

字节跳动开源 CowClip:推荐模型单卡训练最高加速72倍
source link: https://www.qbitai.com/2022/04/34341.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

字节跳动开源 CowClip:推荐模型单卡训练最高加速72倍

不够快!还不够快?
不够快!还不够快?
在 NLP 和 CV 任务上,为了加速神经网络的训练,借助 32K 的批量大小(batch size)和 8 块 GPU,只需 14 分钟就完成 ImageNet 的训练,76 分钟完成 Bert 的训练。研究人员对训练速度的渴望从来没有停止过。
那,只用 1 块 GPU 够不够?在推荐系统上,不仅可以,还能将批量大小继续提升!
最近,字节跳动AML(应用机器学习团队)和新加坡国立大学的研究人员提出了一个新的优化方法 CowClip,在公开点击率预测数据集 Criteo 上最高支持 128K 批量大小,在单张 GPU 上训练 DeepFM,可以将 12 小时的训练时间压缩到 10 分钟,性能不降反升!

论文地址:https://arxiv.org/abs/2204.06240
开源地址:https://github.com/bytedance/LargeBatchCTR
为了支持如此大批量大小的训练,保持模型的训练精度,文中提出了一套全新的优化训练方法:通过参数转换公式确定大批量大小下的参数,对 embedding 层进行自适应梯度裁剪。
用了 CowClip 优化方法的不同推荐模型(文中测试了 DeepFM 等四个模型),在两个公开数据集上进行了理论和实验验证,证实了该方法的合理性和有效性。
作者表示,使用该优化方法,任何人都可以很容易的分分钟训练一个中小规模的推荐模型。
CowClip 加速的理论基础
用户交互会成为推荐系统新的训练数据,模型在一次次的重新训练中都学到最新的知识。目前的推荐系统面对着数以亿计的用户和数以千亿计的训练数据,一次完整的训练要花费大量的时间和计算成本。
为了加速推荐系统的训练,目前推荐系统会利用 GPU 进行加速训练。然而,随着 GPU 计算能力和显存的不断增加,过去推荐系统的训练过程没有完全利用好目前 GPU 的性能。举例而言,在 Criteo 数据集上,当批量大小(batch size)从 1K 提升到 8K 后,用一块 V100 进行训练每次迭代所需的时间只有少量增加。这说明在目前的高性能 GPU 上,以往使用的小批量大小不足以充分利用 GPU 的并行能力。
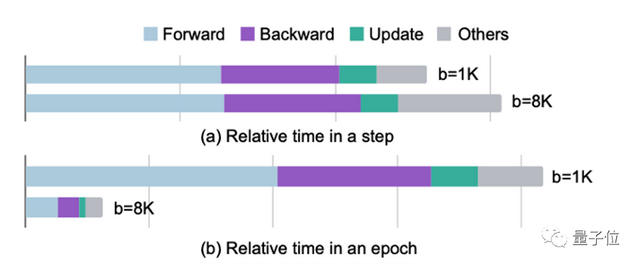
使用更大的批量大小可以更充分的挖掘 GPU 的性能,让 GPU 真正物有所值。只要大批量大小下训练的模型精度没有损失,我们就可以不断提高模型的批量大小,直到塞满 GPU 的显存。
然而防止模型精度损失并不是一件易事。一方面,更大的批量大小可能会使网络训练不稳定,并减弱网络的泛化能力;另一方面,如果没有规则指导在更大的批量大小上进行超参选择,那调参会浪费大量的资源。
文中提出的 CowClip 便希望解决上述问题,通过在嵌入层(Embedding layer)逐列进行的动态梯度裁剪,和一组简单有效的设置不同批量大小下超参数值的方法,让扩大 128 倍的批量大小成为可能。
CowClip 方法
为了让大批量大小下网络的训练更加稳定,研究者提出了自适应逐列梯度裁剪策略(Adaptive Column-wise Gradient Norm Clipping, CowClip)以稳定网络的优化过程。梯度裁剪是一种优化更新过程的方法,它将范数值大于一定阈值的梯度裁剪到范数内。给定一个固定的阈值 clip_t,梯度裁剪过程如下:
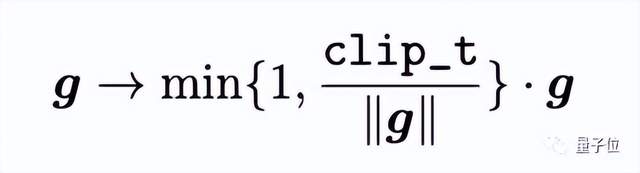
然而直接运用该方法到嵌入层的梯度上效果并不佳。该原因不仅在于难以确定一个有效的阈值,更在于训练过程中,每个特征取值(ID 特征)对应的编码向量(对应嵌入层中嵌入矩阵的一列)在训练过程中的梯度值大小各不相同(如图 4 所示),在全局应用梯度裁剪忽视了不同梯度值之间的差异。
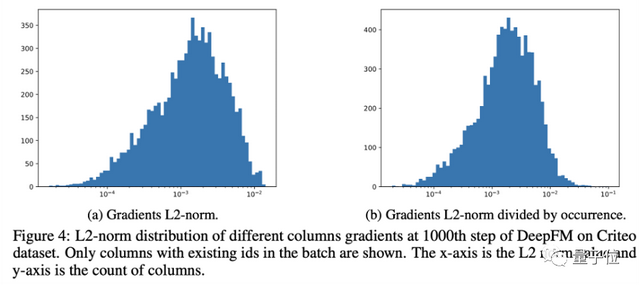
因此,研究者提出对每个特征取值对应的编码向量单独应用裁剪阈值,并自适应地设置该阈值。考虑到如果梯度大小超过参数大小本身时训练过程会很不稳定,研究者提出用特征取值对应的编码向量自身的范数值确定阈值。为了防止裁剪阈值过小,参数 ζ 保证了裁剪值不会低于一定的值。
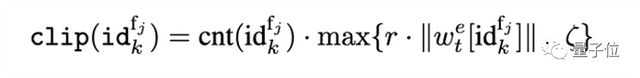
上式中,还需要考虑到由于特征 ID 的总频次不同,在每个批次中出现的次数也不同。为了平衡出现的不同频次,最后获得的裁剪值还需乘以批次中对应频次出现的次数。
基于以上分析,研究者提出的 CowClip 算法如下:

大批量大小下的参数转换
在 CV 和 NLP 任务中,已经有一套扩大批量大小时调整学习率和 L2 正则项参数的方法。常用的方法包括线性调整(Linear Scaling),即在扩大 s 倍批量大小时,扩大 s 倍的学习率;以及平方根调整(Sqrt Scaling),即在扩大 s 倍批量大小时,学习率和正则项参数均以根号下 s 的大小扩大。
研究者首先探索了应用这些调整方法是否能有效的在大批量大小下保持性能。表一左侧的实验表明,当批量大小扩大时,这些方法的性能都出现了一定程度的下降。
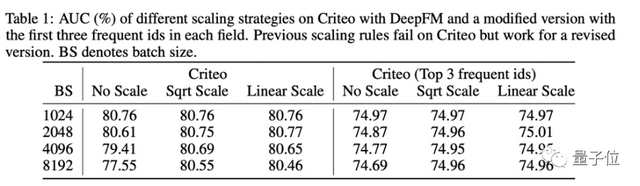
文中指出,以往方法的失败的原因在于,输入的特征 ID 具有不同的频率,而这是 CV 和 NLP 模型输入不具有的特点。举例而言,热榜上的视频播放量高,出现在数据集中的次数也就多,则视频 ID 特征中该视频 ID 的出现频次就远高于一些冷门视频。
为了验证上述想法,研究者改造了一个只包含高频特征的数据集。果不其然,以往的参数调整方法此时可以取得好的结果(表一右侧)。该实验说明了频次分布不一致确实阻碍了之前的参数调整方法,
论文中对该现象还进行了进一步的理论分析。简单而言,如果重新考虑线性调整方法,其背后思想在于当批量大小增大后,更新迭代的步数减小,所以要扩大学习率。但对于出现次数非常少的特征,扩大批量大小时不会减小其更新迭代的次数。
由于点击率预测数据集中绝大部分数据是此类低频的特征 ID,结合 CowClip 方法,对模型的嵌入层可以不做学习率调整,并同时线性增大 L2 参数。
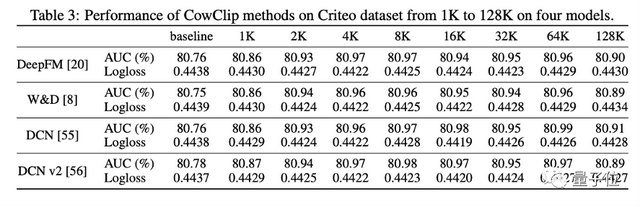
通过最后的实验结果可以看到,利用 CowClip 训练的模型比其它方法不仅精度更高,训练速度也大幅度提升。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK