

深入了解 TiDB SQL 优化器 - DataFunTalk
source link: https://www.cnblogs.com/datafuntalk/p/16190515.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

分享嘉宾:张建 PingCAP TiDB优化器与执行引擎技术负责人
编辑整理:Druid中国用户组第6次大数据MeetUp
出品平台:DataFunTalk
导读: 本次报告张老师主要从原理上带大家深入了解 TiDB SQL 优化器中的关键模块,比如应用一堆逻辑优化规则的逻辑优化部分,基于代价的物理优化部分,还有和代价估算密切相关的统计信息等。
本文将从以下几个方面介绍:首先讲一下TiDB的整体架构,接下来就是优化器的两个比较重要的模块,一个是SQL优化,做执行计划生成;另一个模块就是统计信息模块,其作用是辅助执行计划生成,为每一个执行计划计算cost提供帮助。最后介绍下优化器还有哪些后续工作需要完成。

01 TiDB的整体架构
TiDB架构主要分为四个模块:TiDB、TiKV、TiSpark和PD,TiKV是用来做数据存储,是一个带事务的、分布式的key-value存储,PD集群是对原始数据里用来存储key-value里每一个范围的的k-v存储在每一个具体的k-v元数据信息,也会负责做一些热点调度;如热点 region调度。在Tikv中做数据复制和分布式调度都是rastgroup做的,每一个读写请求都下放到Tikv的leader上去,可能会存在某些Tikv的server或者机器的region leader特别多,这个时候PD集群就会发挥热点调度功能,将一些热点leader调度到其他机器上去。TiDB是所有场景中对接用户客户端的一层,也负责做SQL的优化,也支持所有SQL算子实现。Spark集群是用来做重型IP的SQL或者作业查询,做一些分布式计算。
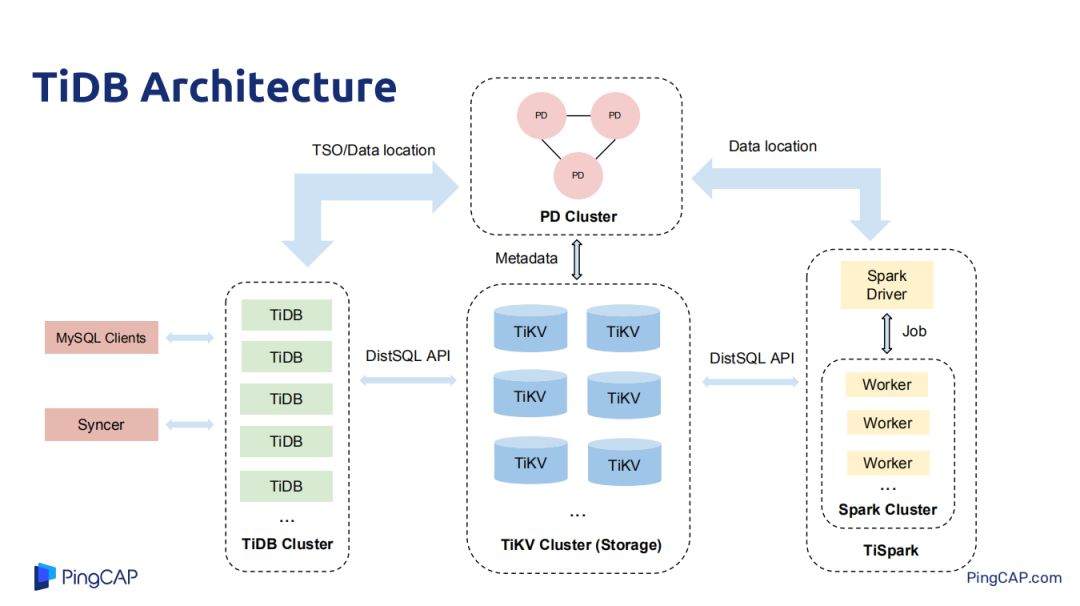
刨除Spark,TiDB集群主要有三个核心部分。最上层TiDB对接用户的各种My SQL/Maria DB clients,ORMs,JDBC/ODBC,TiDB的节点与节点之间本身是不做任何数据交互,是无状态的,其节点就是解析用户的query,query的执行计划生成。把一些执行计划下推到一些Tikv节点,将一些数据从Tikv节点拿上来,然后在PD中做计算,这就是整个TiDB的概览。
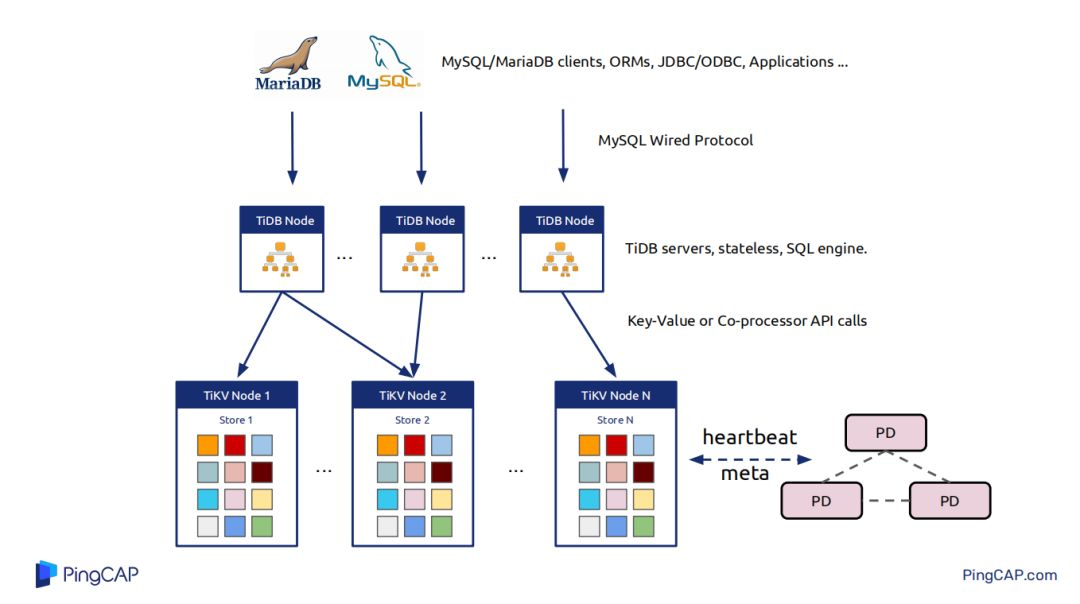
讲优化器之前需要讲一下TiDB中结构化的数据是如何映射到K-V数据的。在TiDB中只有两种数据,一种是表数据,一种是为表数据创建的index数据。表数据就是tableID加RowID的形式将其映射为Key-Value中的key,表数据中具体每一行的数据一个col的映射为其value,以Key-Value的形式存储到Tikv中。索引数据分为两种一种是唯一索引和非唯一索引,唯一索引就是tableID+IndexID+索引的值构成Key-Value中的key,唯一索引对应的那一行的RowID,非唯一索引就是将rowID encode到Key中。

下面是TiDB SQL层的应用组件,左边是协议层,主要负责用户的connect连接,和JDBC/ODBC做一些数据协议,解析用户的SQL,将处理好的结果数据以MySQL的形式encode成符合MySQL规范的格式化数据返回给客户端。中间的Session Context主要负责一个session里面需要处理的一些用户设置的各种变量,最右边就是各种权限管理的manager、源信息管理、DDL Worker,还有GC Worker也是在TiDB层。
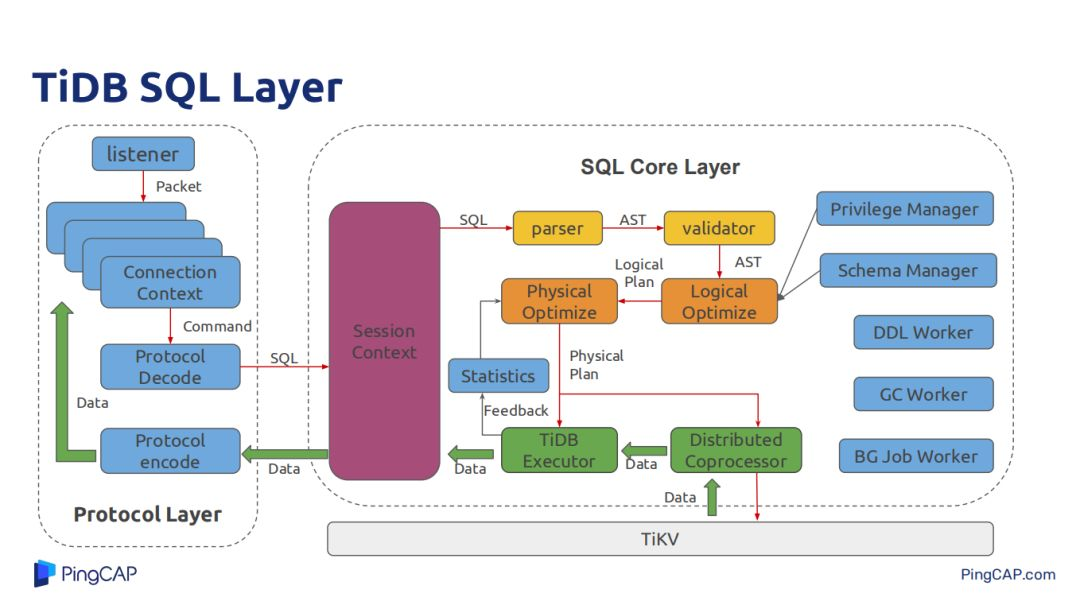
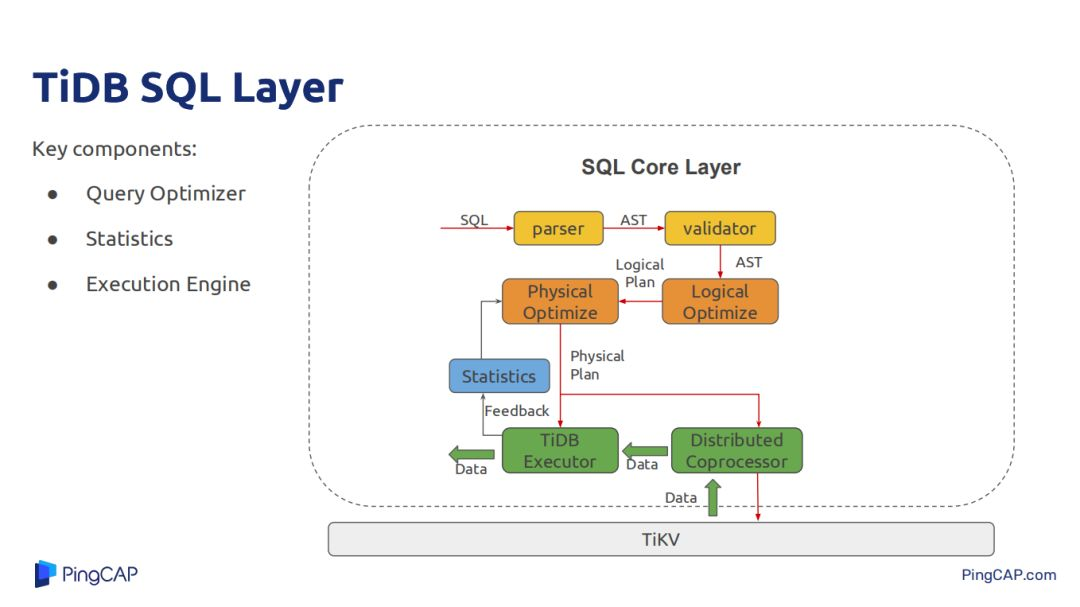
今天主要介绍SQL经过parser 再经过AST,然后Optimize,经过TiDB的SQL执行引擎,还有经过Tikv提供的Coprocessor,Coprocessor支持简单的表达式计算、data scan、聚合等。Tikv能让TiDB将一些大量操作都下推到Tikv上,减少Tikv与TiDB的数据交互带来的网络开销,也能让一部分计算在Tikv上分布式并行执行。
02 Query Optimizer
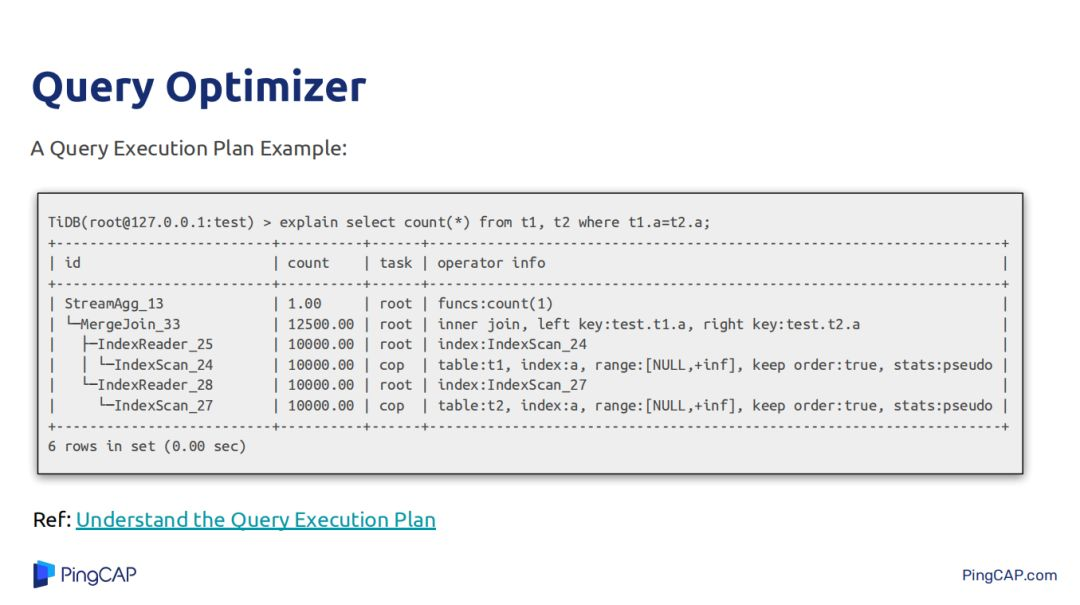
上图中的执行计划比较简单,就是两个表做join,然后对join的结果做count(*),join方式是merge join。
查询优化器解决的工作很复杂,比如需要考虑算子的下推,比如filter的下推,尽量下推到数据源,这样能减少所有执行数据的计算量;还有索引的选择,join Order和join算法的选择,join Order指的是当有多个表做join时以什么样的顺序去执行这些join,不同的join Order意味着有不同大小的中间结果,而且join Oder也会去影响某一些join节点算法的选择;还有子查询的优化,如硬子查询是将其优化成inner join还是嵌套的方式去执行硬子查询而不去join,这些在各种场景中因为数据源的分布不同,每一种策略都会在一种场景中有它自身的优势,需要考虑的方面很多,实现起来也比较困难。

优化器进行优化逻辑复杂,进行优化需要进行一些比较重的计算,为了降低一些不必要的计算。比如对一些简单的场景点查,根据一些组件查一条数据,这种就不需要经过特别复杂的计算,这种需要提前标记出来,直接将索引的唯一值ID解析出来,变成一次k-v scan,这种就不需要做复杂的优化,不用去做执行树的迭代。目前TiDB中的update、delete 、scan都支持k-v scan,还有PointGet Plan也支持这种优化。
TiDB的SQL优化器分为物理优化阶段和逻辑优化阶段,逻辑优化阶段的输入是一个逻辑优化执行计划,有了初始逻辑优化执行计划后,TiDB的逻辑优化过程需要把这个逻辑执行计划去应用一些rule,每一个rule必须具备的特点是输出的逻辑执行计划与输出的逻辑执行计划在逻辑上是等价的。逻辑优化与物理优化的区别是逻辑优化区别数据的形态是什么,是先join再聚合还是先聚合再join,它并不会去聚合算子是stream聚合还好hash聚合,也不会去关注join算子是哪一种物理算子。同时也要求rule将产生的每一个新的逻辑执行计划一定要比原来输入的逻辑执行计划要更优,如将一些算子下推到数据源比不下推下去要更优,下推后上层处理的数据量变少,整体计算量就比原来少。

接下来就讲一下TiDB中已经实现的一些逻辑优化规则,如Column Pruning就是裁减掉一些不需要的列,Partition Pruning针对的是分区表,可以依据一些谓词扫描去掉,Group By Elimination指的是聚合时Group By 的列是表的唯一索引时可以不用聚合。Project Emination是消除一些中间的没用的一些投影操作,产生的原因是在一些优化规则以自己实现简单会加一些Project ,还有就是从AST构造到最初逻辑执行计划时也会为了实现上的简单会去添加一些中间节点的投影操作,Outer Join Simplification主要针对null objective,如A>10,而A有又是null而且又是inner表中的列时,Outer Join就可以转化为inner join。


Max/Min Eliminatation在有索引的时候非常有用,如Max A是一个索引列,直接在A上做一个逆序扫第一行数据就可以对外返回结果,顶层还有一个Max A,这个是为了处理join异常情况,如Max和count对空输入结果值行为结果是不一样的,需要有一个顶层的聚合函数来处理异常情况,这样就不需要对所有数据做max,这样做的好处就是不用做全表扫描。
Outer Join Elimination可以将其转化为只扫描Outer 表,比如当用户只需要使用Outer Join 的Outer表,如例子中只需要t1表中的数据,如何inner表上的key刚好是inner表上的索引,那么这个inner表就可以扔掉,因为对于outer表中的每一条数据如果能join上,只会和inner表的一行数据join上,因为inner表上的key是唯一值,如果对应不上就是null,而返回的数据只需要outer表,inner表上的数据不需要。还有一种情况是父节点只需要outer表的唯一值,再做outer join如果对应上会膨胀很多值,而上层只需要不同值这样就不需要膨胀,这样就可以消除在outer表做一个select的distinct操作。

Subquery Decorrelation是一个多年研究的问题,上图例子是先从t1表中扫一行数据,去构造t2表的filter,然后去扫描t2表中满足这样的数据,对t2表的A做一个聚合,最终是t1表的A类数据小于求的和,才把t1表的这行数据输出。如果执行计划按照上述逻辑执行,那么每一行t1的值都会对t2进行全表扫描,这样就会对集群产生非常大的负担,也会做很多无用的计算。因此可以将优化成先聚合再join,就是先把t2表先按过滤的条件的列做一个group by,每一个group求t2表A的和,将其求得的和再去和t1表做join。上层的arcconditon,这样就不会对inner表频繁的做inner操作,从整体上看不用做全表扫描,每一行outer都会对t2表做扫描。

聚合下推不一定要优,但在某些场景很有用。两个表做join,以上面一个表为例,join的结果以t1的a做一个group by。如果t1表的t1.a列重复的值很多,先去做join就会导致重复的值和t2表能够匹配的值重复很厉害,再去做聚合计算量也非常大,有一种策略是将聚合下推到t1表上。将t1表上a做一个聚合,很多重复的t1.a再join之间就压缩成一条,join操作的计算量非常轻,在更上层的聚合相应减轻不少负担。但是不一定每种情况都有用,如果t1.a中的数据重复值不多,那么下推下去的聚合将数据过滤一遍又没有起到聚合的效果。Top N Limit Push Down只需要将其outer join push到outer端,这是因为outer表的数据要输出,只需要拿三条数据和inner表做join,如果有膨胀,再放一个top/limit将数据只限制在三条。相反如果将topN不push下去,那么从table3读取的数据会很大。

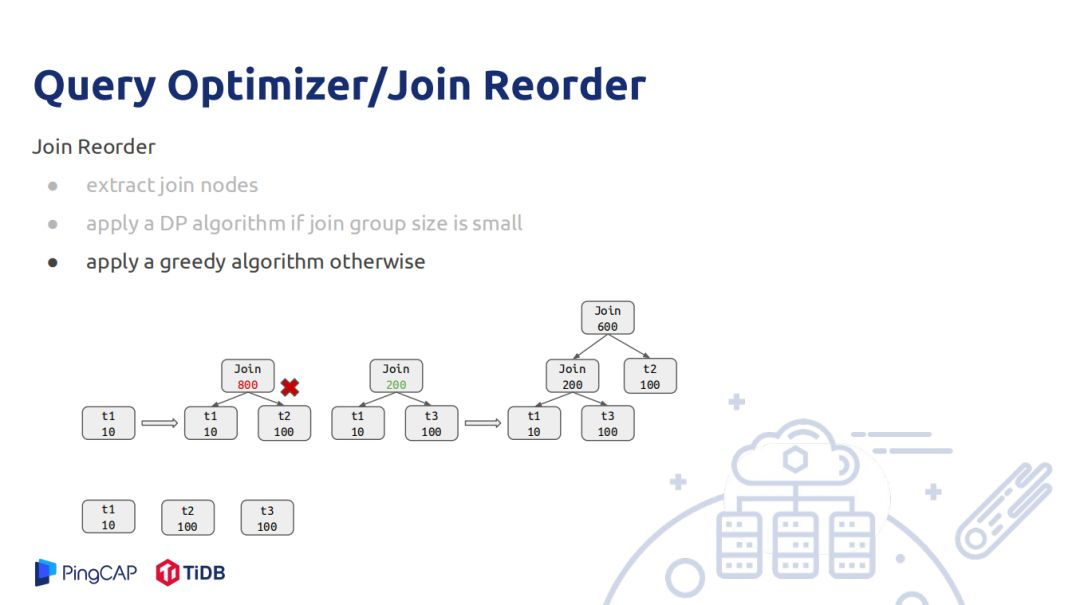
还有一个难题是Join Reorder,目前Join Reorder的算法有很多。统计信息精准度一定的情况下,选出一个最好的Join Reorder算法最好的方式是用DP算法。如果两者信息精确,利用动态规划得出的算法一定是最优的,但是现实中统计信息不一定优,如两张表信息是优但是join后的结果不一定符合数据真实分布,可能有推导误差。A、B统计节点是推导出来的,再去推导节点的统计信息,误差就被放大,因此DP的join order在使用真实的统计信息做join order再去推导统计节点的统计信息所做出来的order也不一定是好的。
在TiDB中使用的join order是一个子树,使用状态压缩的方式做的,就是6的整数用二进制的形式表示110, 0表示节点不存在,1表示节点存在,第1、2节点存在,第0号节点不存在。就决定了最优的join顺序是什么,这样DP算法推导就比较简单,不断的枚举其子集合,6可以分为110和10,分别join两个子集合,选择所有情况中最小的一个;这种方式时间复杂度很高,如果节点过多,做join reorder的时间会很长。还有DP算法是用整数代替join节点,如果10个节点就是210,20个节点就是1M内存。因此当节点比较大的时候采用贪心策略做join reorder,实现原理是先将所有的join recount估算,从小打到大排序,一次选择按边相连的节点去做join,如图一开始初始是t1和t2做join结果估算有800,由于t3的count也是100,也需要考虑t1和t3做join,join出来是200,则t1和t3优先做join,然后再遍历节点数后最小的节点与当前join数做join,当为join节点集合为空时整个join树就生成了。但是局部最优不一定全局最优,并不能把所有情况都考虑最好的join顺序。

接下来是物理优化阶段,逻辑优化并不决定以什么算法去执行,只介绍了join顺序,并没有说要用那种join方式。物理优化需要考虑不同的节点,不同的算法对输入输出有不同的要求,如hash和merge join实现的时间复杂度本身不一样。要理解物理优化的过程要理解什么是物理属性。物理属性是一个物理算法所具备的属性,在TiDB就有task type属性,就是这个算法是应该在TiDB中执行还是在Tikv中执行;data order说的是算法所产生的数据应该以什么样的顺序属性,如merge join是按outer join的key有序的。Stream聚合也是按照group by的column有序。但是有些算法无法提供join顺序,如hash join,还会破坏数据的顺序,hash join无法对外提供任何顺序上的保证。在分布式场景中做执行计划时需要考虑分布的属性,如hash join在一个分式的节点上执行,考虑的是选表多下搜的方式,如果想正确出结果最好的方式是将小表和大表的数据都按照join的key下放到不同的机器上,那么分布式的hash join特点就是join的key分布在同一台机器上。在TiDB没有考虑数据分布的特性,动态规划的状态就是输入的逻辑状态是什么,实现的逻辑执行计划的物理执行计划需要满足什么样的物理属性,最后推导出一个最佳的物理执行计划。这样同一个逻辑节点可能会多次被父节点以不同路劲访问它,因此需要缓存中间节点,下次父节点以同样的动态规划状态访问直接将之前最佳的结果返回就行。
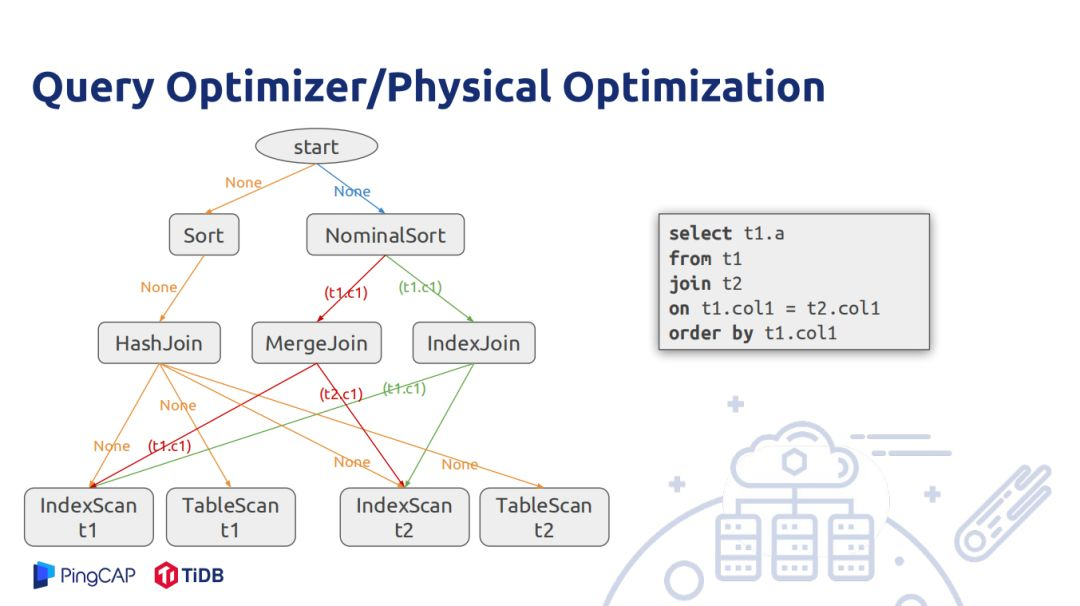
上图的实例是对两个表做join,join后数据按照join key排序,假设t1和t2表都在各自的join key上有索引,对于t1和t2表扫描有两种方式,一种是index scan能够满足返回的数据以index有序,或者table scan不能满足index scan有序,nominalsort是TiDB内部优化算子,既不会出现在逻辑执行计划里面也不会出现物理执行计划里面,只是在做物理执行计划辅助作用,从一开始调用动态规划过程,输入逻辑计划要求满足的物理属性是空,接下来可以用物理sort算子和nominalsort算子,其本身不 排数据,而是将排数据的功能传递给子节点。

在物理优化中比较重要的一点是如何选择索引,没有索引一个慢查询会导致所有集群都慢。最后引入Skyline index Pruning,当要选择那个选项最优时有多个维度可以考量,访问一个表的方式有多种方式选择,其要求就是父节点要求子节点返回的数据是否有序,还有就是索引能够覆盖多少列,这是因为用户建索引并不是一定按照最优解来建。
从优化过程来说,算法并不是最优的,应用完一个rule不会再次去应用,但是实际是会多次使用的。解决有Memo优化,就是将所有表达式存储,将等价表达式存储于一个group里面,将所有rule用最小化、原子化做group expression。
03 Statistics
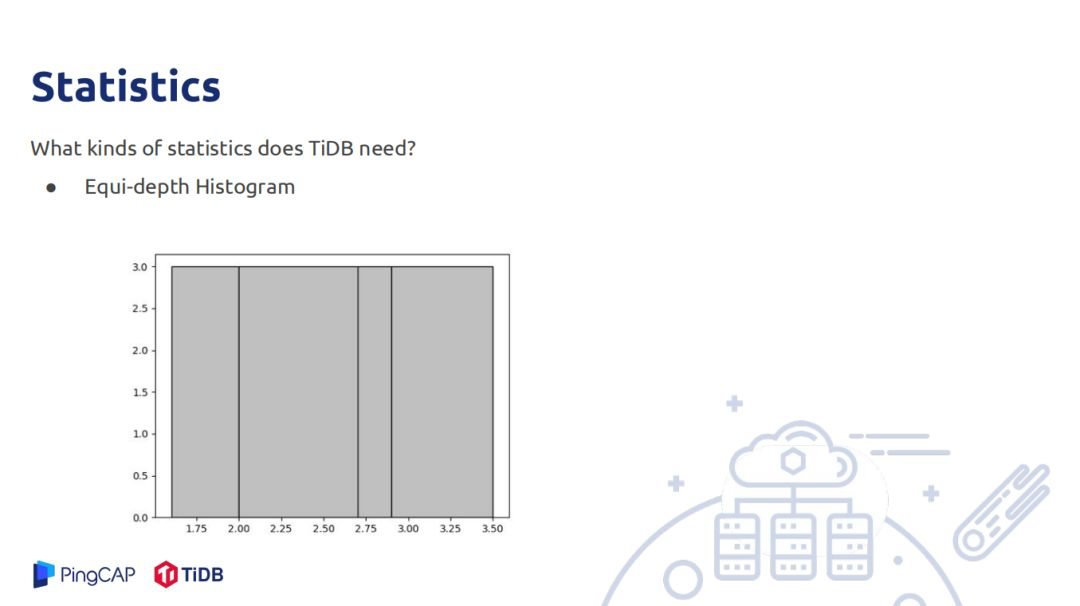
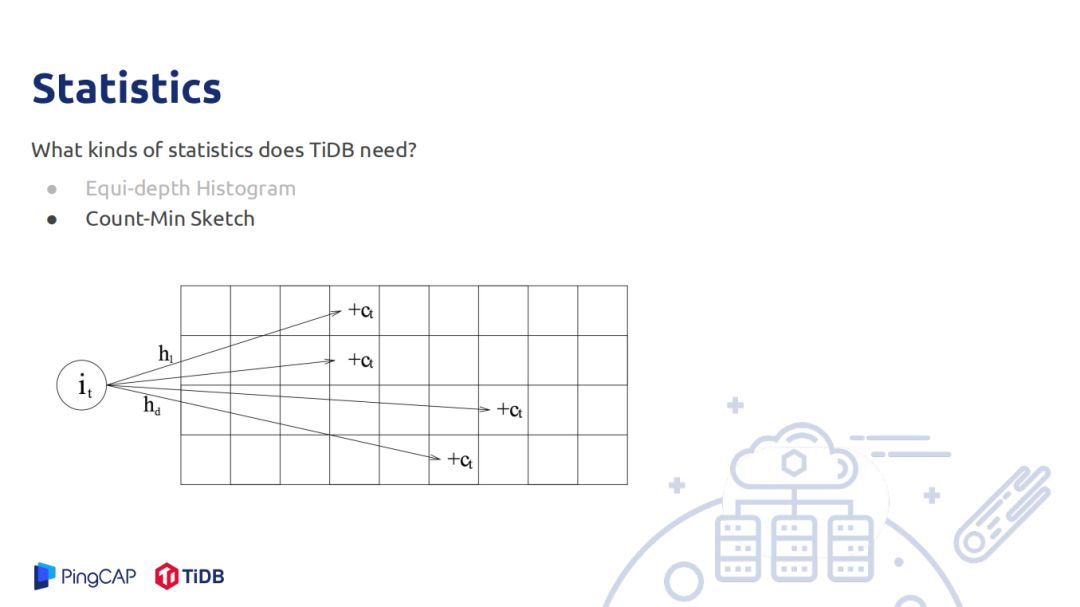
统计信息是用来估算row count,需要估算的row count有filter、join、聚合。TIDB中存储的统计信息有直方图,主要用于估算范围查询的统计信息,被覆盖的其count直接加上去,部分覆盖的桶使用连续均匀分布的假设,被覆盖的部分乘以桶的rowcount加上去;另一个是估算点查询的rowcount,可以理解Min-Sketch,只是估算的值不再是0和1,数据代表是这个位置被hash到了多少次,如一个数据有D个hash函数,将其hash到D的某个位置,对具体位置加上1,查询也做同样的操作,最后取这D位置最小的值作为count估计,这个估计在实际中精度较高。
TiDB收集统计信息的方式有很多,首先手动执行analyze语句做统计信息的搜集;也可以配置自动analyze,就是表的更新超过某些行数会自动做analyze;还有Query Feedback,就是在查询请求,如果查的数据分布和以前统计的数据分布信息不太匹配回去纠正已有的统计信息。
04 Future Work

接下来一些工作就是查询计划的稳定性,重要的是索引的准确,还有就是有些算法的选择也会影响查询计划的稳定性;The Cascades Planner就是要解决搜索空间的搜索算法的效率问题,搜索空间导致执行计划不够优的问题。还有快孙analyze,目前表以亿起步,如果现场采样,会比较慢因此会采取一些手段加速analyze过程。Multi-Column Statistics主要生死用来解决多列之间的相关性,以前做row count估算都是基于column与column间的不相关假设做row count,这样估计的值比实际值偏大,有多列相关估算准确度会提高很多。
今天的分享就到这里,谢谢大家。
本文首发于微信公众号“DatafFunTalk”
欢迎转载分享,转载请留言或评论。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK