

[翻译]Kaldi中的解码图构建过程-可视化教程
source link: http://placebokkk.github.io/kaldi/2019/06/28/asr-hclg.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
[翻译]Kaldi中的解码图构建过程-可视化教程
Jun 28, 2019
注:本文翻译自 Decoding graph construction in Kaldi: A visual walkthrough, 并增加了一些解释。
建议读者阅读此本文前先阅读wfst speech decode的论文以及kaldi的解码图构建文档
草稿,需要校审
专有名词
- Grammar fst(G) 语法模型,建模文本的概率,即N-gram语言模型,其实G是个FSA(acceptor),即输入和输出是一样的FST.
- Lexicon fst(L) 词典模型,建模音素序列到词序列之间的关系
- Context-Dependent fst(C)建模上下文相关音素序列到单音素序列的转换关系
- HMM fst(H) 建模上下文相关音素HMM中的边序列到上下文相关音素序列的转换关系。
- self-loop 自跳转,fst中从当前state跳出仍回到该state的边
- ui-gram 一阶语言模型,当前词的条件概率和上下文无关
- bi-gram 二阶语言模型,当前词的条件概率只和前一个词有关
- backoff 语言模型中,对于训练集中缺失的N阶gram,使用N-1阶的概率进行估计
- recipe kaldi里的完成某个任务整个可执行脚本
- mono-phone 上下文无关单音素
- cd-phone 上下文相关音素,音素由于前后的音素不同会产生不同的发音,因此我们使用上下文相关音素建模往往比单音素要好。
- transition-id kaldi解码fst的输入单元,每个transition-id对应一个(phone, HMM-state, pdf-id, transition-index)元组
- pdf-id pdf-id的个数是决策树绑定后的聚类个数,也是声学模型中GMM的个数或者神经网络的输出节点个数。
最近我在使用kaldi时,识别错误率(WER)超过了40%,远高于我用的语言模型和声学模型应该达到的错误率。经过一番折腾,终于找到了原因 – 我没有在lexicon fst(L)里加上自跳转(self-loop)。
在kaldi中,为了使得Grammar fst(G)是determinizable的,G中back-off的边上使用了特殊的’#0’符号(而不是epsilon,否则G就是non-determinizable的),因此为了使得L和G进行compose操作时可以经过G中输入是’#0’的边,需要在Lexicon fst(L)加上一个自跳转. 因为忘记加这个自跳转边,我的bigram G中back-off边在compose时就被忽略了,使得语言模型缺少了backoff,即解码图里只存在训练集中见过的bigram的路径,从而导致了很高的错误率。而加上self-loop后,不用做其他任何改变,WER就下降到17%。
这个问题让我意识到自己对于解码图构建过程中的细节理解不够深入,所以我决定花些时间认真研究一下。然而,对于大词汇量的hclg而言,各级fst都太大,很难直观看懂,我尝试过用GraphViz将解码图转为可视化图片,即使用的模型量级远小于LVCSR的规模,其占用的内存和cpu也非常巨大。另外,即使机器性能足够强大可以转化为图片,人类也几乎看不懂被优化过的大规模HCLG wfst(至少远超我的理解能力)。所以本文中,我构建了一个非常小规模的解码图来演示整个构建过程以帮助理解,这中通过小型例子理解原理的方式也是工程和科学中很常用的方法。有一些很好的关于WFST解码的资料很值得阅读,包括著名的hbka.pdf(WFST的圣经) 以及Dan Povey写的非常棒的kaldi解码图构建recipe,本文可以作为上述资料的补充。
本文使用规模很小的grammars和lexicon来演示完整的HCLG构建过程. 语言模型方面,会用unigram和bigram演示G fst的构建,而在逐级构建HCLG时为了容易理解,仅使用unigram演示。下面是训练语言模型使用的语料
K. Cay
K. ache
Cay
对应的unigram语言模型是:
\data\
ngram 1=5
\1-grams:
-0.4259687 </s>
-99 <s>
-0.60206 Cay
-0.60206 K.
-0.9030899 ache
\end\
对应的Bigram语言模型是:
\data\
ngram 1=5
ngram 2=6
\1-grams:
-0.4259687 </s>
-99 <s> -0.30103
-0.60206 Cay -0.2730013
-0.60206 K. -0.2730013
-0.9030899 ache -0.09691
\2-grams:
-0.60206 <s> Cay
-0.30103 <s> K.
-0.1760913 Cay </s>
-0.4771213 K. Cay
-0.4771213 K. ache
-0.30103 ache </s>
\end\
lexicon仅包含三个词,其中两个(Cay和K.)是同音词(homophone).
ache ey k
Cay k ey
K. k ey
为了使解码图尽可能简单易懂,总共的音素(phonemes)只有两个(ey和k),从而将cd-phone变换为phone的C fst不会太复杂,
本文用于生成解码图和pdf图片的脚本在这script,其中也包含了该文章中展示的各fst的pdf文件,对于一些比较大的fst,可以直接打开pdf放大看.在使用里面的’mkgraphs.sh’脚本前,你需要先配置”KALDI_ROOT”指向机器上Kaldi的安装根目录。
语法FST的构建(G)
参考Kaldi中关于解码图创建的文档,使用如下命令产生G fst。相比于文档给出的过程,这里省略了移除OOV(out-of-vocabulary,语言模型中的词不在lexicon里)的步骤,因为这个例子里没有OOV的情况:
cat lm.arpa | \
grep -v '<s> <s>' | \
grep -v '</s> <s>' | \
grep -v '</s> </s>' | \
arpa2fst - | \ (step 1)
fstprint | \
eps2disambig.pl |\ (step 2)
s2eps.pl | \ (step 3)
fstcompile --isymbols=words.txt \
--osymbols=words.txt \
--keep_isymbols=false --keep_osymbols=false | \
fstrmepsilon > G.fst (step 4)
最终的产生G的fst如下图:
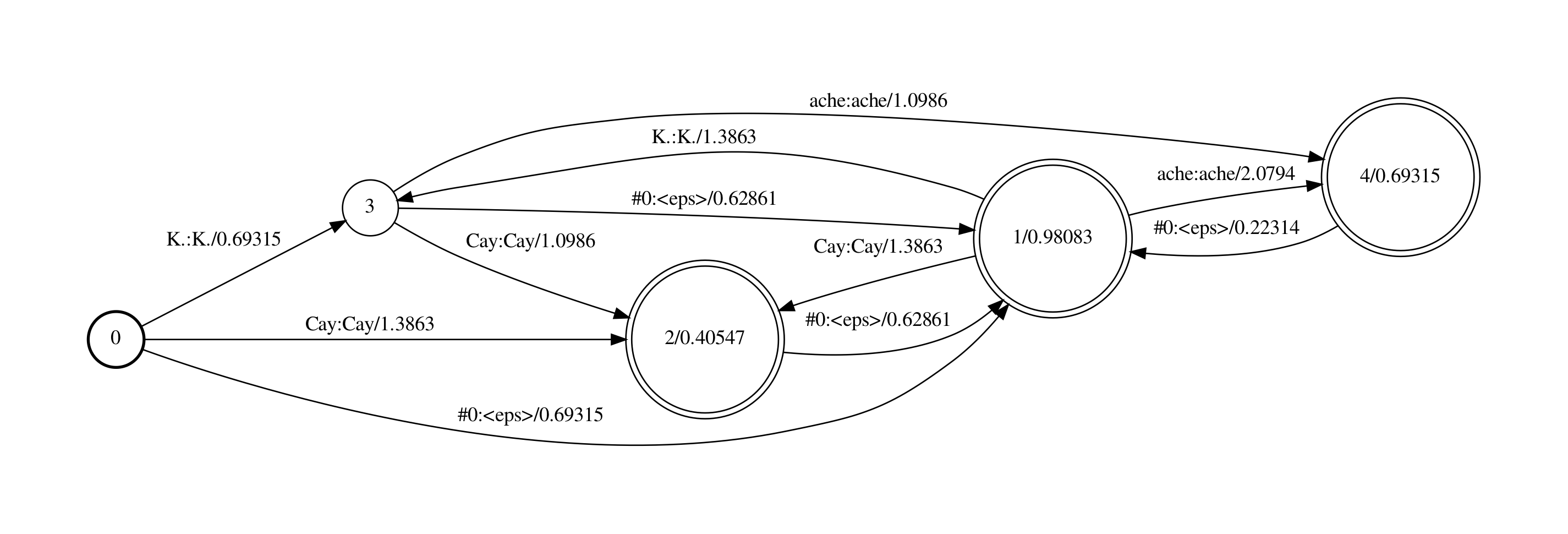
下面我们一步一步来看这个脚本命令对bigram语言模型做了什么。
step 1
首先,将语言模型中的非法的<s>和</s>的组合移除,因为这些组合会导致G fst是non-determinizable的(译注:我不清楚为啥是non-determinizable,但是假如arpa确实因为某种原因包含了这些组合,在G里引入这些组合是无意义的)。然后由arpa2fst命令将arpa转为binary格式的FST.
注意,fst中的权重是对概率计算自然对数再取负,而ARPA文件中的数值是对概率计算以10为底的对数。
解释下G fst
n-gram包含的信息
对于n-gram模型,其中包含了1阶到n阶的gram概率以及backoff权重, 比如2-gram里包含了1-gram和2-gram的概率,以及回退到1-gram的bow(backoff weight)值。这些信息都可以用fst来表达。
- 1-gram: p(*) , bow(*)
- 2-gram: p(*|<s>),p(*|Cay),p(*|K), p(*|ache)
fst中状态和边的含义
ngram包含的信息也可以用fst来表示,在fst中,不同的state(S)节点对应不同的历史词(history,下文中用h表示)。
在n-gram fst里,包含n类state节点,分别记录0到n-1长度的h。
比如2-gram,需要2类S
- 第1类S对应的
h的长度为0,即没有历史词,其跳出边表示的是1-gram的概率。 - 第2类S对应的
h的长度为1,即历史词长度为1,其跳出边表示的是p(∗∥h)p(∗‖h),即以h为历史的各2-gram概率。
在fst里引入bow的方法
对于n-gram, p(x∥hn−1)p(x‖hn−1)回退公式为bow(hn−1)∗p(x∥hn−2)bow(hn−1)∗p(x‖hn−2),在G fst里为了引入backoff路径,需要加一条从hn−1hn−1对应的S到hn−2hn−2对应的S的边,其概率为bow(hn−1)bow(hn−1)。 举个例子,若SpSp 对应的h是ABC,SqSq 对应的h是BC,引入一条SpSp到SqSq的边,该边的weight为bow(BC)。
n-gram转换为fst后的状态数
- 2-gram G fst里有 1+1+1+V1+1+1+V 个状态,V是词典大小(包括<s>,不包括</s>)。
- 类似的,3-gram G fst里有 1+1+1+V+V21+1+1+V+V2个状态,V是词典大小(包括<s>不包括</s>),V2V2是所有p(x|h)中len(h)==2的不同h的个数.
示例中fst分析
- 0和1状态对应的h为空,这里区分出0和1两个状态,0状态上的唯一跳出边表示p(<s>),1状态上的跳出边表示除了p(<s>)以外的1-gram概率p(*)
- 这里区分出0和1状态是因为1状态可以接受来自于高阶状态的bow边,而0状态不可以。因为p(<s>)只能出现在句首,而不能出现在backoff中,即不存在p(<s>|h) = bow(h) * p(<s>),如果不区分,backoff时就会引入p(<s>|h) = bow(h) * p(<s>)的路径。
- 2,3,4,5,6 状态对应的h长度为1,其上的跳出边分别表示 p(*|</s>) p(*|<s>),p(*|Cay),p(*|K), p(*|ache)
- 注意2状态对应的h为</s>,</s>一定是句子的最后一个词,所以这个状态不会有跳出边。
前面说了在G fst里,第n类state节点对应了某个长度为n-1的h,可以验证下,从该state往前看n-1步跳转,输入的label是一样。比如:
- 对于state 1,其对应的h是’‘,所以所有进入state 1的边都是’epsilon’,而state 1的跳出边表示的p(*)。
- 对于state 5,其对应的h是’K’,所以所有进入state 5的边都是’K’,而state 5的跳出边表示的p(*|K)。
我们看一下”<s> ache”这个bigram词串在fst中的路径,因为在训练语料中没有p(ache|<s>)这个bigram概率,因此计算存在back-off,”<s> ache”对应的路径为0到3,3到1,1到6. p(<s> ache) = p(<s>) * p(ache|<s>), 而其中p(ache|<s>)= bow(<s>) * p(ache)
- 0到3的权重是0, p(<s>);
- 3到1的权重为0.69315,即bow(<s>)=−ln10(−0.30103)
- 1到6的权重为2.0794,即p(ache)=(−ln10(−0.9030899)
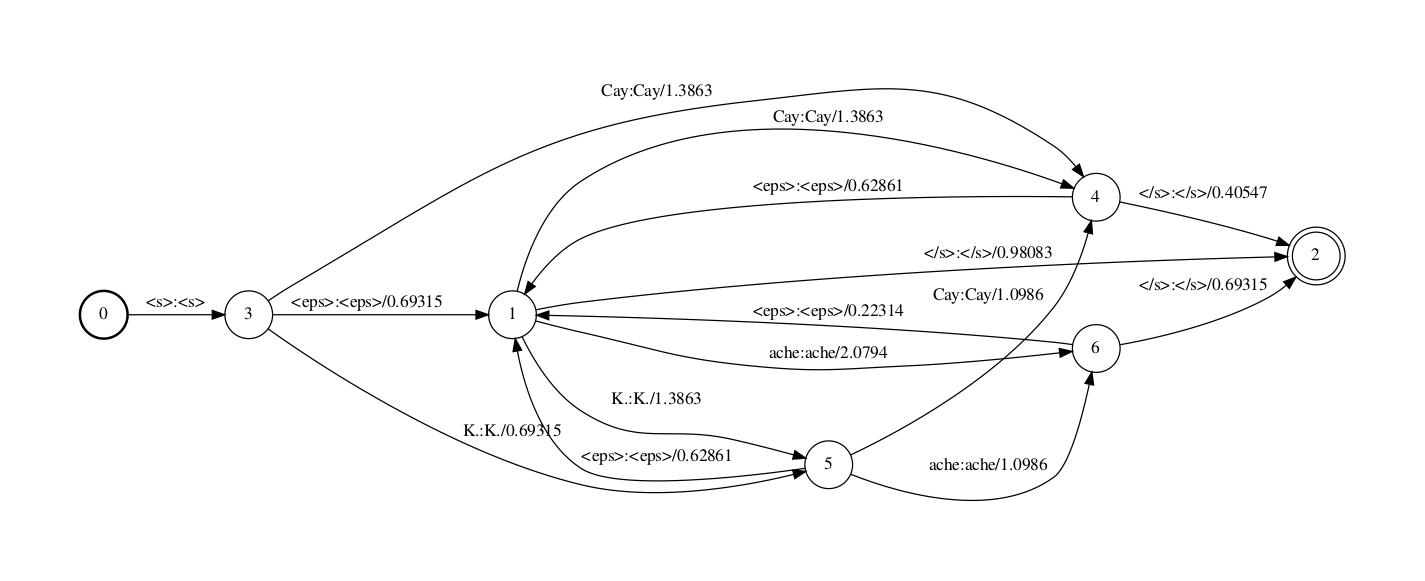
step 2
在step 2中,eps2disambig.pl脚本将输入中的epsilon(backoff边上)转为特殊字符#0,从而使得fst是determinizable的。注意此处words.txt里需要包含这个’#0’符号。(译注:)
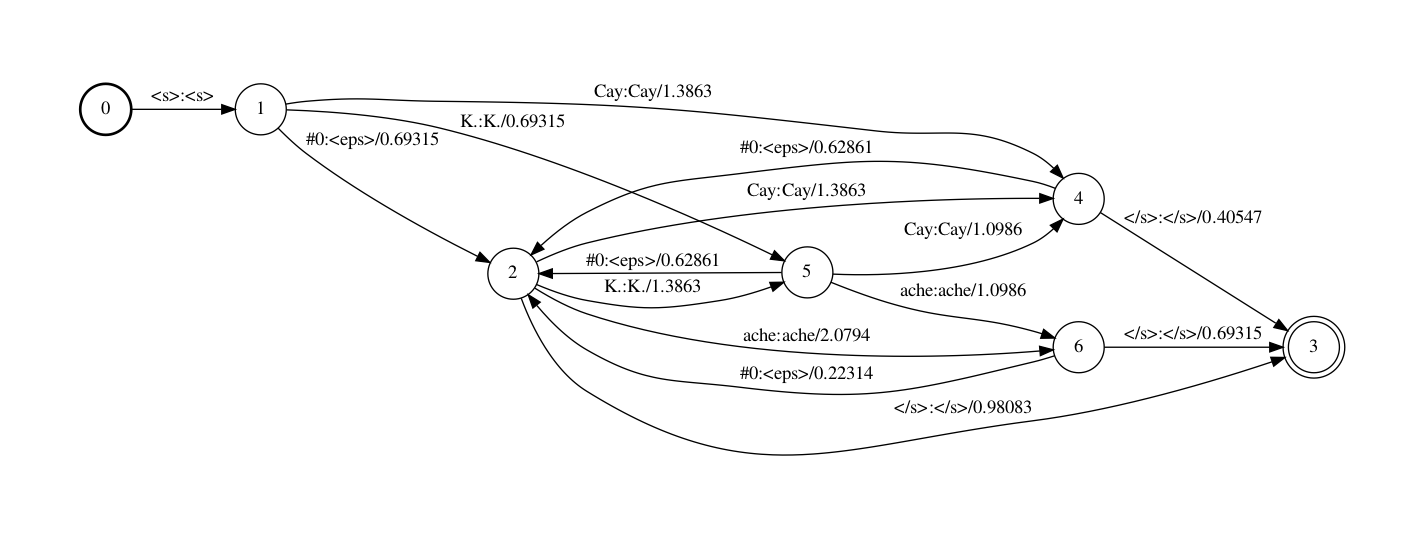
step 3
Step 3中将<s>和</s>符号替换成epsilons。(译注:在fst中开始和结束这个信息不需要用符号显示表达,fst本身就蕴含了这个信息,即从开始节点出发和到达final节点)
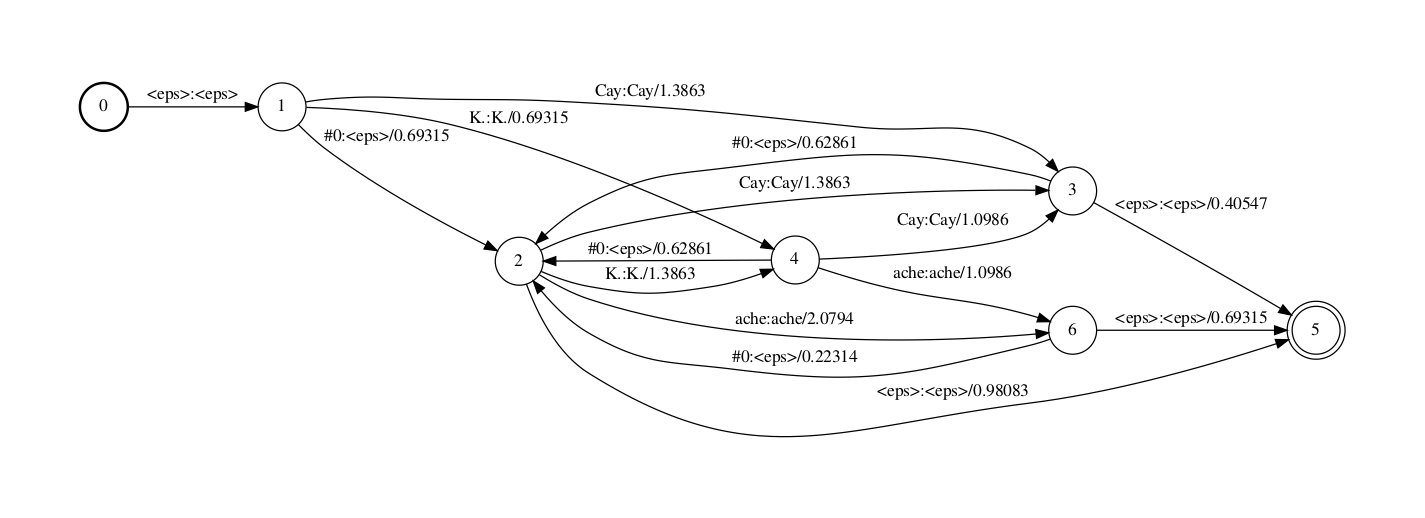
step 4
Step 4 移除epsilon以简化FST,得到最终的G fst。
符号表(word symbol table)
fst的符号表如下
<eps> 0
</s> 1
<s> 2
Cay 3
K. 4
ache 5
#0 6
类似的对于unigram,其G-fst如下,我们就不再单独分析。
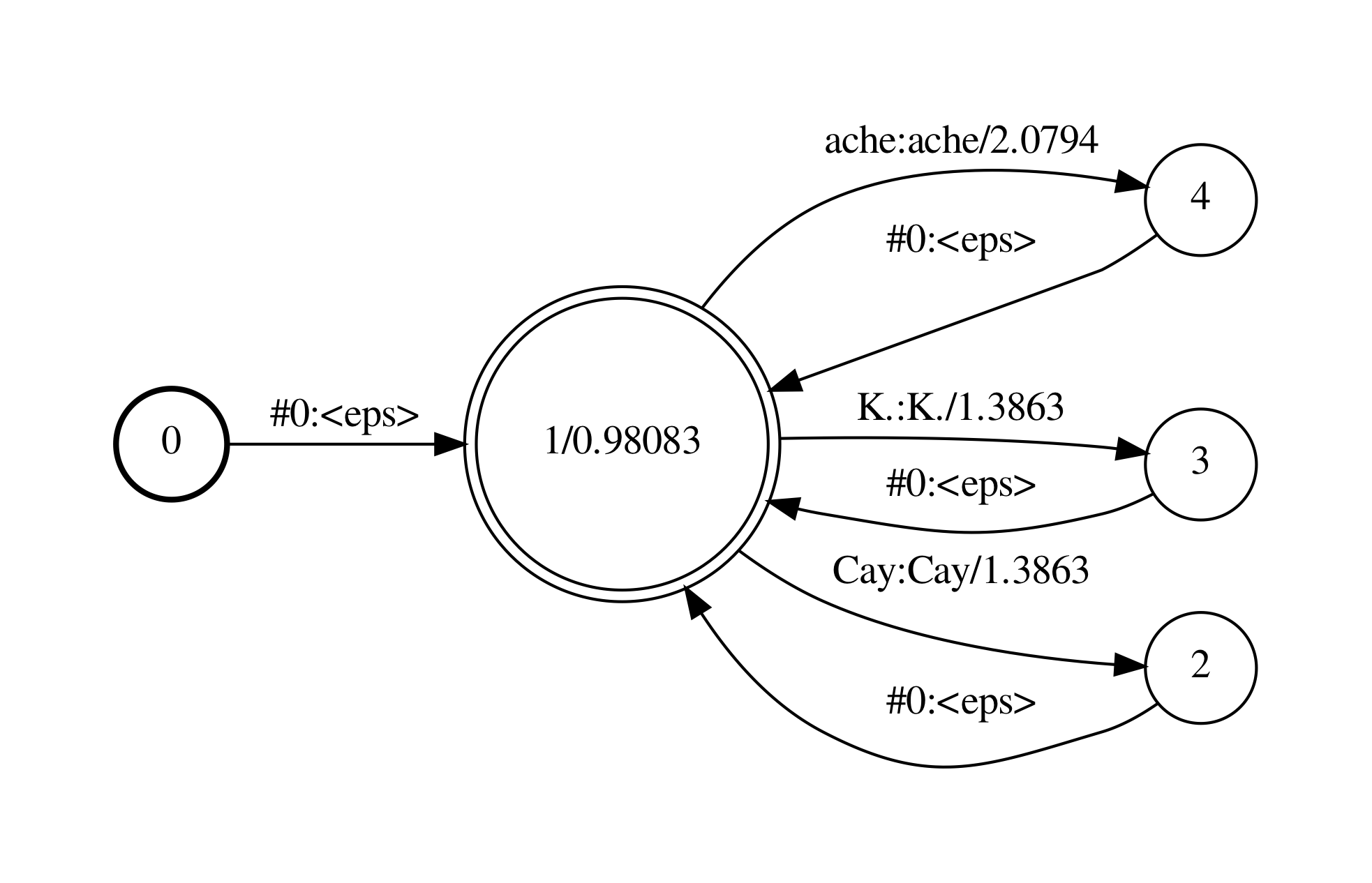
由于HCLG的构建过程不受G的阶数影响,为了使构建出HCLG的各步fst更简单易读,本文接下都使用unigram的G来展示HCLG的构建过程。如果你想了解bigram的G构建出HCLG的过程,可以参考附件中的.pdf文件。
词典(Lexicon)FST的构建 (L)
Kaldi中,lexicon-fst 的准备过程是相对标准的. 首先使用脚本add_lex_disambig.pl为每个同音字(这个例子里是”Cay” 和 “K.”)的发音后面添加一个单独的辅助符号进行区分,将词典变成:
ache ey k
Cay k ey #1
K. k ey #2
make_lexicon_fst.pl用于创建L fst. 这个脚本有四个参数
- 词典文件,其中包含了disambiguation符号(本例中为#1,#2)
- 可选:silence音素的概率
- 可选:silence音素的符号
- 可选:silence的disambiguation符号(本例中为#3)
make_lexicon_fst.pl lexicon_disambig.txt 0.5 sil '#'$ndisambig | \
fstcompile --isymbols=lexgraphs/phones_disambig.txt \
--osymbols=lmgraphs/words.txt \
--keep_isymbols=false --keep_osymbols=false |\
fstaddselfloops $phone_disambig_symbol $word_disambig_symbol | \
fstarcsort --sort_type=olabel \
> lexgraphs/L_disambig.fst
make_lexicon_fst.pl 脚本会在每个词的发音开头和结束加入可选的silence音素(允许一个词的开头和结尾有silence),并且加入silence的disambiguation符号,一般为已使用的最大disambiguation符号加1,本例中为#2+1=#3,只有在lexicon本身包含同音词需要disambiguate时才需要为silence引入一个disambiguation符号。具体解释见(!!!代补充!!!)
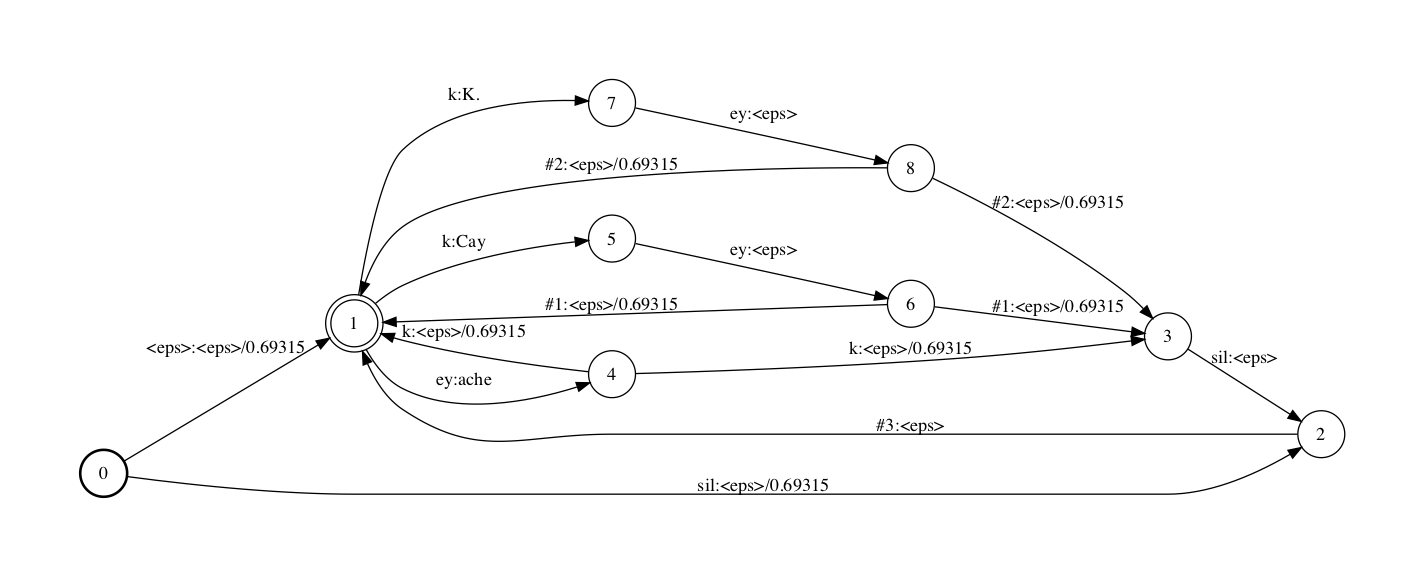
另外,还记得前文提到的G中用于backoff的#0辅助符号吗,我们的词典里并没有#0这个词,因此compose时G中输入为#0(compose时对应L中输出时是#0)的路径都被丢弃了,这里的处理方法为加入一个#0:#0的self-loop边.
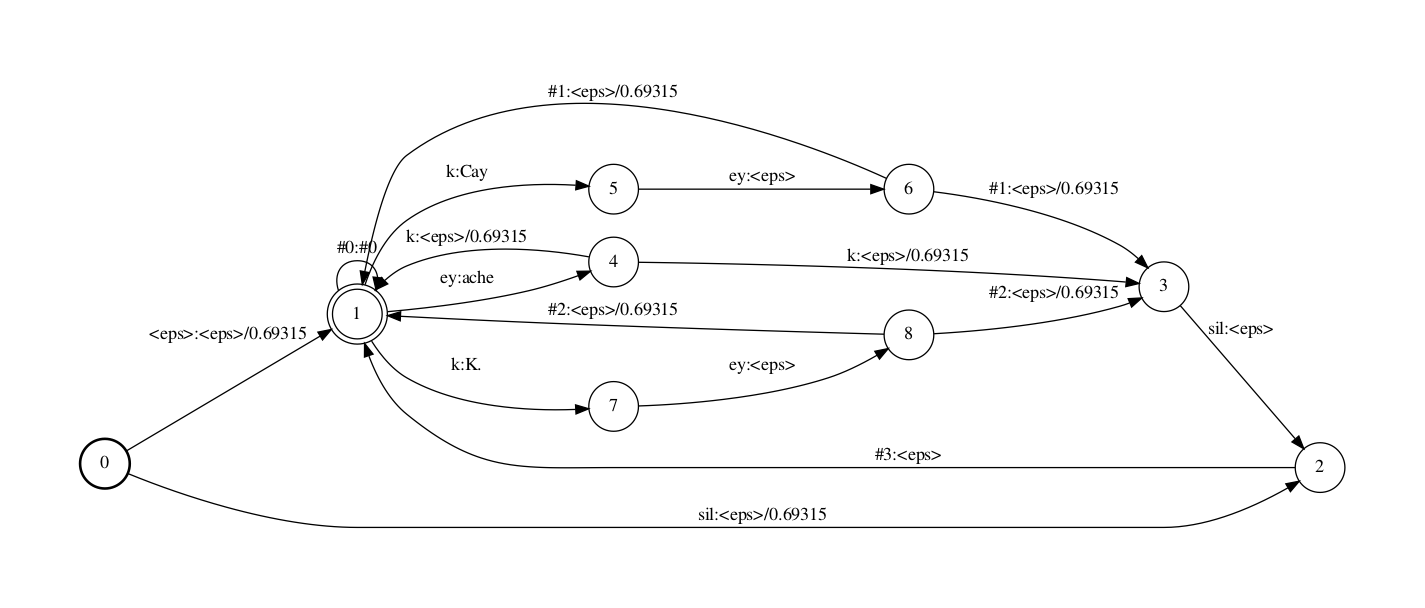
带有disambiguation符号的的phone符号表如下
<eps> 0
ey 15
k 22
sil 42
#0 43
#1 44
#2 45
#3 46
一般phones.txt这个文件里symbol id从0开始连续的,注意这里不是0,1,2,3而是0,15,22,42,这是因为作者是直接从一个真实声学模型的音素集里抽取的这两个音素,为了复用该声学模型音素集对应的H,仍保持了符号id. 另外可以看出,<eps>的id都是0,而#n是再音素后面的继续增加id.
LG composition
L和G的 composition操作如下
fsttablecompose L_disambig.fst G.fst |\
fstdeterminizestar --use-log=true | \
fstminimizeencoded > LG.fst
这个命令里的fsttablecompose/fstdeterminizestar/fstminimizeencoded均为kaldi实现的fst操作,而不是openfst的命令,这个实现和openfst的标准compose/determinize/minimize有些微小的区别. 具体区别参考 kaldi-fst
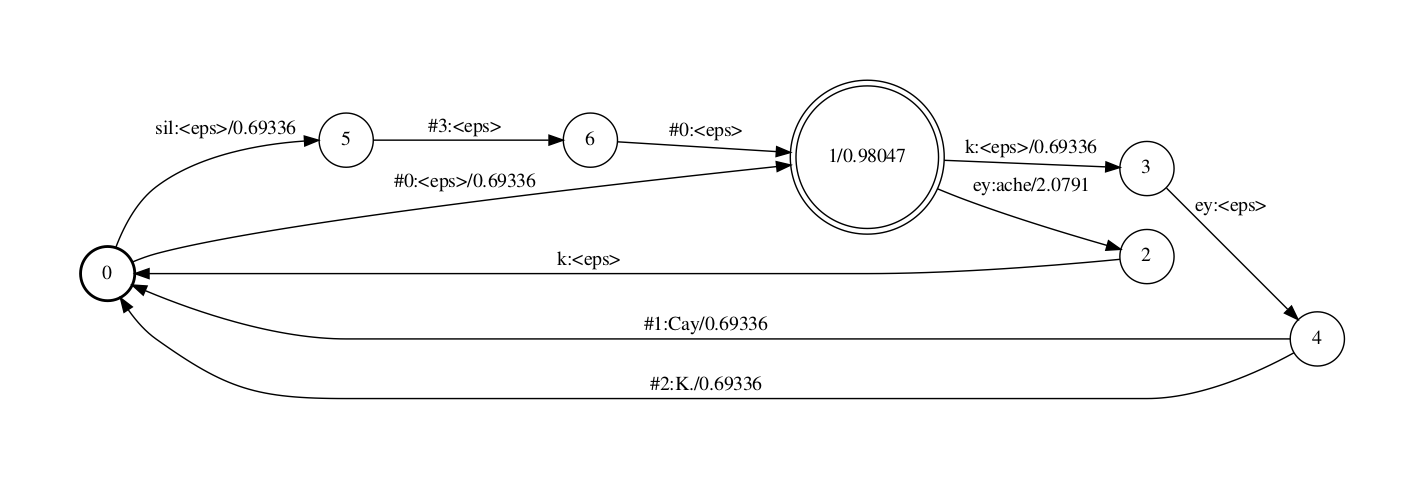
上下文相关音素(context-dependent phones, cd-phones)FST (C)
关于C-fst以及CLG的处理涉及了#-1,$以及logical/physical的概念,是kaldi里理解起来相对麻烦的部分,本文仅简要介绍帮助初步理解,更深入理解需要看kaldi的文档/代码以及其他介绍
在Kaldi中一般不会显式创建出单独的C-fst再和LG compose,而是使用fstcomposecontext工具根据LG动态的生成CLG(注:因为穷举所有的cd-phones非常浪费,根据LG中的需要,动态的创建用到的cd-phones会节省很多开销)。这里,出于演示的目的,显式的创建一个C-fst。
fstmakecontextfst \
--read-disambig-syms=disambig_phones.list \\
--write-disambig-syms=disambig_ilabels.list \
$phones $subseq_sym ilabels |\
fstarcsort --sort_type=olabel > C.fst
创建的C-fst(C, 将cd-phone转换为mono-phone的FST)如下
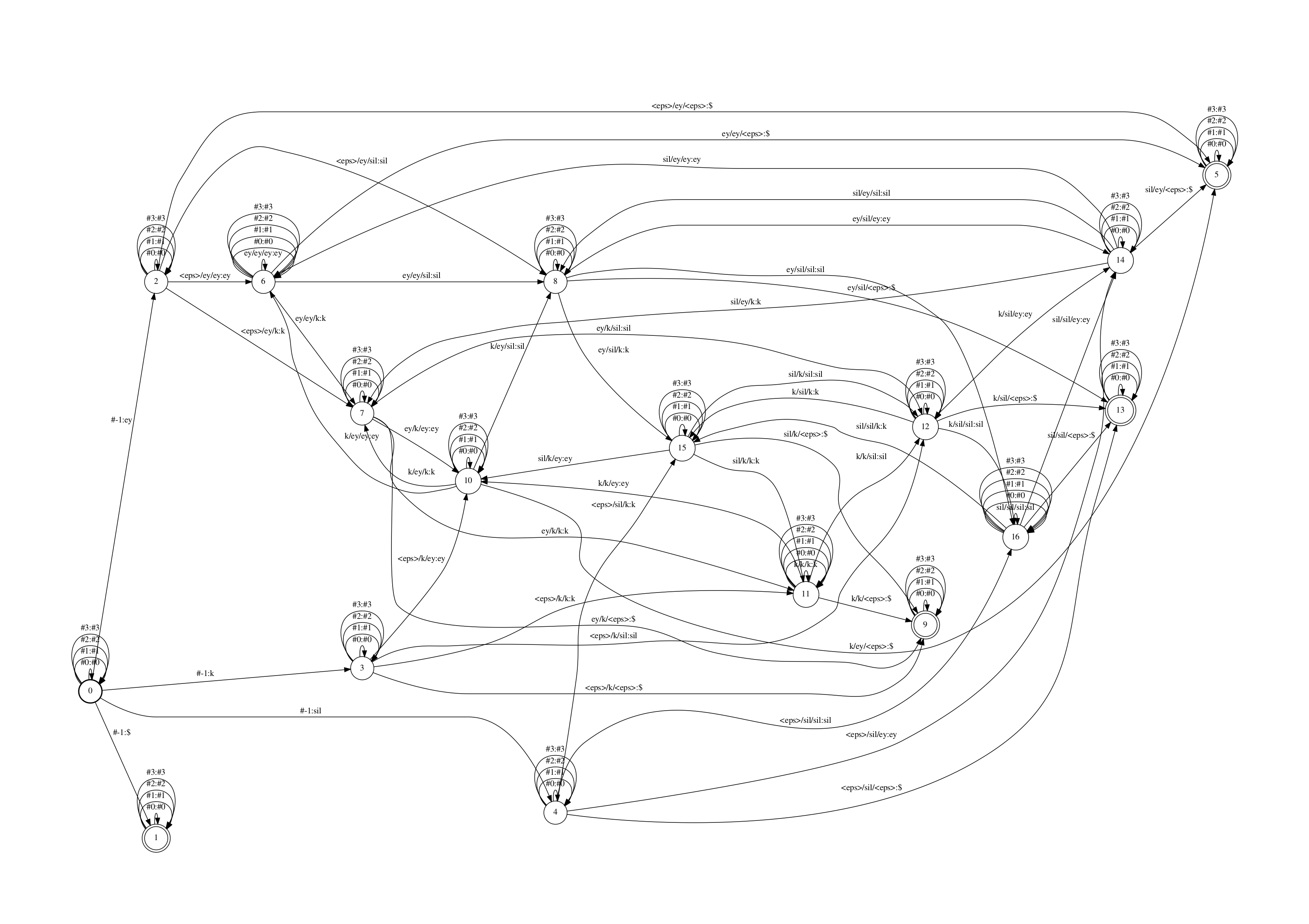
该FST中,每个state都有一些自跳转,用于处理L中引入的#n辅助符号.
C-fst的输入符号是triphone的id(图里显示是把id对应的可读表示left-ctx/phone/right-ctx), 实际上,kaldi用了一个叫ilabel_info的数据结构来存储C fst的输入符号表的信息。ilabel_info是一个数组的数组,数组里的每个元素记录一个C fst的输入符号信息。
举个例子,若triphone “a/b/c”在C中的symbol id是10(id从0开始),则ilabel_info中的第11个元素存储了”a/b/c”的完整上下文信息,若a,b,c在L中的id分别为10,11,12,则该元素存储的信息为[10 11 20].
ilabel_info中还会存储#n符号,但是会将其在L中的id取负,如在L中#1的id是44,则在C中的input也会有一个对应的#1符号,其存储为[-44],之所以用负号,是为了方便直接判断当前是不是辅助符号。
kaldi中用N和P表示上下文相关音素的前后窗口信息。N表示上下文相关音素的窗口宽度,P表示当前音素所在位置(第一个位置是0),比如一般说的triphone就是(N=3,P=1),如果上下文相关音素是和左侧2个音素/右侧1个音素相关,则为(N=4,P=2)
以(N=3,P=1)为例每个边的格式为a/b/c:c,即该边上的输入是a/b/c,其中当前音素是b,左侧上下文是a,右侧上下文是c。这里要注意的是,该边输出并不是当前音素b,而是下一个音素c.这就带来两个问题:
-
假设某个词发音是a b c,对于词的第一个音素,a对应的三音素为
<eps>/a/b,对应的边为<eps>/a/b:b,这时输出是b,但是C应该在输出b前先输出a,那输出的a的边应该是什么样的,可以是<eps>/<eps>/a:a. 然而在kaldi中统一用#-1表示输入是空的,因此该边为#-1:a而不是<eps>/<eps>/a:a. 所以ilabel_info中还存储了这个#-1符号,用于表示从初始状态开始先接受空输入产生音素。在start状态后会有(N-P-1)个#-1输入,才进入到第一个’正常’的cd-phone输入的边。 -
当前上下文音素是
a/b/c时会输出c,但是如果到了句子末尾,接下来的当前音素是b/c/<eps>时,fst的输出什么呢?可以输出<eps>, 但kaldi为C fst引入了一个专用符号subseq_sym来代替这种情况下的<eps>输出 (前面提到,kaldi实际是用fstcomposecontext来compose C和LG,而不会创建出C,其内部用符号$的作为subseq_sym,由此也可知音素集里不能出现$),从而使C是output deterministic的,在和LG compose时会更加高效。在final状态前会有(N-P-1)个$输出。
既然在C中加入了$这个输出,LG中也需要加入输入为$的边。使用Kaldi中的工具fstaddsubsequentialloop对LG进行修改。
fstaddsubsequentialloop ${subseq_sym} cascade/LG_uni.fst > cdgraphs/LG_uni_subseq.fst
可以看到,LG中的final状态用"$:ϵ"边连接到一个带self-loop边的新的final状态上。self-loop是为了处理C中连续(N-P-1)个”$”输出。
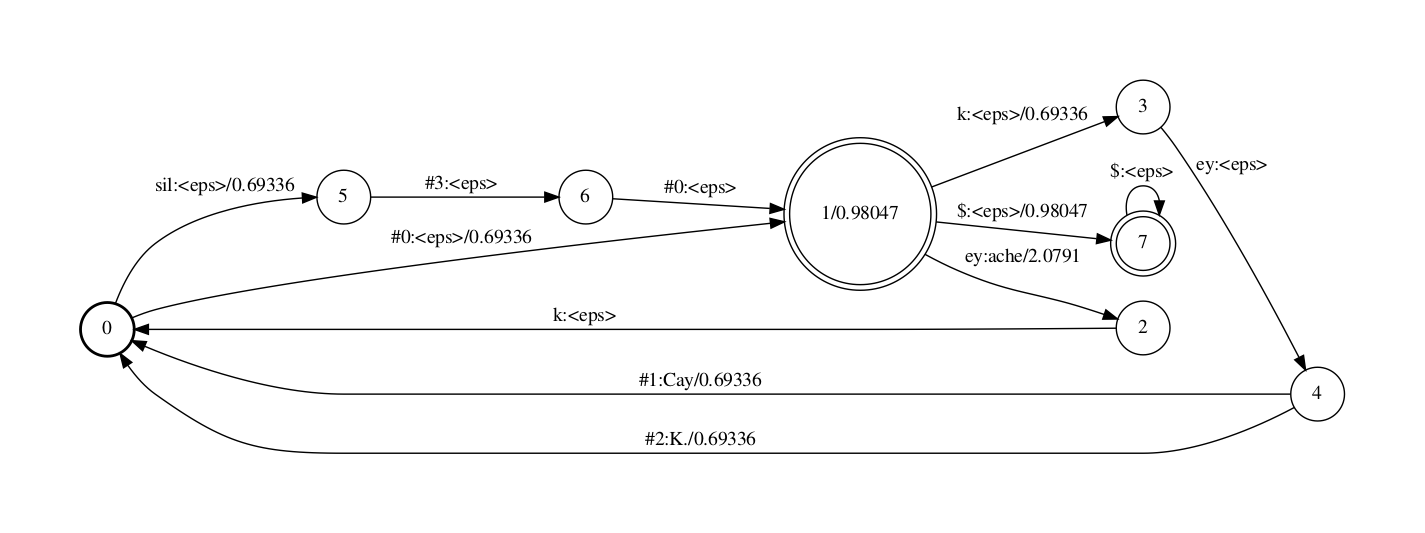
CLG cascade
C/LG compose的脚本如下,过程和L/G compose 一样
fsttablecompose cdgraphs/C.fst cdgraphs/LG_uni_subseq.fst |\
fstdeterminizestar --use-log=true |\
fstminimizeencoded \
> cascade/CLG_uni.fst
得到的CLG fst如下
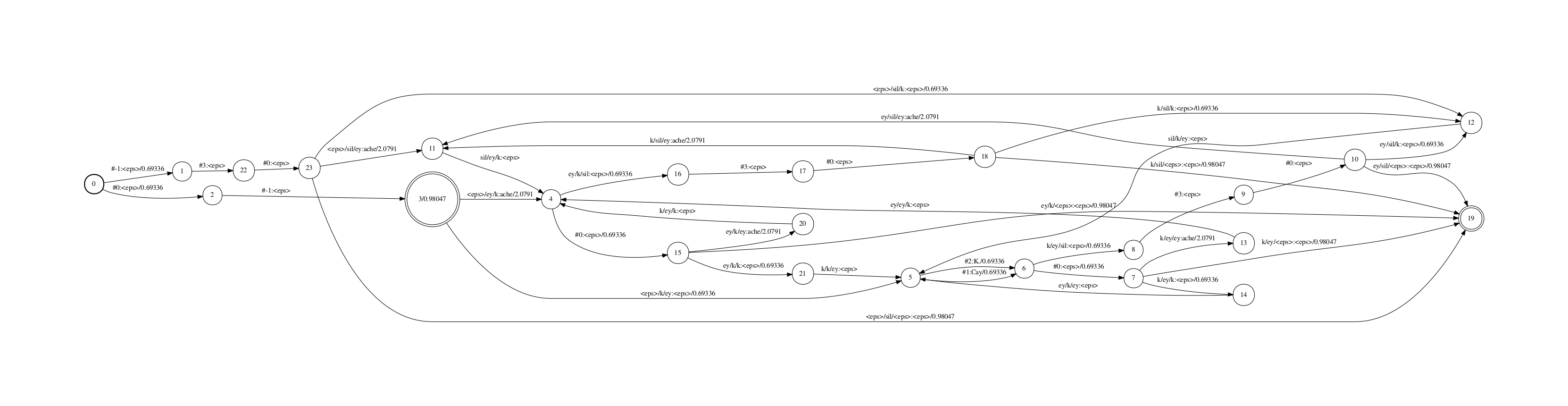
对于这个CLG fst,我们使用一个fst进一步减小cd-phone的个数。
注意,kaldi为了减小cd-phone的个数,一般使用决策树绑定,kaldi的决策树绑定支持将HMM中arc或者state的绑定(待确认),我们只讨论arc的绑定,绑定后的arc称为senone. 假如对于某几个cd-phone, 其topo内各arc绑定senone的情况都一样,则这些cd-phone(绑定前,称为logical cd-phone)对应到同一个physical cd-phone,kaldi会在同一组logical cd-phone中随机选一个作为其phsical cd-phone的id。
目前CLG中的输入可以认为是logical cd-phone,即所有可能组合的音素。可以根据的决策树绑定,构建一个fst,将physical cd-phone映射为logical cd-phone.
make-ilabel-transducer --write-disambig-syms=cdgraphs/disambig_ilabels_remapped.list\
cdgraphs/ilabels $tree $model cdgraphs/ilabels.remapped \
> cdgraphs/ilabel_map.fst
ilabel_map.fst是physical到logical的映射,如下图

kaldi中,把sil当作是上下文无关的音素,因此所有的x/sil/y都绑定到同一个physical cd-phone上,可以在该映射fst里看到相关的边。
另外,我们的例子中,有一条边是<eps>/ey/k:ey/ey/k,表示对于音素’ey’,若其左边是’ey’,右边是'k',等价于左边是'<eps>'右边是'k'.你可以用kaldi的draw-tree工具把tree中的信息输出,"<eps>/ey/k"和"ey/ey/k"的HMM中的PDF是一样的。
将该fst和CLG fst compose,即可得到减小后的输入为physical cd-phone的CLG了。通过增加这个physical到logical的映射,unigram CLG的状态个数从24降到17,边个数从38降到26
对比之前的logical CLG和这里的physical CLG fst,会发现前者中存在输入是"<eps>/ey/k"以及输入是"ey/ey/k"的边,而后者只有输入是"<eps>/ey/k"的边。
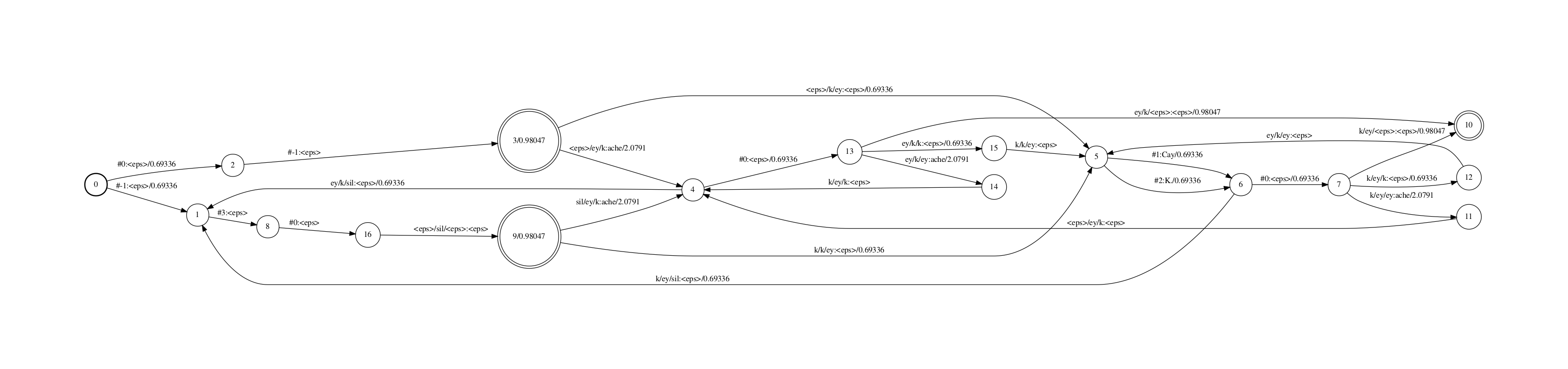
H fst的功能是把transition-id序列映射到cd-phone序列. kaidi中,有一个唯一标识transition-id来表示”cd-phone的当前phone、cd-phone的一个state、该state上的一条边、该边对应的pdf-id”.最终解码fst的输入不是pdf-id而是transition-id.
H fst和L fst看起来很类似.因为Ha.fst比较大,这里只保留了"<eps>/ey/k"和"<eps>/sil/<eps>"两个physical cd-phone。从图中可以看到,kaldi里的sil("<eps>/sil/<eps>")是用的五状态HMM,且该topo的跳转也比较特殊。
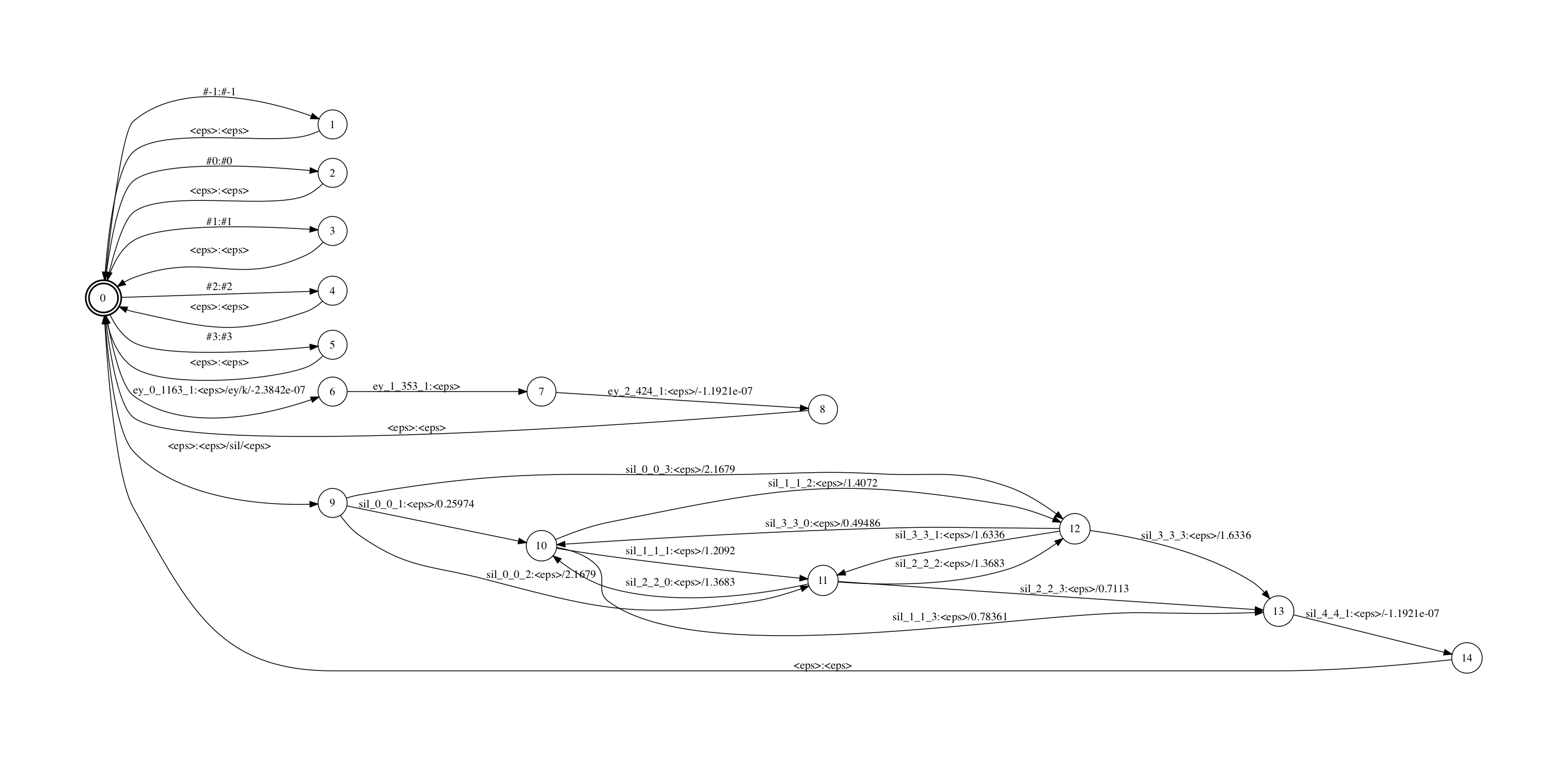
这个fst从一个start节点(同时也是final节点,这个fst是个closure)开始,进入到各个cd-phone的HMM。每个physical cd-phone输出对应一个HMM state的序列的输入(kaldi中其实是transition id序列)。注意并没有路径会输出"ey/ey/k",因为"ey/ey/k"是一个logical cd-phone,其physical cd-phone是"<eps>/ey/k". 另外,start节点上还有一些自跳转用于处理C fst里引入的辅助符号,如"#-1:#-1".
这个FST的输入标签是我用一个自己写的工具fstmaketidsyms打印出来的,这个标签展示了transition-id包含的上文提到的四个信息(用下划线分割),包括cd-phone中的phone,cd-phone中的HMM state,pdf-id以及该state上的对应的跳出边的在该state上的index. 例如”k_1_739_1”表示该transition-id对应了音素k拓扑中的第1个state上的第1个跳出边,其绑定到的pdf-id是739.(音素k的不同的cd-phone,同样位置的边可能会绑定到不同的pdf上)
注意这个fst里没有包含HMM的自跳转,所以这个fst叫做Ha fst而不是H fst.我们在Ha和CLG compose完成后再加入HMM的自跳转.
HCLG fst
下面命令用于创建完整的HCLG(仍然不包含HMM中的状态上的自跳转边)
fsttablecompose Ha.fst CLG_reduced.fst | \
fstdeterminizestar --use-log=true | \
fstrmsymbols disambig_tstate.list | \
fstrmepslocal | fstminimizeencoded \
> HCLGa.fst
Ha fst和CLG fst(加入了physical到logical的mapping)进行compose, determinize操作, 然后将辅助符号(#n,compose和determinze之后这些辅助符号就没用了)用epsilons替代,然后再做minimize.
下图是输出结果,其中输入符号和上面Ha的产生方式一样,也是用fstmaketidsyms工具产生。

然后我们加上HMM里的自跳转边。
add-self-loops --self-loop-scale=0.1 \
--reorder=true $model < HCLGa.fst > HCLG.fst
add-self-loops在加入self-loop时,会根据self-loop-scale参数调整概率(细节见kaldi文档)并且会对transition重排序(reorder),这个重排序操作使得对于每一帧特征,不需要计算两次同样的声学模型得分(对于通常的Bakis从左到右的HMM拓扑),从而可以使得解码过程更快。最终HCLG的解码图如下,

基本上就这些了,感谢阅读。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK