

缓存淘汰策略-LRU
source link: https://weedge.github.io/post/lru/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

缓存淘汰策略-LRU
在计算机硬件中缓/内存设计是用来机器启动的时候加载程序,分配运行空间数据,停机,缓/内存中的数据会丢失;磁盘用来持久化存储,提供数据加载到内存中,内存的读写速度比磁盘快很多,以下是Jeff Dean “Numbers Everyone Should Know” 中提供的数据(虽然过去10多年了), 读取1MB数据,从内存中读比从磁盘中读取快100+倍;但是缓/内存的空间比磁盘空间少,为了加快数据的访问,减少缓存/磁盘io,大概分为三种:1. 可以提前将数据从磁盘加载到内/缓存中(page)、2. 内/缓存miss从下层存储获取数据(cache,pool,page)、3. 无需加载,直接内/缓存evict;如果提供给进程的最大内/缓存资源到了最大限制,需要对存储资源进行evict操作,常用的evict策略可以从Cache_replacement_policies中了解;有关特定于分页的详细算法,请参阅页面替换算法;有关特定于 CPU 和 RAM 之间缓存的详细算法,请参阅CPU 缓存。这里主要关注LRU evict相关策略。
| OP(io) | cost(1s= 10^9ns) |
|---|---|
| L1 cache reference 读取CPU的一级缓存 | 0.5 ns |
| Branch mispredict(转移、分支预测) | 5 ns |
| L2 cache reference 读取CPU的二级缓存 | 7 ns |
| Mutex lock/unlock 互斥锁\解锁 | 100 ns |
| Main memory reference 读取内存数据 | 100 ns |
| Compress 1K bytes with Zippy 1k字节压缩 | 10,000 ns |
| Send 2K bytes over 1 Gbps network 在1Gbps的网络上发送2k字节 | 20,000 ns |
| Read 1 MB sequentially from memory 从内存顺序读取1MB | 250,000 ns |
| Round trip within same datacenter 从一个数据中心往返一次,ping一下 | 500,000 ns |
| Disk seek 磁盘搜索 | 10,000,000 ns |
| Read 1 MB sequentially from network 从网络上顺序读取1兆的数据 | 10,000,000 ns |
| Read 1 MB sequentially from disk 从磁盘里面读出1MB | 30,000,000 ns |
| Send packet CA->Netherlands->CA 一个包的一次远程访问 | 150,000,000 ns |
LRU算法
LRU(least recently used)是一种缓存 evict 策略算法:在缓存有限的情况下,如果有新的数据需要加载进缓存,则需要将最不可能被继续访问的缓存剔除掉。这是一种提前预判假设的算法,因为缓存是否可能被访问到没法做预测的,所以假设 一个key经常被访问,那么该key的idle time应该是最小的。 (但这个假设也是基于概率,并不是充要条件,很明显,idle time最小的,甚至都不一定会被再次访问到)。
LRU 的工作原理是一种时间局部性原理的假设,在过去的几条指令中使用最多的页面最有可能在接下来的几条指令中也被大量使用。
实现方式可以采用wiki中的实现,每个缓存item中有序列号(每个新访问的增量为 1),缓存满了将序列号最低的替换掉,这种实现需要找到最低的进行比较替换;还有种实现实现方式是通过hashMap+双向链表的方式实现,空间换时间的方式,leetcode上有这道题,一般面试会问到;
实际工程实现中,由于实现成本,根据使用场景,考虑空间利用和时间的折中,使用的LRU算法变体:(以下定义来自wiki)
LRU-K 驱逐过去第 K 次最近访问最远的页面。例如,LRU-1 只是 LRU,而 LRU-2 根据倒数第二次访问的时间驱逐页面。LRU-K 在时间上的局部性方面大大改进了 LRU。
ARC 算法通过保持最近驱逐页面的历史可LRU,并使用此选项可以更改的偏好近期或频繁访问。它对顺序扫描特别有抵抗力。
2Q 算法改进了 LRU 和 LRU/2 算法。通过具有两个队列,一个用于热路径项目,另一个用于慢路径项目,项目首先被放置在慢路径队列中,并且在第二次访问放置在热路径项目中的项目之后;由于对添加项的引用比 LRU 和 LRU/2 算法中的保留时间更长,因此它具有更好的热路径队列,从而提高了缓存的命中率。
SLRU 缓存分为两个段,试用段和保护段。每个段中的行按从最近访问到最近最少访问的顺序排列。来自未命中的数据被添加到试用段最近访问的末端的缓存中。命中从它们当前所在的任何地方删除,并添加到受保护段的最近访问端。因此,受保护段中的行至少被访问了两次。
本地缓存中的实现机制
go语言实现的本地缓存策略中有开源方案
https://github.com/golang/groupcache (LRU)
http://github.com/dgryski/go-s4lru (S4LRU)
https://github.com/dgryski/go-arc (ARC)
https://github.com/hashicorp/golang-lru (LRU, ARC, TwoQueue)
https://github.com/vmihailenco/go-cache-benchmark 对不同的cache 淘汰策略的对比,引用结果:
TinyLFU最适合少量的key(少于100k)。TinyLFU内存开销可以通过第二个参数进行调整。 Clock-pro有明显较小的内存使用大量的key(当key的数量超过 1m)。 分段LRU的内存使用量更小,但命中率不一致。 如果你需要它提供的额外功能,Ristretto仍然是一个不错的选择。
存储组件中的实现机制
redis Dict(sds,redisObject) LRU evict策略
redis 是缓存数据库,缓存空间是有限的,可以指定最大内存使用空间;redis提供过期机制,给key制定过期时间,redis实现了删除这些过期key的删除策略(定期删除+惰性删除),但是还是存在问题,对于一些key没有设置过期时间,总会到最大内存使用空间,需要实现内存淘汰回收策略,其中策略就是LRU, 操作对象分为全部key (allkeys-lru) 和 过期key(volatile-lru);这里整体介绍下redis缓存策略,然后单独介绍对应的redis LRU evict策略:
最大内存配置选项
maxmemory 配置选项使用来配置 Redis 的存储数据所能使用的最大内存限制。可以通过在内置文件redis.conf中配置,也可在Redis运行时通过命令CONFIG SET来配置。例如,我们要配置内存上限是100M的Redis缓存,那么我们可以在 redis.conf 配置如下:maxmemory 100mb
设置 maxmemory 为 0 表示没有内存限制。在 64-bit 系统中,默认是 0 无限制,但是在 32-bit 系统中默认是 3GB。当存储数据达到限制时,Redis 会根据情形选择不同策略,或者返回errors(这样会导致浪费更多的内存),或者清除一些旧数据回收内存来添加新数据。
惰性释放的策略
应用这种策略的原因在于对于某些数据对象的释放需要消耗过多的系统资源,如果在Redis的主线程中采用同步的方式去删除以及释放这样的key-value数据,那么会导致系统长时间的阻塞在释放数据操作上,而无法处理其他的业务逻辑。对于这种情况,我们以惰性释放的策略,使用一个后台线程,通过异步的方式来对数据对象进行释放,无疑是一种较为合适的选择,可配置三种情况:
- redisServer.lazyfree_lazy_eviction: 是否在淘汰某个key时,使用惰性释放策略;这个在内存淘汰策略异步释放会用到;
- redisServer.lazyfree_lazy_expire:是否在过期某个key时,使用惰性释放策略;
- redisServer.lazyfree_lazy_server_del: 服务器端删除某个key时,是否使用惰性释放策略;
过期删除缓存策略
分为定期删除,惰性删除, 两种策略配合使用:
定期删除 指的是Redis默认会每隔一定时间(默认100ms)就会抽取一批设置了过期时间的key来检测是否过期,过期就删除。
在Redis2.6版本中,规定每秒运行10次,大概100ms运行一次。在Redis2.8版本后,可以通过修改配置文件redis.conf 的 hz 选项来调整每秒次数(一般用默认值, 过高会的cpu造成一定压力)。由redis.c/activeExpireCycle 函数实现。
惰性删除 在获取某个Key时Redis会先检测一下,这个key是否设置了过期时间?如果设置了过期时间那么是否过期?过期就删除。由 db.c/expireIfNeeded 函数实现。
如果定期抽取一批过期key删除, 以及没有对过期key访问了,这样会存在大量过期key未删除回收的情况,会导致内存使用率大大降低;所以redis内部提供了不同的内存淘汰回收策略。
内存淘汰回收策略
当内存达到限制时,Redis 具体的回收策略是通过 maxmemory-policy 配置项配置的。
以下的策略都是可用的:
-
noenviction:不清除数据,只是返回错误,这样会导致浪费掉更多的内存,对大多数写命令(DEL 命令和其他的少数命令例外)
-
allkeys-lru:从所有的数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰,以供新数据使用
-
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰,以供新数据使用
-
allkeys-random:从所有数据集(server.db[i].dict)中任意选择数据淘汰,以供新数据使用
-
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰,以供新数据使用
-
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰,以供新数据使用
从 Redis 4.0 版开始,引入了新的 LFU(最近最不常用)策略。
-
volatile-lfu:从已设置过期时间的数据集(server.db[i].expires)中挑选近似 LFU 数据淘汰。
-
allkeys-lfu:从所有的数据集(server.db[i].dict)中挑选近似 LFU 数据淘汰。
LFU 类似于 LRU:它使用一个概率计数器,称为莫里斯计数器,以便仅使用每个对象的几位来估计对象访问频率,并结合衰减周期,以便计数器随着时间的推移而减少:在某些时候,我们不再希望将key视为经常访问的key,即使它们过去是这样,以便算法可以适应访问的转变。LFU具有可调参数: (见:Random notes on improving the Redis LRU algorithm Least Frequently Used)
lfu-log-factor 10 //在大约一百万个请求时使计数器饱和因子,计数器对数因子会改变需要多少次命中才能使频率计数器饱和,这恰好在 0-255 的范围内。系数越高,需要越多的访问以达到最大值。系数越低,低访问计数器的分辨率越好,见redis示例redis.conf文件 lfu-decay-time 1 //每一分钟衰减一次计数器。
当 cache 中没有符合清除条件的 key 时,回收策略 volatile-lru, volatile-random 和volatile-ttl 将会和 策略 noeviction 一样返回错误。选择正确的回收策略是很重要的,取决于你的应用程序的访问模式。但是,你可以在程序运行时重新配置策略,使用 INFO 输出来监控缓存命中和错过的次数,以调优你的设置。
普适经验规则:
- 如果期望用户请求呈现幂律分布(power-law distribution),也就是,期望一部分子集元素被访问得远比其他元素多时,可以使用allkeys-lru策略。在你不确定时这是一个好的选择。
- 如果期望是循环周期的访问,所有的键被连续扫描,或者期望请求符合平均分布(每个元素以相同的概率被访问),可以使用allkeys-random策略。
- 如果你期望能让 Redis 通过使用你创建缓存对象的时候设置的TTL值,确定哪些对象应该是较好的清除候选项,可以使用volatile-ttl策略。
当你想使用单个Redis实例来实现缓存和持久化一些键,allkeys-lru和volatile-random策略会很有用。但是,通常最好是运行两个Redis实例来解决这个问题。
另外值得注意的是,为键设置过期时间需要消耗内存,所以使用像allkeys-lru这样的策略会更高效,因为在内存压力下没有必要为键的回收设置过期时间。
回收过程
理解回收过程是运作流程非常的重要,回收过程如下:
- 一个客户端运行一个新命令,添加了新数据。
- Redis检查内存使用情况,如果大于maxmemory限制,根据策略来回收键。
- 一个新的命令被执行,如此等等。
我们添加数据时通过检查,然后回收键以返回到限制以下,来连续不断的穿越内存限制的边界。如果一个命令导致大量的内存被占用(比如一个很大的集合保存到一个新的键),那么内存限制很快就会被这个明显的内存量所超越。
近似LRU算法
Redis整体上是一个大的dict,如果实现一个双向链表需要在每个key上首先增加两个指针,需要16个字节,并且额外需要一个list结构体去存储该双向链表的头尾节点信息。Redis作者认为这样实现不仅内存占用太大,而且可能导致性能降低。具体详见作者博客文章:Random notes on improving the Redis LRU algorithm
Redis为什么不使用原生LRU算法?
- 原生LRU算法需要 双向链表 来管理数据,需要额外内存;
- 数据访问时涉及数据移动,有性能损耗;
- Redis现有数据结构需要改造,dictEntry, key指向sds, val指向redisObject,dictEntry 是个单向链表;
Redis的LRU算法不是一个严格的LRU实现。这意味着Redis不能选择最佳候选键来回收,也就是最久未被访问的那些键。相反,Redis 会尝试执行一个近似的LRU算法,通过采样一小部分键,然后在采样键中回收最适合(拥有最久访问时间)的那个。然而,从Redis3.0开始,算法被改进为维护一个回收候选键池。这改善了算法的性能,使得更接近于真实的LRU算法的行为。Redis的LRU算法有一点很重要,你可以调整算法的精度,通过改变每次回收时检查的采样数量。这个参数可以通过如下配置指令:maxmemory-samples 5
Redis没有使用真实的LRU实现的原因,是因为这会消耗更多的内存。然而,近似值对使用Redis的应用来说基本上也是等价的。文章Using Redis as an LRU cache为Redis使用的LRU近似值和真实LRU之间的比较。
触发时机是在redis server执行新的写命令时, 当 mem_used > maxmemory 的时候,通过 performEvictions 方法完成数据淘汰(所看的Redis6.2.6源码)。LRU策略淘汰核心逻辑在 evictionPoolPopulate(淘汰数据集合填充) 方法。
Redis6.2.6 淘汰策略整体逻辑
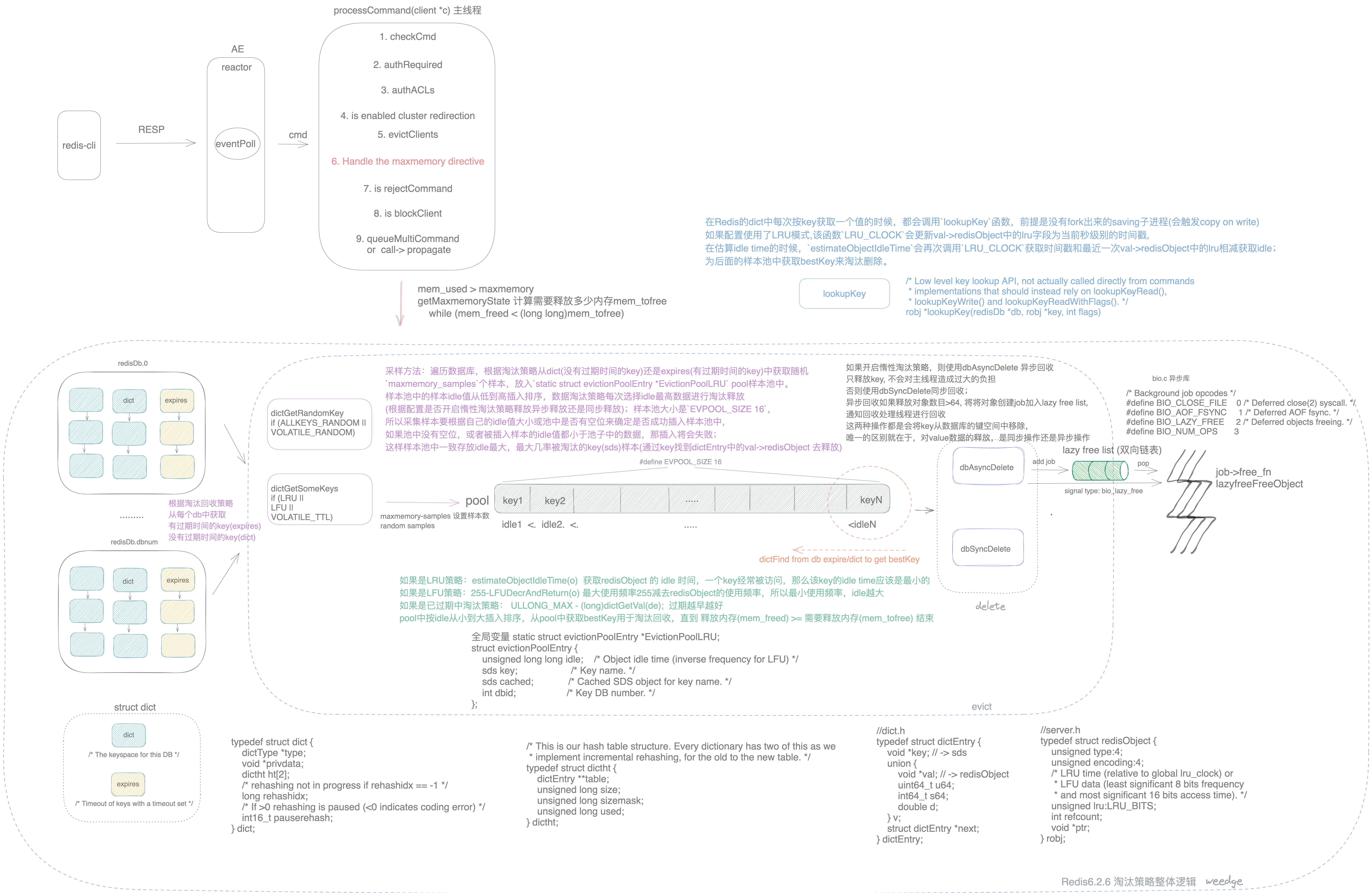
key访问变更策略值(用于计算idle):
在Redis的dict中每次按key获取一个值的时候,都会调用lookupKey函数,前提是没有fork出来的saving子进程(会触发copy on write)
如果配置使用了LRU模式,该函数LRU_CLOCK会更新val->redisObject中的lru字段为当前秒级别的时间戳, 在估算idle time的时候,estimateObjectIdleTime会再次调用LRU_CLOCK获取时间戳和最近一次val->redisObject中的lru相减获取idle;
为后面的样本池中获取bestKey来淘汰删除。
采样方法:
遍历数据库,根据淘汰策略从dict(没有过期时间的key)还是expires(有过期时间的key)中获取随机maxmemory_samples个样本,放入static struct evictionPoolEntry *EvictionPoolLRU pool样本池中。样本池中的样本idle值从低到高插入排序,数据淘汰策略每次选择idle最高数据进行淘汰释放(根据配置是否开启惰性淘汰策略释放异步释放还是同步释放);样本池大小是EVPOOL_SIZE 16,所以采集样本要根据自己的idle值大小或池中是否有空位来确定是否成功插入样本池中,如果池中没有空位,或者被插入样本的idle值都小于池子中的数据,那插入将会失败;这样样本池中一致存放idle最大,最大几率被淘汰的key(sds)样本(通过key找到dictEntry中的val->redisObject 去释放)。
Idle获取:
如果是LRU策略:estimateObjectIdleTime(o) 获取redisObject 的 idle 时间,一个key经常被访问,那么该key的idle time应该是最小; 如果是LFU策略:255-LFUDecrAndReturn(o) 最大使用频率255减去redisObject的使用频率,所以最小使用频率,idle越大; 如果是已过期中淘汰策略: ULLONG_MAX - (long)dictGetVal(de); 过期越早越好; pool中按idle从小到大插入排序,便于获取bestKey,用于删除。
淘汰删除策略:
如果开启惰性淘汰策略,则使用dbAsyncDelete 异步回收只释放key, 不会对主线程造成过大的负担,否则使用dbSyncDelete同步回收;
异步回收如果释放对象数目>64, 将对象创建job加入lazy free list;通知signal type: bio_lazy_free回收处理线程进行回收;
这两种操作都是会将key从数据库的键空间中移除,唯一的区别就在于,对value数据的释放,是同步操作还是异步操作。
触发代码在server.c中:activeExpireCycle performEvictions 函数 在 server.c readme中有介绍什么时候触发。
Mysql8.0 InnoDB page buffer pool LRU evict策略
页Page
数据库的数据是放在磁盘空间以表空间存放的,加载的时候以页page为单位进行加载,页是InnoDB存储引擎磁盘管理的最小单位,每个页默认16KB;可以通过参数innodb_page_size设置(一个页内必须存储2行记录,否则就不是B+tree,而是链表了),页面类型:
数据页(B-tree Node)
undo页(undo Log Page)
系统页(System Page)
事务数据页(Transaction system Page)
插入缓冲位图页(Insert Buffer Page)
插入缓冲空闲列表页(Insert Buffer Free List)
未压缩的二进制大对象页(Uncompressd BLOB Page)
压缩的二进制大对象页(Compressd BLOB Page)

从InnoDB存储引擎的逻辑结构看,所有数据都被逻辑地存放在一个空间内,称为表空间(tablespace),而表空间由段(sengment)、区(extent)、页(page)组成。 在一些文档中extend又称块(block)。这里有几个概念简单介绍下:
-
表空间(Tablespace) 是一个逻辑容器,表空间存储的对象是段,在一个表空间中可以有一个或多个段,但是一个段只能属于一个表空间。数据库由一个或多个表空间组成,表空间从管理上可以划分为系统表空间、File-per-table 表空间、通用表空间、撤销表空间、临时表空间。(表空间文件可以通过xxd进行分析)
在 InnoDB 中存在两种表空间的类型:共享表空间(例如系统表空间或通用表空间)和独立表空间(File-per-table 表空间)。如果是共享表空间就意味着多张表共用一个表空间。如果是独立表空间,就意味着每张表有一个独立的表空间,也就是数据和索引信息都会保存在自己的表空间中。独立的表空间可以在不同的数据库之间进行迁移。禁用
innodb_file_per_table会在系统表空间中创建表。mysql8.0 InnoDB存储引擎对磁盘结构中的表空间操作有些改变:
- 8.0版本中,系统表空间只是更改缓冲区的存储区域;以前版本是InnoDB数据字典、双写缓冲区、更改缓冲区和撤消日志的存储区域 。(如果表是在系统表空间中创建的,而不是在每个表文件或通用表空间中创建,则它还可能包含表和索引数据)
- 在8.0以前的 MySQL 版本中,系统表空间包含InnoDB数据字典mysql.* 。在 MySQL 8.0 中InnoDB将元数据存储在 MySQL 数据字典表空间中,表结构等数据字典元数据都是通过InnoDB来管理(mysql.ibd或者独立表空间*.ibd文件中)。
- 在 MySQL 8.0.20 之前,doublewrite 缓冲区存储区位于InnoDB系统表空间中;从 MySQL 8.0.20 开始,双写缓冲区存储区域位于双写文件中。附上官方mysql8.0 InnoDB存储引擎架构图(对比 5.7版本架构):

-
段(Segment) 由一个或多个区组成,区在文件系统是一个连续分配的空间(在 InnoDB 中是连续的 64 个页),不过在段中不要求区与区之间是相邻的。段是数据库中的分配单位,不同类型的数据库对象以不同的段形式存在。当我们创建数据表、索引的时候,就会相应创建对应的段,比如创建一张表时会创建一个表段,创建一个索引时会创建一个索引段。
-
区(extent) 在 InnoDB 存储引擎中,一个区会分配 64 个连续的页。因为 InnoDB 中的页大小默认是 16KB,所以一个区的大小是 64*16KB=1MB。在任何情况下每个区大小都为1MB,为了保证页的连续性,InnoDB存储引擎每次从磁盘一次申请4-5个区。默认情况下,InnoDB存储引擎的页大小为16KB,即一个区中有64个连续的页。
-
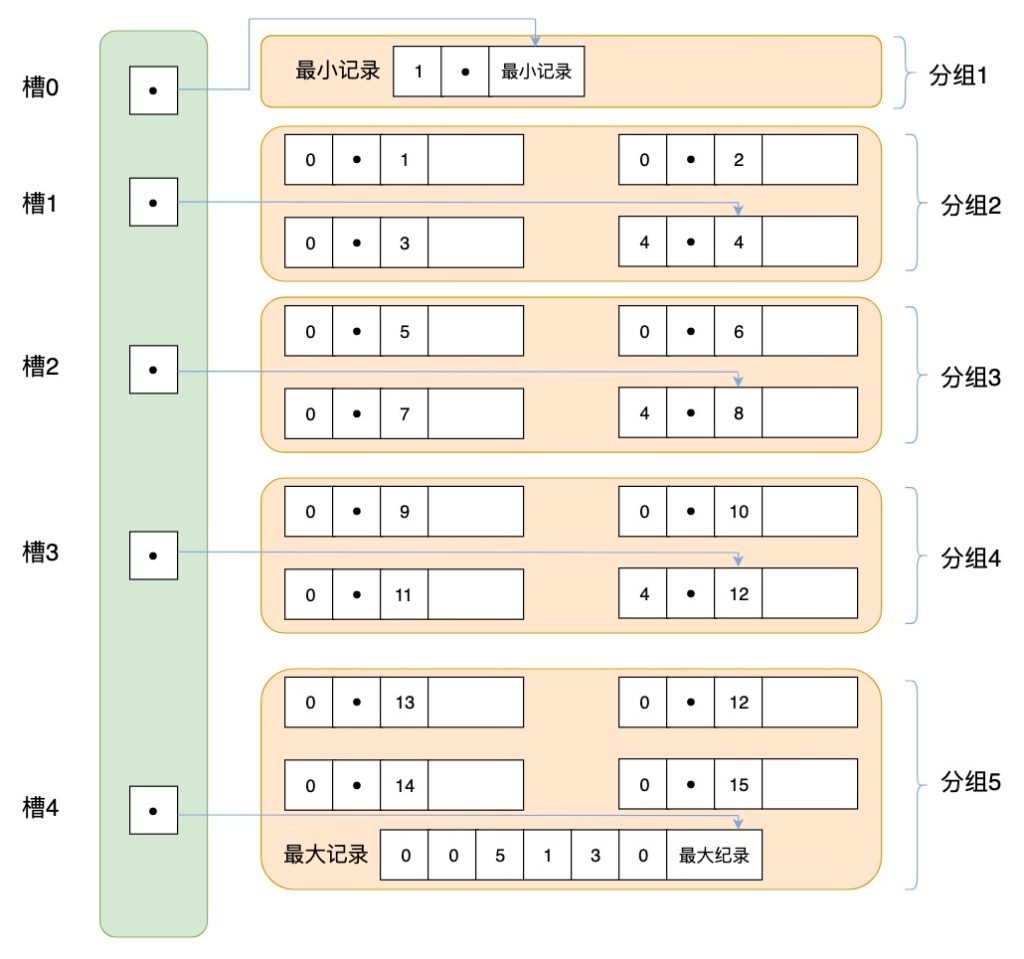
页(page) 是InnoDB存储引擎磁盘管理的最小单位,每个页默认16KB,页结构如下:
Page directory 页目录用来存储每组最后一条记录的地址偏移量,这些地址偏移量会按照先后顺序存储起来,每组的地址偏移量也被称之为槽(slot),每个槽相当于指针指向了不同组的最后一个记录,这样方便二分查找快速定位到记录;
-
行(row) InnoDB存储引擎是按行进行存放的,每个页存放的行记录也是有硬性定义的,最多允许存放16KB/2-200,即7992行记录。InnoDB 行格式支持四名的格式:REDUNDANT,COMPACT, DYNAMIC,和COMPRESSED,默认DYNAMIC
B+ 树是如何进行记录检索的?
如果通过 B+ 树的索引查询行记录,首先是从 B+ 树的根开始,逐层检索,直到找到叶子节点,也就是找到对应的数据页为止,如果数据页没在缓冲池中,将数据页加载到内存 缓冲池(buffer pool) 中,页目录中的 槽(slot) 采用二分查找的方式先找到一个粗略的记录分组,然后再在分组中通过链表遍历的方式查找记录。
缓冲池(buffer pool) LRU/unzip_LRU 链表
缓冲池(buffer pool) 是主内存中的一个区域,用于在 InnoDB访问时缓存表和索引数据。缓冲池允许直接从内存访问经常使用的数据,从而加快处理速度。在专用服务器上,多达 80% 的物理内存通常分配给缓冲池。
这里有个问题,比如有如下 场景,一个直播间id为1的观看人数上百万,假如运营后台需要查找全部数据,(这里假设没有通过CQRS模式将数据放入ES中,ES查询缓存也用到了LRU, 可以参考这篇Elasticsearch 的查询缓存)
select * from room_student_history where room_id=1 and id>=(select id from room_student_history where order by id limit 1000000,1) order by id limit 1000
如果room_student_history中有大量长尾用户数据并且读取之后不会继续使用,则LRU头部会被大量的room_student_history中的数据占据。这样会造成热点数据被逐出缓存从而导致大量的磁盘io ;
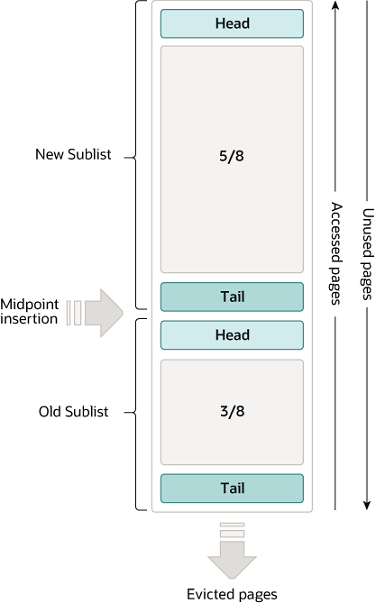
mysql innodb的buffer pool使用了一种改进的LRU算法,大意是将LRU链表分成两部分,一部分为newlist,一部分为oldlist,newlist是头部热点数据,oldlist是非热点数据,oldlist默认占整个list长度的3/8.当初次加载一个page的时候,会首先放入oldlist的头部,只有满足一定条件后,才被移到new list上,主要是为了防止预读的数据页和全表扫描污染buffer pool。详细介绍见官方文档
附mac下把玩操作:(单机实例,通过brew切换版本服务挺方便的;生产环境优化配置: 高可用,性能优化稳定等配置)
- brew install [email protected] //安装5.7版本
- brew services start [email protected] //启动5.7版本mysqld,mysqld_safe
- 建表,查看/usr/local/var/mysql 目录下的数据文件,可以对照 5.7版本架构 查看表空间文件;
- 写些数据,查看相关数据文件的数据变化, 通过 xxd/hexdump 以十六进制的方式查看表空间二进制文件*.ibd等
- brew install mysql //安装最新版本8.0
- brew services stop [email protected] //停止[email protected]服务
- brew services start mysql //启动8.0版本mysqld,mysqld_safe
- 查看/usr/local/var/mysql 目录下的数据文件, 对比5.7版本的文件变化,新增了哪些文件分开管理, 以及对数据字典的变化
- /usr/local/opt/mysql/bin/ibd2sdi (utilities/ibd2sdi.cc文件) 查看ibd文件中的字典序列化信息,mysqlbinlog binlog.* 打印binlo g信息
- 客户端命令执行show VARIABLES like “%Innodb%"; show status like “%Innodb%"; 查看Innodb参数和状态统计;
- 客户端命令执行 SHOW ENGINE INNODB STATUS; 查看整体运行状态监控数据(io,thread, buffer pool memory, SEMAPHORES, TRANSACTIONS,INSERT BUFFER AND ADAPTIVE HASH INDEX,LOG,ROW OPERATIONS)
- 客户端执行命令,通过dtruss -p 查看mysqld进程对应的系统调用
- 相关的参数可以从官网查看介绍Server Option, System Variable, and Status Variable Reference
- 下载源码 https://github.com/mysql/mysql-server 8.0 版本分支,download zip文件,解压,编译,运行,gdb debug
缓/内存io比磁盘io快许多,但是缓/内存空间有限,且无法持久化,所以需要提供缓/内存淘汰机制来保证缓/内存使用命中率,本文介绍常用的LRU算法;golang实现的开源方案,可以结合业务场景,进行使用,redis 为了节省空间,通过抽样将淘汰的数据放入待淘汰数据池(evictionPoolEntry) 进行淘汰,在 Redis 3.0 中使用 10 个样本大小,该近似值非常接近 Redis 3.0 的原始LRU理论性能。mysql 需要充分利用缓存池资源,减少磁盘io, 因为加载单元是page, 如果第一次加载放入LRU链表头,可能这些数据使用频率不高,导致缓存池命中率低,将LRU链表按3/8分成old list 和new list , 第一次加载放入oldList头,再次访问时才会移动到newlist。根据淘汰的结构,根据数据使用场景,将LRU算法优化, redis和mysql 都用到了pool, 但是是两种场景,redis是为了淘汰释放使用样本pool, 样本池中放入的是idle值,根据不同策略算出的值,用来淘汰最大的idle, 方便扩展优化算法; mysql 中的pool是buffer pool 缓冲池,主要是为了存放page, page 是innodb磁盘管理的最小单位,为了减少磁盘io, 尽量减少缓存miss, 增加hit率,提高读写操作方案。
references
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK