

记一次面向线程栈的防爆栈机制的实现探索
source link: https://xiaowing.github.io/post/20180313_thread_stack_overflow_protection/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

记一次面向线程栈的防爆栈机制的实现探索
爆栈(stack overflow), 众所周知是一种软件的致命错误, 一旦发生程序就core了。根据维基百科的描述,当代码中有以下三种情形时会引发爆栈
- 函数调用链展开过深
- 函数内申请过大的局部变量
其中1.和2.本质上是相同的,不管是否递归,只要函数调用链过深,压栈过多就会引发爆栈。只不过在实践中,由递归更容易引发爆栈。
可是在很多时候,我们无法避免递归。比如数据库在对SQL语句的执行实现中,伴随着输入的SQL语句的复杂性,间接递归通常是可以预见的。但是无论哪种情况,我们都不能容忍一个用户输入导致程序爆栈,因此这种情况下,我们就需要一个防爆栈机制
下文通过介绍我经手的一个防爆栈机制的实现过程,分享一下有关程序设计的教训与心得:
我们的系统是一个高并发的系统,实现的是基于线程的并发(session-per-thread模式),由于用户输入可能会引发我们系统内部的合理的间接递归。由于用户输入的复杂性不可避免,如果极端情况下用户输入引发了一个会话爆栈,将会使整个进程core掉。因此我们需要一个基于线程栈的防爆栈机制。
此外,为了尽可能地容忍更大地并发量,系统为每个用户会话创建后台线程时限定了线程栈的大小为256KB(通过pthread_attr_setstacksize()设置)
借鉴——PostgreSQL的防爆栈实现
首先我们想到了PG的实现,PG代码中也实现了一个防爆栈机制。其原理简要说明如下:
PG在为新的用户会话创建后台进程(PG是session-per-process模式)后,在入口函数
PostmasterMain()中获取进程栈中的基地址,并将其记录在postgres进程的一个全局变量(会话内可见)上保存栈基址的代码如下:
pg_stack_base_t set_stack_base(void) { char stack_base; pg_stack_base_t old; #if defined(__ia64__) || defined(__ia64) old.stack_base_ptr = stack_base_ptr; old.register_stack_base_ptr = register_stack_base_ptr; #else old = stack_base_ptr; #endif /* Set up reference point for stack depth checking */ stack_base_ptr = &stack_base; /* ★stack_base_ptr即为保存栈基址的全局变量 */ #if defined(__ia64__) || defined(__ia64) register_stack_base_ptr = ia64_get_bsp(); #endif return old; }在SQL语句的处理逻辑在所有涉嫌递归调用的入口执行栈深的检查函数,通过比较检查时点所用的局部变量的地址与先前记录的栈基址做比较,如果差值超过阈值,则退出当前SQL的执行并提示错误信息
PG中栈深的阈值(
max_stack_depth_bytes)默认为2MB, 其大小可由用户配置,但最大值不能超过操作系统的栈大小(可通过ulimit -a查询) 减去 512KB其比较栈深的代码实现如下:
/* src/backend/tcop/postgres.c */ bool stack_is_too_deep(void) { char stack_top_loc; long stack_depth; stack_depth = (long) (stack_base_ptr - &stack_top_loc); /* ★stack_base_ptr即为保存栈基址的全局变量 */ if (stack_depth < 0) stack_depth = -stack_depth; if (stack_depth > max_stack_depth_bytes && stack_base_ptr != NULL) return true; #if defined(__ia64__) || defined(__ia64) stack_depth = (long) (ia64_get_bsp() - register_stack_base_ptr); if (stack_depth > max_stack_depth_bytes && register_stack_base_ptr != NULL) return true; #endif /* IA64 */ return false; }
PG的代码质量是值得信赖的,所以我们借鉴了上述机制。由于两个系统的会话模型不同,因此我们做了一些改造: 由于我们系统的用户会话和线程是一一对应的关系,所以把栈基址的保存位置从全局变量放到了会话上下文中。比如上述检查栈深的代码就变成了类似以下的代码:
bool
stack_is_too_deep(session_t *session)
{
char stack_top_loc;
long stack_depth;
stack_depth = (long) (session->stack_base_ptr - &stack_top_loc); /* 之前获取的栈基地址放在了会话上下文 */
if (stack_depth < 0)
stack_depth = -stack_depth;
/* MAX_STACK_SIZE为256KB */
if (stack_depth > MAX_STACK_SIZE && stack_base_ptr != NULL)
return true;
return false;
}
本以为这样一来就大功告成了,后来的事实证明: 我们把问题考虑得太简单了…
第一次爆栈
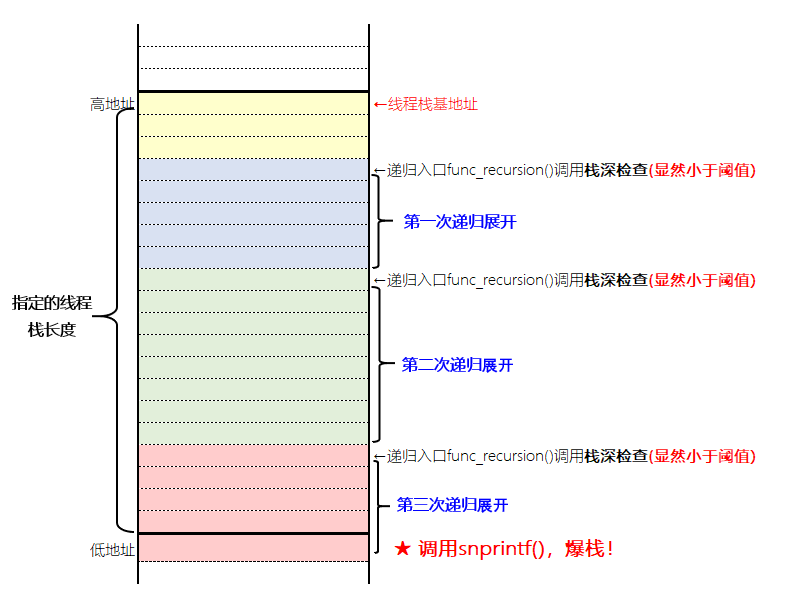
在事先了上述防爆栈机制后,为了测试效果,我们构造了一个会引发无限递归的用户输入, 希望将之加入回归测试集作为该防爆栈功能的看护用例。可是,当我们运行该用例时,结果却让我们傻眼了——程序直接core掉了!!
连忙分析生成的core文件:发现事发现场的线程栈有 3000+ 个栈帧(stack frame), 最后程序core掉时所处的栈帧居然是标准库函数 snprintf()……换言之,防爆栈机制没有生效
首先分析了一下PG原有的防爆栈实现,突然被其GUC参数max_stack_depth_bytes的配置逻辑所吸引:
栈深的阈值(
max_stack_depth_bytes)默认为2MB, 其大小可由用户配置,但最大值不能超过操作系统的栈大小(可通过ulimit -a查询) 减去 512KB
PG的允许用户设置的阈值为什么不是直接等于操作系统的栈大小?
这是因为如果将阈值等于OS的栈大小,将会产生下述后果:
只要程序走到栈深检查函数时,则说明栈深肯定没有超过阈值; 另一方面, 当栈深超过阈值时, 已经没有时间让程序在走到栈深检查函数去自我预警了.
换言之: 关于栈深检查的阈值,应当设置为一个在两次检查之间事实上允许程序栈深适当超过的值。也就是说,在栈深的阈值和操作系统所允许的最大栈深之间应该放一个余量,这个余量要能够让程序在两次栈深检查之间继续展开栈帧并坚持到下一个栈深检查为止。——考虑到当代Linux系统下默认的栈大小为8MB,所以结合PG的max_stack_depth_bytes的规格来看,PG所放的余量最大为6MB,最小也有512KB.
但是在我们的实现中,我们将栈深检查的阈值直接定为线程栈的大小。这就意味着,我们为两次栈深检查之间没有放任何余量。这便使得栈深检查机制变得毫无意义。
下图示意了这一次爆栈的原因:
第一次修正
既然明白了原因,修正方法就很简单: 给阈值放点余量。经过反复试验,最终决定将这个余量设置为16KB。因此栈深检查的代码就修改为下述形式:
bool
stack_is_too_deep(session_t *session)
{
char stack_top_loc;
long stack_depth;
stack_depth = (long) (session->stack_base_ptr - &stack_top_loc); /* 之前获取的栈基地址放在了会话上下文 */
if (stack_depth < 0)
stack_depth = -stack_depth;
/* MAX_STACK_SIZE为256KB */
/* 检查的阈值为 (线程栈长度 - 16KB) */
if (stack_depth > (MAX_STACK_SIZE - (16 * 1024)) &&
stack_base_ptr != NULL)
return true;
return false;
}
当然, 上述修改还是存在一些风险的: 毕竟余量16KB还是比较小的。如果两次栈深检查之间的函数展开中有某个函数使用了16KB的局部变量,照样会让程序爆栈core掉。为此,我又对代码进行了审视,确保了栈深检查之间的函数调用没有使用太多局部变量。之后,便将上述修正给commit了.
第二次爆栈
之后相当长的一段时间内,这个爆栈防护运行得都比较好。且放入回归测试集中的看护测试也总是能如期报出”stack too deep“的错误消息。一切看上去相安无事.
然而,距离上一次对stack_is_too_deep()的修正已有两个月的某一天下午,回归测试被运行起来后,上述的看护测试没有再能如期报出”stack too deep“的错误消息, 而是直接导致了程序core了。再一分析core文件的栈信息,发现有1000+个栈帧——显然,又爆栈了…
得知这一信息后,我的内心是纠结的:理论上可以考虑把之前修正中引入的余量再放大,把检查的阈值再降低; 但是这样一来,将有可能会导致stack_is_too_deep()错误消息报出的频率增大,进而导致我们规格中定义的用户线程栈的默认大小256KB失去意义. 如果再贸然增大线程栈的默认大小,那么就有可能会导致并发度的下降,进而产生一连串连锁反应。更何况,就算要放大余量,放到多少为合适呢?……
思来想去,决定还是先回溯一下代码的commit履历,看看是不是有人在函数调用中使用了过大的局部变量,如果是的话,到底用了多大.
通过回溯代码的commit, 问题引入的commit很快就被定位到了。但是这个commit的修改内容却和我预想的不太一样:
引入问题的commit简而言之其实只干了一件事情——它把一个线程的静态TLS变量的大小进行了调整。引发问题的代码概要如下:
typedef struct foo {
char buf_a[BUFFER_SIZE];
char buf_b[BUFFER_SIZE];
} Foo;
__thread Foo thbuf;
引入问题的commit的修改就是把上述宏BUFFER_SIZE的定义从 512 变成了 4096
但是线程的TLS变量大小的改变和线程栈之间又有什么关系呢?
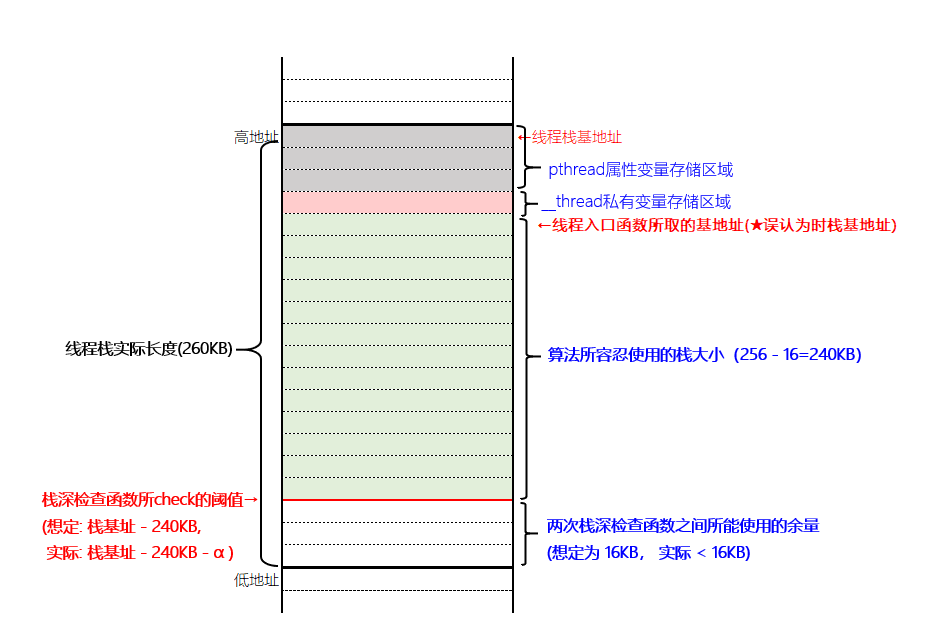
分析了一下core文件, 突然发现TLS变量的地址只比代码中线程入口函数取到的所谓”线程栈基地址” 要高一点,但是又没有高出太多——难道这只是一个巧合??
进一步在网上查找了一下,找到了一篇文章,里面贴出了一张pthread线程栈的结构图让我恍然大悟:
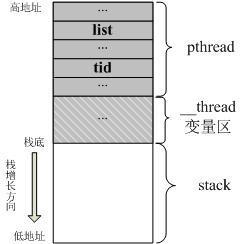
上图出自 https://www.jianshu.com/p/e01c1a2a46e7
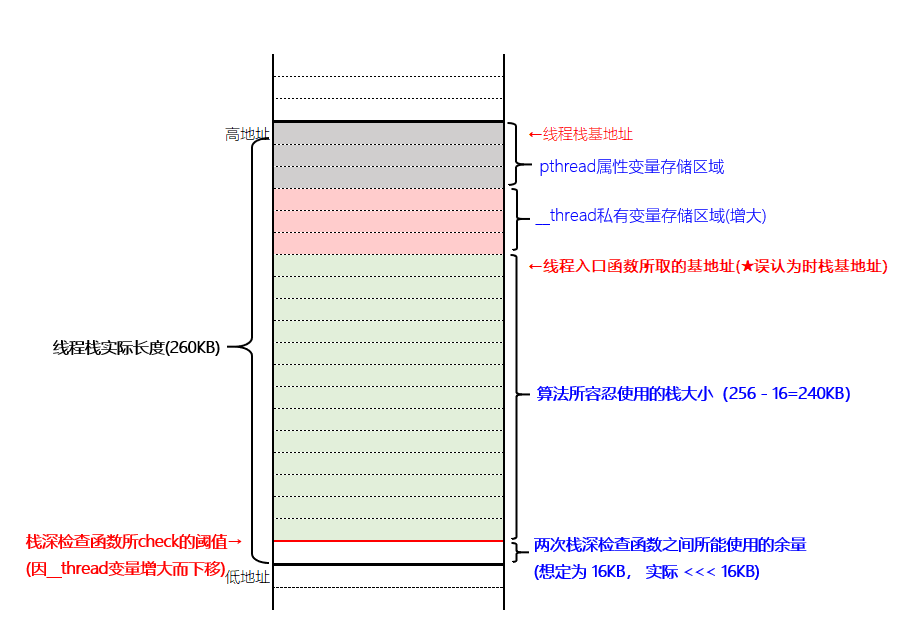
事实上,我在线程入口函数处取到的所谓”栈基址”并不是真正的线程栈的栈基址,它只是线程栈中用户程序可用部分的栈底而已。由于TLS变量也是存储在线程栈中的,但是我在算已使用的栈大小时却没有算入TLS变量所占大小。因此,虽然我的防爆栈机制的意图时想让两次栈深检查之间能有16KB的余量可用,但实际上由于计算时的栈基地址选取不当,真正放出的余量并没有16KB,而是要小于16KB。而且随着TLS变量的增大,线程栈阈值之上的余量空间被大大压缩,从而导致在两次栈深检查之间又发生了爆栈。
TLS变量的增大引发的连锁反应如下所示:
- TLS变量大小修改前
- TLS变量大小修改后
第二次修正
由于是栈深检查时选取的线程栈基地址有误,因此修改了后台线程入口函数中取基地址的逻辑:
原本是直接在入口函数一上来便声明一个局部变量并取其地址; 现在修改为使用pthread线程库中的pthread_attr_getstackaddr()来获取。
获取当前线程的线程栈基地址以及栈大小的方法可参见下述代码示例:
void *thread_handler(void *args) {
char start;
pthread_t self_tid;
pthread_attr_t curr_attr;
void *addr = NULL;
size_t size;
self_tid = pthread_self();
if (pthread_getattr_np(self_tid, &curr_attr) != 0)
perror("pthread_getattr_np() failed");
if (pthread_attr_getstackaddr(&curr_attr, &addr) != 0)
perror("pthread_attr_getstackaddr() failed");
if (pthread_attr_getstacksize(&curr_attr, &size) != 0)
perror("pthread_attr_getstacksize() failed");
printf("[Thread %d]: retrieved address of thread stack %p, stack size %d bytes\n", (int)self_tid, addr, (int)size);
pthread_attr_destroy(&curr_attr);
return 0;
}
经过了一波三折,总算是把爆栈防护机制给稳定了。回溯一下整个过程,可以得到以下教训:
- 对于程序中所设计的阈值告警,应当把阈值设计得要比”不可触及”的红线略小,否则阈值告警本身等于无效。
- 形而上学地照搬代码并不能真正地解决问题,应当还是要祥日本人提倡的那样”原理原則に従って設計する”
最后,我个人认为这个防爆栈实现代码的改善过程还是很有裨益的,因此多写了一点,以飨后者。
Related Issues not found
Please contact @xiaowing to initialize the comment
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK