

Bipartite Matching and Hungarian Algorithm
source link: https://senyang-ml.github.io/2020/06/01/Bipartite-Matching-and-Hungarian-Algorithm/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Bipartite Matching and Hungarian Algorithm
posted on 2020-06-01
二分图匹配和匈牙利算法(Bipartite Matching and Hungarian Algorithm)在CV领域的后处理算法中是经常可以看到的,比如以下的一些论文:
- 2017年的CVPR工作,OpenPose 利用bipartite matching 来进行,同关节类型的多个人体关键点分配到不同的隶属人体
- 2020年的End-to-end Object Detection with Transformer直接构造了一个Hungarian Loss,来解决预测目标与真实目标的分配问题
- 2020年CVPR Compressed Volumetric Heatmaps for Multi-Person 3D Pose Estimation中多人人体3D距离匹配算法
- 多目标跟踪领域内的,前后相邻帧匹配问题
- 在Instance Segmentation领域,这也是很常见的
顾名思义,二分图匹配是一个分配问题 (Assignment Problem)。
Hungarian Algorithm (匈牙利算法) 是在1955年提出的1 .
如果想要彻底理解它,需要先掌握它所涉及到的一些概念,作为先验知识。如下所示:
匈牙利算法
二分图的最大匹配
首先将我们遇到的问题转换成分配问题。我们的数据以一种二分图的数据结构呈现。
什么是二分图呢,它是一种特殊的图,即可以将图分为两组,两组内的节点之间没有连接边,两组之间节点存在连接关系。
我们的目标是寻找一个最大的匹配结果,使得匹配结果最合理。
比如说,我们想在一群男生和一群女生之间,根据他们各自喜欢的异性,找到一种能够成全更多对情侣的方案。又比如说,我们打算把工作项目,指派给员工们,希望用一种最大效率或者最低成本的方案。
最大匹配,即,在任意一个节点最多只有一个边与之相连接的条件下,尽可能使得两组之间的匹配边数最多。这就是我们的最优匹配目标,那么,如何求解出一种匹配方式,能够达到最大匹配呢?
最粗暴的算法就是暴力搜索,然而它的时间复杂度是指数级O(n!)
那有没有可以降低复杂度,并能够确定找到最优解的算法呢?
有,匈牙利算法就是!
匈牙利算法是一个什么算法呢?一种搜索算法,怎么样去搜索解呢?
其中,引入一种增广路的概念,它能在暴力搜索的过程中能够用一种简单的策略来改进当前匹配结果,直到我们无法找到更优的匹配。
增广路是什么意思呢,就是一种特殊的交错路,它从一个未匹配点出发,经过未匹配边、已匹配边、未匹配边,...,直到到达另外一个未匹配点,那么这样交换交错路径(匹配边和未匹配边),就总能改进匹配,因为增广路上的未匹配边总比匹配边多1个,交换就意味着改进,因为我们想要最多的匹配边。
基本概念讲完了。求解最大匹配问题的一个算法是匈牙利算法,下面讲的概念都为这个算法服务。
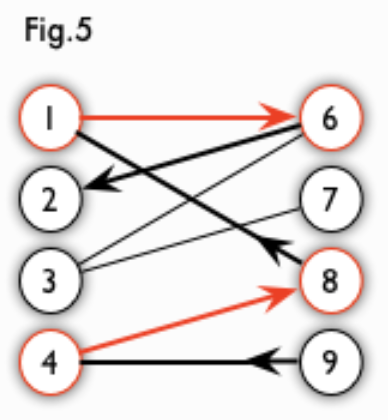
交替路:从一个未匹配点出发,依次经过非匹配边、匹配边、非匹配边…形成的路径叫交替路。
增广路:从一个未匹配点出发,走交替路,如果途径另一个未匹配点(出发的点不算),则这条交替路称为增广路(agumenting path)。例如,图 5 中的一条增广路如图 6 所示(图中的匹配点均用红色标出):
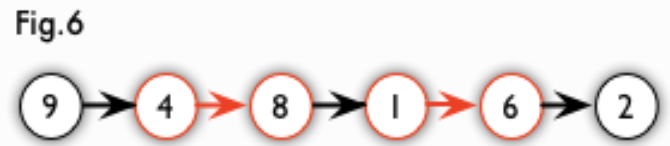
增广路有一个重要特点:非匹配边比匹配边多一条。因此,研究增广路的意义是改进匹配。只要把增广路中的匹配边和非匹配边的身份交换即可。由于中间的匹配节点不存在其他相连的匹配边,所以这样做不会破坏匹配的性质。交换后,图中的匹配边数目比原来多了 1 条。
我们可以通过不停地找增广路来增加匹配中的匹配边和匹配点。找不到增广路时,达到最大匹配(这是增广路定理)。匈牙利算法正是这么做的。在给出匈牙利算法 DFS 和 BFS 版本的代码之前,先讲一下匈牙利树。
匈牙利树一般由 BFS 构造(类似于 BFS 树)。从一个未匹配点出发运行 BFS(唯一的限制是,必须走交替路),直到不能再扩展为止。例如,由图 7,可以得到如图 8 的一棵 BFS 树:
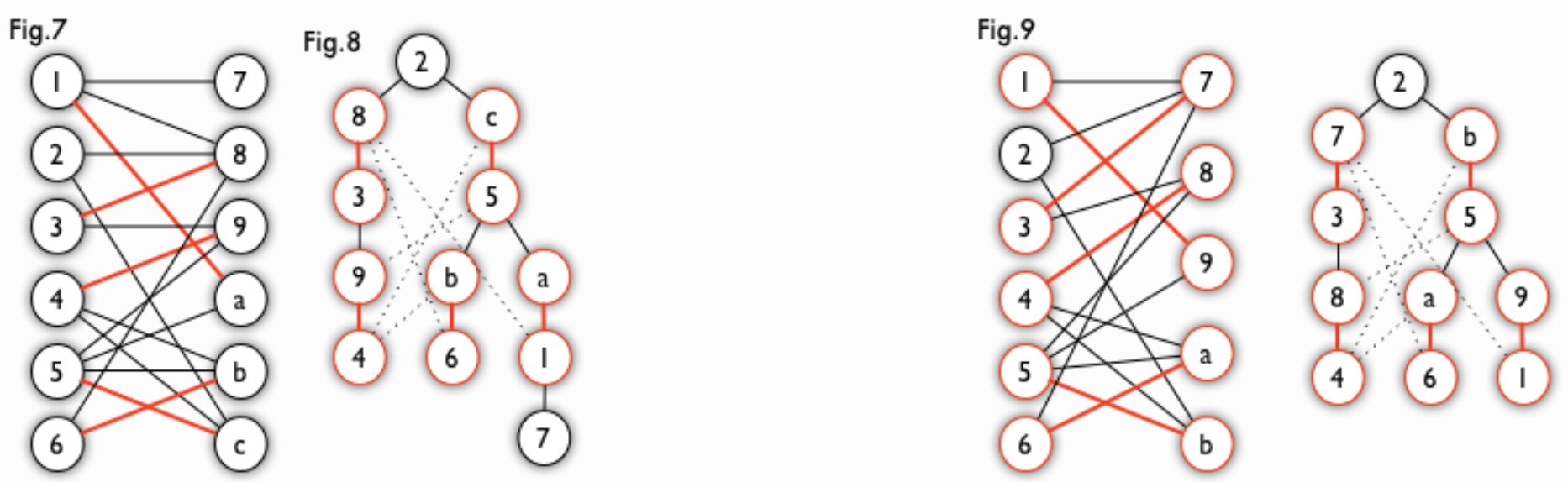 匈牙利树
匈牙利树这棵树存在一个叶子节点为非匹配点(7 号),但是匈牙利树要求所有叶子节点均为匹配点,因此这不是一棵匈牙利树。如果原图中根本不含 7 号节点,那么从 2 号节点出发就会得到一棵匈牙利树。这种情况如图 9 所示(顺便说一句,图 8 中根节点 2 到非匹配叶子节点 7 显然是一条增广路,沿这条增广路扩充后将得到一个完美匹配)。
Kuhn-Munkres算法(二分图最大权匹配)
在进入加权二分图之前,我们默认已经掌握了图、交错路径、增广路径、最大匹配和完美匹配的概念
上面探讨的二分图匹配问题中,任意两个节点之间,要么是有边的,要么是没有边。在很多情况下,节点之间的候选连接是有强度的,带权值的。
在这种情况下,整体最优的匹配是,我们希望找到一种方案(依然是一点至多只有一个边的条件)使得我们的成本最少或者权重和最大。
Kuhn-Munkres 算法的原理是什么呢?
先一言以蔽之
The KM theorem transforms the problem from an op- timization problem of finding a max-weight matching into a combinatorial one of finding a perfect match- ing. It combinatorializes the weights. This is a classic technique in combinatorial optimization. KM定理将问题从寻找最大权重匹配的优化问题转变为寻找完美匹配的组合问题。 它组合了权重。 这是组合优化中的经典技术。
如何转换的呢?
KM又引入了Feasible Labelings& Equality Graphs这两个概念
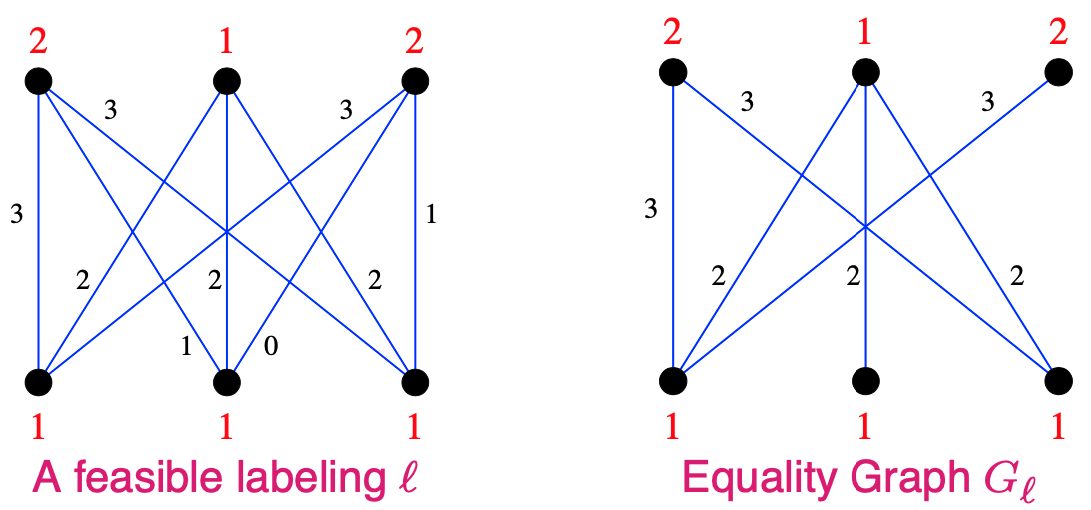
A vetex labeling is a function ℓ:V→R
A feasible labeling is one such that ℓ(x)+ℓ(y)≥w(x,y),∀x∈X,y∈Y
the Equality Graph (with respect to ℓ) is G=(V,Eℓ) where Eℓ={(x,y):ℓ(x)+ℓ(y)=w(x,y)}
理论与证明
Theorem[Kuhn-Munkres]: If ℓ is feasible and M is a Perfect matching in Eℓ then M is a max-weight matching.
如果能找到一个取值节点策略 ℓ:V→R ,使得满足Feasible Labelings & Equality Graphs 两个条件,就可以找到最大匹配
The KM theorem transforms the problem from an optimization problem of finding a max-weight matching into a combinatorial one of finding a perfect matching. It combinatorializes the weights. This is a classic technique in combinatorial optimization.
Notice that the proof of the KM theorem says that for any matching M and any feasible labeling ℓ we have w(M)≤∑v∈Vℓ(v) This has very strong echos of the max-flow min-cut theorem.
Proof:
只要证明:任意一个匹配解的权重和的上界都不大于 ∑v∈Vℓ(v)
Denote edge e∈E by e=(ex,ey) Let M′ be any PM in G (not necessarily in in Eℓ ). since every v∈V¯ is covered exactly once by M we have w(M′)=∑e∈M′w(e)≤∑e∈M′(ℓ(ex)+ℓ(ey))≤∑v∈Vℓ(v) so ∑v∈Vℓ(v) is an upper-bound on the cost of any perfect matching. Now let M be a PM in Eℓ. Then w(M)=∑e∈Mw(e)=∑v∈Vℓ(v) So w(M′)≤w(M) and M is optimal.
算法思路
This algorithm will be to Start with any feasible labeling ℓ and some matching M in Eℓ While M is not perfect repeat the following:
- Find an augmenting path for M in Eℓ this increases size of M
- If no augmenting path exists, improve ℓ to ℓ′ such that Eℓ⊂Eℓ′ Go to 1 Note that in each step of the loop we will either be increasing the size of M or Eℓ so this process must terminate.
Furthermore, when the process terminates, M will be a perfect matching in Eℓ for some feasible labeling ℓ So, by the Kuhn-Munkres theorem, M will be a maxweight matching.
1.Finding an Initial Feasible Labelling--其中一边端点为0,另一边取节点连接边权重的最大值
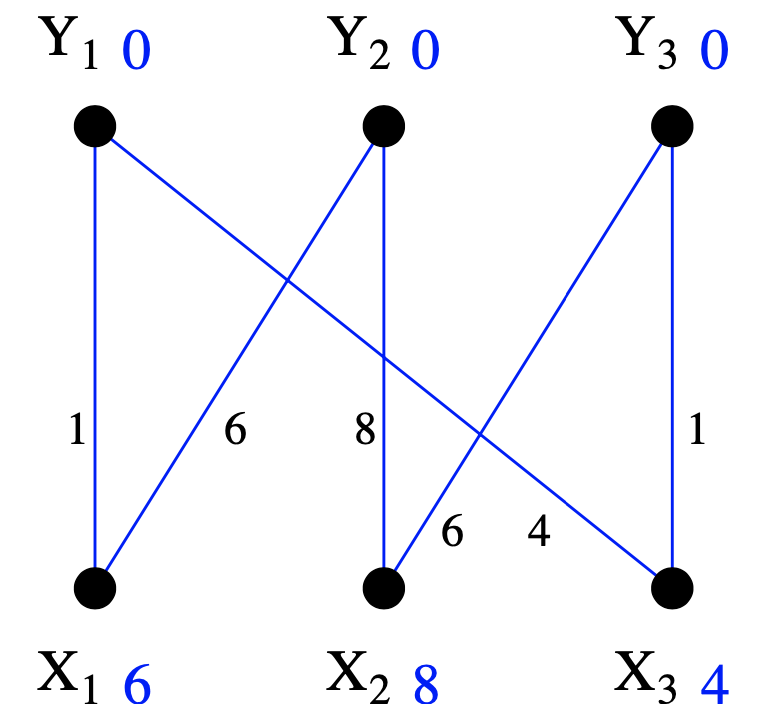
Finding an initial feasible labeling is simple. Just use:
∀y∈Y,ℓ(y)=0,∀x∈X,ℓ(x)=maxy∈Y{w(x,y)}
With this labelling it is obvious that
∀x∈X,y∈Y,w(x)≤ℓ(x)+ℓ(y)
2.Improving Labellings
这是初始labeling产生的equality graph的Eℓ,节点和边用红色标注了出来. Note: 这个时候红色的图,只能找到最大匹配,形成不了完美匹配
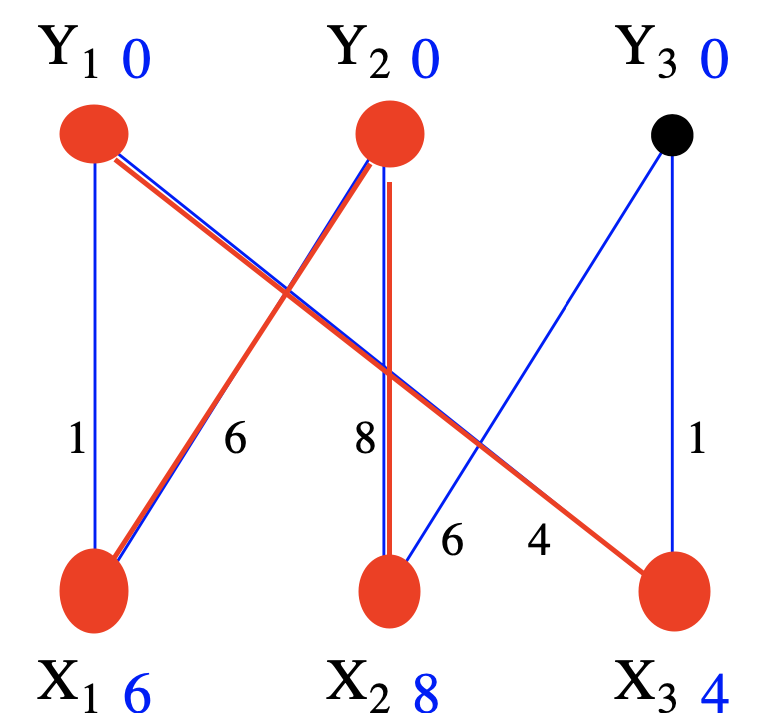
扩展Eℓ⊂Eℓ′ 的技巧
Let ℓ be a feasible labeling. Define neighbor of u∈V and setS⊆V to be Nℓ(u)={v:(u,v)∈Eℓ,},Nℓ(S)=∪u∈SNℓ(u) Lemma: Let S⊆X and T=Nℓ(S)≠Y. Set
Sen Yang Note:Bipartite graph:the neighbours of x∈S are the $ yY$, so T⊆Y.
αℓ=minx∈S,y∉T{ℓ(x)+ℓ(y)−w(x,y)} and ℓ′(v)={ℓ(v)−αℓ if v∈Sℓ(v)+αℓ if v∈Tℓ(v) otherwise
Sen Yang Note:比如拿此时equality graph为例,x∈S,y∉T的条件就是 Y3和X2,X3,那么αℓ=minX2,X3,Y3{8+0−6,4+0−1}=2然后上面构造ℓ′(v)的逻辑是,因为S∪T=Eℓ,这样还能保证其中每个边对应labeling的和ℓ(vS)−αℓ+ℓ(vT)+αℓ=ℓ′(vS)+ℓ′(vT)依然是保持不变,那么原来属于,并且Y的label值增加,X的label值减少
Then ℓ′ is a feasible labeling and (i) If (x,y)∈Eℓ for x∈S,y∈T then (x,y)∈Eℓ′ (ii) If (x,y)∈Eℓ for x∉S,y∉T then (x,y)∈Eℓ′ (iii) There is some edge (x,y)∈Eℓ′ for x∈S,y∉T
Sen Yang Note:(i)一定可以满足,(ii)不一定能找到这样的(x,y)比如当前的图中找不到一个(x,y)∈Eℓ for x∉S,y∉T
(iii)多产生了一个新边 (X2,Y3)∈Eℓ′,如下图。为什么会产生,这是因为我们αℓ=minX2,X3,Y3{8+0−6,4+0−1}
我们可以知道了这个
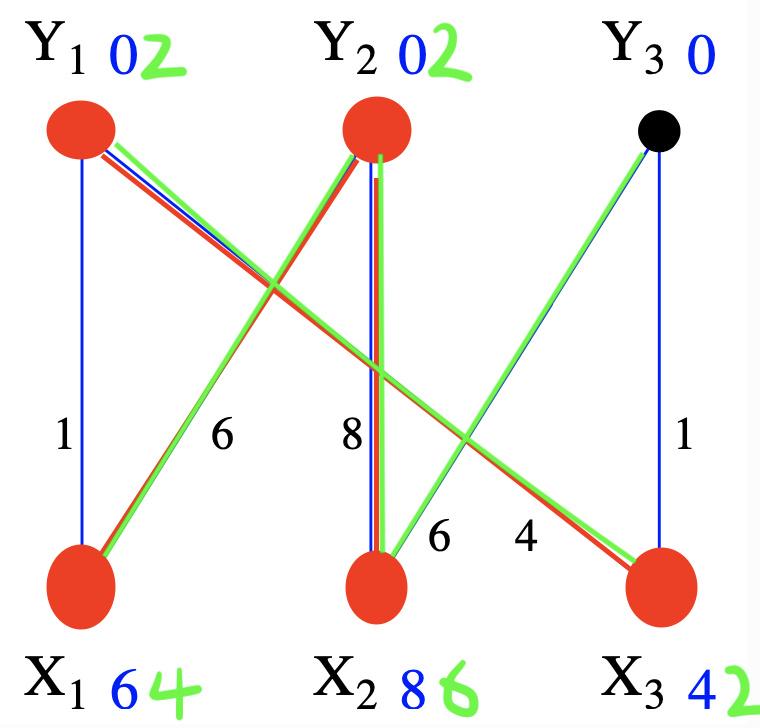
上面我们展示了扩展Eℓ⊂Eℓ′ 的技巧,请注意,它并不是实际KM算法(Hungarian )中的步骤,下面是真正的算法过程
KM算法:二分图加权最大匹配的匈牙利方法
Generate initial labelling ℓ and matching M in Eℓ
If M perfect, stop.
Otherwise pick free vertex u∈XSetS={u},T=∅
If Nℓ(S)=T, update labels (forcing Nℓ(S)≠T)αℓ=mins∈S,y∉T{ℓ(x)+ℓ(y)−w(x,y)}ℓ′(v)={ℓ(v)−αℓ if v∈Sℓ(v)+αℓ if v∈Tℓ(v) otherwise
If Nℓ(S)≠T, pick y∈Nℓ(S)−T
- If $ y$ free, u−y is augmenting path. Augment M and go to 2.
Note that:增强路为什么会在这个时候产生?2 - If y matched, say toz, extend
alternating tree:S=S∪{z},T=T∪{y}.3 Go to 3
迭代扩展匹配M至完美匹配
迭代等价图El
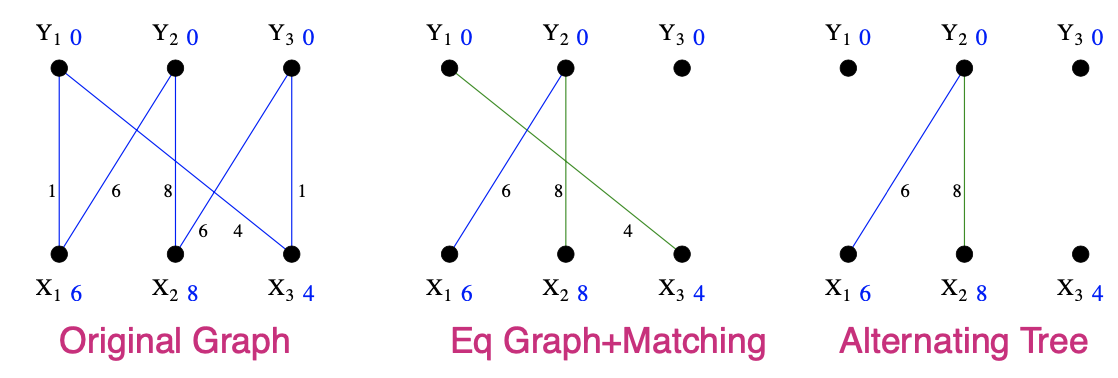
- Initial Graph, trivial labelling and associated Equality Graph
- Initial matching: (x3,y1),(x2,y2)
初始的任意一种匹配M'S={x1},T=∅ - since Nℓ(S)≠T, do step 4 Choose y2∈Nℓ(S)−T
- y2 is matched so grow tree by adding (y2,x2) ¡.e., S={x1,x2},T={y2}
- At this point Nℓ(S)=T, so goto 3
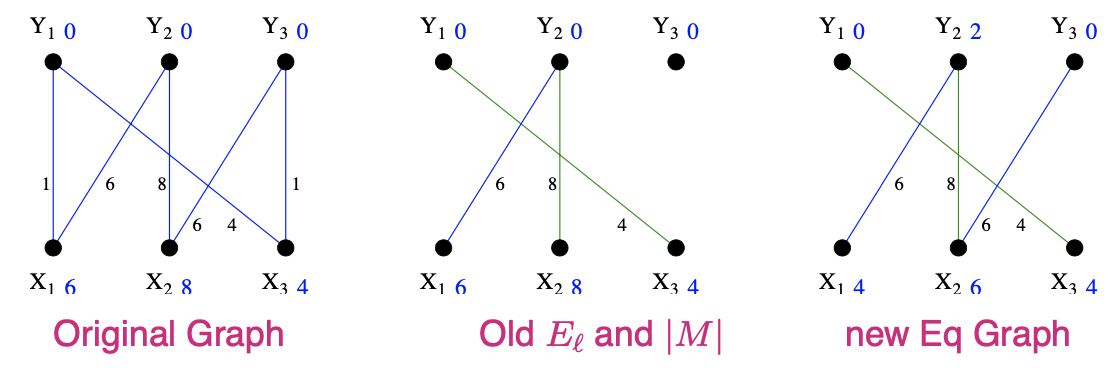
S={x1,x2},T={y2} and Nℓ(S)=T
Calculate αℓαℓ=minx∈S,y∉T{6+0−1,(x1,y1)6+0−0,(x1,y3)8+0−0,(x2,y1)8+0−6,(x2,y3)=2
Reduce labels of S by 2
Increase labels of T by 2
Now Nℓ(S)={y2,y3}≠{y2}=T
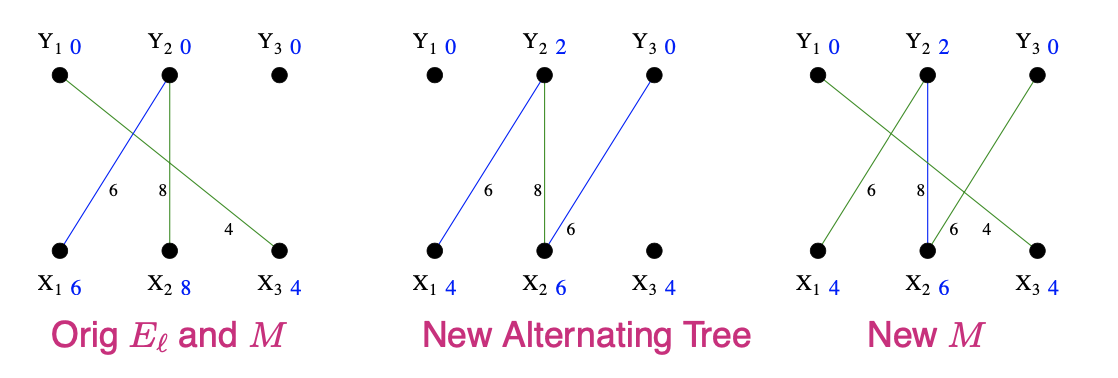
S={x1,x2},Nℓ(S)={y2,y3},T={y2}
- Choose y3∈Nℓ(S)−T and add it to T
- y3 is not matched in M so we have just found an alternating path x1,y2,x2,y3 with two free endpoints. We can therefore augment M to get a larger matching in the new equality graph. This matching is perfect, so it must be optimal.
Note that matching (x1,y2),(x2,y3),(x3,y1) has cost 6+6+4=16 which is exactly the sum of the labels in our final feasible labelling.
至此,我们从名词解释,到术语概念,到问题转换目标,到问题区分(二分图匹配和二分图加权最大匹配),到KM算法的原理与证明,再到算法步骤,最后举一个实际例分析,完整介绍了匈牙利算法。
后续,我们还会进一步研究匈牙利算法如何和一些CV任务进行结合。
实现-python
from scipy.optimize import linear_sum_assignment
Munkres' Assignment Algorithm /Modified for Rectangular Matrices
建议阅读下面两个文档,从数学和算法的角度分析了加权二分图的最大权匹配问题
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK