

《Redis 源码剖析与实战》学习笔记
source link: https://dongzl.github.io/2021/07/27/13-Redis-Source-Code-Analyze/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


《Redis 源码剖析与实战》学习笔记
开篇词 | 阅读Redis源码能给你带来什么?
阅读源码带来的受益:
- 第一,从原理到源码,学习源码阅读方法,培养源码习惯,掌握学习主动权。
- 第二,学习良好的编程规范和技巧,写出高质量的代码。
- 第三,举一反三,学习计算机系统设计思想,实现职业能力进阶。
高效阅读代码的要点:
- 先从整体上掌握源码的结构。
- 一定要有目标牵引和原理支撑。
- 要做到先主线逻辑再分支细节。
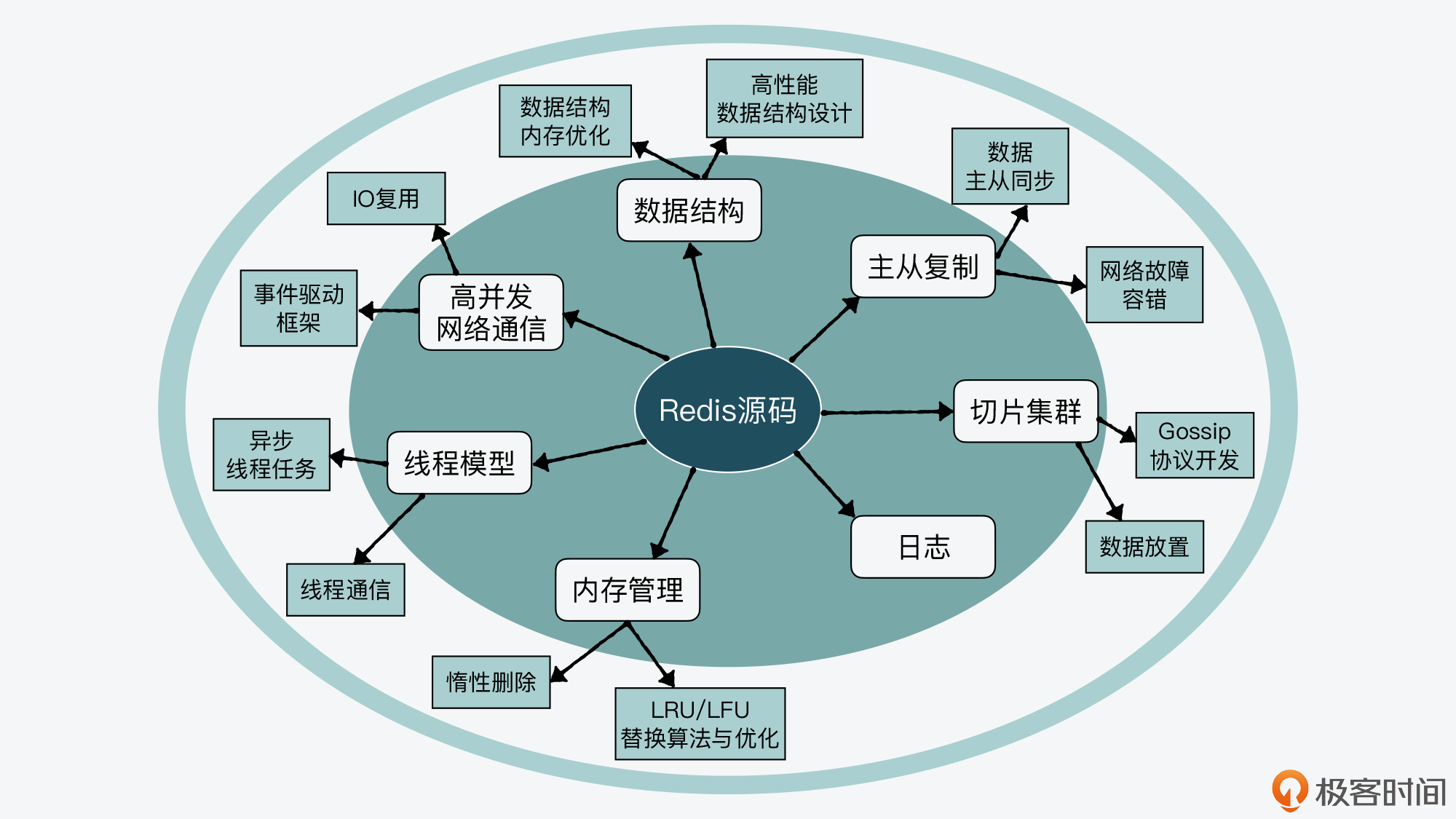
01 | 带你快速攻略Redis源码的整体架构
Redis 源码学习需要掌握的两方面内容:
代码的目录结构和目录划分,目的是理解
Redis代码的整体架构,以及所包含的代码功能类别;系统功能模块与对应代码文件,目的是了解
Redis实例提供的各项功能及其相应的实现文件,以便后续深入学习。
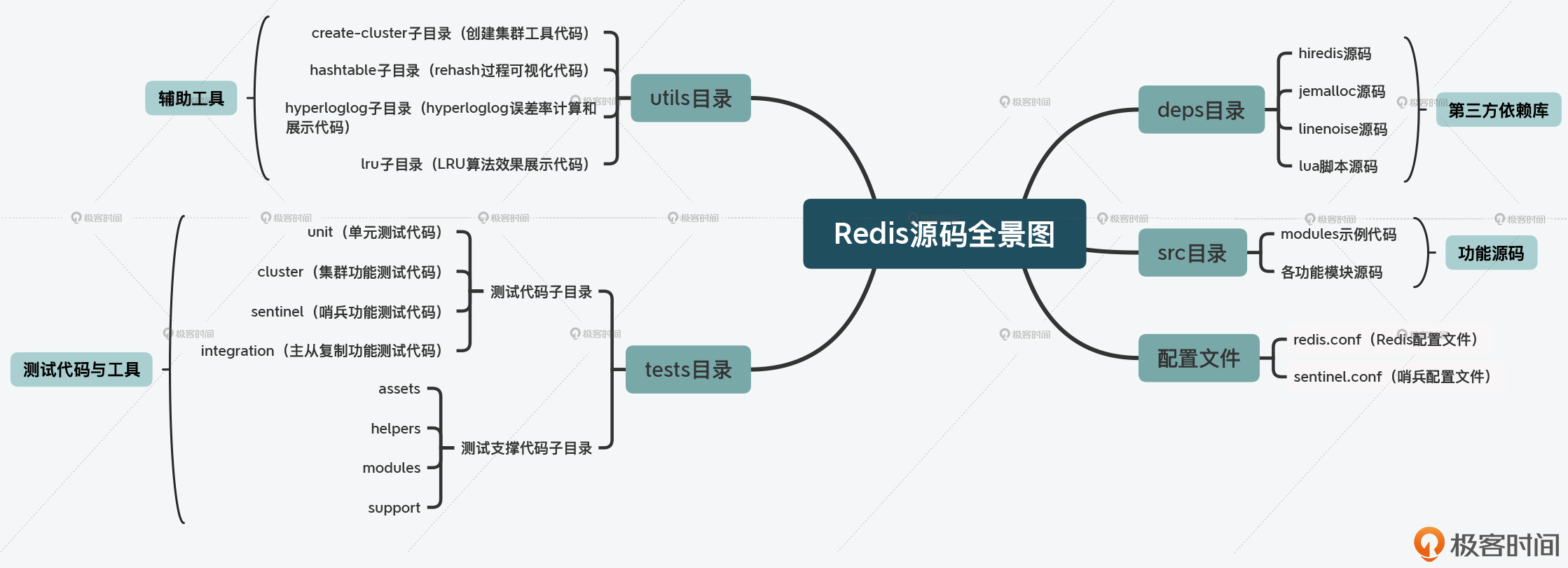
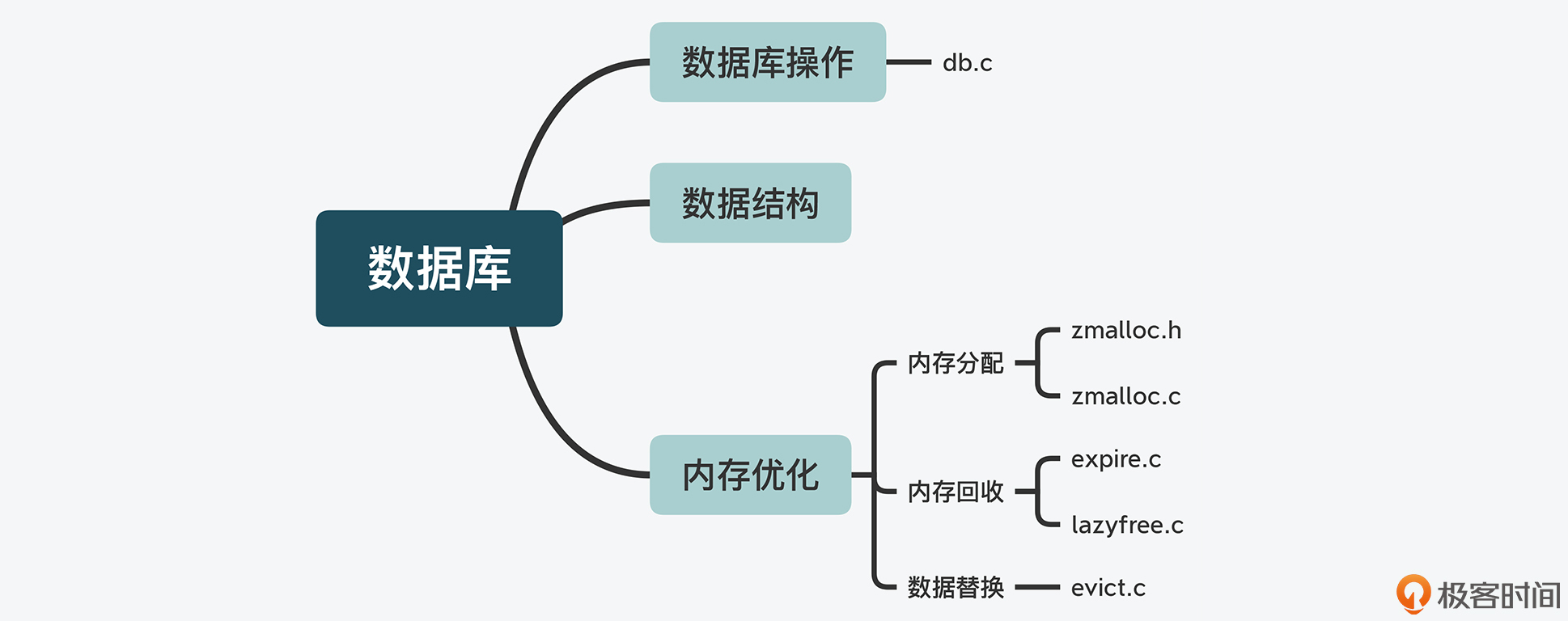
Redis 目录结构
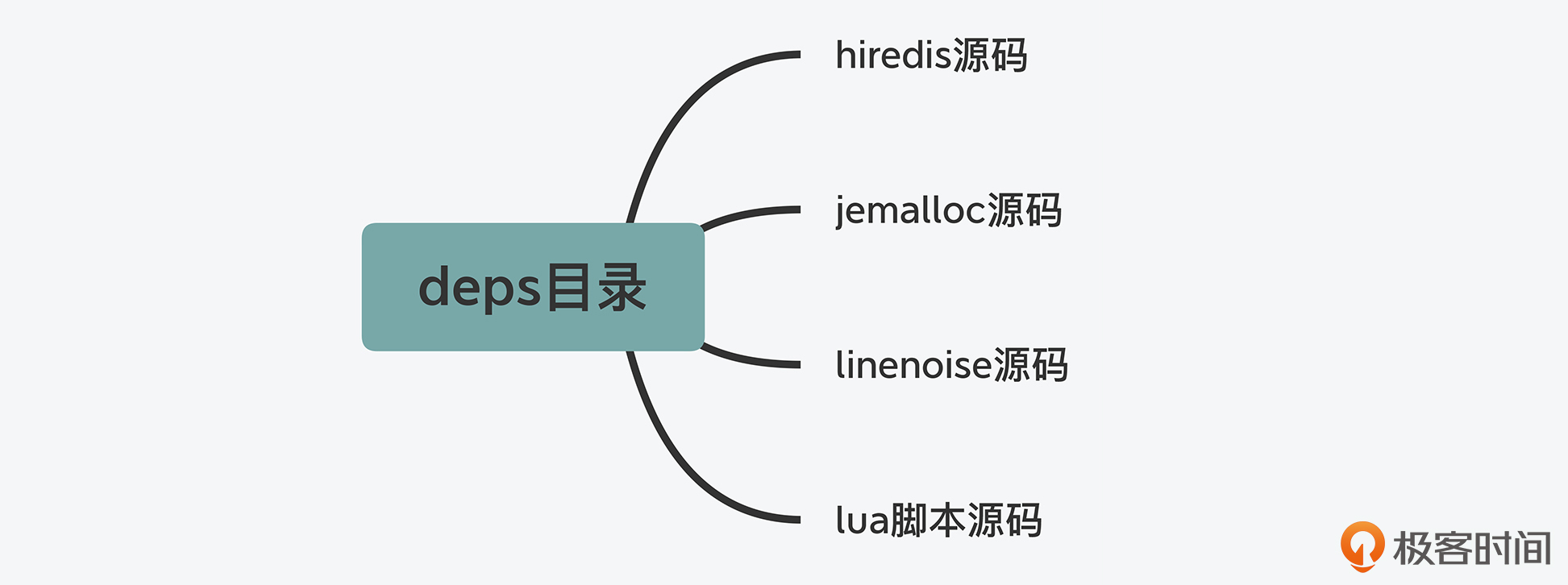
deps目录:Redis依赖的第三方代码库;
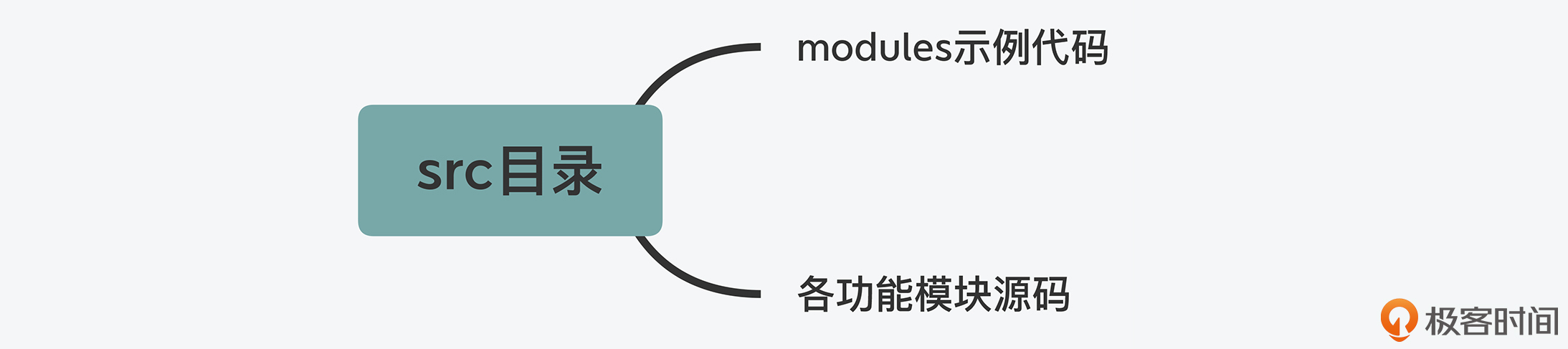
src目录:Redis所有功能模块的代码文件,也是Redis源码的重要组成部分;
tests目录:- 单元测试(
unit子目录) Redis Cluster功能测试(cluster子目录)- 哨兵功能测试(
sentinel子目录) - 主从复制功能测试(
integration子目录);
- 单元测试(
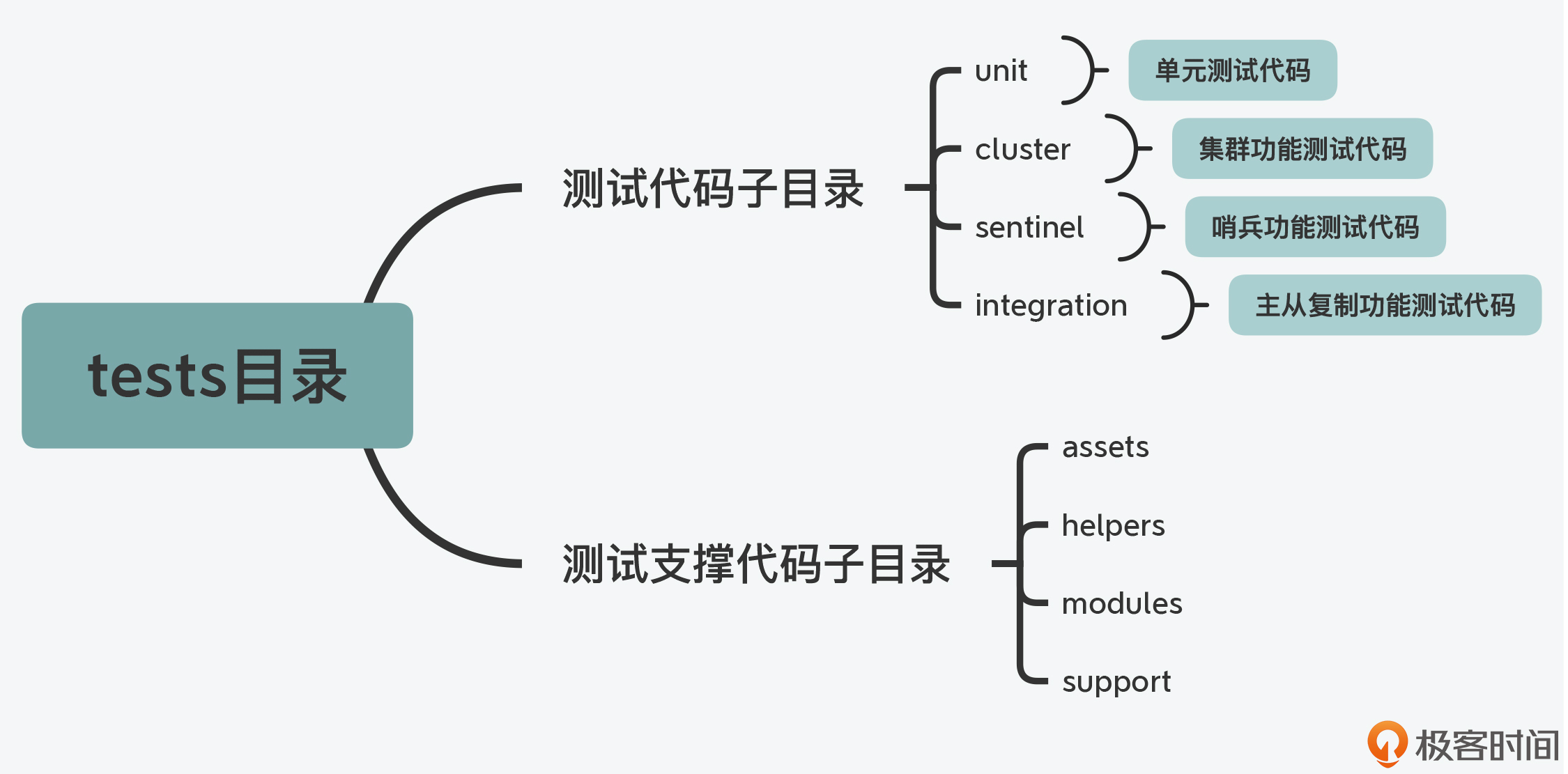
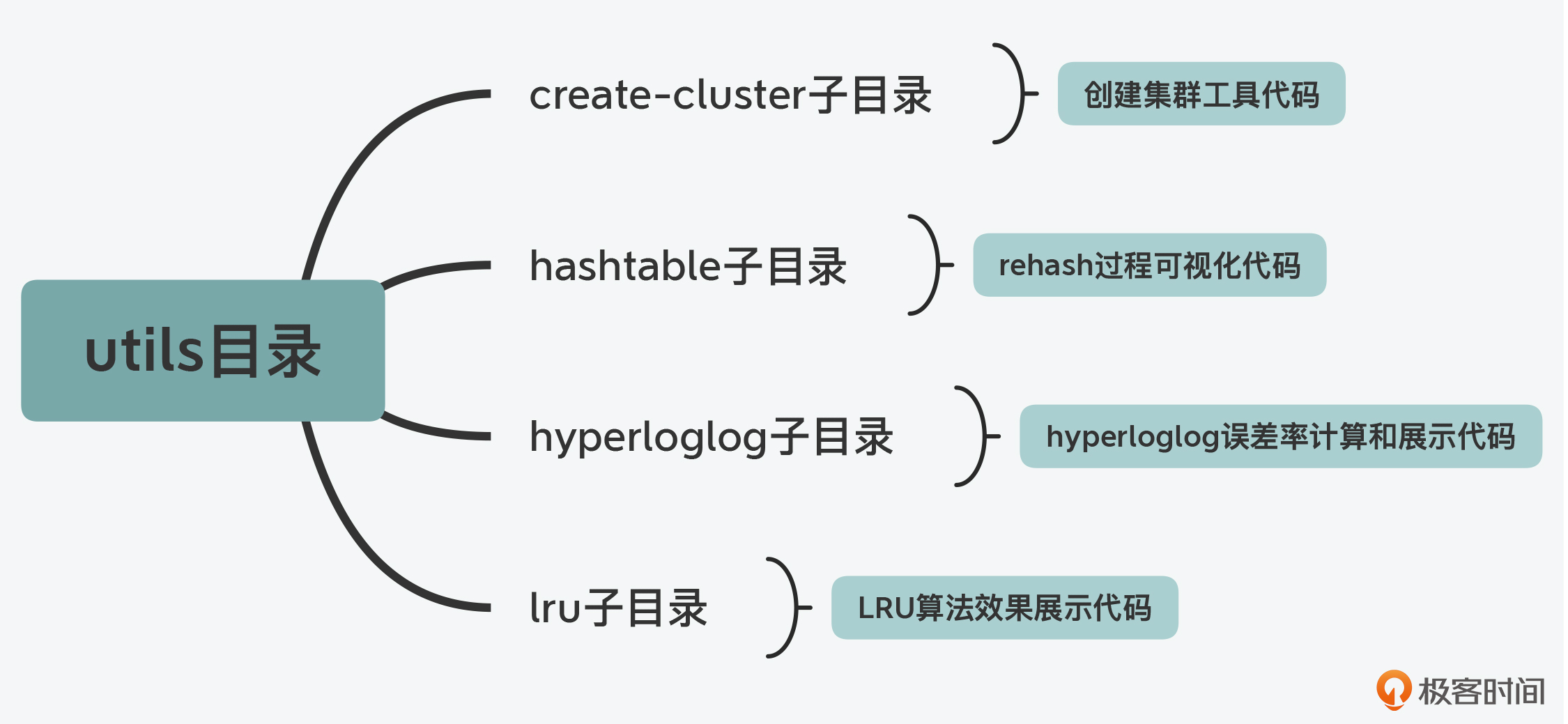
utils目录:
Redis 源码全景图
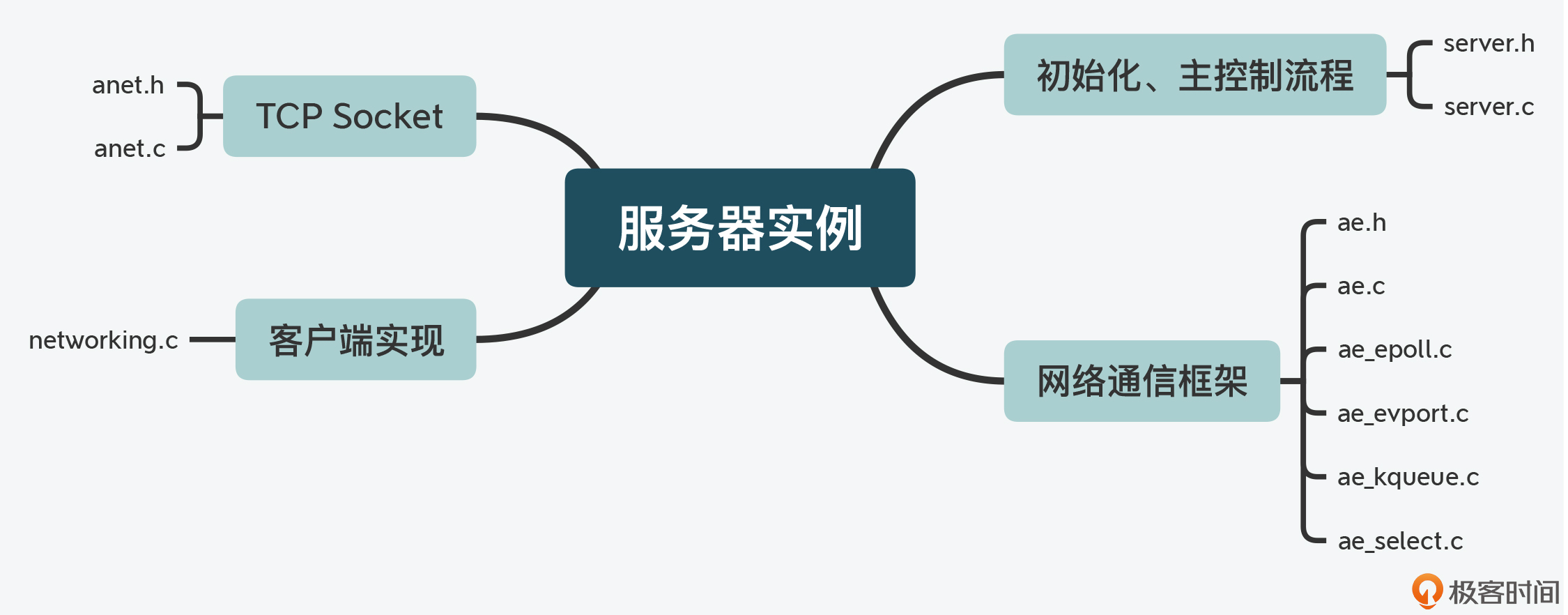
服务器实例代码结构
数据库数据类型与操作
高可靠性和高可扩展性
数据持久化实现:
rdb.h/rdb.c和aof.c;主从复制功能实现:
replication.c。
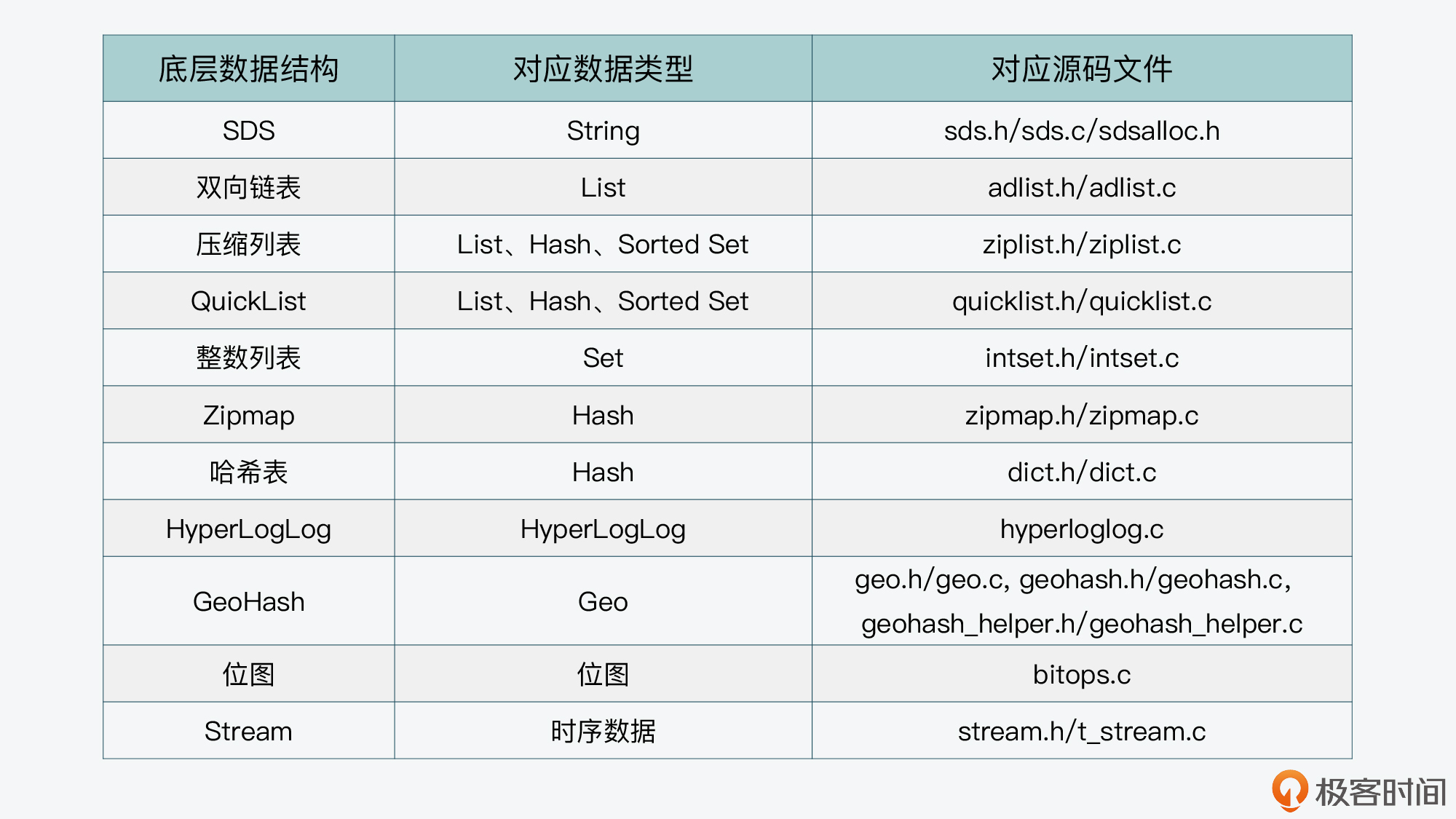
数据类型:
- String(t_string.c、sds.c、bitops.c)
- List(t_list.c、ziplist.c)
- Hash(t_hash.c、ziplist.c、dict.c)
- Set(t_set.c、intset.c)
- Sorted Set(t_zset.c、ziplist.c、dict.c)
- HyperLogLog(hyperloglog.c)
- Geo(geo.c、geohash.c、geohash_helper.c)
- Stream(t_stream.c、rax.c、listpack.c)
全局:
- Server(server.c、anet.c)
- Object(object.c)
- 键值对(db.c)
- 事件驱动(ae.c、ae_epoll.c、ae_kqueue.c、ae_evport.c、ae_select.c、networking.c)
- 内存回收(expire.c、lazyfree.c)
- 数据替换(evict.c)
- 后台线程(bio.c)
- 事务(multi.c)
- PubSub(pubsub.c)
- 内存分配(zmalloc.c)
- 双向链表(adlist.c)
高可用&集群:
- 持久化:RDB(rdb.c、redis-check-rdb.c)、AOF(aof.c、redis-check-aof.c)
- 主从复制(replication.c)
- 哨兵(sentinel.c)
- 集群(cluster.c)
辅助功能:
- 延迟统计(latency.c)
- 慢日志(slowlog.c)
- 通知(notify.c)
- 基准性能(redis-benchmark.c)
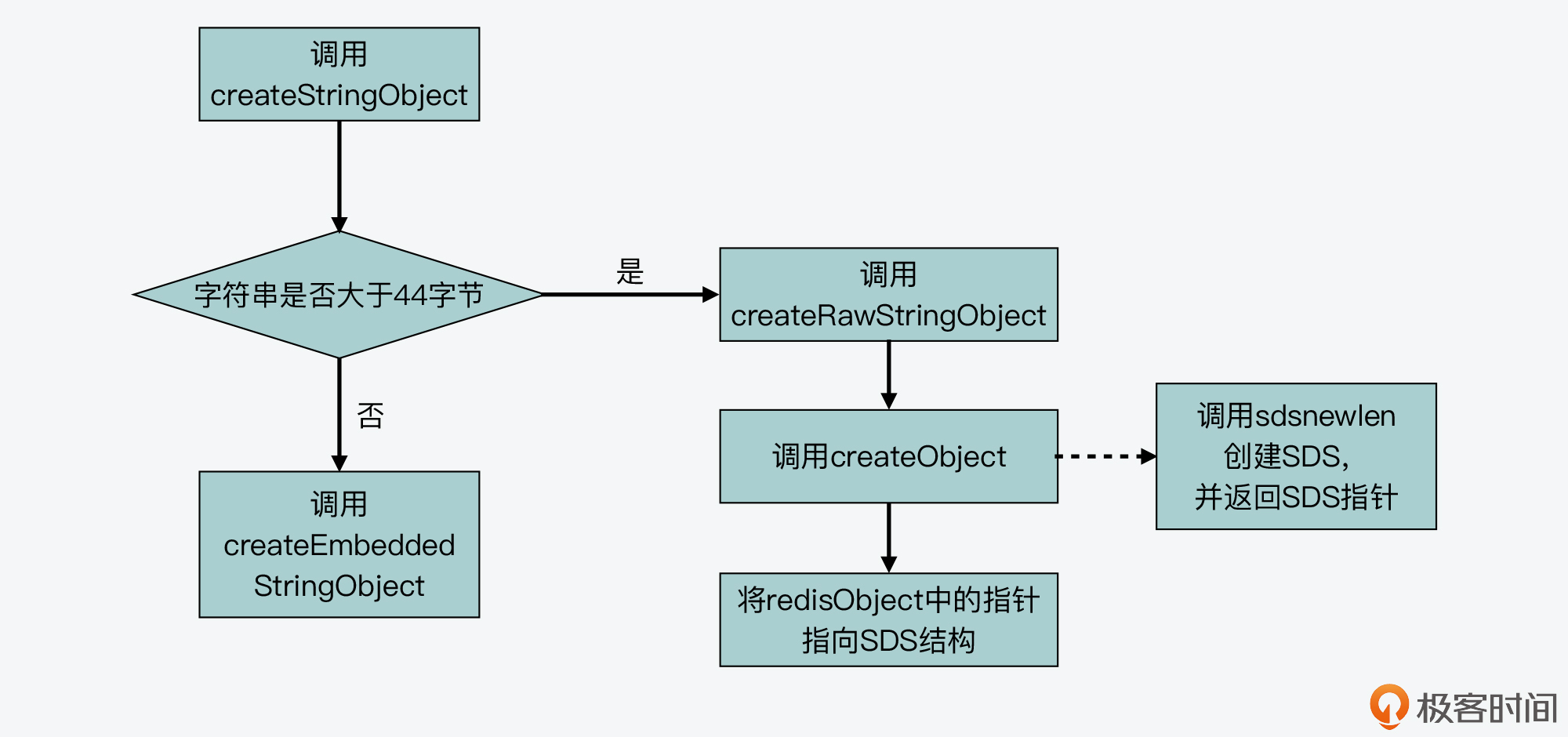
02 | 键值对中字符串的实现,用char*还是结构体?
字符串使用非常广泛,实现字符串功能需要满足如下需求:
- 能支持丰富且高效的字符串操作,比如字符串追加、拷贝、比较、获取长度等;
- 能保存任意的二进制数据,比如图片等;
- 能尽可能地节省内存开销。
C 语音字符串不足:
- 经常需要手动检查和分配字符串空间,而这就会增加代码开发的工作量;
- 图片等数据还无法用字符串保存,也就限制了应用范围。
Redis 的简单动态字符串(Simple Dynamic String,SDS):提升操作效率,并且可以保存二进制数据。
为什么 Redis 不用 char*
char* 就是一块连续的内存空间,依次存放了字符串中的每一个字符。
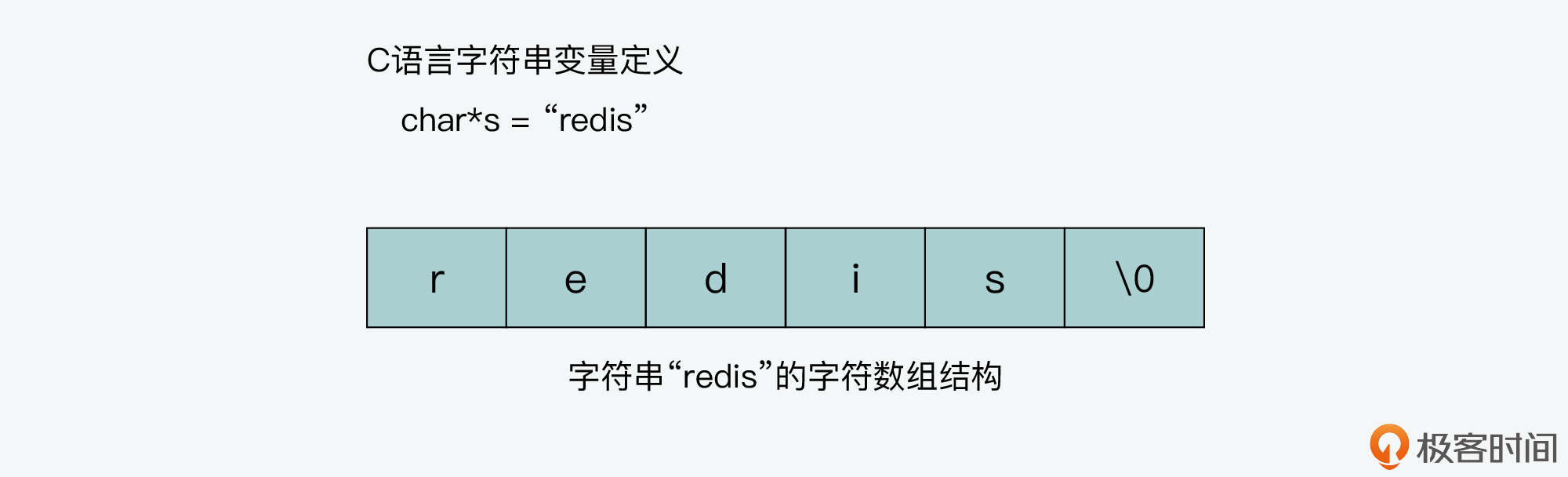
char* 指针指向字符数组的起始位置,而字符数组的结尾位置就用“\0”表示,意思是指字符串的结束。
C 语言标准库中字符串操作,是通过检查“\0”来判断字符串结束,这种实现方式会影响某些函数使用。
操作函数复杂度:某些函数时间复杂度为 O(N)。
C 语言中 char* 实现字符串功能两大不足:
- 使用 ”\0“ 表示字符串结束,无法存储二进制数据;
- 某些函数时间复杂度很高(O(N)),无法满足 Redis 高性能需要。
SDS 设计思想
为了尽量复用 C 标准库中字符串操作函数,Redis 保留了使用字符串数组来保存实际数据;同时 Redis 又专门设计了 SDS 数据结构。
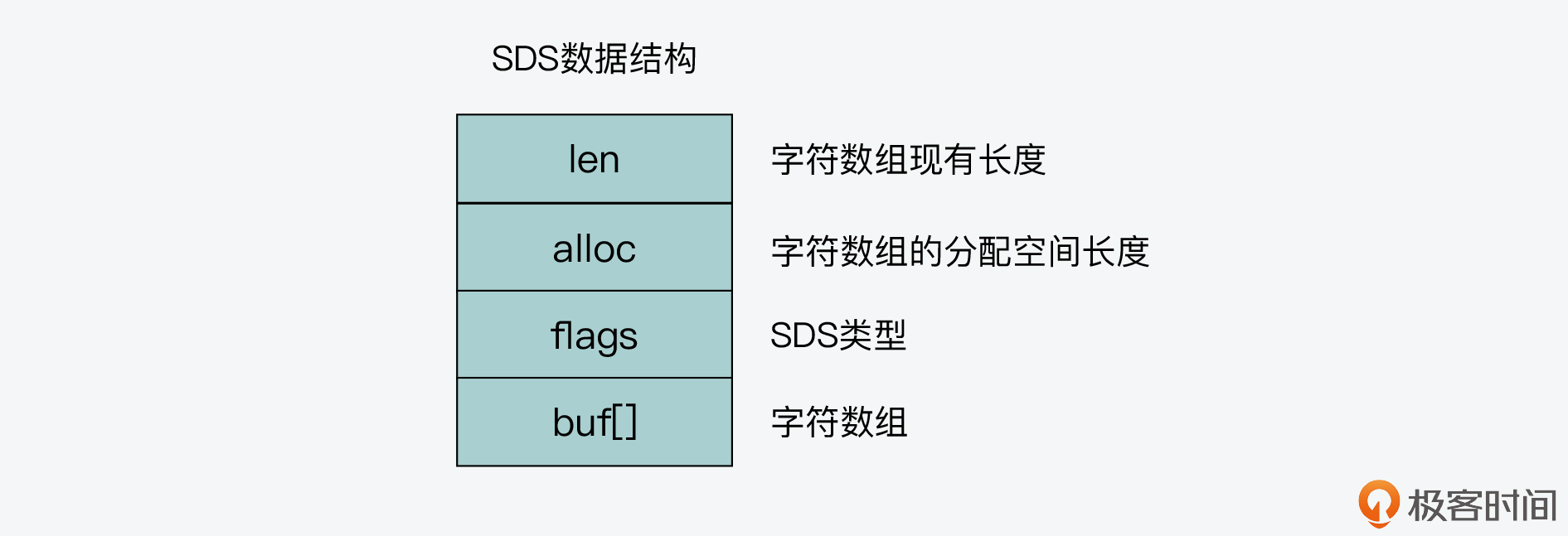
SDS 结构设计
SDS 结构设计:
SDS 操作效率
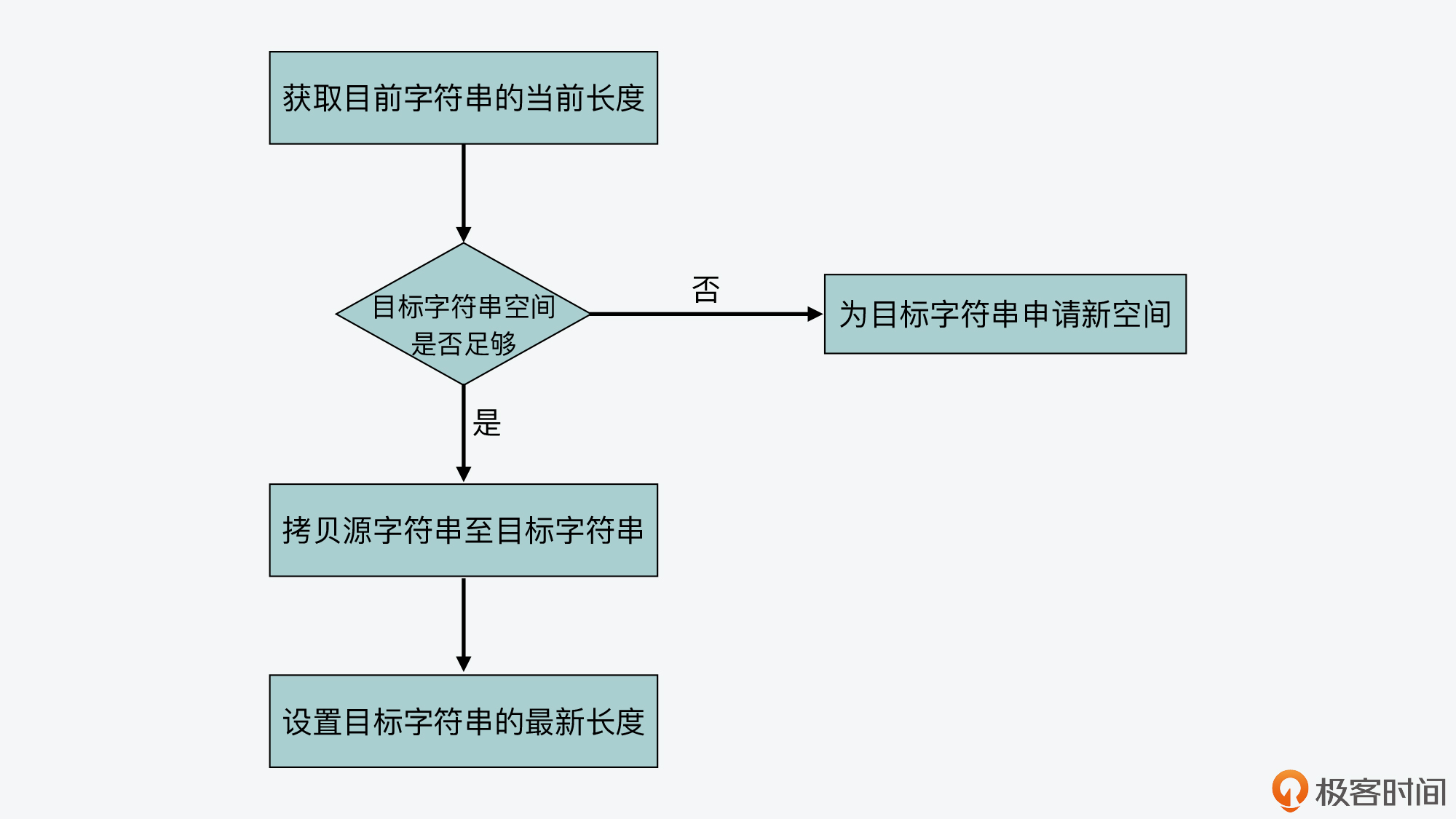
SDS 通过记录字符数组的使用长度和分配空间大小,避免了对字符串的遍历操作,降低了操作开销,进一步就可以帮助诸多字符串操作更加高效地完成。
紧凑型字符串结构的编程技巧
SDS 设计了 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64 五种类型,类型之间主要区别是:字符数组现有长度 len 和分配空间长度 alloc 这两个元数据类型不同。
SDS 之所以设计不同的结构头(即不同类型),是为了能灵活保存不同大小的字符串,从而有效节省内存空间。因为在保存不同大小的字符串时,结构头占用的内存空间也不一样,这样一来,在保存小字符串时,结构头占用空间也比较少。
使用 __attribute__ ((__packed__)) 编译优化来节省内存空间:不要使用字节对齐的方式,而是采用紧凑的方式分配内存。
C语言中使用char*实现字符串的不足,主要是因为使用“\0”表示字符串结束,操作时需遍历字符串,效率不高,并且无法完整表示包含“\0”的数据,因而这就无法满足Redis的需求。Redis中字符串的设计思想与实现方法。Redis专门设计了SDS数据结构,在字符数组的基础上,增加了字符数组长度和分配空间大小等元数据。这样一来,需要基于字符串长度进行的追加、复制、比较等操作,就可以直接读取元数据,效率也就提升了。而且,SDS不通过字符串中的“\0”字符判断字符串结束,而是直接将其作为二进制数据处理,可以用来保存图片等二进制数据。SDS中是通过设计不同SDS类型来表示不同大小的字符串,并使用__attribute__ ((__packed__))这个编程小技巧,来实现紧凑型内存布局,达到节省内存的目的。
评论区补充
Redis 在操作 SDS 时,为了避免频繁操作字符串时,每次申请、释放内存的开销,还做了这些优化:
- 内存预分配:
SDS扩容,会多申请一些内存(小于1MB翻倍扩容,大于1MB按1MB扩容); - 多余内存不释放:
SDS缩容,不释放多余的内存,下次使用可直接复用这些内存。
使用了空间换时间的思路。
03 | 如何实现一个性能优异的Hash表?(这一篇还需要重新学习)
Redis 哈希表结构:链式哈希。
Redis 哈希扩容:渐进式 rehash 设计。
Redis 如何实现链式哈希?
链式哈希,就是用一个链表把映射到 Hash 表同一桶中的键给连接起来。
Redis 如何实现 rehash
- 首先,
Redis准备了两个哈希表,用于rehash时交替保存数据。 - 其次,在正常服务请求阶段,所有的键值对写入哈希表
ht[0]。 - 接着,当进行
rehash时,键值对被迁移到哈希表ht[1]中。 - 最后,当迁移完成后,
ht[0]的空间会被释放,并把ht[1]的地址赋值给ht[0],ht[1]的表大小设置为0。这样一来,又回到了正常服务请求的阶段,ht[0]接收和服务请求,ht[1]作为下一次rehash时的迁移表。
什么时候触发 rehash
- 条件一:
ht[0]的大小为0。 - 条件二:
ht[0]承载的元素个数已经超过了ht[0]的大小,同时Hash表可以进行扩容。 - 条件三:
ht[0]承载的元素个数,是ht[0]的大小的dict_force_resize_ratio倍,其中,dict_force_resize_ratio的默认值是5。
rehash 扩容扩多大?
如果当前表的已用空间大小为 size,那么就将表扩容到 size * 2 的大小。
渐进式 rehash 如何实现?
04 | 内存友好的数据结构该如何细化设计?
Redis 提升内存使用效率的思想:
- 数据结构的优化设计与使用;
- 内存数据按一定规则淘汰。
Redis 数据结构在面向内存使用效率方面的优化:
- 内存友好的数据结构设计;
- 内存友好的数据使用方式。
内存友好的数据结构
SDS 的内存友好设计
SDS 设计了不同类型的结构头,包括 sdshdr8、sdshdr16、sdshdr32 和 sdshdr64。这些不同类型的结构头可以适配不同大小的字符串,从而避免了内存浪费。
redisObject 结构体与位域定义方法
redisObject 结构体是在 server.h 文件中定义的,主要功能是用来保存键值对中的值。这个结构一共定义了 4 个元数据和一个指针。
type:redisObject的数据类型,是应用程序在Redis中保存的数据类型,包括String、List、Hash等。encoding:redisObject的编码类型,是Redis内部实现各种数据类型所用的数据结构。lru:redisObject的LRU时间。refcount:redisObject的引用计数。ptr:指向值的指针。
typedef struct redisObject { |
变量后使用冒号和数值的定义方法。这实际上是 C 语言中的位域定义方法,可以用来有效地节省内存开销。
嵌入式字符串

Redis 创建字符串的过程:
压缩列表和整数集合的设计
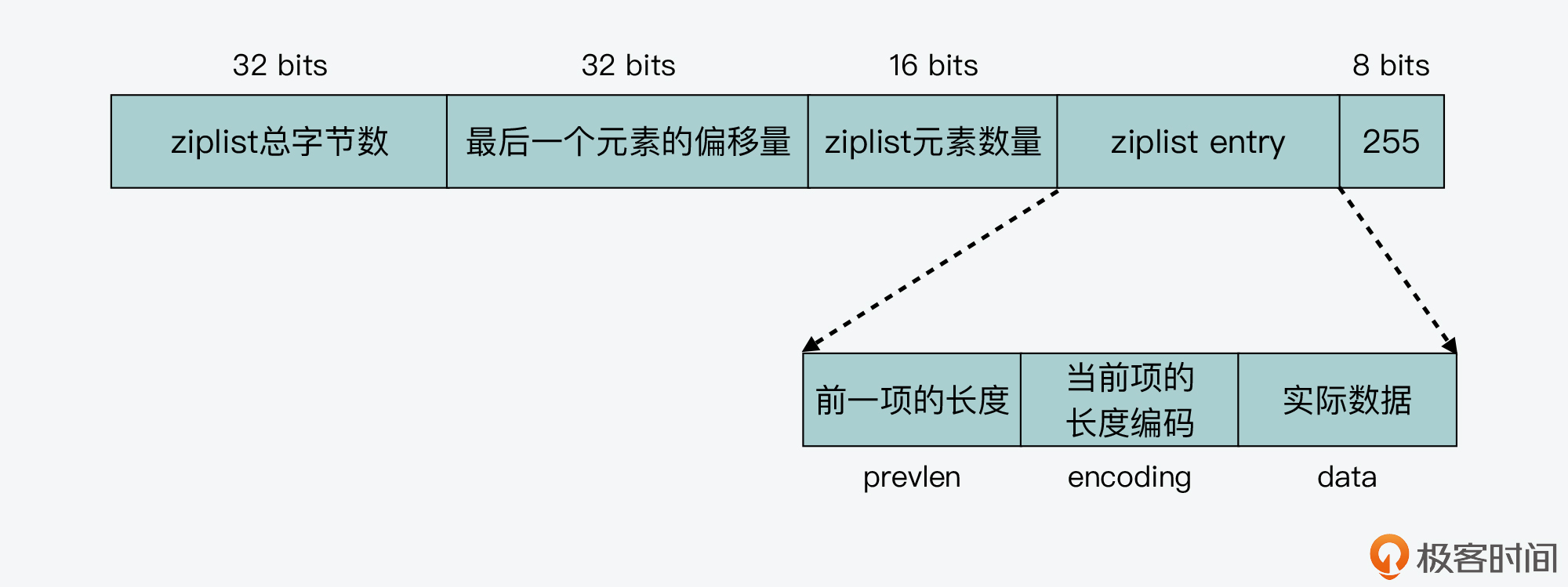
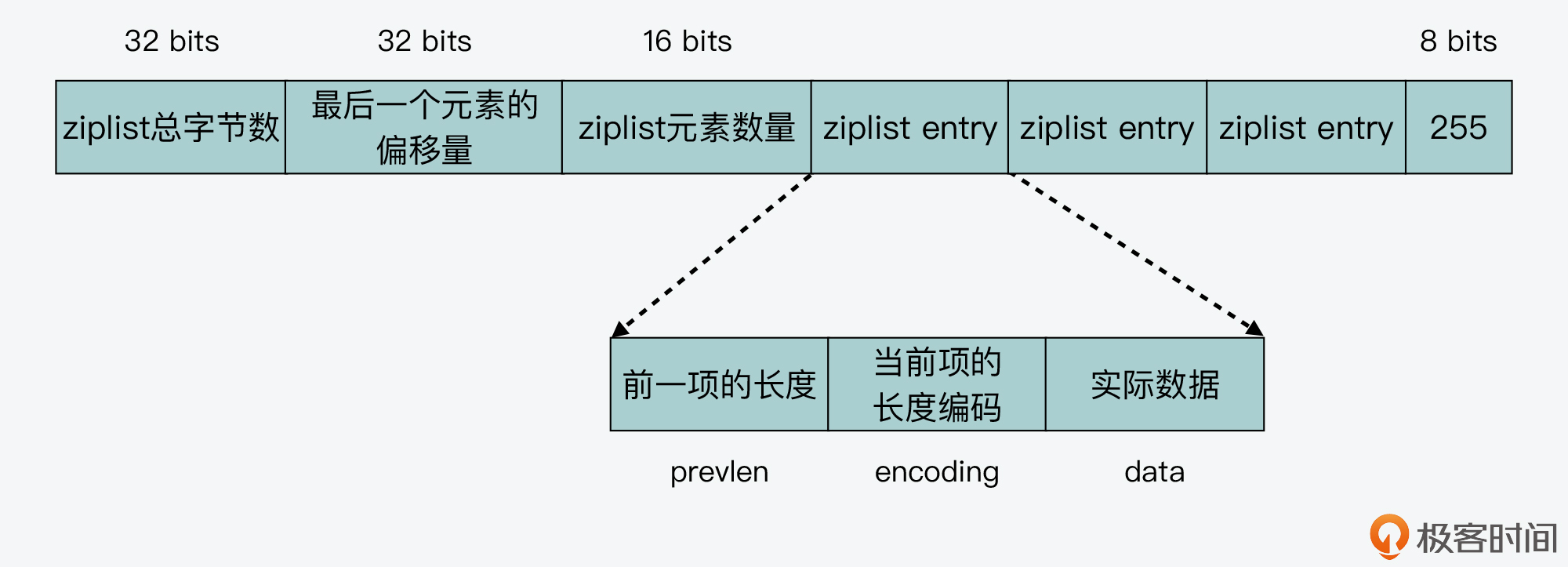
压缩列表本身就是一块连续的内存空间,它通过使用不同的编码来保存数据。
在创建一个新的 ziplist 后,列表的内存布局如下,此时列表中还没有任何数据:

当我们往 ziplist 中插入数据时,ziplist 就会根据数据是字符串还是整数,以及它们的大小进行不同的编码。这种根据数据大小进行相应编码的设计思想,正是 Redis 为了节省内存而采用的。
ziplist 列表项包括三部分内容:
- 前一项的长度(prevlen);
- 当前项长度信息的编码结果(encoding);
- 当前项的实际数据(data)。
节省内存的数据访问
共享对象:把一些常用数据创建为共享对象,当上层应用需要访问它们时,直接读取就行。
void createSharedObjects(void) { |
节省内存的数据结构实现思路:
- 使用连续的内存空间,避免内存碎片开销;
- 针对不同长度的数据,采用不同大小的元数据,以避免使用统一大小的元数据,造成内存空间的浪费。
使用共享对象可以避免重复创建冗余的数据,也可以有效地节省内存空间。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK