

预训练模型-BERT预训练源码解读笔记
source link: https://carlos9310.github.io/2019/09/30/pre-trained-bert/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

之前总是直接用预训练好的BERT模型,对预训练部分的认识只停留在其同时训练两个无监督的任务:masked LM和Next Sentence Prediction (NSP)。而之后的SOTA模型如XLNet、RoBERTa、ALBERT等都属于BERT的追随者。因此有必要详细了解BERT预训练的细节。
本篇post主要从代码角度解读BERT的预训练的思路与细节。
官方给出了一个作为初始训练语料的.txt格式的demo文件sample_text.txt,其中每一行表示一句话,不同文档用空格区分。如果想训练自己的数据,整理成上述形式即可。
数据预处理
先直观地看一下数据预处理时执行脚本。
python create_pretraining_data.py \
--input_file=./sample_text.txt \
--output_file=/tmp/tf_examples.tfrecord \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--do_lower_case=True \
--max_seq_length=128 \
--max_predictions_per_seq=20 \
--masked_lm_prob=0.15 \
--random_seed=12345 \
--dupe_factor=5
其中input_file为初始训练语料的文件路径,可有多个(用逗号分隔);output_file指定了生成.tfrecord格式的文件路径,可有多个(用逗号分隔);vocab_file预训练的词表文件,直接用google提供的即可。若使用自己生成的 词表需重新训练,但需保证自己有足够多的文本语料;max_seq_length 表示拼接后的句子对组成的序列中包含Wordpiece级别的token数的上限,超过部分,需将较长的句子进行首尾截断;max_predictions_per_seq表示每个序列中需要预测的token数的上限;masked_lm_prob表示生成的序列中被masked的token占总token数的比例(这里的masked是广义的mask,即将选中的token替换成[mask]或保持原词汇或随机替换成词表中的另一个词),且有如下关系max_predictions_per_seq 约等于 max_seq_length * masked_lm_prob;random_seed为随机种子,便于复现结果;dupe_factor表示重复因子,即重复创建TrainingInstance的次数,因每次随机生成mask,所以需预测的mask的token是不同的。
create_pretraining_data.py模块主要是将上述.txt格式的初始训练语料先转化为TrainingInstance对象组成的list,然后将生成的每一个TrainingInstance对象依此转成tf.train.Example对象后,序列化到.tfrecord格式的文件中。最终生成的.tfrecord格式的文件是BERT预训练时的数据源。
下面分步骤依此看下各个处理过程。
首先是从原始的.txt格式的语料中生成由TrainingInstance对象组成的list。其主流程代码如下:
def create_training_instances(input_files, tokenizer, max_seq_length,
dupe_factor, short_seq_prob, masked_lm_prob,
max_predictions_per_seq, rng):
"""Create `TrainingInstance`s from raw text."""
all_documents = [[]]
# Input file format:
# (1) One sentence per line. These should ideally be actual sentences, not
# entire paragraphs or arbitrary spans of text. (Because we use the
# sentence boundaries for the "next sentence prediction" task).
# (2) Blank lines between documents. Document boundaries are needed so
# that the "next sentence prediction" task doesn't span between documents.
for input_file in input_files:
with tf.gfile.GFile(input_file, "r") as reader:
while True:
line = tokenization.convert_to_unicode(reader.readline())
if not line:
break
line = line.strip()
# Empty lines are used as document delimiters
if not line:
all_documents.append([])
tokens = tokenizer.tokenize(line)
if tokens:
all_documents[-1].append(tokens)
# Remove empty documents
all_documents = [x for x in all_documents if x]
rng.shuffle(all_documents)
vocab_words = list(tokenizer.vocab.keys())
instances = []
for _ in range(dupe_factor):
for document_index in range(len(all_documents)):
instances.extend(
create_instances_from_document(
all_documents, document_index, max_seq_length, short_seq_prob,
masked_lm_prob, max_predictions_per_seq, vocab_words, rng))
rng.shuffle(instances)
return instances
先遍历可用的语料,依次读取每个语料中的每一行,如果没有行可读,停止当前语料的遍历;如果扫描到换行符(空行),往all_documents中追加一个空list;其他情况则先将读取的行分割成wordpiece级别的list,然后追加到all_documents中的最后一个文档中。最终形成如下形式的文档list:[[[d1_s1],[d1_s2],…,[d1_sn]],[[d2_s1],[d2_s2],…,[d2_sm]],…,[[dk_s1],[dk_s2],…,[dk_sz]]]。上述表示一个语料中有k个文档,第一个文档有n句话,第二个文档有m句话,第k个文档有z句话,d1_s1表示第一个文档中的第一句话被分割成wordpiece级别的list。
接着过滤掉all_documents中的空文档并随机打乱其中的文档顺序。然后对all_documents中的每一个文档生成由TrainingInstance对象组成的instances列表,即create_instances_from_document,并拼接(extend)所有的instances到一个instances中。重复上述all_documents–>instances的过程dupe_factor次。最后再随机打乱生成的instances并返回。
上述最重要的操作是如何从单个文档中生成由TrainingInstance对象组成的instances列表,即create_instances_from_document函数。该函数涉及masked LM和Next Sentence Prediction (NSP)的具体实现细节。 具体代码如下:
def create_instances_from_document(
all_documents, document_index, max_seq_length, short_seq_prob,
masked_lm_prob, max_predictions_per_seq, vocab_words, rng):
"""Creates `TrainingInstance`s for a single document."""
document = all_documents[document_index]
# Account for [CLS], [SEP], [SEP]
max_num_tokens = max_seq_length - 3
# We *usually* want to fill up the entire sequence since we are padding
# to `max_seq_length` anyways, so short sequences are generally wasted
# computation. However, we *sometimes*
# (i.e., short_seq_prob == 0.1 == 10% of the time) want to use shorter
# sequences to minimize the mismatch between pre-training and fine-tuning.
# The `target_seq_length` is just a rough target however, whereas
# `max_seq_length` is a hard limit.
target_seq_length = max_num_tokens
if rng.random() < short_seq_prob:
target_seq_length = rng.randint(2, max_num_tokens)
# We DON'T just concatenate all of the tokens from a document into a long
# sequence and choose an arbitrary split point because this would make the
# next sentence prediction task too easy. Instead, we split the input into
# segments "A" and "B" based on the actual "sentences" provided by the user
# input.
instances = []
current_chunk = []
current_length = 0
i = 0
while i < len(document):
segment = document[i]
current_chunk.append(segment)
current_length += len(segment)
if i == len(document) - 1 or current_length >= target_seq_length:
if current_chunk:
# `a_end` is how many segments from `current_chunk` go into the `A`
# (first) sentence.
a_end = 1
if len(current_chunk) >= 2:
a_end = rng.randint(1, len(current_chunk) - 1)
tokens_a = []
for j in range(a_end):
tokens_a.extend(current_chunk[j])
tokens_b = []
# Random next
is_random_next = False
if len(current_chunk) == 1 or rng.random() < 0.5:
is_random_next = True
target_b_length = target_seq_length - len(tokens_a)
# This should rarely go for more than one iteration for large
# corpora. However, just to be careful, we try to make sure that
# the random document is not the same as the document
# we're processing.
for _ in range(10):
random_document_index = rng.randint(0, len(all_documents) - 1)
if random_document_index != document_index:
break
random_document = all_documents[random_document_index]
random_start = rng.randint(0, len(random_document) - 1)
for j in range(random_start, len(random_document)):
tokens_b.extend(random_document[j])
if len(tokens_b) >= target_b_length:
break
# We didn't actually use these segments so we "put them back" so
# they don't go to waste.
num_unused_segments = len(current_chunk) - a_end
i -= num_unused_segments
# Actual next
else:
is_random_next = False
for j in range(a_end, len(current_chunk)):
tokens_b.extend(current_chunk[j])
truncate_seq_pair(tokens_a, tokens_b, max_num_tokens, rng)
assert len(tokens_a) >= 1
assert len(tokens_b) >= 1
tokens = []
segment_ids = []
tokens.append("[CLS]")
segment_ids.append(0)
for token in tokens_a:
tokens.append(token)
segment_ids.append(0)
tokens.append("[SEP]")
segment_ids.append(0)
for token in tokens_b:
tokens.append(token)
segment_ids.append(1)
tokens.append("[SEP]")
segment_ids.append(1)
(tokens, masked_lm_positions,
masked_lm_labels) = create_masked_lm_predictions(
tokens, masked_lm_prob, max_predictions_per_seq, vocab_words, rng)
instance = TrainingInstance(
tokens=tokens,
segment_ids=segment_ids,
is_random_next=is_random_next,
masked_lm_positions=masked_lm_positions,
masked_lm_labels=masked_lm_labels)
instances.append(instance)
current_chunk = []
current_length = 0
i += 1
return instances
首先确定要从哪个文档生成TrainingInstance对象,接着确定拼接两个segment(segment是基于句子生成的,一个segment可能只有一个句子,也可能由多个句子拼接而成)组成的序列中可容纳的最多token数为max_num_tokens,然后循环遍历该文档中的每一个句子,当遍历的前几个句子对应的token的总数大于等于目标序列的最大值(target_seq_length,不是max_num_tokens)或已遍历到最后一个句子,则从current_chunk中按顺序选取一定数量(随机生成)的句子拼接成tokens_a(segment A),而tokens_b(segment B)的生成有两种可能(与NSP相对应)。一种是从current_chunk中依次拼接tokens_a剩下的句子,此时tokens_a与tokens_b是连贯的;另一种是随机选择其他文档,并随机地确定要遍历的句子的开始,然后不断拼接直到大于等于target_b_length。需要注意的是,此时需进一步确定current_chunk中未用到的句子,并将遍历该文档句子的索引重新置位到未用到的句子的位置。
至此tokens_a(segment A)与tokens_b(segment B)便分别确定了。在进一步处理前需保证拼接后两个segment的总tokens数小于等于max_num_tokens,对于超过的部分,每次选择较长的句子随机地去掉头或尾,直至符合要求。
然后将截取后的tokens_a与tokens_b拼接成 [CLS] tokens_a [SEP] tokens_b [SEP]的形式。以上就是Next Sentence Prediction (NSP)任务对应的数据预处理的细节。
接着在最终拼接后的两个segments形成的tokens的基础上做mask操作,生成masked LM任务需要的tokens形式。具体代码如下:
def create_masked_lm_predictions(tokens, masked_lm_prob,
max_predictions_per_seq, vocab_words, rng):
"""Creates the predictions for the masked LM objective."""
cand_indexes = []
for (i, token) in enumerate(tokens):
if token == "[CLS]" or token == "[SEP]":
continue
# Whole Word Masking means that if we mask all of the wordpieces
# corresponding to an original word. When a word has been split into
# WordPieces, the first token does not have any marker and any subsequence
# tokens are prefixed with ##. So whenever we see the ## token, we
# append it to the previous set of word indexes.
#
# Note that Whole Word Masking does *not* change the training code
# at all -- we still predict each WordPiece independently, softmaxed
# over the entire vocabulary.
if (FLAGS.do_whole_word_mask and len(cand_indexes) >= 1 and
token.startswith("##")):
cand_indexes[-1].append(i)
else:
cand_indexes.append([i])
rng.shuffle(cand_indexes)
output_tokens = list(tokens)
num_to_predict = min(max_predictions_per_seq,
max(1, int(round(len(tokens) * masked_lm_prob))))
masked_lms = []
covered_indexes = set()
for index_set in cand_indexes:
if len(masked_lms) >= num_to_predict:
break
# If adding a whole-word mask would exceed the maximum number of
# predictions, then just skip this candidate.
if len(masked_lms) + len(index_set) > num_to_predict:
continue
is_any_index_covered = False
for index in index_set:
if index in covered_indexes:
is_any_index_covered = True
break
if is_any_index_covered:
continue
for index in index_set:
covered_indexes.add(index)
masked_token = None
# 80% of the time, replace with [MASK]
if rng.random() < 0.8:
masked_token = "[MASK]"
else:
# 10% of the time, keep original
if rng.random() < 0.5:
masked_token = tokens[index]
# 10% of the time, replace with random word
else:
masked_token = vocab_words[rng.randint(0, len(vocab_words) - 1)]
output_tokens[index] = masked_token
masked_lms.append(MaskedLmInstance(index=index, label=tokens[index]))
assert len(masked_lms) <= num_to_predict
masked_lms = sorted(masked_lms, key=lambda x: x.index)
masked_lm_positions = []
masked_lm_labels = []
for p in masked_lms:
masked_lm_positions.append(p.index)
masked_lm_labels.append(p.label)
return (output_tokens, masked_lm_positions, masked_lm_labels)
首先记录在NSP阶段生成的tokens序列中每个token(除了[CLS]与[SEP])的位置信息([[1],[2],…,[8],[10],[11,12,13],…],mask时考虑了整词mask的情况),接着随机打乱位置信息,复制一份mask前的tokens序列信息到output_tokens中,确定在该tokens序列中要预测的token的个数(num_to_predict,大概占总tokens数的15%)。然后顺序遍历被打乱的位置,对每个位置的token进行mask操作并记录被mask的位置信息和mask前的token值,其中有80%的概率该token被替换成’[mask]’,10%的概率该token被替换成自己(保持不变),10%的概率该token被替换成词表中的任一token。 直到被mask的token数大于等于设定值num_to_predict。最后将所有被mask的token按位置信息升序排序后,返回mask后的整个序列、被mask的位置及mask前的token。
以上为masked LM任务对应的数据预处理的细节。
最后将生成的与NSP和masked LM相关的特征赋值给TrainingInstance对象对应属性 (tokens,segment_ids,is_random_next,masked_lm_positions,masked_lm_labels) ,形成最终的 instance。
至此,梳理完了从原始的.txt的语料生成由TrainingInstance对象组成的list的过程。
最后看下如何将上述的list写入到.tfrecord格式的文件中。具体代码如下:
def write_instance_to_example_files(instances, tokenizer, max_seq_length,
max_predictions_per_seq, output_files):
"""Create TF example files from `TrainingInstance`s."""
writers = []
for output_file in output_files:
writers.append(tf.python_io.TFRecordWriter(output_file))
writer_index = 0
total_written = 0
for (inst_index, instance) in enumerate(instances):
input_ids = tokenizer.convert_tokens_to_ids(instance.tokens)
input_mask = [1] * len(input_ids)
segment_ids = list(instance.segment_ids)
assert len(input_ids) <= max_seq_length
while len(input_ids) < max_seq_length:
input_ids.append(0)
input_mask.append(0)
segment_ids.append(0)
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
masked_lm_positions = list(instance.masked_lm_positions)
masked_lm_ids = tokenizer.convert_tokens_to_ids(instance.masked_lm_labels)
masked_lm_weights = [1.0] * len(masked_lm_ids)
while len(masked_lm_positions) < max_predictions_per_seq:
masked_lm_positions.append(0)
masked_lm_ids.append(0)
masked_lm_weights.append(0.0)
next_sentence_label = 1 if instance.is_random_next else 0
features = collections.OrderedDict()
features["input_ids"] = create_int_feature(input_ids)
features["input_mask"] = create_int_feature(input_mask)
features["segment_ids"] = create_int_feature(segment_ids)
features["masked_lm_positions"] = create_int_feature(masked_lm_positions)
features["masked_lm_ids"] = create_int_feature(masked_lm_ids)
features["masked_lm_weights"] = create_float_feature(masked_lm_weights)
features["next_sentence_labels"] = create_int_feature([next_sentence_label])
tf_example = tf.train.Example(features=tf.train.Features(feature=features))
writers[writer_index].write(tf_example.SerializeToString())
writer_index = (writer_index + 1) % len(writers)
total_written += 1
if inst_index < 20:
tf.logging.info("*** Example ***")
tf.logging.info("tokens: %s" % " ".join(
[tokenization.printable_text(x) for x in instance.tokens]))
for feature_name in features.keys():
feature = features[feature_name]
values = []
if feature.int64_list.value:
values = feature.int64_list.value
elif feature.float_list.value:
values = feature.float_list.value
tf.logging.info(
"%s: %s" % (feature_name, " ".join([str(x) for x in values])))
for writer in writers:
writer.close()
tf.logging.info("Wrote %d total instances", total_written)
首先根据不同的输出文件路径,实例化多个不同的tf.python_io.TFRecordWriter对象。然后依次遍历instances列表中每个TrainingInstance对象,解析其相关属性值,保证input_ids、input_mask与segment_ids的长度等于max_seq_length,masked_lm_positions、masked_lm_ids与masked_lm_weights的长度等于max_predictions_per_seq。(不足补零) 将相关属性值统一放到features的字典(key:特征名,value:tf.train.Feature对象)中,将含多个特征属性值的字典传给tf.train.Example对象后,序列化到.tfrecord格式的文件中(此文件为预训练的输入文件),并打印前20个样本的相关特征值。
至此,从.txt的原始语料到.tfrecord格式的预训练的输入文件的转化梳理完成。
以下为预训练的运行脚本。
python run_pretraining.py \
--input_file=/tmp/tf_examples.tfrecord \
--output_dir=/tmp/pretraining_output \
--do_train=True \
--do_eval=True \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--train_batch_size=32 \
--max_seq_length=128 \
--max_predictions_per_seq=20 \
--num_train_steps=20 \
--num_warmup_steps=10 \
--learning_rate=2e-5
其中input_file为数据预处理部分生成的.tfrecord格式的文件路径;output_dir为预训练后生成的模型文件的路径;bert_config_file为(预训练)模型的配置文件;init_checkpoint为(预训练)模型的初始检查点,如果想要从头开始训练,那么不要此参数,一般都是在google预训练好的模型基础上微调,即模型相关的初始参数从ckpt文件中加载,除非自己有特别大的某一领域的语料;train_batch_size表示训练阶段每步中最多包含的样本数;max_seq_length表示每个样本中含有token个数的最大值,此值需与数据预处理部分保持一致,该参数类似于RNN中的最大时间步,每次可动态调整。针对某一特定领域的语料,可在通用的语言模型的基础上,每次通过设置不同长度的专业领域的句子对微调语言模型,使最终生成的预训练的语言模型更适合某一特定领域;max_predictions_per_seq表示每个序列中需要预测的token的最大个数,此值需与数据预处理部分保持一致;num_train_steps表示训练阶段的步数;num_warmup_steps表示学习率从0逐渐增加到初始学习率所需的步数,以后的步数保持固定学习率。
接着从源码角度重点分析下预训练模块中BERT模型的内部结构。
首先看下如何从输入的.tfrecord文件中解析出BERT需要的输入数据。代码如下:
def input_fn_builder(input_files,
max_seq_length,
max_predictions_per_seq,
is_training,
num_cpu_threads=4):
"""Creates an `input_fn` closure to be passed to TPUEstimator."""
def input_fn(params):
"""The actual input function."""
batch_size = params["batch_size"]
name_to_features = {
"input_ids":
tf.FixedLenFeature([max_seq_length], tf.int64),
"input_mask":
tf.FixedLenFeature([max_seq_length], tf.int64),
"segment_ids":
tf.FixedLenFeature([max_seq_length], tf.int64),
"masked_lm_positions":
tf.FixedLenFeature([max_predictions_per_seq], tf.int64),
"masked_lm_ids":
tf.FixedLenFeature([max_predictions_per_seq], tf.int64),
"masked_lm_weights":
tf.FixedLenFeature([max_predictions_per_seq], tf.float32),
"next_sentence_labels":
tf.FixedLenFeature([1], tf.int64),
}
# For training, we want a lot of parallel reading and shuffling.
# For eval, we want no shuffling and parallel reading doesn't matter.
if is_training:
tf.logging.info(f'input_files---:{input_files}')
tf.logging.info(f'tf.constant(input_files)---:{tf.constant(input_files)}')
d = tf.data.Dataset.from_tensor_slices(tf.constant(input_files)) # ???
d = d.repeat()
d = d.shuffle(buffer_size=len(input_files))
# `cycle_length` is the number of parallel files that get read.
cycle_length = min(num_cpu_threads, len(input_files))
# `sloppy` mode means that the interleaving is not exact. This adds
# even more randomness to the training pipeline.
d = d.apply(
tf.contrib.data.parallel_interleave(
tf.data.TFRecordDataset,
sloppy=is_training,
cycle_length=cycle_length))
d = d.shuffle(buffer_size=100)
else:
d = tf.data.TFRecordDataset(input_files)
# Since we evaluate for a fixed number of steps we don't want to encounter
# out-of-range exceptions.
d = d.repeat()
# We must `drop_remainder` on training because the TPU requires fixed
# size dimensions. For eval, we assume we are evaluating on the CPU or GPU
# and we *don't* want to drop the remainder, otherwise we wont cover
# every sample.
d = d.apply(
tf.contrib.data.map_and_batch(
lambda record: _decode_record(record, name_to_features),
batch_size=batch_size,
num_parallel_batches=num_cpu_threads,
drop_remainder=True))
return d
return input_fn
以上代码将.tfrecord文件加载成dataset的对象,接着利用其固有方法进行repeat、shuffle操作后,再利用其map_and_batch方法先将数据集中序列化的Example对象解码成由各个feature组成的features字典,然后将解析后的值分成多组batch,作为模型的输入数据(model_fn中的features)。
接着重点看下模型的内部结构。从宏观上看,其主要有三部分:embeddings、encoder和输出。其中embeddings包括word_embeddings、token_type_embeddings(segment_embeddings)和position_embeddings三部分;encoder部分由num_hidden_layers(12)个Transformer Encoders堆叠而成;输出部分由两种形式,一种是输出最后一层(Transformer) Encoder的sequence_output(形状为[batch_size, seq_length, hidden_size],token级别的embedding),这个输出用于masked LM任务的训练。另一种是取sequence_output中的第一个token,然后接一个带有tanh的激活函数的全连接层作为输出(形状为[batch_size, hidden_size],句级别的embedding),此输出用于NSP任务的训练。 上述三部分宏观代码如下:
class BertModel(object):
"""BERT model ("Bidirectional Encoder Representations from Transformers").
Example usage:
```python
# Already been converted into WordPiece token ids
input_ids = tf.constant([[31, 51, 99], [15, 5, 0]])
input_mask = tf.constant([[1, 1, 1], [1, 1, 0]])
token_type_ids = tf.constant([[0, 0, 1], [0, 2, 0]])
config = modeling.BertConfig(vocab_size=32000, hidden_size=512,
num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
model = modeling.BertModel(config=config, is_training=True,
input_ids=input_ids, input_mask=input_mask, token_type_ids=token_type_ids)
label_embeddings = tf.get_variable(...)
pooled_output = model.get_pooled_output()
logits = tf.matmul(pooled_output, label_embeddings)
...
"""
def __init__(self,
config,
is_training,
input_ids,
input_mask=None,
token_type_ids=None,
use_one_hot_embeddings=False,
scope=None):
"""Constructor for BertModel.
Args:
config: `BertConfig` instance.
is_training: bool. true for training model, false for eval model. Controls
whether dropout will be applied.
input_ids: int32 Tensor of shape [batch_size, seq_length].
input_mask: (optional) int32 Tensor of shape [batch_size, seq_length].
token_type_ids: (optional) int32 Tensor of shape [batch_size, seq_length]. <==> segment id
use_one_hot_embeddings: (optional) bool. Whether to use one-hot word
embeddings or tf.embedding_lookup() for the word embeddings.
scope: (optional) variable scope. Defaults to "bert".
Raises:
ValueError: The config is invalid or one of the input tensor shapes
is invalid.
"""
config = copy.deepcopy(config)
if not is_training:
config.hidden_dropout_prob = 0.0
config.attention_probs_dropout_prob = 0.0
input_shape = get_shape_list(input_ids, expected_rank=2)
batch_size = input_shape[0]
seq_length = input_shape[1]
if input_mask is None:
input_mask = tf.ones(shape=[batch_size, seq_length], dtype=tf.int32)
if token_type_ids is None:
token_type_ids = tf.zeros(shape=[batch_size, seq_length], dtype=tf.int32)
with tf.variable_scope(scope, default_name="bert"):
with tf.variable_scope("embeddings"):
# Perform embedding lookup on the word ids.
(self.embedding_output, self.embedding_table) = embedding_lookup(
input_ids=input_ids,
vocab_size=config.vocab_size,
embedding_size=config.hidden_size,
initializer_range=config.initializer_range,
word_embedding_name="word_embeddings",
use_one_hot_embeddings=use_one_hot_embeddings)
# Add positional embeddings and token type embeddings, then layer
# normalize and perform dropout.
self.embedding_output = embedding_postprocessor(
input_tensor=self.embedding_output,
use_token_type=True,
token_type_ids=token_type_ids,
token_type_vocab_size=config.type_vocab_size,
token_type_embedding_name="token_type_embeddings",
use_position_embeddings=True,
position_embedding_name="position_embeddings",
initializer_range=config.initializer_range,
max_position_embeddings=config.max_position_embeddings,
dropout_prob=config.hidden_dropout_prob)
with tf.variable_scope("encoder"):
# This converts a 2D mask of shape [batch_size, seq_length] to a 3D
# mask of shape [batch_size, seq_length, seq_length] which is used
# for the attention scores.
attention_mask = create_attention_mask_from_input_mask(
input_ids, input_mask)
# Run the stacked transformer.
# `sequence_output` shape = [batch_size, seq_length, hidden_size].
self.all_encoder_layers = transformer_model(
input_tensor=self.embedding_output,
attention_mask=attention_mask,
hidden_size=config.hidden_size,
num_hidden_layers=config.num_hidden_layers,
num_attention_heads=config.num_attention_heads,
intermediate_size=config.intermediate_size,
intermediate_act_fn=get_activation(config.hidden_act),
hidden_dropout_prob=config.hidden_dropout_prob,
attention_probs_dropout_prob=config.attention_probs_dropout_prob,
initializer_range=config.initializer_range,
do_return_all_layers=True)
self.sequence_output = self.all_encoder_layers[-1]
# The "pooler" converts the encoded sequence tensor of shape
# [batch_size, seq_length, hidden_size] to a tensor of shape
# [batch_size, hidden_size]. This is necessary for segment-level
# (or segment-pair-level) classification tasks where we need a fixed
# dimensional representation of the segment.
with tf.variable_scope("pooler"):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token. We assume that this has been pre-trained
first_token_tensor = tf.squeeze(self.sequence_output[:, 0:1, :], axis=1)
self.pooled_output = tf.layers.dense(
first_token_tensor,
config.hidden_size,
activation=tf.tanh,
kernel_initializer=create_initializer(config.initializer_range))
论文中给出了预训练的模型在不同任务上的示意图:
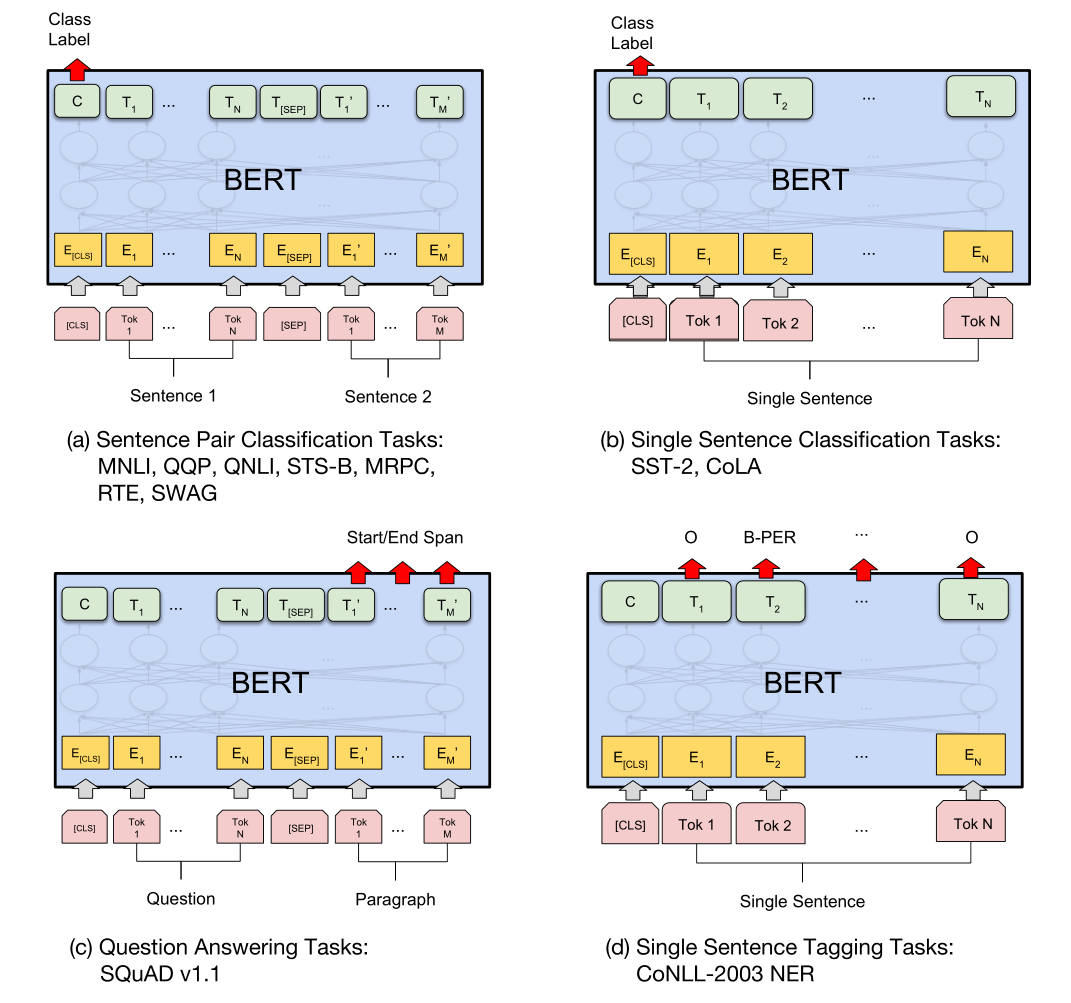
其中(a)、(b)(a)、(b)为句子级别的任务,输出端的第一个token表示句子(/句子对)的embedding,即输入的[CLS]对应的输出。 (c)、(d)(c)、(d)为token级别的任务,输出端每一个位置的embedding与输入端各位置相对应。
下面重点看下embeddings和encoder部分的内部结构。
embeddings部分的embedding_lookup主要用来生成词表中每个token的向量表示,同时将[batch_size, seq_length]的input_ids转换成形状为[batch_size,seq_length,embedding_size]的word_embeddings形式。具体代码如下(embedding_table为模型待学习参数):
def embedding_lookup(input_ids,
vocab_size,
embedding_size=128,
initializer_range=0.02,
word_embedding_name="word_embeddings",
use_one_hot_embeddings=False):
"""Looks up words embeddings for id tensor.
Args:
input_ids: int32 Tensor of shape [batch_size, seq_length] containing word
ids.
vocab_size: int. Size of the embedding vocabulary.
embedding_size: int. Width of the word embeddings.
initializer_range: float. Embedding initialization range.
word_embedding_name: string. Name of the embedding table.
use_one_hot_embeddings: bool. If True, use one-hot method for word
embeddings. If False, use `tf.gather()`.
Returns:
float Tensor of shape [batch_size, seq_length, embedding_size].
"""
# This function assumes that the input is of shape [batch_size, seq_length,
# num_inputs].
#
# If the input is a 2D tensor of shape [batch_size, seq_length], we
# reshape to [batch_size, seq_length, 1].
if input_ids.shape.ndims == 2:
input_ids = tf.expand_dims(input_ids, axis=[-1])
embedding_table = tf.get_variable(
name=word_embedding_name,
shape=[vocab_size, embedding_size],
initializer=create_initializer(initializer_range))
flat_input_ids = tf.reshape(input_ids, [-1]) # [batch_size*seq_length]
if use_one_hot_embeddings:
one_hot_input_ids = tf.one_hot(flat_input_ids, depth=vocab_size)
output = tf.matmul(one_hot_input_ids, embedding_table)
else:
output = tf.gather(embedding_table, flat_input_ids) # [batch_size*seq_length,embedding_size]
input_shape = get_shape_list(input_ids)
output = tf.reshape(output,
input_shape[0:-1] + [input_shape[-1] * embedding_size]) # [batch_size,seq_length,embedding_size]
return (output, embedding_table)
embeddings部分的embedding_postprocessor主要是在word_embeddings的基础上增加segment_id和position信息,最后将叠加后embedding分别进行layer_norm(对每个样本的不同维度进行归一化操作,而batch_norm则是对不同样本的同一特征进行归一化操作)和dropout(一个张量中某几个位置的值变成0)操作。具体代码如下(full_position_embeddings与full_position_embeddings为模型待学习参数):
def embedding_postprocessor(input_tensor,
use_token_type=False,
token_type_ids=None,
token_type_vocab_size=16,
token_type_embedding_name="token_type_embeddings",
use_position_embeddings=True,
position_embedding_name="position_embeddings",
initializer_range=0.02,
max_position_embeddings=512,
dropout_prob=0.1):
"""Performs various post-processing on a word embedding tensor.
Args:
input_tensor: float Tensor of shape [batch_size, seq_length,
embedding_size].
use_token_type: bool. Whether to add embeddings for `token_type_ids`.
token_type_ids: (optional) int32 Tensor of shape [batch_size, seq_length].
Must be specified if `use_token_type` is True.
token_type_vocab_size: int. The vocabulary size of `token_type_ids`.
token_type_embedding_name: string. The name of the embedding table variable
for token type ids.
use_position_embeddings: bool. Whether to add position embeddings for the
position of each token in the sequence.
position_embedding_name: string. The name of the embedding table variable
for positional embeddings.
initializer_range: float. Range of the weight initialization.
max_position_embeddings: int. Maximum sequence length that might ever be
used with this model. This can be longer than the sequence length of
input_tensor, but cannot be shorter.
dropout_prob: float. Dropout probability applied to the final output tensor.
Returns:
float tensor with same shape as `input_tensor`.
Raises:
ValueError: One of the tensor shapes or input values is invalid.
"""
input_shape = get_shape_list(input_tensor, expected_rank=3)
batch_size = input_shape[0]
seq_length = input_shape[1]
width = input_shape[2]
output = input_tensor # [batch_size, seq_length,embedding_size]
if use_token_type:
if token_type_ids is None:
raise ValueError("`token_type_ids` must be specified if"
"`use_token_type` is True.")
token_type_table = tf.get_variable(
name=token_type_embedding_name,
shape=[token_type_vocab_size, width],
initializer=create_initializer(initializer_range))
# This vocab will be small so we always do one-hot here, since it is always
# faster for a small vocabulary.
flat_token_type_ids = tf.reshape(token_type_ids, [-1]) # [batch_size, seq_length] --> [batch_size*seq_length]
one_hot_ids = tf.one_hot(flat_token_type_ids, depth=token_type_vocab_size) # [batch_size*seq_length,token_type_vocab_size]
token_type_embeddings = tf.matmul(one_hot_ids, token_type_table)
token_type_embeddings = tf.reshape(token_type_embeddings,
[batch_size, seq_length, width])
output += token_type_embeddings
if use_position_embeddings:
assert_op = tf.assert_less_equal(seq_length, max_position_embeddings)
with tf.control_dependencies([assert_op]):
full_position_embeddings = tf.get_variable(
name=position_embedding_name,
shape=[max_position_embeddings, width],
initializer=create_initializer(initializer_range))
# Since the position embedding table is a learned variable, we create it
# using a (long) sequence length `max_position_embeddings`. The actual
# sequence length might be shorter than this, for faster training of
# tasks that do not have long sequences.
#
# So `full_position_embeddings` is effectively an embedding table
# for position [0, 1, 2, ..., max_position_embeddings-1], and the current
# sequence has positions [0, 1, 2, ... seq_length-1], so we can just
# perform a slice.
position_embeddings = tf.slice(full_position_embeddings, [0, 0],
[seq_length, -1]) # [max_position_embeddings, width] --> [seq_length, width]
num_dims = len(output.shape.as_list()) # [batch_size, seq_length,embedding_size]
# Only the last two dimensions are relevant (`seq_length` and `width`), so
# we broadcast among the first dimensions, which is typically just
# the batch size.
position_broadcast_shape = []
for _ in range(num_dims - 2):
position_broadcast_shape.append(1)
position_broadcast_shape.extend([seq_length, width]) # [1,seq_length,width]
position_embeddings = tf.reshape(position_embeddings,
position_broadcast_shape)
output += position_embeddings
output = layer_norm_and_dropout(output, dropout_prob)
return output
论文中关于embedding部分的示意图如下:
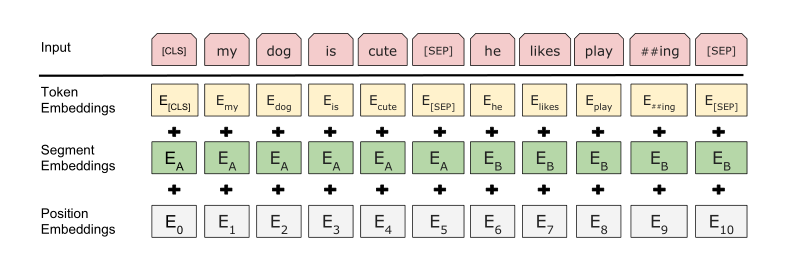
至此embeddings部分的结构介绍完毕。
接着看下encoder部分,其是BERT模型的核心。上述embeddings部分的最终输出作为第一层的transformer encoder (block)的输入。
而一个transformer encoder (block)由多头注意层(共有hidden_size个单元)和前馈神经网络层(有激活函数的dense层,共有intermediate_size个单元,约定有如下关系intermediate_size=4*hidden_size)两个子层构成。其中每个子层的输出分别进行线性投影(没有激活函数的dense层)、dropout、Resnet(残差,输入与输出直接相加)与layer_norm操作。
前馈神经网络层的输出经layer_norm后的输出为一个transformer encoder (block)的最终输出,保存该输出并将其作为下一个transformer encoder (block)的输入。循环上述过程num_hidden_layers次(堆叠num_hidden_layers个transformer encoder (block)),形成最终encoder部分的输出。值得说明的是,上述数据转换过程都是2D的。 以上描述的整个过程可看作一个transformer model,其简易示意图与具体代码分别如下:
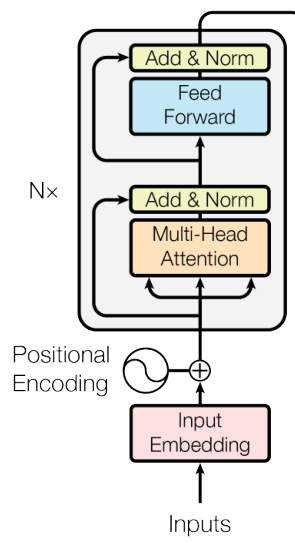
def transformer_model(input_tensor,
attention_mask=None,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
intermediate_act_fn=gelu,
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
initializer_range=0.02,
do_return_all_layers=False):
"""Multi-headed, multi-layer Transformer from "Attention is All You Need".
This is almost an exact implementation of the original Transformer encoder.
See the original paper:
https://arxiv.org/abs/1706.03762
Also see:
https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/transformer.py
Args:
input_tensor: float Tensor of shape [batch_size, seq_length, hidden_size].
attention_mask: (optional) int32 Tensor of shape [batch_size, seq_length,
seq_length], with 1 for positions that can be attended to and 0 in
positions that should not be.
hidden_size: int. Hidden size of the Transformer.
num_hidden_layers: int. Number of layers (blocks) in the Transformer.
num_attention_heads: int. Number of attention heads in the Transformer.
intermediate_size: int. The size of the "intermediate" (a.k.a., feed
forward) layer.
intermediate_act_fn: function. The non-linear activation function to apply
to the output of the intermediate/feed-forward layer.
hidden_dropout_prob: float. Dropout probability for the hidden layers.
attention_probs_dropout_prob: float. Dropout probability of the attention
probabilities.
initializer_range: float. Range of the initializer (stddev of truncated
normal).
do_return_all_layers: Whether to also return all layers or just the final
layer.
Returns:
float Tensor of shape [batch_size, seq_length, hidden_size], the final
hidden layer of the Transformer.
Raises:
ValueError: A Tensor shape or parameter is invalid.
"""
if hidden_size % num_attention_heads != 0:
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (hidden_size, num_attention_heads))
attention_head_size = int(hidden_size / num_attention_heads)
input_shape = get_shape_list(input_tensor, expected_rank=3)
batch_size = input_shape[0]
seq_length = input_shape[1]
input_width = input_shape[2]
# The Transformer performs sum residuals on all layers so the input needs
# to be the same as the hidden size.
if input_width != hidden_size:
raise ValueError("The width of the input tensor (%d) != hidden size (%d)" %
(input_width, hidden_size))
# We keep the representation as a 2D tensor to avoid re-shaping it back and
# forth from a 3D tensor to a 2D tensor. Re-shapes are normally free on
# the GPU/CPU but may not be free on the TPU, so we want to minimize them to
# help the optimizer.
prev_output = reshape_to_matrix(input_tensor)
all_layer_outputs = []
for layer_idx in range(num_hidden_layers):
with tf.variable_scope("layer_%d" % layer_idx):
layer_input = prev_output
with tf.variable_scope("attention"):
attention_heads = []
with tf.variable_scope("self"):
attention_head = attention_layer( # [B*F, N*H] / [B, F, N*H]
from_tensor=layer_input,
to_tensor=layer_input,
attention_mask=attention_mask,
num_attention_heads=num_attention_heads,
size_per_head=attention_head_size,
attention_probs_dropout_prob=attention_probs_dropout_prob,
initializer_range=initializer_range,
do_return_2d_tensor=True,
batch_size=batch_size,
from_seq_length=seq_length,
to_seq_length=seq_length)
attention_heads.append(attention_head)
attention_output = None
if len(attention_heads) == 1:
attention_output = attention_heads[0]
else: # ??? 什么情况没想到啊。。。先不考率
# In the case where we have other sequences, we just concatenate
# them to the self-attention head before the projection.
attention_output = tf.concat(attention_heads, axis=-1)
# Run a linear projection of `hidden_size` then add a residual
# with `layer_input`.
with tf.variable_scope("output"):
attention_output = tf.layers.dense(
attention_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
attention_output = dropout(attention_output, hidden_dropout_prob)
attention_output = layer_norm(attention_output + layer_input)
# The activation is only applied to the "intermediate" hidden layer.
with tf.variable_scope("intermediate"):
intermediate_output = tf.layers.dense(
attention_output,
intermediate_size,
activation=intermediate_act_fn,
kernel_initializer=create_initializer(initializer_range))
# Down-project back to `hidden_size` then add the residual.
with tf.variable_scope("output"):
layer_output = tf.layers.dense(
intermediate_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
layer_output = dropout(layer_output, hidden_dropout_prob)
layer_output = layer_norm(layer_output + attention_output)
prev_output = layer_output
all_layer_outputs.append(layer_output)
if do_return_all_layers:
final_outputs = []
for layer_output in all_layer_outputs:
final_output = reshape_from_matrix(layer_output, input_shape)
final_outputs.append(final_output)
return final_outputs
else:
final_output = reshape_from_matrix(prev_output, input_shape)
return final_output
其中多头注意层(attention_layer)是transformer encoder (block)的核心,该层从from_tensor到to_tensor进行多头注意的计算(当from_tensor和to_tensor是同一个序列时,称为自注意)。相关流程如下: attention_layer首先将from_tensor投影成query张量,将to_tensor投影成key、value张量。其中query、key和value是由num_attention_heads个张量组成的list,每个张量的形状为[batch_size, seq_length, size_per_head]。然后将映射后的query和key张量进行相应变换后,计算注意力得分,并缩放(防止数值过大,有利于梯度计算)。接着利用attention_mask(根据input_ids(from_tensor)与input_mask(to_mask)进行计算的。 由0,1组成的mask张量,表示一个batch的每一个序列(from_tensor)中的每一个token(用1表示)与另一序列(to_mask)中的哪些token有关联,1表示有关联,0表示无关联)进一步对缩放后的注意力得分张量进行变换(关注的位置相应得分不变,不关注的位置得分变低)后,利用softmax操作将得分变成注意力概率值(0-1之间的权重),并进行dropout操作得到最终的权重值张量。最后利用得到的权重张量与初始的value张量得到attention_layer的输出context_layer。
由上述分析可知,多头注意力是在原有tensor的基础上进行投影、转置、变形等操作完成计算的。相关代码如下:
def attention_layer(from_tensor,
to_tensor,
attention_mask=None,
num_attention_heads=1,
size_per_head=512,
query_act=None,
key_act=None,
value_act=None,
attention_probs_dropout_prob=0.0,
initializer_range=0.02,
do_return_2d_tensor=False,
batch_size=None,
from_seq_length=None,
to_seq_length=None):
"""Performs multi-headed attention from `from_tensor` to `to_tensor`.
This is an implementation of multi-headed attention based on "Attention
is all you Need". If `from_tensor` and `to_tensor` are the same, then
this is self-attention. Each timestep in `from_tensor` attends to the
corresponding sequence in `to_tensor`, and returns a fixed-with vector.
This function first projects `from_tensor` into a "query" tensor and
`to_tensor` into "key" and "value" tensors. These are (effectively) a list
of tensors of length `num_attention_heads`, where each tensor is of shape
[batch_size, seq_length, size_per_head].
Then, the query and key tensors are dot-producted and scaled. These are
softmaxed to obtain attention probabilities. The value tensors are then
interpolated by these probabilities, then concatenated back to a single
tensor and returned.
In practice, the multi-headed attention are done with transposes and
reshapes rather than actual separate tensors.
Args:
from_tensor: float Tensor of shape [batch_size, from_seq_length,
from_width].
to_tensor: float Tensor of shape [batch_size, to_seq_length, to_width].
attention_mask: (optional) int32 Tensor of shape [batch_size,
from_seq_length, to_seq_length]. The values should be 1 or 0. The
attention scores will effectively be set to -infinity for any positions in
the mask that are 0, and will be unchanged for positions that are 1.
num_attention_heads: int. Number of attention heads.
size_per_head: int. Size of each attention head.
query_act: (optional) Activation function for the query transform.
key_act: (optional) Activation function for the key transform.
value_act: (optional) Activation function for the value transform.
attention_probs_dropout_prob: (optional) float. Dropout probability of the
attention probabilities.
initializer_range: float. Range of the weight initializer.
do_return_2d_tensor: bool. If True, the output will be of shape [batch_size
* from_seq_length, num_attention_heads * size_per_head]. If False, the
output will be of shape [batch_size, from_seq_length, num_attention_heads
* size_per_head].
batch_size: (Optional) int. If the input is 2D, this might be the batch size
of the 3D version of the `from_tensor` and `to_tensor`.
from_seq_length: (Optional) If the input is 2D, this might be the seq length
of the 3D version of the `from_tensor`.
to_seq_length: (Optional) If the input is 2D, this might be the seq length
of the 3D version of the `to_tensor`.
Returns:
float Tensor of shape [batch_size, from_seq_length,
num_attention_heads * size_per_head]. (If `do_return_2d_tensor` is
true, this will be of shape [batch_size * from_seq_length,
num_attention_heads * size_per_head]).
Raises:
ValueError: Any of the arguments or tensor shapes are invalid.
"""
def transpose_for_scores(input_tensor, batch_size, num_attention_heads,
seq_length, width):
output_tensor = tf.reshape(
input_tensor, [batch_size, seq_length, num_attention_heads, width])
output_tensor = tf.transpose(output_tensor, [0, 2, 1, 3])
return output_tensor
from_shape = get_shape_list(from_tensor, expected_rank=[2, 3])
to_shape = get_shape_list(to_tensor, expected_rank=[2, 3])
if len(from_shape) != len(to_shape):
raise ValueError(
"The rank of `from_tensor` must match the rank of `to_tensor`.")
if len(from_shape) == 3:
batch_size = from_shape[0]
from_seq_length = from_shape[1]
to_seq_length = to_shape[1]
elif len(from_shape) == 2:
if (batch_size is None or from_seq_length is None or to_seq_length is None):
raise ValueError(
"When passing in rank 2 tensors to attention_layer, the values "
"for `batch_size`, `from_seq_length`, and `to_seq_length` "
"must all be specified.")
# Scalar dimensions referenced here:
# B = batch size (number of sequences)
# F = `from_tensor` sequence length
# T = `to_tensor` sequence length
# N = `num_attention_heads`
# H = `size_per_head`
from_tensor_2d = reshape_to_matrix(from_tensor)
to_tensor_2d = reshape_to_matrix(to_tensor)
# `query_layer` = [B*F, N*H]
query_layer = tf.layers.dense(
from_tensor_2d,
num_attention_heads * size_per_head,
activation=query_act,
name="query",
kernel_initializer=create_initializer(initializer_range))
# `key_layer` = [B*T, N*H]
key_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=key_act,
name="key",
kernel_initializer=create_initializer(initializer_range))
# `value_layer` = [B*T, N*H]
value_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=value_act,
name="value",
kernel_initializer=create_initializer(initializer_range))
# `query_layer` = [B, N, F, H]
query_layer = transpose_for_scores(query_layer, batch_size,
num_attention_heads, from_seq_length,
size_per_head)
# `key_layer` = [B, N, T, H]
key_layer = transpose_for_scores(key_layer, batch_size, num_attention_heads,
to_seq_length, size_per_head)
# Take the dot product between "query" and "key" to get the raw
# attention scores.
# `attention_scores` = [B, N, F, T]
attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True)
attention_scores = tf.multiply(attention_scores,
1.0 / math.sqrt(float(size_per_head)))
if attention_mask is not None:
# `attention_mask` = [B, 1, F, T]
attention_mask = tf.expand_dims(attention_mask, axis=[1])
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and -10000.0 for masked positions.
adder = (1.0 - tf.cast(attention_mask, tf.float32)) * -10000.0
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
attention_scores += adder
# Normalize the attention scores to probabilities.
# `attention_probs` = [B, N, F, T]
attention_probs = tf.nn.softmax(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = dropout(attention_probs, attention_probs_dropout_prob)
# `value_layer` = [B, T, N, H]
value_layer = tf.reshape(
value_layer,
[batch_size, to_seq_length, num_attention_heads, size_per_head])
# `value_layer` = [B, N, T, H]
value_layer = tf.transpose(value_layer, [0, 2, 1, 3])
# `context_layer` = [B, N, F, H]
context_layer = tf.matmul(attention_probs, value_layer)
# `context_layer` = [B, F, N, H]
context_layer = tf.transpose(context_layer, [0, 2, 1, 3])
if do_return_2d_tensor:
# `context_layer` = [B*F, N*H]
context_layer = tf.reshape(
context_layer,
[batch_size * from_seq_length, num_attention_heads * size_per_head])
else:
# `context_layer` = [B, F, N*H]
context_layer = tf.reshape(
context_layer,
[batch_size, from_seq_length, num_attention_heads * size_per_head])
return context_layer
至此encoder部分的相关细节介绍完毕。
基于上述模型结构,可分别得到masked LM任务和NSP任务的预测输出,再结合输入文件中实际的输出,可分别得到相应的损失差值,将两个损失相加作为总的损失。
两个任务的本质都是分类任务,一个是二分类,即两个segment是否是连贯的;一个是多分类,即输入序列中被mask的token为词表中某个token的概率。它们的损失函数都是交叉熵损失。
相关代码如下:
def get_masked_lm_output(bert_config, input_tensor, output_weights, positions,
label_ids, label_weights):
"""Get loss and log probs for the masked LM.
input_tensor --> [batch_size, seq_length, hidden_size]
output_weights --> [vocab_size, embedding_size]
positions --> [batch_size, max_predictions_per_seq]
label_ids --> [batch_size, max_predictions_per_seq]
label_weights --> [batch_size, max_predictions_per_seq]
"""
tf.logging.info(f'get_masked_lm_output--positions:{positions}')
input_tensor = gather_indexes(input_tensor, positions) # [batch_size*max_predictions_per_seq, hidden_size]
with tf.variable_scope("cls/predictions"):
# We apply one more non-linear transformation before the output layer.
# This matrix is not used after pre-training.
with tf.variable_scope("transform"):
input_tensor = tf.layers.dense(
input_tensor,
units=bert_config.hidden_size,
activation=modeling.get_activation(bert_config.hidden_act),
kernel_initializer=modeling.create_initializer(
bert_config.initializer_range))
input_tensor = modeling.layer_norm(input_tensor) # [batch_size*max_predictions_per_seq, hidden_size]
# The output weights are the same as the input embeddings, but there is
# an output-only bias for each token.
output_bias = tf.get_variable(
"output_bias",
shape=[bert_config.vocab_size],
initializer=tf.zeros_initializer())
logits = tf.matmul(input_tensor, output_weights, transpose_b=True) # [batch_size*max_predictions_per_seq, vocab_size]
logits = tf.nn.bias_add(logits, output_bias)
log_probs = tf.nn.log_softmax(logits, axis=-1) # [batch_size*max_predictions_per_seq, vocab_size]
label_ids = tf.reshape(label_ids, [-1])
label_weights = tf.reshape(label_weights, [-1]) # [batch_size*max_predictions_per_seq]
one_hot_labels = tf.one_hot(
label_ids, depth=bert_config.vocab_size, dtype=tf.float32) # [batch_size*max_predictions_per_seq, vocab_size]
# The `positions` tensor might be zero-padded (if the sequence is too
# short to have the maximum number of predictions). The `label_weights`
# tensor has a value of 1.0 for every real prediction and 0.0 for the
# padding predictions.
per_example_loss = -tf.reduce_sum(log_probs * one_hot_labels, axis=[-1]) # 交叉熵 [flat_positions]
numerator = tf.reduce_sum(label_weights * per_example_loss)
denominator = tf.reduce_sum(label_weights) + 1e-5
loss = numerator / denominator
return (loss, per_example_loss, log_probs)
def get_next_sentence_output(bert_config, input_tensor, labels):
"""Get loss and log probs for the next sentence prediction.
input_tensor: [batch_size, hidden_size]
labels: [batch_size, 1]
"""
# Simple binary classification. Note that 0 is "next sentence" and 1 is
# "random sentence". This weight matrix is not used after pre-training.
with tf.variable_scope("cls/seq_relationship"):
output_weights = tf.get_variable(
"output_weights",
shape=[2, bert_config.hidden_size],
initializer=modeling.create_initializer(bert_config.initializer_range))
output_bias = tf.get_variable(
"output_bias", shape=[2], initializer=tf.zeros_initializer())
logits = tf.matmul(input_tensor, output_weights, transpose_b=True) # [batch_size, 2]
logits = tf.nn.bias_add(logits, output_bias) # [batch_size, 2]
log_probs = tf.nn.log_softmax(logits, axis=-1) # [batch_size, 2]
labels = tf.reshape(labels, [-1])
one_hot_labels = tf.one_hot(labels, depth=2, dtype=tf.float32) # [batch_size, 2]
per_example_loss = -tf.reduce_sum(one_hot_labels * log_probs, axis=-1) # 交叉熵 [batch_size]
loss = tf.reduce_mean(per_example_loss)
return (loss, per_example_loss, log_probs)
基于上述搭建好的模型结构及相应的损失函数,在训练阶段,利用相应的优化器(AdamWeightDecayOptimizer)优化损失函数,使其减小,并保存不同训练步数对应的模型参数,直到跑完所有步数,从而确定最终的模型结构与参数。由于BERT在预训练中使用了estimator这种高级API形式,在训练完成后会自动生成 ckpt格式的模型文件(结构和数据是分开的) 及可供tensorboard查看的事件文件。具体文件说明如下:
-
checkpoint : 记录了模型文件的路径信息列表,可以用来迅速查找最近一次的ckpt文件。(每个ckpt文件对应一个模型)其内容如下所示
model_checkpoint_path: "model.ckpt-20" all_model_checkpoint_paths: "model.ckpt-0" all_model_checkpoint_paths: "model.ckpt-20" -
events.out.tfevents.1570029823.04c93f97d224 :事件文件,tensorboard可加载显示
-
graph.pbtxt : 以Protobuffer格式描述的模型结构文件(text格式的图文件(.pbtext),二进制格式的图文件为(.pb)),记录了模型中所有的节点信息,内容大致如下:
node { name: "global_step/Initializer/zeros" op: "Const" attr { key: "_class" value { list { s: "loc:@global_step" } } } attr { key: "_output_shapes" value { list { shape { } } } } attr { key: "dtype" value { type: DT_INT64 } } attr { key: "value" value { tensor { dtype: DT_INT64 tensor_shape { } int64_val: 0 } } } } -
model.ckpt-20.data-00000-of-00001 : 模型文件中的数据(the values of all variables)部分 (二进制文件)
-
model.ckpt-20.index : 模型文件中的映射表( Each key is a name of a tensor and its value is a serialized BundleEntryProto. Each BundleEntryProto describes the metadata of a tensor: which of the “data” files contains the content of a tensor, the offset into that file, checksum, some auxiliary data, etc.)部分 (二进制文件)
-
model.ckpt-20.meta : 模型文件中的(图)结构(由GraphDef, SaverDef, MateInfoDef,SignatureDef,CollectionDef等组成的MetaGraphDef)部分 (二进制文件,内容和graph.pbtxt基本一样,其是一个序列化的MetaGraphDef protocol buffer)
在评估阶段,直接加载训练好的模型结构与参数,对预测样本进行预测即可。
下面解读下优化器(用来更新模型(权重)参数)部分。首先是学习率部分,将学习率设置为线性衰减的形式,接着根据global_step是否达到num_warmup_steps,在原来线性衰减的基础上将学习率进一步分成warmup_learning_rate和learning_rate两种方式。然后是优化器的构建。
先是实例化AdamWeightDecayOptimizer(其是梯度下降法的一种变种,也由待更新参数、学习率和参数更新方向三大要素组成),接着通过tvars = tf.trainable_variables()解析出模型中所有待训练的参数变量,并给出loss关于所有参数变量的梯度表示grads = tf.gradients(loss, tvars),同时限制梯度的大小。最后基于上述描述的梯度与变量,进行参数更新操作。更新时,依此遍历每一个待更新的参数,根据标准的Adam更新公式(参考Adam和学习率衰减(learning rate decay)),先确定参数更新方向,接着在方向的基础上增加衰减参数(这个操作叫纠正的L2 weight decay),然后在纠正后的方向上移动一定距离(learning_rate * update)后,更新现有的参数。 以上更新步骤随着训练步数不断进行,直到走完所有训练步数。相关代码如下:
def create_optimizer(loss, init_lr, num_train_steps, num_warmup_steps, use_tpu):
"""Creates an optimizer training op."""
global_step = tf.train.get_or_create_global_step()
learning_rate = tf.constant(value=init_lr, shape=[], dtype=tf.float32)
# Implements linear decay of the learning rate. 计算公式如下
'''
global_step = min(global_step, decay_steps)
decayed_learning_rate = (learning_rate - end_learning_rate) *
(1 - global_step / decay_steps) ^ (power) +
end_learning_rate
'''
learning_rate = tf.train.polynomial_decay(
learning_rate,
global_step,
num_train_steps,
end_learning_rate=0.0,
power=1.0,
cycle=False)
# Implements linear warmup. I.e., if global_step < num_warmup_steps, the
# learning rate will be `global_step/num_warmup_steps * init_lr`.
if num_warmup_steps:
global_steps_int = tf.cast(global_step, tf.int32)
warmup_steps_int = tf.constant(num_warmup_steps, dtype=tf.int32)
global_steps_float = tf.cast(global_steps_int, tf.float32)
warmup_steps_float = tf.cast(warmup_steps_int, tf.float32)
warmup_percent_done = global_steps_float / warmup_steps_float
warmup_learning_rate = init_lr * warmup_percent_done
is_warmup = tf.cast(global_steps_int < warmup_steps_int, tf.float32)
learning_rate = (
(1.0 - is_warmup) * learning_rate + is_warmup * warmup_learning_rate)
# It is recommended that you use this optimizer for fine tuning, since this
# is how the model was trained (note that the Adam m/v variables are NOT
# loaded from init_checkpoint.)
optimizer = AdamWeightDecayOptimizer(
learning_rate=learning_rate,
weight_decay_rate=0.01,
beta_1=0.9,
beta_2=0.999,
epsilon=1e-6,
exclude_from_weight_decay=["LayerNorm", "layer_norm", "bias"])
if use_tpu:
optimizer = tf.contrib.tpu.CrossShardOptimizer(optimizer)
tvars = tf.trainable_variables()
grads = tf.gradients(loss, tvars)
# This is how the model was pre-trained.
(grads, _) = tf.clip_by_global_norm(grads, clip_norm=1.0)
train_op = optimizer.apply_gradients(
zip(grads, tvars), global_step=global_step)
# Normally the global step update is done inside of `apply_gradients`.
# However, `AdamWeightDecayOptimizer` doesn't do this. But if you use
# a different optimizer, you should probably take this line out.
new_global_step = global_step + 1
train_op = tf.group(train_op, [global_step.assign(new_global_step)])
return train_op
class AdamWeightDecayOptimizer(tf.train.Optimizer):
"""A basic Adam optimizer that includes "correct" L2 weight decay."""
def __init__(self,
learning_rate,
weight_decay_rate=0.0,
beta_1=0.9,
beta_2=0.999,
epsilon=1e-6,
exclude_from_weight_decay=None,
name="AdamWeightDecayOptimizer"):
"""Constructs a AdamWeightDecayOptimizer."""
super(AdamWeightDecayOptimizer, self).__init__(False, name)
self.learning_rate = learning_rate
self.weight_decay_rate = weight_decay_rate
self.beta_1 = beta_1
self.beta_2 = beta_2
self.epsilon = epsilon
self.exclude_from_weight_decay = exclude_from_weight_decay
def apply_gradients(self, grads_and_vars, global_step=None, name=None):
"""See base class."""
assignments = []
for (grad, param) in grads_and_vars: # param:待更新参数
if grad is None or param is None:
continue
param_name = self._get_variable_name(param.name)
m = tf.get_variable(
name=param_name + "/adam_m",
shape=param.shape.as_list(),
dtype=tf.float32,
trainable=False,
initializer=tf.zeros_initializer())
v = tf.get_variable(
name=param_name + "/adam_v",
shape=param.shape.as_list(),
dtype=tf.float32,
trainable=False,
initializer=tf.zeros_initializer())
# Standard Adam update. 是梯度下降法的一种变种,可对比理解三个要素: 待更新参数、学习率、参数更新方向
next_m = (
tf.multiply(self.beta_1, m) + tf.multiply(1.0 - self.beta_1, grad))
next_v = (
tf.multiply(self.beta_2, v) + tf.multiply(1.0 - self.beta_2,
tf.square(grad)))
# 参数更新方向
update = next_m / (tf.sqrt(next_v) + self.epsilon)
# Just adding the square of the weights to the loss function is *not*
# the correct way of using L2 regularization/weight decay with Adam,
# since that will interact with the m and v parameters in strange ways.
#
# Instead we want to decay the weights in a manner that doesn't interact
# with the m/v parameters. This is equivalent to adding the square
# of the weights to the loss with plain (non-momentum) SGD.
if self._do_use_weight_decay(param_name):
update += self.weight_decay_rate * param
update_with_lr = self.learning_rate * update
next_param = param - update_with_lr
assignments.extend(
[param.assign(next_param),
m.assign(next_m),
v.assign(next_v)])
return tf.group(*assignments, name=name)
def _do_use_weight_decay(self, param_name):
"""Whether to use L2 weight decay for `param_name`."""
if not self.weight_decay_rate:
return False
if self.exclude_from_weight_decay:
for r in self.exclude_from_weight_decay:
if re.search(r, param_name) is not None:
return False
return True
def _get_variable_name(self, param_name):
"""Get the variable name from the tensor name."""
m = re.match("^(.*):\\d+$", param_name)
if m is not None:
param_name = m.group(1)
return param_name
至此,BERT的整个预训练过程算是梳理完成了。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK