# ES{"query":{"multi_match":{"query":"up.com ahmadajmi","fields":["hostname","application"]}}}# Clickhouse、"SELECT * FROM syslog WHERE hostname='for.org' OR application='ahmadajmi'"
-
单词查找,查找包含特定单词的字段
# ES{"query":{"term":{"message":"pretty"}}}# Clickhouse"SELECT * FROM syslog WHERE lowerUTF8(raw) LIKE '%pretty%'"
-
范围查询, 查找版本大于2的记录
# ES{"query":{"range":{"version":{"gte":2}}}}# Clickhouse"SELECT * FROM syslog WHERE version >= 2"
-
查找到存在某字段的记录
ES是文档类型的数据库,每一个文档的模式不固定,所以会存在某字段不存在的情况;而Clickhouse对应为字段为空值
# ES{"query":{"exists":{"field":"application"}}}# Clickhouse"SELECT * FROM syslog WHERE application is not NULL"
-
正则表达式查询,查询匹配某个正则表达式的数据
# ES{"query":{"regexp":{"hostname":{"value":"up.*","flags":"ALL","max_determinized_states":10000,"rewrite":"constant_score"}}}}# Clickhouse"SELECT * FROM syslog WHERE match(hostname, 'up.*')"
-
聚合计数,统计某个字段出现的次数
# ES{"aggs":{"version_count":{"value_count":{"field":"version"}}}}# Clickhouse"SELECT count(version) FROM syslog"
-
聚合不重复的值,查找所有不重复的字段的个数
# ES{"aggs":{"my-agg-name":{"cardinality":{"field":"priority"}}}}# Clickhouse"SELECT count(distinct(priority)) FROM syslog "
我用Python的SDK,对上述的查询在两个Stack上各跑10次,然后统计查询的性能结果。
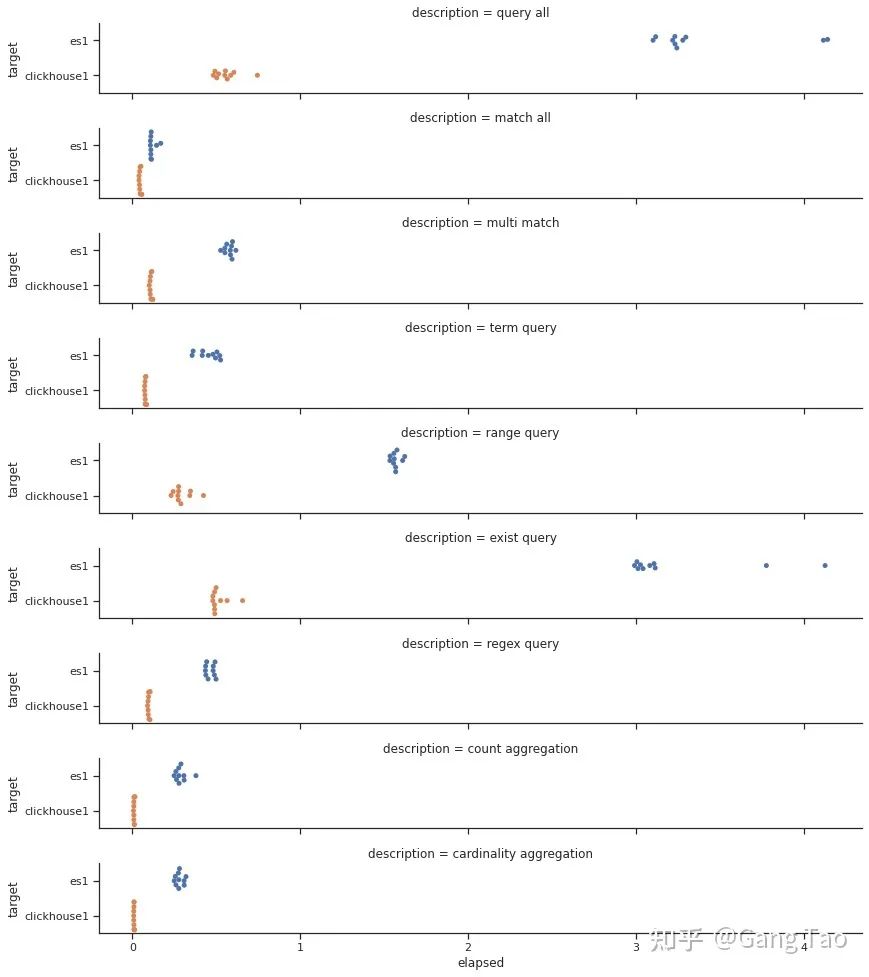
我们画出出所有的查询的响应时间的分布:
总查询时间的对比如下:
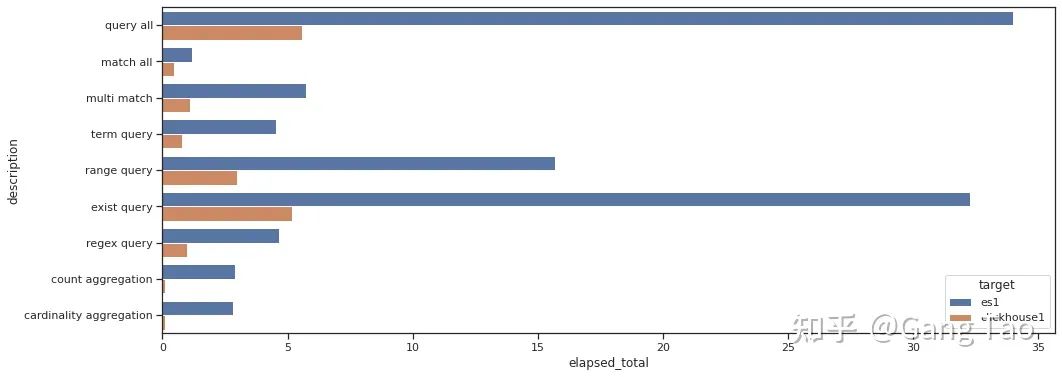
通过测试数据我们可以看出Clickhouse在大部分的查询的性能上都明显要优于Elastic。在正则查询(Regex query)和单词查询(Term query)等搜索常见的场景下,也并不逊色。
在聚合场景下,Clickhouse表现异常优秀,充分发挥了列村引擎的优势。
我的测试并没有任何优化,对于Clickhouse也没有打开布隆过滤器。可见Clickhouse确实是一款非常优秀的数据库,可以用于某些搜索的场景。当然ES还支持非常丰富的查询功能,这里只有一些非常基本的查询,有些查询可能存在无法用SQL表达的情况。
三、总结
本文通过对于一些基本查询的测试,对比了Clickhouse 和Elasticsearch的功能和性能,测试结果表明,Clickhouse在这些基本场景表现非常优秀,性能优于ES,这也解释了为什么有很多的公司应从ES切换到Clickhouse之上。
作者丨Gang Tao
来源丨网址:https://zhuanlan.zhihu.com/p/353296392
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:[email protected]
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK