

CVPR 2022:微笑识别也带性别歧视?浙大武大联合蚂蚁Adobe搞了个公平性提升框架
source link: https://www.qbitai.com/2022/04/34250.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
CVPR 2022:微笑识别也带性别歧视?浙大武大联合蚂蚁Adobe搞了个公平性提升框架

无须改变已部署模型
作者:董小威
AI模型存在偏见怎么办?
近年来,AI在多个领域展现出卓越的性能,给人类生活带来便捷和改善。
与此同时,不少AI系统被发现存在对特定群体的偏见或者歧视现象。
犯罪预测系统COMPAS在美国被广泛使用,通过预测再次犯罪的可能性来指导判刑。
研究者发现,相比于白人,黑人被预测为高暴力犯罪风险的可能性竟然高77%。这里就存在一个严肃的问题:犯罪与否难道能由肤色来决定?

我们经常使用的搜索引擎也普遍存在偏见。如果搜索“护士”的图片,返回的结果中大部分都是女性。

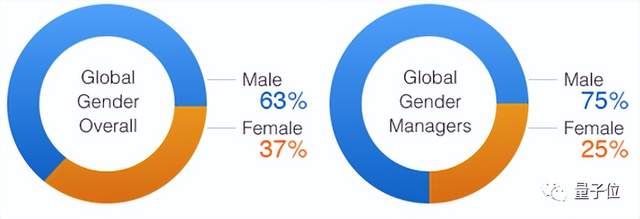
亚马逊的员工招聘系统,被曝出倾向于给男性打高分,给女性打低分。

为什么AI系统存在偏见?它是如何学会的?多半是数据教会了它。
例如,在亚马逊的雇员数据中,男性远多于女性,导致AI学到了性别和录用间的虚假关联,误以为男性更有资格被录用。
针对这一问题,研究者提出了多种公平性提升方案,但它们本质上都要修改已部署的深度学习模型。
“如果已部署上线的深度学习模型存在偏见,如何在不修改模型的情况下提升公平性呢?”浙江大学王志波教授提出了这个问题。
针对该问题,浙大王志波和任奎团队联合武汉大学、蚂蚁集团与Adobe公司,提出了一种基于对抗性扰动的深度学习模型公平性提升方案,在无须改变已部署模型的情况下提升系统的公平性。
该方案的基本思想是:通过自适应地对输入数据添加对抗性扰动,阻止模型提取出敏感属性相关信息,保留目标任务相关信息,从而使得模型公平地对待不同敏感属性的群体,给出公平的预测结果。
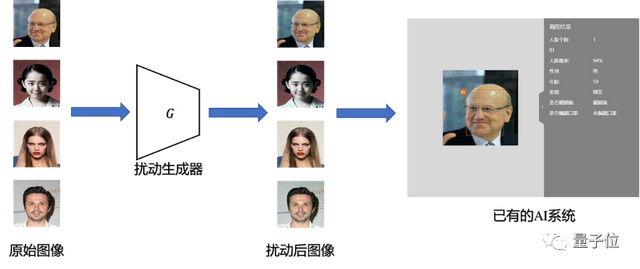
公平性提升方案FAAP
FAAP框架包含已部署的模型、扰动生成器和判别器三个部分:

首先,用扰动生成器对图像添加对抗性扰动,扰动后的图像会输入到部署模型的特征提取器,获得图像的隐空间表示,并分别输入到标签预测器和判别器。

接着衡量扰动后的图像中包含的敏感属性的信息,训练判别器从隐空间表示中预测敏感属性,并对判别器进行更新。
之后对扰动生成器进行更新,欺骗判别器,使扰动后的图像在隐空间表示中不包含敏感属性的信息,同时使标签预测器的预测结果准确。

对以上步骤进行迭代,获得最终的扰动生成器,作为数据预处理单元,为已有的AI系统提升公平性。
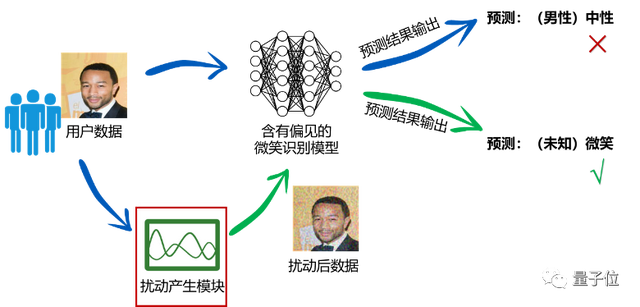
模型预测真的变公平了吗?
通过观察注意力显著图可以发现,有性别偏见的微笑识别模型,会关注于原始图像的头发区域,不可避免地使用性别相关特征进行预测。相比之下,该方案可以让模型更关注于图像嘴部区域,从而不受敏感属性的影响,做出公平的预测:

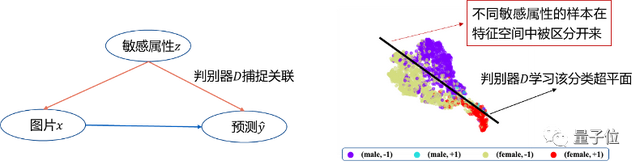
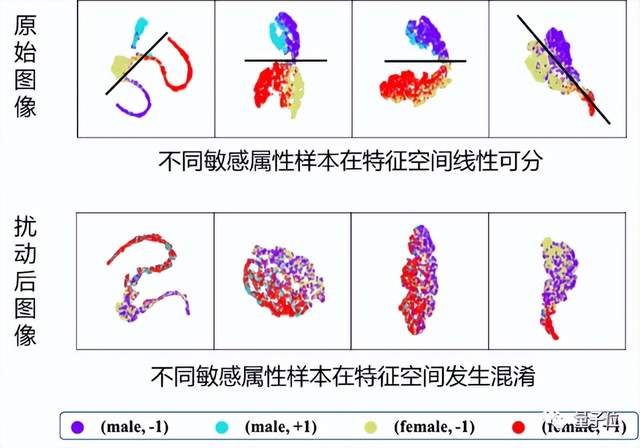
使用T-SNE处理模型特征空间的输出,可以发现,带有性别偏见的模型,在特征空间能分辨出原始图像中不同性别的样本,因而区别对待不同性别的人群。相比之下,该方案让具有不同敏感属性的样本在特征空间发生混淆,使得它们被模型公平对待:
该项研究首次考虑在不改变深度学习模型的前提下提升公平性,提出的方案更贴合真实应用场景。
对于一般的部署模型,在基本不影响准确率的情况下,该方案可以大幅提升公平性,例如,在公平性指标DP和DEO上平均能够获得27.5%和66.1%的提升。
目前,该研究成果的相关论文“Fairness-aware Adversarial Perturbation Towards Bias Mitigation for Deployed Deep Models”已被CVPR 2022录用。
论文地址:
https://arxiv.org/abs/2203.01584
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK