

论文解读Real-time Personalization using Embeddings for Search Ranking at Airbnb
source link: https://jasonyanglu.github.io/posts/2019/07/blog-post-5/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

论文解读Real-time Personalization using Embeddings for Search Ranking at Airbnb
less than 1 minute read
Published: July 02, 2019
这篇文章是airbnb提出的一种构造item embedding的方式。该方法将应用领域的需求与算法高度结合。
- Real-time Personalization - 实时个性化。相比之前工作离线构建user-item和item-item表进行训练,这篇文章提出在线方法训练最近交互的物品的embeddings然后计算相似度进行排序。
- Adapting Training for Congregated Search - 面向聚合搜索自适应训练。在负采样的时候进行了调整,学习不同地方的相似性。
- Leveraging Conversions as Global Context - 限定窗口的重要性,在每个对话中的click sessions构建list embeddings。
- User Type Embeddings - 当用户和listing ID稀疏时,使用user type和listing type级别上训练type embedding。
- Rejections as Explicit Negatives - 将房东拒绝出租的case作为训练中明确的负样本。
- Listing embeddings: 通过用户在一个session中的短期点击行为来训练房源的id embedding。
- User-type & listing-type embeddings: 通过用户的历史消费行为来训练用户和房源的type embedding。
- Experiment:描述了如何将训练得到的embedding用在真实的推荐场景中。
Listing Embeddings
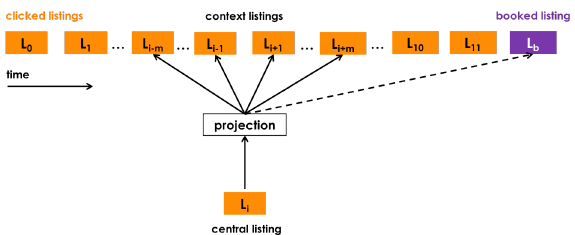
应用原始Skip-gram算法在Airbnb场景
- 点击会话 (Session) ,每个会话s=(L1,…,Ln)∈Ss=(L1,…,Ln)∈S定义为一个由用户点击的 n 个房源 id 组成的的不间断序列。
- 只要用户连续两次点击之间的时间间隔超过30分钟,第二次点击会被认为是一个新的会话的开始。
- 目标是学习一个 32 维的实值表示方式 ,使相似房源在Embedding空间中处于临近的位置。
- 在每一步中,将中央房源的向量更新并将其推向正向相关房源的向量(用户在点击中心房源前后点击的其他房源,滑动窗口长度为m=5),并通过随机抽样房源的方式将它从负向相关房源推开(因为这些房源很大几率与中央房源没有关系)。
- 用最终预订的房源作为全局上下文 (Global Context) :使用以用户预订了房源(上图中紫色标记)为告终的用户会话来做这个优化,在这个优化的每个步骤中不仅预测相邻的点击房源,还会预测最终预订的房源。 当窗口滑动时,一些房源会进入和离开窗口,而预订的房源始终作为全局上下文(图中虚线)保留在其中,并用于更新中央房源向量。
- 适配聚集搜索的场景:在线旅行预订网站的用户通常仅在他们的旅行目的地内进行搜索。 因此,对于给定的中心房源,正相关的房源主要包括来自相同目的地的房源,而负相关房源主要包括来自不同目的地的房源,因为它们是从整个房源列表中随机抽样的。 但这种不平衡会导致在一个目的地内相似性不是最优的。所以在训练embedding时再加上了一个相同目的地下没被点击的负样本来加强同一位置的房源相似度的区分。
- 冷启动Embedding:每天在 Airbnb 上都有新的房源提供。这些房源在新建时还不在训练数据集中,所以没有嵌入信息。 要为新房源创建嵌入,会找到 3 个地理位置最接近、房源类别和价格区间相同的已存在的房源,并计算这些房源嵌入的向量平均值来作为新房源的嵌入值。
- 在对使用了嵌入的推荐系统进行线上搜索测试之前进行了多次离线测试。同时还使用这些测试比较了多种不同参数训练出来的不同嵌入,以快速做优化,决定嵌入维度、算法修改的不同思路、训练数据的构造、超参数的选择等。
- 评估Embedding的一种方法是测试它们通过用户最近的点击来推荐的房源,有多大可能最终会产生预订。更具体地说,假设获得了最近点击的房源和需要排序的房源候选列表,其中包括用户最终预订的房源;通过计算点击房源和候选房源在嵌入空间的余弦相似度可以对候选房源进行排序,并观察最终被预订的房源在排序中的位置。
- 搜索中的房源根据Embedding空间的相似性进行了重新排序,并且最终被预订房源的排序是按照每次预定前的点击的平均值来计算。
User-type & listing-type embeddings
在session内的embedding比较适合短期的个性化推荐,其目标是给用户展示跟刚刚点击过的房源相似的房源。但是用户的长期消费行为历史对于个性化推荐也十分有用。例如,一个用户正在搜索洛杉矶的房源,他曾经订过纽约和伦敦的房源,给他推荐和他以前订过的房源相似的房源是有帮助的。但是通过用户的历史消费来训练embedding会带来一些挑战:
- 相比于点击行为,用户的历史消费行为很少。
- 有一些用户曾经只消费过一次,只有一个item的list没办法训练embedding。
- 通常5-10个item的list才能够训练出较好的embedding,但是多数用户并没有5-10次消费记录。
- 用户的历史消费记录可能有较长的时间跨度,用户的喜好会发生转变。
为解决上述问题,作者提出通过训练user_type和listing_type的embedding来取代user_id和listing_id的embedding。type是通过一系列人工规则来将不同的id映射到不同的type:
对于新用户,先用其画像属性来分type,待其有了消费记录后,用其最近一次消费过后的type来作为该用户的user_type。
对于历史消费记录,训练embedding的一个session表示为sb=(utype1ltype1,…,utypeMltypeM)sb=(utype1ltype1,…,utypeMltypeM),utype1ltype1utype1ltype1代表用户第1次消费记录时的user_type和当时订的listing的listing_type。user_type和listing_type在同一个向量空间中被训练。中心被训练的item可以是user_type也可以是listing_type
拒绝租客作为显示负样本
如果一个用户下订单之后被房东拒绝了,那么这个listing会被看做是一个显式的负样本,这个负样本将被放进训练窗口中。
Experiment
- 模型采用的是GBDT回归,特征由4部分组成:listing特征,用户特征,请求特征,交叉特征。样本的标签定义如下:
- 0:曝光未点击。
- 1:成功预定。
- 0.25:用户联系了房东,但是最终没预定。
- 0.01:点击。
- -0.4:用户被房东拒绝。
- 除了一些基础画像特征和统计特征,文章使用了用户最近2周的行为特征,将listing id分成了6个组
- 点过的listing。
- 点过并且在页面停留了60秒以上的listing。
- 曝光了但是被跳过的listing。
- 收藏的listing。
- 联系过房东但是没订的listing。
- 订了的listing。
- 一个用户的这些组的listing的embedding计算均值之后作为用户的embedding,与被推荐的listing embedding计算cosine距离后,作为一个特征丢进模型。除了以上6个特征以外,还有2个特征:
- 最近一次点过并且在页面停留了60秒以上的listing和被推荐listing的距离。
- user_type和listing_type的距离。
Real-time体现在什么地方?
用户当前点击的listing的向量来计算listing embedding features,从而加入特征进行实时的推荐。 也就是说,t时刻的推荐结果,是根据用户在t时刻之前的行为生成的特征。 在t+1时刻如果用户点击了另外一个listing, listing embedding features也会随之发生变化,推荐的结果也就可能变化。
实际业务中怎么用listing embedding,listing type embedding和user type embedding?
最后所有的embedding都没有直接放入模型,取而代之的是将各种embedding之间的cosine距离作为特征丢给模型训练。实验部分说明了,最后训练出的embedding只是在原有的GBDT模型上,加了8维cosine距离的特征,加完之后共104维特征,结论是embedding特征的feature importance比较高。
为什么不用点击率作为排序目标?
Airbnb的最终目标是用户是否下订,点击不下订和曝光不点击对于业务指标并没有太多区别(但是对训练listing embedding很重要),这一点从文章的回归任务中的曝光不点击的label是0,而点击不下订的label是0.01就可以看出。
listing embedding已经有了30min作为session分隔,为什么还需要sliding window?
文中提到的sliding window应该指的是在一个session内,从第一个listing开始作为中心,逐渐往右边移动选择下一个作为中心,和skip-gram的window是对应的。
https://zhuanlan.zhihu.com/p/43295545
感谢腾讯高级研究员陈亮与本人共同完成此文。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK