

延迟:安全 vs 性能
source link: http://gywbd.github.io/posts/2015/7/latency-security-and-peformance.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

延迟:安全 vs 性能
2015-07-27
这是一篇非常棒的文章,对于数据库的性能我们更多的只会关注SQL语句的查询性能,很少会关注应用程序跟数据库交互过程中的延迟,而大多数时候我们会觉得延迟是网络访问所固有的,或者说是没有办法可以用于降低延迟,但是事实并非如此,实际上有很多方法可以用于降低延迟,而且通过降低延迟可以给程序带来非常大的性能改进。
我曾经在一个客户的圣诞party上听到过一个网络工程师和一个高级经理的闲聊,聊天的内容大概是网络工程师说防火墙会给应用服务器和数据库之间的每次交互(round trip)额外带来大概0.2毫秒的延迟,在某些特殊的情况下这个时间累积可以达到几个小时。经理听到这个观点后就问这种情况应该怎么解决,然后网络工程师给出了两个解决方案:
- 修改应用程序减少它与数据库间的交互次数
- 把防火墙关了,忽略安全上的威胁
搞笑的是后来搞网络的家伙解释说第二种方案需要经理签字,因为这样才能绕过公司的安全规范,并且出了事有人背锅。
如果你是那个经理,你会签字么?
反正我是不会的,而且我的客户也不会同意——要不然这就是违背了我当初给他们的建议。
在这篇文章中我会解释延迟的含义,然后对为什么我们有时候会搞出一些高延迟的应用发表下个人的见解,最后介绍几个降低延迟的方法。
去超市购物
我见到过的对延迟最好的解释出自于RoughSea。他们做了一个视频,里面用“去超时购物”这个行为来讲解延迟(简化版):
- 开车去超市
- 找到要买的东西(例如,牛奶)
- 把买的东西放到车上
- 把东西储存起来(例如,放到冰箱中)
- 然后再把上面的过程重复一边去买下一件东西(例如,麦片)
这个大概20分钟的视频非常不错,除了延迟外还有很多跟数据库优化相关的东西。如果你只是想看延迟相关的部分,可以通过这个youtube的链接进入。
当你看了这个视频,你可能会感叹:“我靠”。如果你是这样去超市买东西的话,你会在路上花费很多时间,而真正的买时间却只占很少一部分。
应用程序和数据库间的网络连接就是这个例子中的路。如果你的架构需要应用程序层和数据库层之间频繁的交互,这就可能导致严重的性能问题——不管你的网络传输到底有多快。
这是怎么发生的呢?
首先需要考虑两个问题:
- 怎么会有人以这种方式来开发软件?
- 0.2毫秒的延迟可以带来多大的问题?
我们先看下0.2毫秒的问题。这个值是由上面说道的网络工程师提供的,它是使用防火墙后带来的额外的延迟。在没有防火墙的时候,这也是一般网络的最高延迟。对于交换式局域网,在没有防火墙的时候,它通常的延迟时间为0.1-0.2毫秒。如果防火墙额外导致0.2毫秒,那么每次交互的总延迟时间就会达到0.4ms。换句话说,2500次交互会带来1秒的延迟。2500次交互看起来很多,但事实并非如此。这主要是因为没有什么任务是可以在一次交互中完成的。
现实中的程序需要执行很多不同的SQL来完成一个任务,并且单个SQL语句可能需要多次交互才能完成。例如,Oracle中的SELECT语句需要至少两次交互,所以一个需要执行10次SELECT查询的任务总的延迟时间会是8ms。更复杂的应用可能会执行100条SQL语句——这个意味着会有80ms的延迟。我见过执行5千万条SQL语句的批处理任务,所有交互造成的延迟加在一起有10个小时!
为什么?为什么会这样?
因为这样的程序开发起来更容易。实现起来也更快,错误也会更少。我们再来看下购物的例子。它的算法很简单;只需要重复所有步骤直到购物清单上的物品都买完为止。这很容易搞定——不管购物清单有多长。
当我们意识到在路上花费了很多时间后(这不是废话么,谁都看得到),我们可能会对这个算法做如下的改进:
- 开车去超市
- FOR EACH ITEM :找到存放位置(牛奶,麦片)
- FOR EACH ITEM :放到汽车里
- FOR EACH ITEM :把物品储存起来(例如,冰箱,餐柜)
现在把之前只需要循环一次的算法分割成为3个循环,它们存在于整个购物过程中。这个修改增加了购物的复杂度。更糟糕的是,修改后算法引入了几个复杂的场景,这些场景中有可能会出现更复杂的错误。例如,如果购物清单非常长,那么整个车子会装不下。在应用程序中,我们需要对这些复杂的场景进行特殊的错误处理。对于装不下的问题,我们可以对这个算法做进一步的修改,比如把大的清单分成多个小的清单,然后每次只完成其中一个小的清单,这使得每次都可以装下所购买的物品。然而,这么做又进一步增加了复杂度——也进一步增加了开发时间,而且也引入了更多需要测试的场景。此时你只有做更多的努力——特别是溢出(overflow)的情况很难测试。
顺便提醒下:买的东西太多导致车子放不下,这种情况在现实中发生的可能性很小,尽管理论上是可能的。不过这在计算机程序中就很常见了,特别是你必须得考虑这种边界情况。以我个人经验来看,一般情况下产品发布后的一年内碰到这种情况的概率为60%。
在软件复杂度和软件性能之间我们总是会做一定的权衡,这其实更应该开作是软件开发速度和软件运行速度间的权衡。如果你是一个程序员,并且总是有人催着你要尽快把程序开发完,快点发布上线——那么在这种情况下,你会选择实现哪种算法呢?
这就是为什么最后我们总是会搞出一些高延迟的应用来的一个原因,而且每当出现这种性能问题的时候,我们总是会说:“这在开发/测试环境中运行起来是没问题的啊”。
开发工作通常是在桌面环境中搞定的,在这种环境下所有东西都是安装在同一台计算机上。很显然,在这个环境中是不会有防火墙,而且有时候也不需要通过网络访问数据库。在这种开发环境中出现的延迟只是拥有多层架构的生产环境中出现的延迟的很小部分(大概十分之一吧)。如果我们还是以购物的示例来类比的话,开发环境就相当于是把超市开在厨房旁边,这对于生产环境显然是不现实的。
怎么避免这种延迟?
我们现在开始关注技术方面的东西。什么技术可以降低与数据库的交互次数?下面的列表中展示了三种最有效技术:
- 使用join
- 使用分组/批量(array/batch)处理
- 使用更高级的技术(open cursors,fetch buffer,bulk/implicit commit, …)
通常有一种反模式(anti-pattern)的方法:先从一个SELECT语句中查询出结果集,然后循环这个结果集中的每一行,然后再对循环的每一行执行另外一个SELECT语句。我把这种方法称为嵌套(nested)select,这跟嵌套循环(nested loops)join相对应。这两种方法都可以达到同样的目的;先从表A获取出所有需要数据,然后循环所有从表A中获取的数据,每次循环都会从表B中查询相应的数据。嵌套select需要额外的交互,这会带来不必要的延迟。避免延迟的最重要的方法是减少SQL语句的数量。
嵌套select可以随意扩展。嵌套的层级可以更深,或者某个层级可以包含多个嵌套select。上面提到的包含五千万个SQL操作的批处理任务光是延迟就花费了10个小时。这个任务会对主查询结果的每一行都执行10个额外的子表查询,而主查询返回的数据是百万级的,可以想象这会有多少次SQL查询操作,这些SQL操作加在一起的延迟达到10个小时也就不难理解了。
最终开发的程序会导致这么高的延迟有时候并不是程序员的问题,这既有组织上,也有技术上的原因。首先,公司一般都会有代码规范,代码规范都会规定如果有合适的函数可以用于获取需要的数据的话,那就不应该写额外的SQL语句。另外一个是主表(main table)和嵌套查询间有一定的依赖关系,主查询(main query)中结果集可能会决定嵌套select中查询的表或者是查询的参数。我们假设需要处理三种不同的情况,最好的解决办法是使用三个不同的SQL语句。如果需要一个单一的结果集(例如,存在order语句),那就使用UNION。
所以如果使用了join,10个小时的延迟就不会存在了,最终执行时间只需要2个小时,而不是12个小时。
(译者注:这里说的嵌套select并不是我们通常说的嵌套子查询,而是在应用实现过程中,先从一个表中查出一个结果集,然后对这个结果集进行循环,每次循环都会执行一个select语句。而这里并没有说怎么使用join,作者的意思是把这种通过程序实现的嵌套select直接改成join查询,这就可以极大地减少SQL语句的数量,这只是降低延迟的一个思路,因为有时候这种嵌套的select语句并不一定能转换为join。)
批量执行(batch execution)
第二种可以较好地降低延迟的技术是使用批量执行——也被称为分组执行(array execution)。很多数据库都支持一次执行多条SQL语句。尽管JDBC也提供对批处理的支持,但是程序员有时候却没有在开发中使用这个功能,这也是有一些原因的:
- 恐怖的错误处理
尽管API定义了一些方法来确认哪些语句执行失败了,但是API都很2。更糟糕的是当批量执行因为错误而停止执行的时候,却没有定义任何方法来处理错误。我的最佳做法是在批量执行之前设置一个savepoint,如果出错了,则会回滚到这个savepoint。 - 批量执行的量太大
批量执行的量太大也会带来问题。以超市购物为例,这就相当于购物清单太大,对于这种情况只有执行多次的批量操作,相当于把整个大的批量操作分成多个小的批量操作,这也是一件很麻烦的事情。 - 不要总是想得赶快把工作做完
一般情况下,怎么样做才能真正的实现性能提升跟所使用的数据库有一定的关系。例如,如果希望批量执行能够给Oracle数据库的性能带来提升,那只有在使用PreparedStatments时才有效。如果使用的只是Statement对象,则不会提升任何性能。但是MYSQL却可以从Statement的批处理中获益。对于这一点,我建议只有有可能就使用PreparedStatments,这总是可以带来性能改进。 - JDBC API不可用
首先你必须检查驱动器是否支持这个API。在现实的程序中,我建议创建一个抽象类,它会检查是否支持这个API,如果不支持的话,则可以将批量执行改成单个语句一条一条地执行,理想情况下,JDBC会为你搞定批量处理。
这里还有很多其他的重要问题,这些问题都需要我们极大的努力才能搞定,确定什么时候使用批量处理就是其中之一。当然我们必须坚信所有的努力都会得到回报。在很多情况下,使用PreparedStatement批量执行两个语句所需要的时间不会超过单个语句的执行时间,这样使用批量执行会至少得到2倍的性能提升。对于一些简单的SQL语句,速度提升10倍是很容易达到的。很明显,这都需要我们的努力才能实现。
还有很多可以减少延迟的方法,它们大体上可以分成两类:基于SQL或者基于API。
我们先来讨论基于SQL的情况:
- Join
之前说过,这里再次提醒一下,这是最有效的降低延迟的方法。 - 使用IN语句
我们可以使用IN语句来从同一个表中获取多条数据,它只需要执行一次。遗憾的是,SQL并不能保证返回的结果集的顺序跟IN语句中的顺序一致。可以通过增加一个额外的层来处理这种情况(例如,使用HashMap)。另外一个潜在的问题是IN语句可以包含的元素的个数是有限制的——Oracle中最多可以包含1000个:ORA-01795。如果可以达到这个量,这未尝不是个好机会,因为这也表示这么多的数据可以一次性地从数据库返回,极大地减少了延迟。不过有时候当IN中的元素个数很大时,也许Join可能会是更好的选择——重要的东西要不断说。 - UNION
如果需要从两个具有相同表结构的表中获取数据,你可以使用UNION实现一次性获取。例如,一个CURRENT表和一个HISTORY表,它们包含了数据的版本信息。如果要获取当前的和所有过去的版本信息,两个表都需要查询。另外一个例子是预先计算好的集合数据( pre-calculated aggregates),一个表包含了到昨天为止的每天的销售量的总数,另外一个表包含了当天的所有的新的销售记录,现在要查找到目前位置每天的销售的总量,一般情况下也需要分别查找两个表。 - RETURNING语句
如果使用squence来进行insert操作,你一般需要两步,先获取key,然后再插入一行。Oracle数据库的解决方案是在INSERT语句中使用RETURNING语句。尽管JDBC的API自从3.0版就认识到了这个问题,但是Oracle的实现却并不是太有效——它返回的是ROWID。不过还是有一些可行的变通方法。
(译注:Sequence是数据库系统按照一定规则自动增加的数字序列,这个序列一般作为代理主键。我大概查了下,这个特性在Oracle,DB2和Postgresql中都有支持,但在Mysql和SQL Server中却没有得到支持,但有一些变通方式可以实现这个效果。这可以实现批量的插入操作(貌似也支持更新和删除操作),主键是sequence序列负责生成的。如果要在程序中使用的话,就需要用RETURNING语句,这样每次调用JDBC的API时会返回一个主键,但问题是在3.0版中返回的是ROWID(不知道现在的版本返回的是什么,很久没有关注Java了),而这个ROWID确实一个字符串类型的,具体请参见Oracle论坛上提到的变通方法)。
- 1*1的笛卡尔集或者cross join
我们偶尔也会用到所谓的笛卡尔集(把所有一切都连接起来(everything with everything)),但是它可能会产生出非常巨大的结果集。这也是为什么SQL-92中会引入了一个不同的关键词,这个关键词就是CROSS。两个只返回单行结果的语句的笛卡尔集最终得到的结果集还是一个单行数据:
SELECT a.*, b.* FROM a CROSS JOIN b WHERE a.id=1 AND b.id=2
这个技术可以用于把多个只会返回单个行的语句结合起来,最终只需要一条语句就可以搞定,显然这只会与数据库服务器发生一次交互。不过请注意这个技术只能用于返回单行数据的查询语句上,这里所说的单行就是确切的一行,不会返回多余一行的数据,也不会返回0行的数据。这个技术一般不会作为首先,只能算是一种奇巧淫技。
上面介绍的就是一些可以用于减少延迟的方法,这些方法基本上都是SQL方面的技术。另外一种降低交互次数的策略是以不同的方式使用API:
- 批量执行
再说一边重要的东西要不断重复 - 打开的游标 (open cursor)
如果同一个SQL语句会执行多次,那么应该使用同一个PreparedStatement的实例(instance)来执行这个SQL语句。每个Statement的第一次执行都需要一次额外的交互来打开游标(open the cursor)。重复使用同一个PreparedStatement的实例可以避免这次额外的交互。它还有另外一个作用,可以减少解析(PARSING)的开销(参见:解析开销的说明)。
另外打开的游标的数量有一定的限制,所以永远不要忘记在用完后把它关掉。 - 增加PreFetch的数量
Oracle数据库的网络层可以使用一种名为PreFetch的技术来减少SELECT语句所需要的交互次数。查询的结果集并不是一行数据一行数据地传输的,而是一定数量的行的合集会在一次交互中一起传输的。Oracle的客户端库(client library)会透明地处理PreFetch,并且能够保证一行接着一行的逻辑。对于SELECT语句,PreFetch跟INSERT/UPDATE/DELETE语句的批量执行一样强大,对于大的结果集,它可以非常有效地降低延迟,差不多可以实现几个数量级上的改进。Oracle JDBC驱动器默认一次交互最多可以获取10行数据。JDBC标准提供了改变这个值的方法:Statement.setFetchSize(20):将应用程序一次读取的行数设置为20行,这不会影响返回的记录小于20行的情况。
更新2010-01-29:为了反映我的最新发现,我对这一部分做了点修改,可以参加我的最新的文章:Oracle JDBC PreFetch Portability。
下面的图表现显示了使用不同的PreFetch的大小执行select的情况。第一组会从数据库查询40000行。当PreFetch的大小被设置为第一次的2倍的时候(红色表示PreFetch被设置为10,绿色是20),总体的查询时间降低了一半。其他两组只执行一个返回20行的查询语句,这个语句会被执行1000次。重复执行可以使用打开的游标优化(open cursor optimization)。这两个都使用了PreparedStatement,中间的柱状图表示每次查询执行完后PreparedStatement会被关闭掉。最后一组跟中间一组的情况相同,除了PreparedStatement在开始的时候会创建一次,在1000次查询的过程中会被不断重用,所有查询执行完后才会关闭。
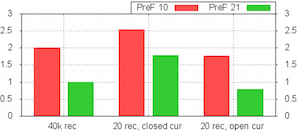
PreFetch的大小设置为10,并且每次都关闭游标(closed cursor)的情况跟PreFetch的大小为20使用“打开的游标(open cursor)”的延迟时间的差异大概有70%,后一种情况的延迟时间相对于前一种情况减少了70%。
在这个简单的统计实验中执行的select语句都很简单,基本上可以认为是立即执行完毕。统计结果基本上反映了使用上面的一些优化策略可以带来的最大的改进。
网络复杂度的增加会带来额外的延迟,这可能会对应用程序的性能造成影响。
有很多方法可以降低服务器之间的交互次数,这可以减少网络延迟对应用程序的影响。这些方法基本都需要修改应用程序的处理流程,这反过来又会增加应用程序的复杂度。
“受限于防火墙”的应用程序有一些竞争优势,以及可以让人们对生产环境的复杂程度有一定的意识。
最后你请发挥你的想象力找到更多可以减少延迟的方法。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK