

Java并发编程之:Java内存模型
source link: https://hellolyfing.github.io/2018/07/30/Java%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B%E4%B9%8B-Java%E5%86%85%E5%AD%98%E6%A8%A1%E5%9E%8B.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

前言:Java内存模型详细说明了Java虚拟机(以下将使用JVM这个术语)是如何与计算机的内存(RAM)进行交互的。JVM是一个完整计算机的模型,所以该模型也包含了内存模块,也就是我们熟知的Java内存模型。
想要设计出符合预期的并发程序,了解Java的内存模型是非常重要的。Java内存模型详细描述了不同的线程如何以及何时可以看见被其他线程写入的共享变量,以及在需要时如何同步使用共享变量。
Java内存模型在一开始是不够完善的,不过它在Java 1.5中被改进了。Java8依然在使用这一改进版本的内存模型。
一、一窥Java内存模型的内部
JVM中的Java内存模型将内存分为线程栈(thread stacks)和堆(heap)。下图从逻辑角度演示了Java的内存模型:

在JVM中运行的每个线程都有自己的线程栈。线程栈包含的信息为:当前方法执行到的点。我将称这个栈为“调用栈”,当线程执行代码时,调用栈也会随之变化。
线程栈还包含了每个被执行的方法(所有位于调用栈的方法)内部的所有局部变量(local variables)。一个线程只能访问自己的线程栈。由一个线程创建的内部变量,对其他线程是不可见的。即便两个线程在执行一模一样的代码,他们仍然会在自己的线程栈中创建各自的局部变量。也就是说,每个线程都有自己的局部变量的版本。
所有原始类型( boolean, byte, short, char, int, long, float, double)的局部变量全部都存储在线程栈中,所以它们对其他线程是不可见的。一个线程可以向其他线程传递原始类型变量的拷贝,但无法共享内部的原始类型变量。
堆则包含了所有Java对象(objects),无论它们是由哪个线程创建的,这些对象包括对原始类型封装而成的包装类(Integer、Long等)。无论对象是在局部被创建并赋值给局部变量,还是作为其他对象的成员被创建的。这些对象始终都位于堆中。
下图展示了线程栈中存储的调用栈和局部变量,以及堆中存储的对象:

一个局部变量如果是原始类型的,则它会存储在线程栈中。
一个局部变量如果是对一个对象的引用,则这个变量的引用会存储在线程栈中,但引用的对象则会存储在堆中。
一个对象的方法以及方法内的局部变量,也是存储在线程栈中,即便这个对象本身存储在堆中。
一个对象的成员变量(Field)和对象一样存储在堆中,无论这个成员变量是原始类型还是对对象的引用。此外,静态类变量也是存储在堆中。
处于堆中的对象,可以被任何拥有其引用的线程访问到。当一个线程访问一个对象时,它也可以访问到对象的成员变量(Field)和方法。如果两个线程在同一时间访问同一个对象的方法,他们可以同时调用该对象的该方法,不过每个线程都会拥有一份方法内的局部变量的拷贝。
下图演示了上面提到的那些点:

两个线程有一组局部变量。其中一个局部变量Local Variable 2指向了位于堆中的对象Object 3。这两个线程的局部变量和引用是不一样的,它们存储在各自的线程栈中,虽然二者指向的同一个对象存储在堆中。
注意对象Object 3的成员变量,分别引用了对象Object 2和对象Object 4(注意图中Object 3指向Object 2和Object 4的箭头),藉由对象Object 3中的成员变量,两个线程也可以访问到对象Object 2和Object 4。
图中也展示了:线程栈中的methodTwo()中的局部变量Local Variable 1指向位于堆中的两个不同对象的情况。此时这个引用指向了两个不同的对象(Object 1和Object 5),而不是同一对象。理论上每个线程都可以访问到这两个对象Object 1和Object 5,前提是每个线程都有指向这两个对象的引用。不过在上图中,每个线程只有一个指向两个对象之一的引用。
那么,用什么样的Java代码可以反推出上面的内存图呢?其实,图例对应的Java代码也很简单:
public class MyRunnable implements Runnable() {
public void run() {
methodOne();
}
public void methodOne() {
int localVariable1 = 45;
MySharedObject localVariable2 =
MySharedObject.sharedInstance;
//... do more with local variables.
methodTwo();
}
public void methodTwo() {
Integer localVariable1 = new Integer(99);
//... do more with local variable.
}
}
public class MySharedObject {
//static variable pointing to instance of MySharedObject
public static final MySharedObject sharedInstance =
new MySharedObject();
//member variables pointing to two objects on the heap
public Integer object2 = new Integer(22);
public Integer object4 = new Integer(44);
public long member1 = 12345;
public long member1 = 67890;
}
如果启动两个线程同时执行run()方法,就能得出上图中的那些关系。run()方法调用了methodOne(),methodOne()又调用了methodTwo().
methodOne()定义了一个原始int型的局部变量localVariable1,以及一个对对象引用的局部变量localVariable2。
每个执行methodOne()的线程都会在自己的线程栈中创建localVariable1和localVariable2的拷贝。各线程之间的localVariable1是完全隔离的,只存在于各自的线程栈中。线程A无法看到其他线程对拷贝来的localVariable1做出的改变。
每个执行methodOne()的方法,也都会创建属于自己的localVariable2的拷贝。然而,这两份独立的互不相干的localVariable2拷贝,其引用都指向了位于堆中的同一对象Object 3。从代码中可以看出,localVariable2的引用指向了另外一个对象MySharedObject中的静态成员变量sharedInstance。我们知道对象的静态成员变量只有一份,而且是存储在堆中的。这样一来,两份独立的localVariable2的拷贝最终都指向了MySharedObject对象中的同一个静态成员变量所指向的对象:MySharedObject的实例,也就是上图中的Object 3。
注意观察MySharedObject也包含了两个Integer类型的成员变量。这两个成员变量和对象本身都存储在堆中。二者分别指向了两个即时创建的Integer对象Object 2和Object 4,如上图所示。
注意观察methodTwo()创建了一个局部变量localVariable1。这个局部变量是对一个Integer对象的引用。该方法将localVariable1的引用指向了一个新的Integer对象实例。局部变量localVariable1储存在每个执行methodTwo()的线程的线程栈中。由于每个线程每次执行methodTwo()时都会创建新的Integer对象,所以当两个线程执行该方法时会创建两个独立的Integer对象,即上图中的Object 1和Object 5。
注意MySharedObject对象中的两个原始long类型的成员变量。由于这些变量是原始类型的,所以他们和对象本身都会存储在堆中。只有方法中的局部变量会存储在线程栈中。
二、物理内存的结构
现代的物理内存架构和JVM中的Java内存模型有些不同。为了更好地理解Java内存模型是如何与硬件内存相互协作的,我们也需要了解下物理内存的结构。本节会描述一个常见的物理内存架构,后续章节则会介绍Java内存模型是如何与之协作的。
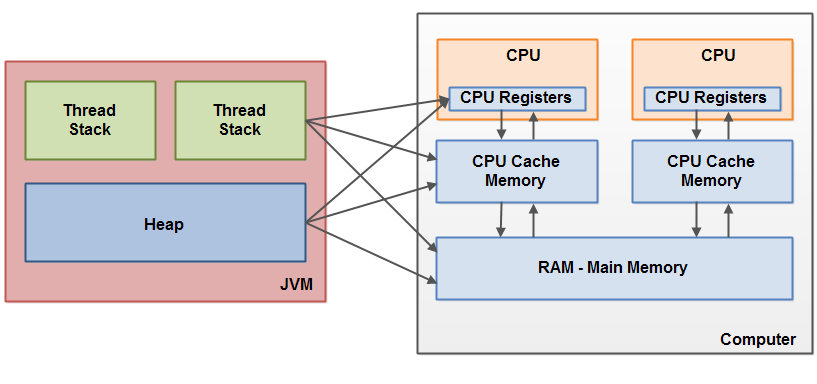
下面是一个简化版的现代计算机硬件结构图:

一个现代计算机通常会有2个或更多的CPU,有些CPU还会有多个核心。关键在于,一个拥有两个或更多CPU的现代计算机,同步执行多个线程任务是完全可能的。每个CPU在任何时间都可以执行一个线程。也就是说,如果你的Java应用是多线程的,那么为每个线程分配一个CPU,同步(并行)地运行的Java任务也是有可能的。
每个CPU都包含了一组寄存器,这些寄存器本质上其实是更靠近CPU的内存(in-CPU memory),我们还是叫它寄存器吧。CPU在寄存器上执行的操作比在主内存(main memory)上要快得多。这是因为CPU访问寄存器的速度比访问主内存要快得多。
每个CPU可能也会有一个CPU缓存层。事实上,大多数现代CPU都有一个大小不一的缓存层。CPU访问缓存的速度虽然没有访问内部寄存器快,但却比访问主内存要快的多。所以CPU访问缓存的速度是介于访问内部寄存器和访问主内存之间的。有些CPU可能会有多层级的缓存(Level 1 and Level 2等),但这跟理解Java内存模型的原理关系不大,重要的是了解到CPU有一个缓存层。
计算机还有一个主内存(main memory area,即RAM)。所有CPU都可以访问主内存。主内存的大小通常也比CPU的缓存更大一些。
通常情况下,当CPU需要访问主内存时,它会读取部分主内存中的信息放入CPU缓存。CPU也会读取部分缓存中的信息放入内部寄存器,然后在其之上进行操作。当CPU需要把计算结果写回主内存时,它会先把内部寄存器的值flush(拷贝后清空)至缓存,然后在某个时间点再把缓存中的值flush至主内存。
CPU缓存中的值flush至主内存,通常发生在CPU需要在缓存中存储其他值时。在某个时间点,CPU缓存中写入的数据只占了缓存空间的一部分,同样在某个时间点,它会flush back部分数据至主内存。当数据更新时,它并不需要读取或写入整个缓存。通常情况下,缓存以一个更小的内存块来更新,这个内存块就叫做”缓存行”(cache lines)。一条或多条缓存行会被读入缓存中,另外一条或多条缓存行又会被flush back至主内存中。
三、打通Java内存模型与物理内存结构
上面已经说过Java内存模型和物理内存结构是不同的。物理内存结构不会区分线程栈和堆。在硬件层面,线程栈和堆都是存储在主内存中的。部分线程栈或堆的信息会出现在CPU缓存及内部寄存器中。线程栈和堆在CPU寄存器、缓存以及主内存中的存储关系如下图所示:
当对象和变量存储在计算机中不同的存储区域(如CPU缓存和主内存中)时,某些问题便会出现。两个主要的问题有:
- 线程更新共享变量时的可见性
- 共同读、检查以及写共享变量时引发的竞争情形(Race conditions)
下面章节会讨论这两个问题。
3.1 共享对象的可见性问题
如果两个或更多的线程共享同一对象,又没有恰当地使用volatile声明或synchronization声明,那么当线程A更新共享对象的信息时,其他线程可能看不到。
想象一下,共享的对象一开始存储在主内存中。运行在CPU-1中的线程A将共享对象读入CPU缓存中,接着对共享对象做了一个更新操作。只要CPU-1中的缓存没有被flush back至主内存,那么共享对象变更后的版本对运行在其他CPU上的线程便是不可见的。这样一来,运行在不同CPU中的线程,在各自CPU的缓存中都会对共享的对象有一份各自的临时拷贝。
下面的图例演示了这种情况:运行在左侧CPU中的线程将共享对象拷贝至CPU缓存中,然后将该对象的count变量更新为2. 但这个变更对运行在右侧CPU中的线程是不可见的,因为此时更新后的count值还没有被flush back至主内存中。
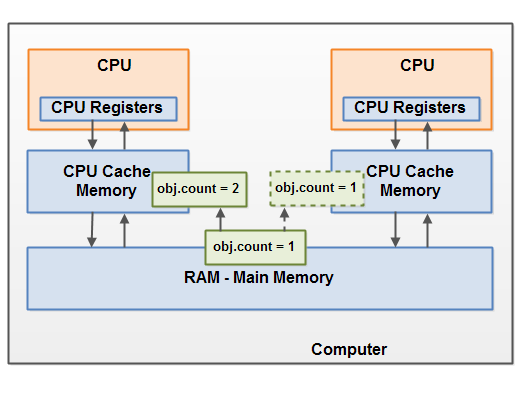
你可以使用Java中的volatile关键字来避免这种情况。volatile关键字可以保证在读取给定变量时直接从主内存中读取,当变量值更新时又会被写回主内存中。
3.2 竞争情形(Race conditions)
如果两个或以上的线程共享同一对象,并且有一个或多个线程在更新共享的对象,竞争情形便会出现。
想象一下:线程A将共享对象的count变量读入CPU缓存中,接着线程B也做了同样的事,不过读入了另外一个CPU缓存中。现在线程A将count加1,线程B也会这么做。那么count变量实际自增了两次,分别在两个CPU缓存中完成。
如果这些自增是按顺序执行的(即在同一CPU缓存中执行),那么count变量会被自增两次,最后以count + 2的结果写回主内存。
然而,这两次的自增实际上是并行执行的,并且没有保证顺序。尽管线程A和B分别对count自增了一次,之后也会将更新后的结果回写至主内存,但最终的结果是count只增加了1。
下面的图例演示了上面提到的竞争情形:
你可以使用Java中的synchronized结构体来避免这种情况。一个synchronized代码块保证在同一时间只有一个线程可以进入关键区域执行代码。Synchronized代码块也会保证所有包含在代码块中的变量,直接从内存中读取,在线程步出代码块时,所有更新过的变量会被回写至主内存中,无论这些变量是否用volatile声明过。
本篇文章翻译自:http://tutorials.jenkov.com/java-concurrency/java-memory-model.html
后记:前段时间看《Java并发编程的艺术》这本书,发现书中对volatile关键字的介绍有些深入不浅出。后来在网上找相关资料时发现了这个并发编程系列的博客,一读之后豁然开朗,于是便有了翻译过来与各位共享的想法。后续还会继续翻译一些该系列中的博客。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK