

网络进程:Http请求流程
source link: https://lianpf.github.io/posts/%E8%AE%A1%E7%AE%97%E6%9C%BA%E5%8E%9F%E7%90%86/http%E8%AF%B7%E6%B1%82%E6%B5%81%E7%A8%8B/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

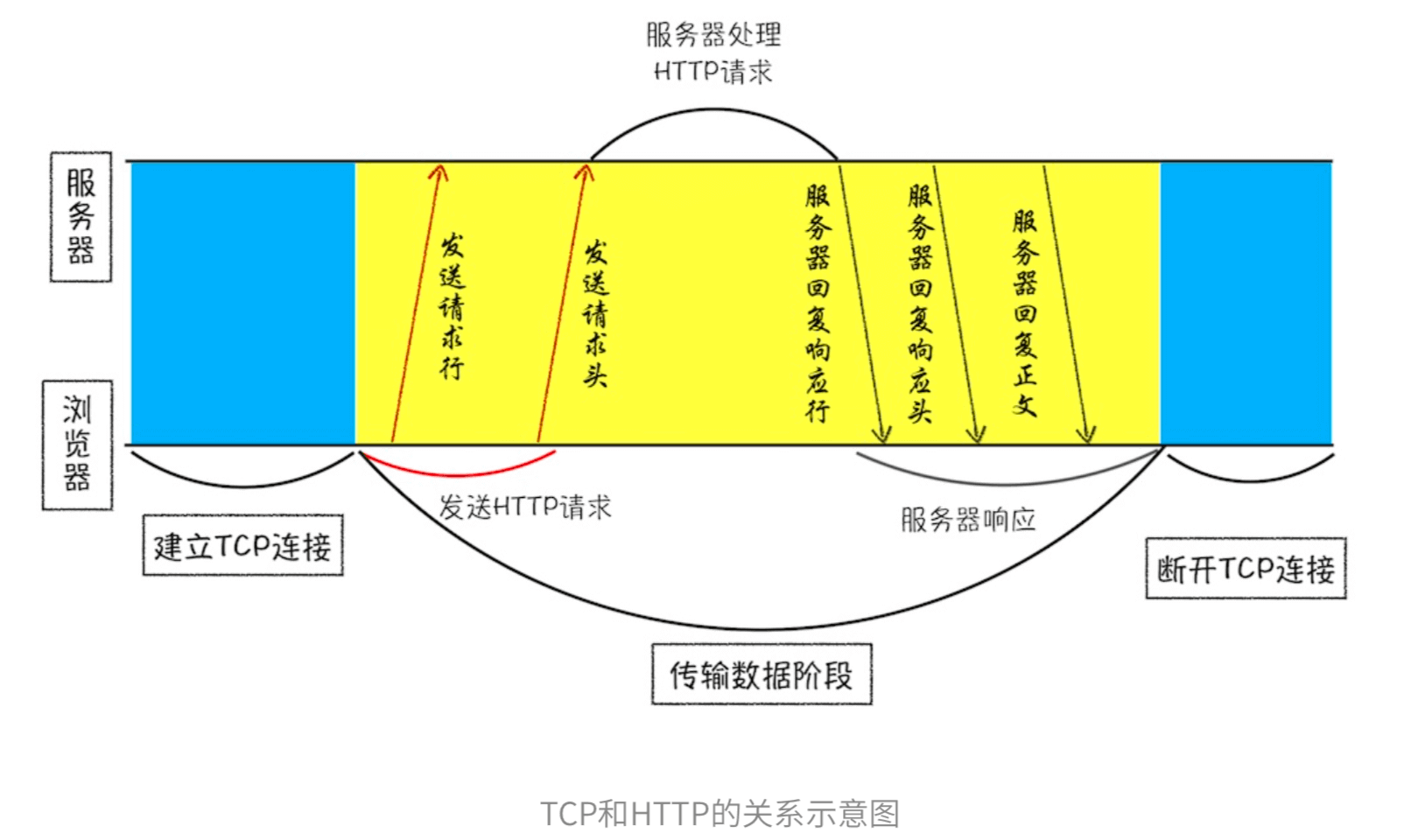
http和TCP的关系? 什么是 HTTP协议?建立在TCP连接基础之上,一种允许浏览器向服务器获取资源(JavaScript、CSS、图片等)的协议…
完整的HTTP请求包括两个过程:
- 浏览器端发起HTTP请求流程
- 服务器端处理HTTP请求流程
一、 浏览器端发起HTTP请求流程
- 查找缓存:缓解服务器端压力、快速资源加载
- 缓存查找失败,进入网络请求过程:准备IP地址和端口
- 等待、建立TCP队列
- 发送HTTP请求
1、浏览器缓存
一种在本地保存资源副本,以供下次请求直接使用的技术
当浏览器发现请求的资源已经在浏览器缓存中存有副本,它会拦截请求,返回该资源的副本,并直接结束请 求,而不会再去源服务器重新下载。若缓存查找失败,则进入网络请求过程
- 缓解服务器端压力
- 实现资源快速加载
2、缓存查找失败,进入网络请求过程:准备IP地址和端口
浏览器使用HTTP协议作为应用层协议,封存请求的文本信息。且使用TCP/IP作为传输层协议将其发布到网络上。
HTTP的内容是通过TCP的传输数据阶段来实现的,在HTTP工作开始之前,浏览器需要通过TCP与服务器建立连接
数据包都是通过IP地址传输给接收方,所以我们需要域名系统DNS(Domain Name System),根据域名和IP地址的映射关系,获取到主机IP
真正的第一步浏览器会请求DNS返回域名对应的IP,当然浏览器还提供了DNS数据缓存服务,如果某个域名已经解析过了,那么浏览器会缓存解析的结果,以供下次查询时直接使用,这样也会减少一次网络请求 域名系统(DNS)
3、等待、建立TCP队列
Chrome有个机制,同一个域名同时最多只能建立6个TCP连接。即在同一个域名下同时有10个请求发生,那么其中4个请求会进入排队等待状态,直至进行中的请求完成。如果当前请求数量少于6,会直接进入下一步,建立TCP连接
HTTP工作开始之前,浏览器通过TCP与服务器建立连接——三次握手
4、 发送HTTP请求
建立了TCP连接,浏览器就可以和服务器进行通信了。而HTTP中的数据正是在这个通信过程中传输的
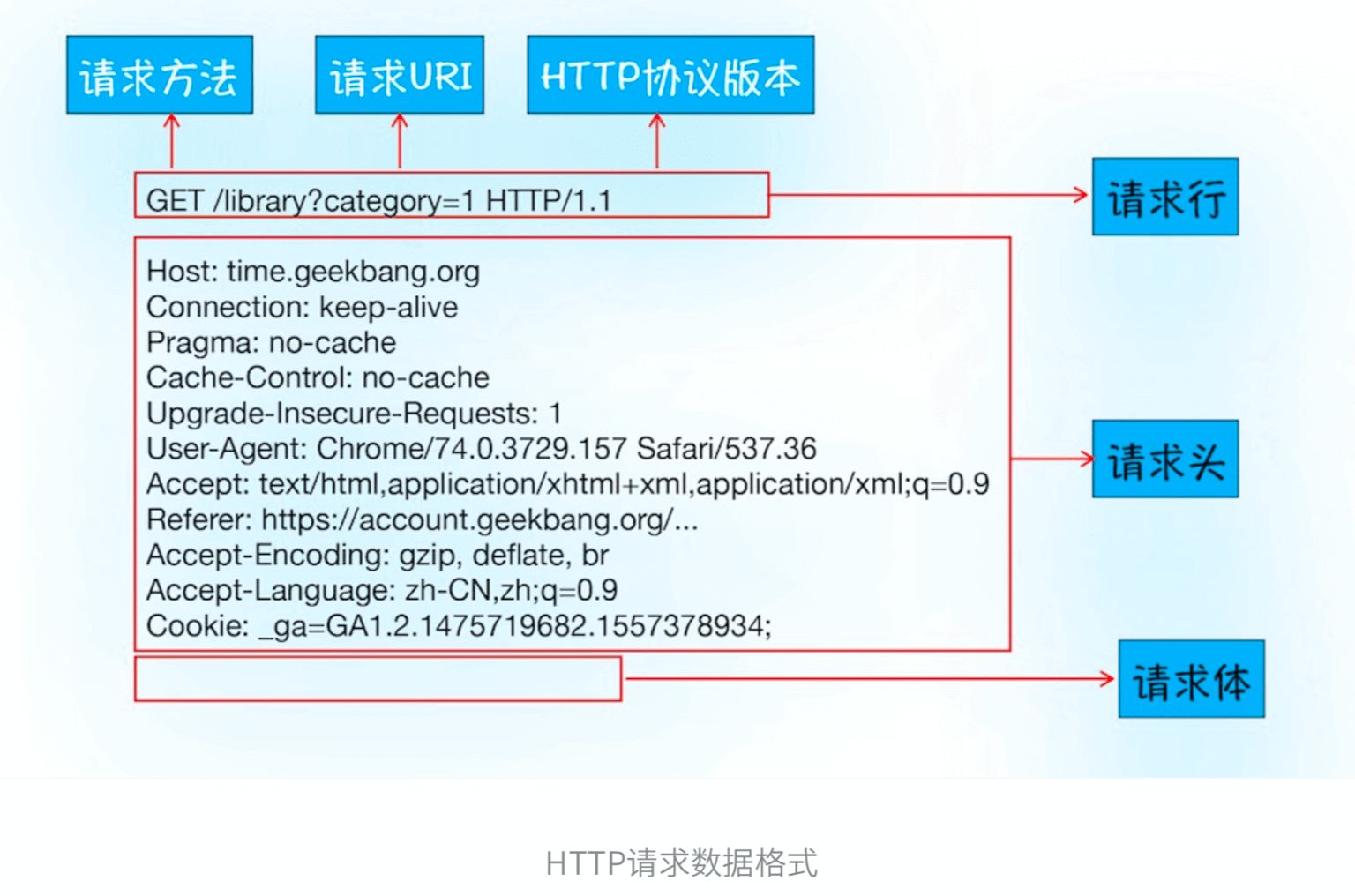
- 请求行:
- 告诉服务器浏览器需要什么资源
- 包括请求方法、请求URI(Uniform Resource Identifier)和HTTP协议版本
- 请求头:把浏览器的一些基础信息告诉服务器,比如:浏览器所使用的操作系统、浏览器内核等信息,以及当前请求的域名信息、浏览器端的 Cookie信息等
- 请求体:Post请求,等发送一些数据给服务器
二、服务器端处理HTTP请求流程
curl命令查看
1、返回请求
curl命令curl -i https://time.geekbang.org/查看返回请求数据
i是为了返回响应行、响应头和响应体的数据。-I表示只获取响应头和响应行数据,不需要获取响应体的数据

- 响应行:包含协议版本和状态码
- 响应头:包含服务器信息,比如服务器生成返回数据的时间、返回的数据类型(JSON、HTML、流媒体等类 型),以及服务器要在客戶端保存的Cookie等
- 响应体:包含了HTML的实际内容
2、断开连接
通常情况下,一旦服务器向客戶端返回了请求数据,它就要关闭 TCP 连接。但可配置Connection:Keep-Alive长连接,TCP连接在发送后将仍保持打开状态,浏览器就可以继续通过同一个TCP连接发送请求
保持TCP连接可以省去下次请求时需要建立连接的时间,提升资源加载速度
3、重定向操作

需要重定向的网址正是包含在响应头的Location字段
三、几个问题
1、HTTP请求流程: 为什么很多站点第二次打开速度会很快
主要原因是第一次加载⻚面过程中,DNS缓存、页面资源缓存
DNS缓存比较简单,就是在浏览器本地把对应的IP和域名关联起来
浏览器资源缓存处理的过程:
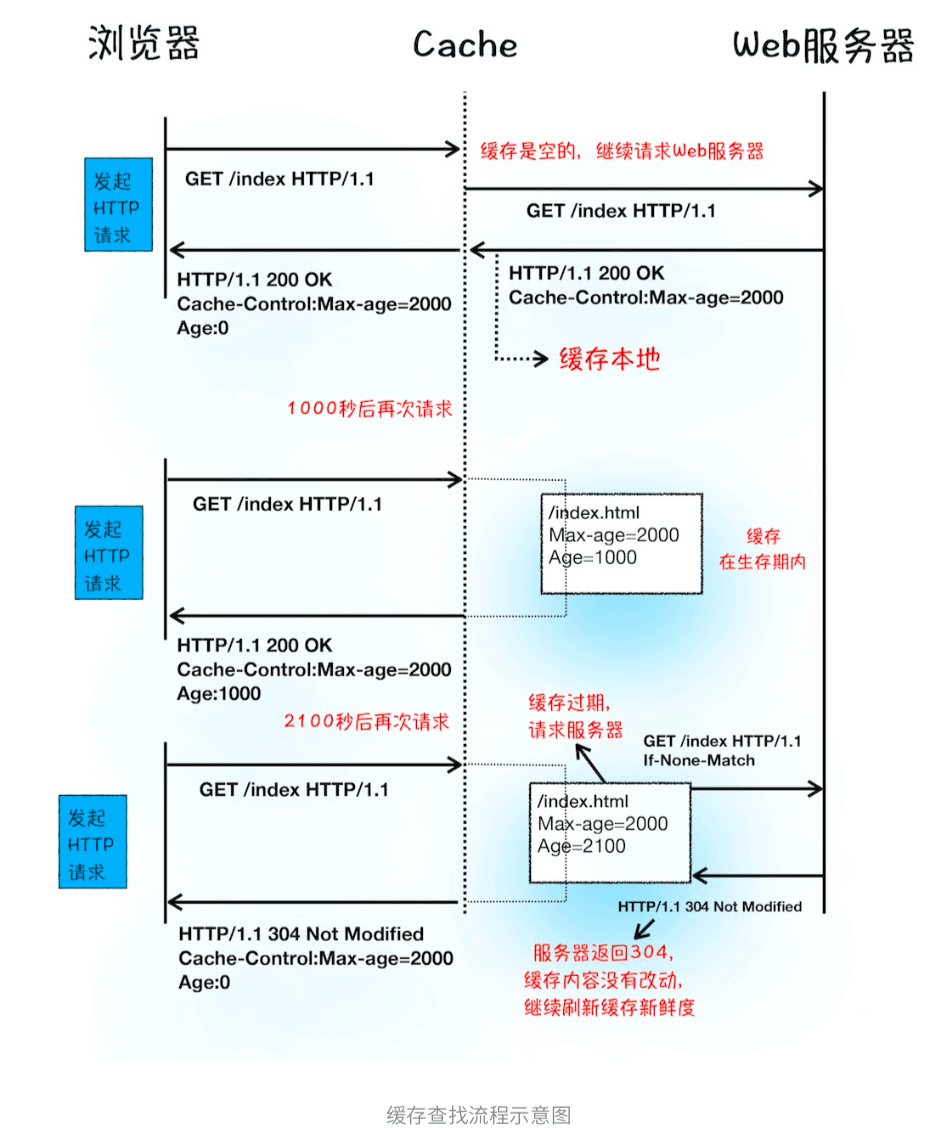
第一次请求,服务器返回HTTP响应头给浏览器时,浏览器是通过响应头中的Cache-Control字段来设置是否缓存该资源。以及Cache-Control:Max-age=2000设置该资源缓存过期时⻓。
- 缓存资源还未过期的情况下, 如果再次请求该资源,会直接返回缓存中的资源给浏览 器
- 缓存过期了,浏览器则会继续发起网络请求,并且在HTTP请求头中带上
If-None-Match:"4f80f-13c-3a1xb12a"
服务器收到请求头后,会根据If-None-Match的值来判断请求的资源是否有更新
- 没有更新,就返回304状态码,相当于服务器告诉浏览器:“这个缓存可以继续使用,这次就不重复 发送数据给你了
- 资源有更新,服务器就直接返回最新资源给浏览器
在浏览器中访问的时候打开network面板,发现缓 存的来源有的from disk有的是from memory ???
防止网络劫持:http在传输过程中是明文的,所以数据在传输过程中是能够被截获或者修改的
2、登录状态如何保持?
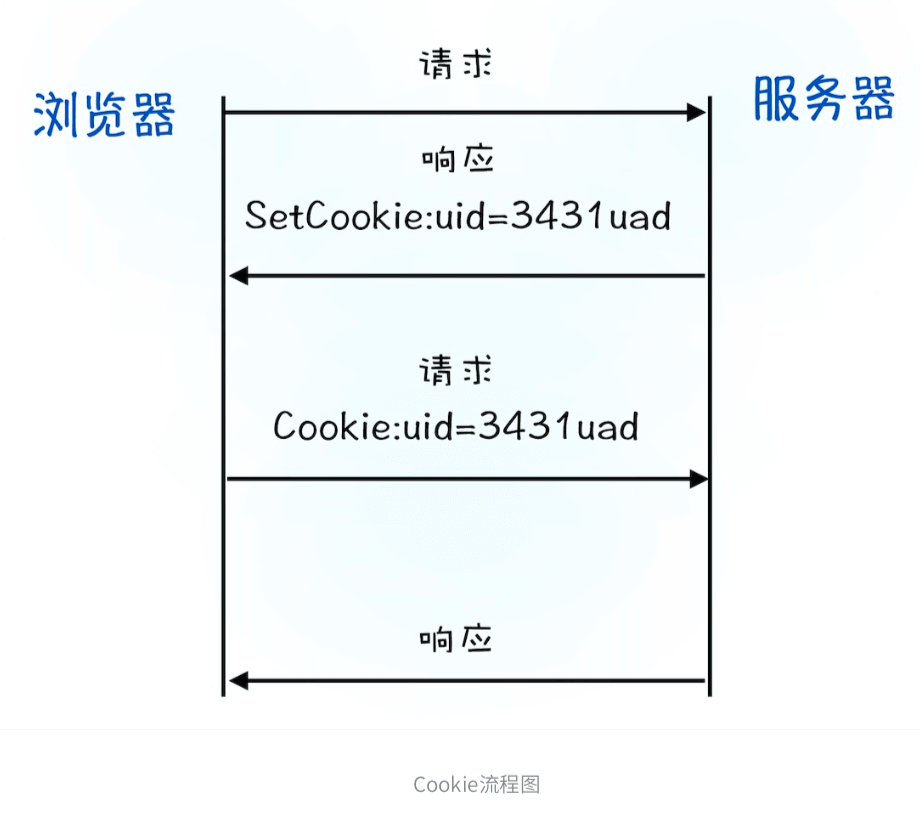
- 服务器接收到浏览器提交的信息之后,查询后台,验证用戶登录信息是否正确,如果正确的话,会生成一段表示用戶身份的字符串,并把该字符串写到响应头的Set-Cookie字段里
- 浏览器接收到服务器的响应头且解析,如果服务器端发送的响应头内有 Set-Cookie 的字段,那么浏览器就会将该字段的内容保持到本地。
- 用户再次访问,发起HTTP请求前,浏览器会读取之前保存的Cookie数据,并把数据写进请求头里的Cookie字段里再将请求头发送给服务器
- 服务器端发现客戶端发送过来的Cookie后,会去检查究竟是从哪一个客戶端发来的连接请求,然后对比服务器上的记录,最后得到该用戶的状态信息
四、总结HTTP请求流程
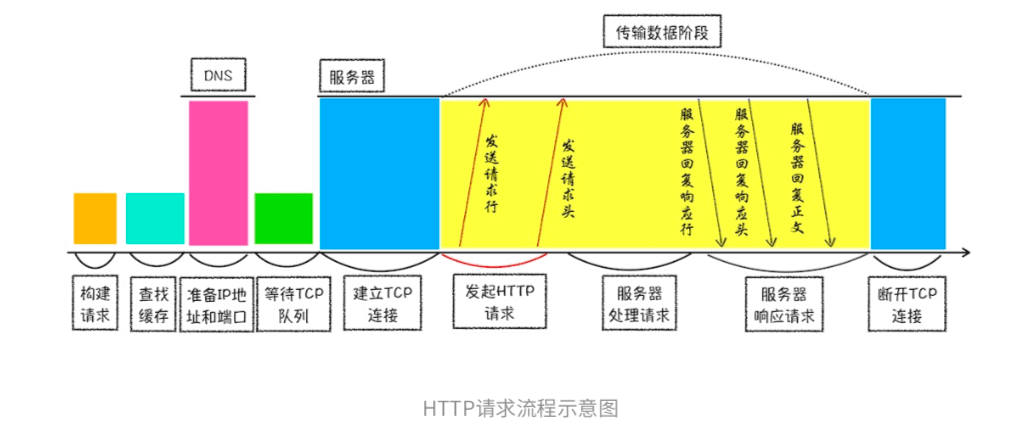
浏览器中的HTTP请求从发起到结束一共经历了如下八个阶段:构建请求、查找缓存、准 备IP和端口、等待TCP队列、建立TCP连接、发起HTTP请求、服务器处理请求、服务器返回请求和断开连接
最后, 希望大家早日实现:成为前端高手的伟大梦想!
欢迎交流~

本文版权归原作者曜灵所有!未经允许,严禁转载!对非法转载者, 原作者保留采用法律手段追究的权利!
若需转载,请联系微信公众号:连先生有猫病,可获取作者联系方式!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK