

超大规模系统下,MySQL到Redis的数据同步也不难吧?
source link: https://www.51cto.com/article/707158.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


一、缓存穿透
超大规模系统的不能承受之痛
如何构建Redis集群?由于集群可以水平扩容,因此只要集群足够大,理论上支持海量并发就不是问题。但是,如果并发请求数量的基数过大,那么即使只有很小比率的请求穿透缓存,直接访问数据库的请求其绝对数量也仍然不小。再加上大促期间的流量峰值,还是会存在因为缓存穿透而引发系统雪崩的风险。
那么,这个问题该如何解决呢?其实方法并不难想到,不让请求穿透缓存就行了。如今内存存储的价格一路走低,只要能买得起足够多的服务器,Redis集群的容量就是无限的。 我们可以把全量数据都放在Redis集群中,处理读请求的时候,只需要读取Redis,而不用访问数据库,这样就完全没有“缓存穿透”的风险了。 实际上,很多大型互联网公司都在使用这种方法。
不过,在Redis中缓存全量数据,又会引发一个新的问题。那就是,缓存中的数据应该如何更新呢?因为我们取消了缓存穿透的机制,在这种情况下,如果能从缓存中直接读到数据,则可以直接返回,如果没能读到数据,那就只能返回错误了! 所以,当系统更新数据库的数据之后,必须及时更新缓存。
至此,我们又要面对一个老问题:如何保证Redis中的数据与数据库中的数据同步更新?可以用分布式事务来解决数据一致性的问题,但是这些方法都不太适合用来更新缓存。原因是,分布式事务对数据更新服务有很强的侵入性。这里仍以下单服务为例来说明,如果为了更新缓存,增加一个分布式事务,那么无论我们使用哪种分布式事务,下单服务的性能或多或少都会受到影响。还有一个问题是,如果Redis本身出现了故障,写入数据失败,则还会导致下单失败的问题,相当于是降低了下单服务的性能和可用性,这样肯定是不行的。
对于像订单服务之类的核心业务,一个可行的方法是,启动一个更新订单缓存的服务,接收订单变更的消息队列(Message Queue,MQ)中的消息,然后更新Redis中缓存的订单数据。使用订单变更消息更新缓存的结构如图1所示。因为对于这类核心的业务数据,使用方通常会非常多,服务本来就需要向外发送消息,增加一个消费订阅,基本上不会增加额外的开发成本,也不需要对订单服务本身做出任何更改。
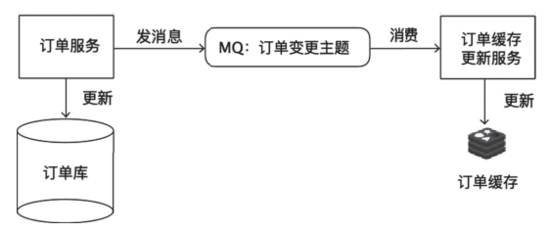
图1使用订单变更消息更新缓存
对于上述方法,我们唯一需要担心的问题是,如果消息丢失了,应该怎么办?因为现在消息是缓存数据的唯一来源,一旦出现消息丢失的问题,缓存里缺失的那条数据就会永远也无法补上,所以,必须保证整个消息链条的可靠性。不过,好在现在的MQ集群(比如Kafka或RocketMQ),都拥有高可用性和高可靠性的保证机制,只要能事先正确配置好,就可以满足数据的可靠性要求。
像订单服务这样,由于本来就有现成的数据变更消息可以订阅,因此像这样更新缓存也是一个不错的选择,因为这种方式实现起来很简单,对系统的其他模块也完全没有侵入。
二、使用Binlog实时更新Redis缓存
如果我们要缓存的数据,原本就没有一份数据更新的消息队列可以订阅,又该怎么办呢?下面就来介绍很多大型互联网企业所采用的,也是更通用的解决方案。
数据更新服务只负责处理业务逻辑,更新MySQL,完全不用考虑如何更新缓存。 负责更新缓存的服务,把自己伪装成一个MySQL的从节点,从MySQL接收并解析Binlog之后,就可以得到实时的数据变更信息,然后该服务就会根据这个变更信息去更新Redis缓存。订阅Binlog更新缓存的结构如图2所示。
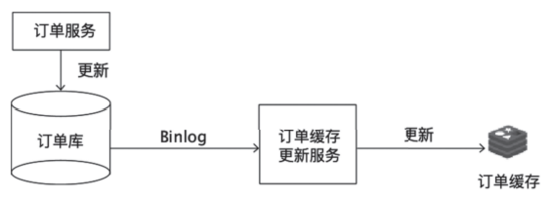
图2订阅Binlog更新缓存的结构
订阅Binlog更新缓存的方案,相较于上文中接收消息更新Redis缓存的方案,两者的实现思路其实是一样的,都是 异步实时订阅数据变更信息以更新Redis缓存。 只不过,直接读取Binlog这种方式,通用性更强。该方式不会要求订单服务再发送订单消息,订单更新服务也不用额外考虑如何解决“消息发送失败了该怎么办?”这种数据一致性问题。
除此之外,由于在整个缓存更新链路上,减少了一个收发消息队列的环节,从MySQL更新到Redis更新的时延变得更短,出现故障的可能性也更低,因此很多大型互联网企业更青睐于采用这种方案。
订阅Binlog更新缓存的方案唯一的缺点是,实现订单缓存更新服务比较复杂,该方案毕竟不像接收消息那样,收到的直接就是订单数据,解析Binlog还是挺麻烦的。
很多开源的项目都提供了订阅和解析MySQL Binlog的功能,下面就以比较常用的开源项目Canal为例来演示,如何实时接收Binlog更新Redis缓存。
Canal通过模拟MySQL主从复制的交互协议,把自己伪装成一个MySQL的从节点,向MySQL主节点发送dump请求。MySQL收到请求后,就会向Canal开始推送Binlog,Canal解析Binlog字节流之后,将其转换为便于读取的结构化数据,供下游程序订阅使用。图3展示了如何使用Canal订阅Binlog更新Redis中的订单缓存。
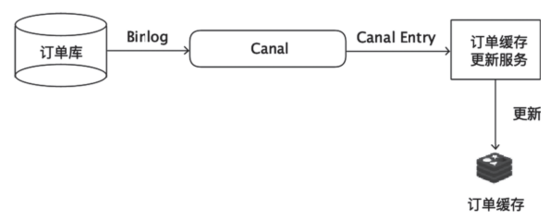
图3使用Canal订阅Binlog更新缓存
在这个示例中,MySQL和Redis都在本地的默认端口上运行,MySQL的端口为3306,Redis的端口为6379。为了便于大家操作,下面还是以第5章中提到的账户余额表account_balance作为演示数据。
首先,下载并在本地解压Canal当前最新的1.1.4版本,操作命令如下:
wget https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.deployer-1.1.4.tar.gz
tar zvfx canal.deployer-1.1.4.tar.gz然后,配置MySQL,我们需要在MySQL的配置文件中开启Binlog,并将Binlog的格式设置为ROW,配置项如下:
[mysqld]
log-bin=mysql-bin # 开启Binlog。
binlog-format=ROW # 将Binlog格式设置为ROW。
server_id=1 # 配置一个ServerID。接下来,为Canal新建一个专门的MySQL用户并授权,以确保这个用户有复制Binlog的权限,具体操作的SQL命令如下:
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;然后,重启MySQL,以确保所有的配置都能生效。重启后再检查一下当前的Binlog文件和位置,SQL命令和输出结果具体如下:
mysql> show master status;
+-------------+--------+------------+----------------+-----------------+
| File |Position|Binlog_Do_DB|Binlog_Ignore_DB|Executed_Gtid_Set|
+-------------+--------+------------+----------------+-----------------+
|binlog.000009| 155| | | |
+-------------+--------+------------+----------------+-----------------+记录下File和Position两列的值,然后再来配置Canal。编辑Canal的实例配置文件canal/conf/example/instance.properties,以便让Canal连接到我们的MySQL上,具体配置如下:
canal.instance.gtidon=false
# position info
canal.instance.master.address=127.0.0.1:3306
canal.instance.master.journal.name=binlog.000009
canal.instance.master.position=155
canal.instance.master.timestamp=
canal.instance.master.gtid=
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8
canal.instance.defaultDatabaseName=test
# table regex
canal.instance.filter.regex=.*\\..*这个配置文件需要配置MySQL的连接地址、库名、用户名和密码,除此之外,还要配置canal.instance.master.journal.name和canal.instance.master.position这两个属性,取值就是刚刚记录的File和Position两列。然后就可以启动Canal服务了,命令如下:
canal/bin/startup.sh启动之后再查看一下日志文件canal/logs/example/example.log,如果日志中没有报错信息,就说明Canal服务已启动成功并连接到我们的MySQL上了。
Canal服务启动之后,会开启一个端口(11111)等待客户端连接,客户端连接上Canal服务之后,就可以从Canal服务拉取(PULL)数据了,每拉取一批数据,正确写入Redis之后,需要向Canal服务返回处理成功的响应。如果发生客户端程序宕机,或者处理失败等异常情况,Canal服务没有收到处理成功的响应,那么下次客户端来拉取的就还是同一批数据,这样就可以保证读到的Binlog顺序不会乱,并且不会丢失数据。
接下来,我们来开发一个账户余额缓存的更新程序,以下代码都是用Java语言编写的:
while (true) {
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据。
long batchId = message.getId();
try {
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
Thread.sleep(1000);
} else {
processEntries(message.getEntries(), jedis);
}
connector.ack(batchId); // 提交确认。
} catch (Throwable t) {
connector.rollback(batchId); // 处理失败,回滚数据。
}
}这个程序的逻辑并不复杂,程序启动并连接到Canal服务后,就不停地拉取数据,如果没有数据就休眠一会儿,如果有数据就调用processEntries方法处理并更新缓存。每批数据更新成功之后,都会调用ack方法向Canal服务返回成功响应,如果失败则抛出异常之后再回滚。下面是processEntries方法的主要代码:
for (CanalEntry.RowData rowData : rowChage.getRowDatasList()) {
if (eventType == CanalEntry.EventType.DELETE) { // 删除。
jedis.del(row2Key("user_id", rowData.getBeforeColumnsList()));
} else if (eventType == CanalEntry.EventType.INSERT) { // 插入。
jedis.set(row2Key("user_id", rowData.getAfterColumnsList()), row2Value(rowData.getAfterColumnsList()));
} else { // 更新。
jedis.set(row2Key("user_id", rowData.getAfterColumnsList()), row2Value(rowData.getAfterColumnsList()));
}
}上述代码会根据事件类型分别进行处理,如果MySQL中的数据删除了,就删除Redis中对应的数据。如果是更新和插入操作,就调用Redis的SET命令来写入数据。
下面就来启动这个账户缓存更新服务以进行验证。在账户余额表中插入一条记录,SQL命令如下:
mysql> insert into account_balance values (888, 100, NOW(), 999);然后,我们再来看一下Redis缓存,操作命令和输出结果如下:
127.0.0.1:6379> get 888
"{\"log_id\":\"999\",\"balance\":\"100\",\"user_id\":\"888\",\
"timestamp\":\"2020-03-08 16:18:10\"}"从上述输出结果中我们可以看到,数据已经自动同步到Redis中了。GitHub上可以下载该示例的完整代码,链接地址是:https://github.com/liyue2008/canal-to-redis-example。
在处理超大规模并发的场景时,由于并发请求的数量非常大,即使只有少量的缓存穿透,也有可能卡死数据库引发雪崩效应。对于这种情况,我们可以通过Redis缓存全量数据来彻底避免缓存穿透的问题。对于缓存数据更新的方法,我们可以通过订阅数据更新的消息队列来异步更新缓存,更通用的方法是,把缓存更新服务伪装成一个MySQL从节点,订阅MySQL的Binlog,通过Binlog来更新Redis缓存。
需要特别注意的是,无论是通过消息队列还是Canal来异步更新缓存,系统对整个更新服务的数据可靠性和实时性要求都比较高,数据丢失或者更新慢了,都会造成Redis中的数据与MySQL中的数据不同步的问题。在把这套方案应用到生产环境之前,我们需要考虑一旦出现不同步的问题,应该采取什么样的降级或补偿方案。
李玥, 美团基础技术部高级技术专家,极客时间《后端存储实战课》《消息队列高手课》等专栏作者。曾在当当网、京东零售等公司任职。从事互联网电商行业基础架构领域的架构设计和研发工作多年,曾多次参与双十一和618电商大促。专注于分布式存储、云原生架构下的服务治理、分布式消息和实时计算等技术领域,致力于推进基础架构技术的创新与开源。
本文摘编自《电商存储系统实战:架构设计与海量数据处理》,经出版方授权发布。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK