

Predicted Class Balance
source link: https://bbengfort.github.io/2018/03/prediction-balance/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Predicted Class Balance
This is a follow on to the [prediction distribution]({{ site.base_url }}{% link _posts/2018-02-28-prediction-distribution.md %}) visualization presented in the last post. This visualization shows a bar chart with the number of predicted and number of actual values for each class, e.g. a class balance chart with predicted balance as well.
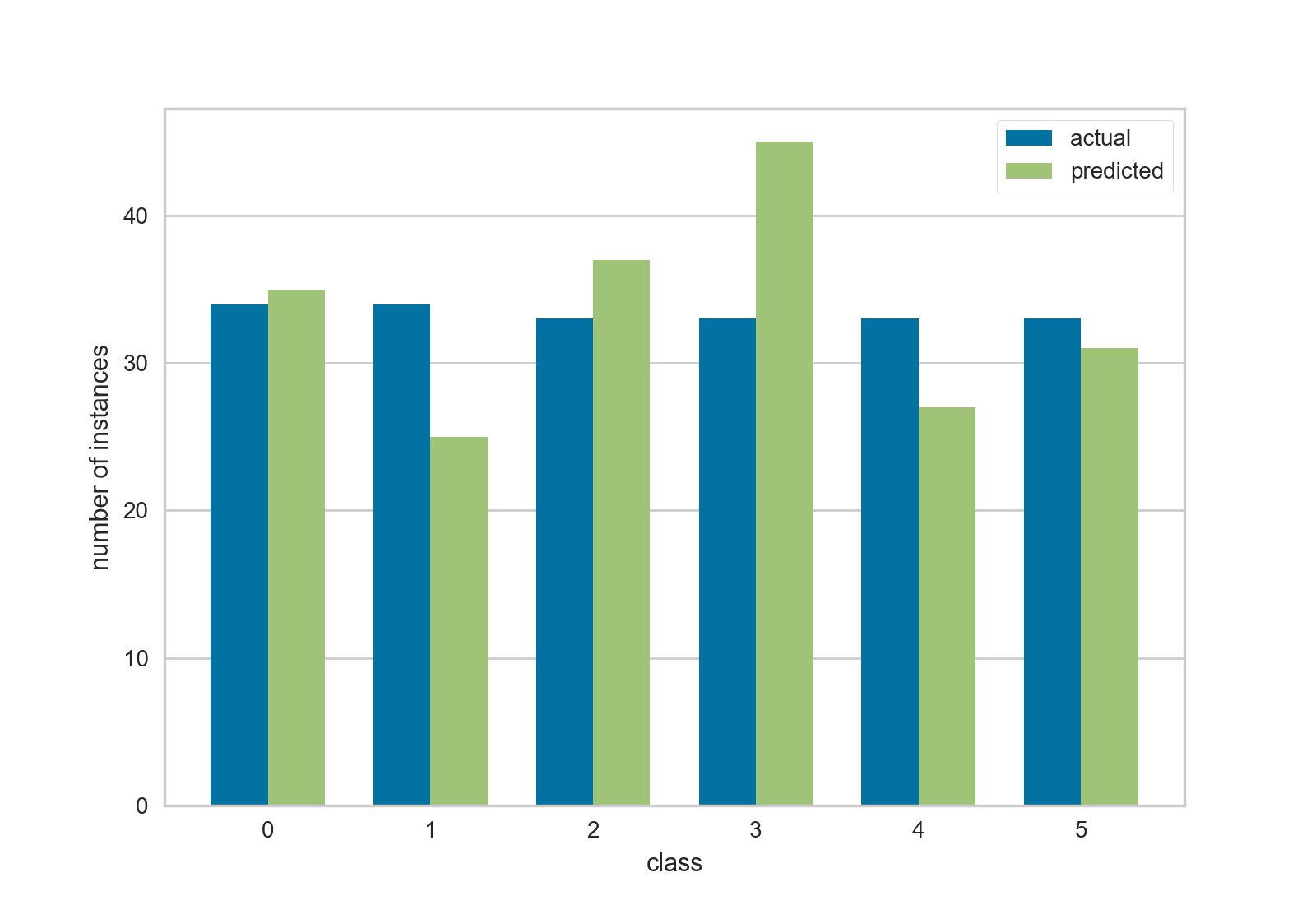
This visualization actually came before the prior visualization, but I was more excited about that one because it showed where error was occurring similar to a classification report or confusion matrix. I’ve recently been using this chart for initial spot checking more however, since it gives me a general feel for how balanced both the class and the classifier is with respect to each other. It has also helped diagnose what is being displayed in the heat map chart of the other post.
The code follows, again prototype code. However in this code I made an effort to use more scikit-learn tooling in the visualization, including their validation and checking code. Hopefully this will help us eliminate problems with various types of input.
import numpy as np import matplotlib.pyplot as plt import yellowbrick as yb # For the styles
from sklearn.base import clone from sklearn.model_selection import KFold from sklearn.metrics.classification import _check_targets from sklearn.utils.multiclass import unique_labels from sklearn.utils.validation import check_consistent_length from sklearn.externals.joblib import Parallel, delayed
def plot_target(y_true, y_pred, labels=None, ax=None, width=0.35, **kwargs): # Validate the input y_type, y_true, y_pred = _check_targets(y_true, y_pred) if y_type not in ("binary", "multiclass"): raise ValueError("%s is not supported" % y_type)
# This is probably not necessary check_consistent_length(y_true, y_pred) # Manage the labels passed in (yb might use classes for this arg) if labels is None: labels = unique_labels(y_true, y_pred) else: labels = np.asarray(labels) if np.all([l not in y_true for l in labels]): raise ValueError("At least one label specified must be in y_true")
# Count the values of y_true and y_pred for each class indices = np.arange(0, labels.shape[0])
# This expects labels to be numerically encoded, not strings # YB needs to handle either case better, though _check_targets # may deal with this, I'm not sure - need to review the code. # Needless to say this is a HACK that needs to be addressed. t_counts = np.array([(y_true==label).sum() for label in indices]) p_counts = np.array([(y_pred==label).sum() for label in indices]) # Begin the figure if ax is None: _, ax = plt.subplots()
b1 = ax.bar(indices, t_counts, width, color='b', label="actual") b2 = ax.bar(indices+width, p_counts, width, color='g', label="predicted")
ax.set_xticks(indices + width/2) ax.set_xticklabels(labels) ax.set_xlabel("class") ax.set_ylabel("number of instances") ax.legend(loc='best', frameon=True) ax.grid(False, axis='x')
return ax
def _cross_validate(model, X, y, cv=6, n_jobs=6): """ Returns y_true and y_pred for all instances using cross-validation """ # HACK: should use sklearn method to get split indices folds = KFold(cv)
splits = Parallel(n_jobs=n_jobs)( delayed(_split_validate)(model, X, y, train, test) for train, test in folds.split(X, y) )
y_true = [] y_pred = []
for y_true_split, y_pred_split in splits: y_true.append(y_true_split) y_pred.append(y_pred_split)
return np.concatenate(y_true), np.concatenate(y_pred)
def _split_validate(model, X, y, train, test): X_train, X_test = X[train], X[test] y_train, y_true = y[train], y[test]
est = clone(model) est.fit(X_train, y_train)
return y_true, est.predict(X_test)
if __name__ == "__main__": from sklearn.linear_model import LogisticRegression from sklearn.datasets import make_classification X, y = make_classification(n_samples=200, n_features=100, n_informative=20, n_redundant=10, n_classes=6, random_state=42)
y_true, y_pred = _cross_validate(LogisticRegression(), X, y) plot_target(y_true, y_pred) plt.show()
This code also shows a cross-validation strategy for getting y_true and y_pred from a classifier. I think this type of code will become a cornerstone in Yellowbrick, so please let us know in the YB issues if you see anything fishy with this methodology!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK