

gatsby-remark-link-beautify 开发记录
source link: https://www.talaxy.site/gatsby-plugin-dev/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

gatsby-remark-link-beautify 开发记录
2022 年 04 月 14 日 • 🍵🍵 需要 8 分钟
今年春节期间我开始着手实现去年的一个想法:
刚刚洗澡的时候我突发奇想!能不能让鼠标悬浮在网页链接的时候用小窗把这个页面加载出来,起到预览的效果,项目名我都想好了,就叫 link-preview。然后出来在 GitHub 上搜了下,发现已经有一堆这样的项目了🥴
— 鲮鱼罐头 009 (@Taozc009) December 13, 2021
很长一段时间里我都没有实现的思路,我曾试过在页面中加入 iframe 来预览目标网页,但可惜的是很多站点都不允许被以这种方式嵌入,加之 iframe 也有一些问题,所以我放弃了这条路。直到春节期间,我实在是闲着没事,才最终发现了一个可以实现的思路:
拿起你的武器
我在 Gatsby 的插件列表里找到了 gatsby-remark-link-preview
,这个插件给了我很大的启发。它可以遍历 markdown 文件中的特定链接,并生成卡片插入到页面中,主要工作流程大致如下:- 遍历 markdownAST,找到所有链接节点
- 筛选这些节点中包含
$card文本的节点 - 使用 puppeteer 访问这些链接的页面
- 将网站信息提取出来,拼接成 HTML 字符串
- 将 HTML 字符串插入到原有的节点中并将节点类型修改为
html
我第一次知道 Puppeteer
这个东西,一番搜索后,我知道这实际上是个受 JS 代码控制的浏览器(基于 Chromium)。更重要的是!它可以给访问的页面生成截图,这正是我新项目所需要的功能。那么,我把上面流程稍微修改一下就可以了:
- 遍历 markdownAST,找到所有链接节点
- 使用 puppeteer 访问这些节点链接的页面
- 获取页面截图(base64),拼接成 HTML 字符串
- 将 HTML 字符串插入到原有的节点中并将节点类型修改为
html
真的有这么简单吗?
还真的就这么简单!
我把这些工作完成后发布了 1.0.0 版本,这个版本我保留了 gatsby-remark-link-preview 的嵌入卡片功能(因为我正好可以用这来生成友情链接页面),并且支持了自定义卡片的样式,效果如下。
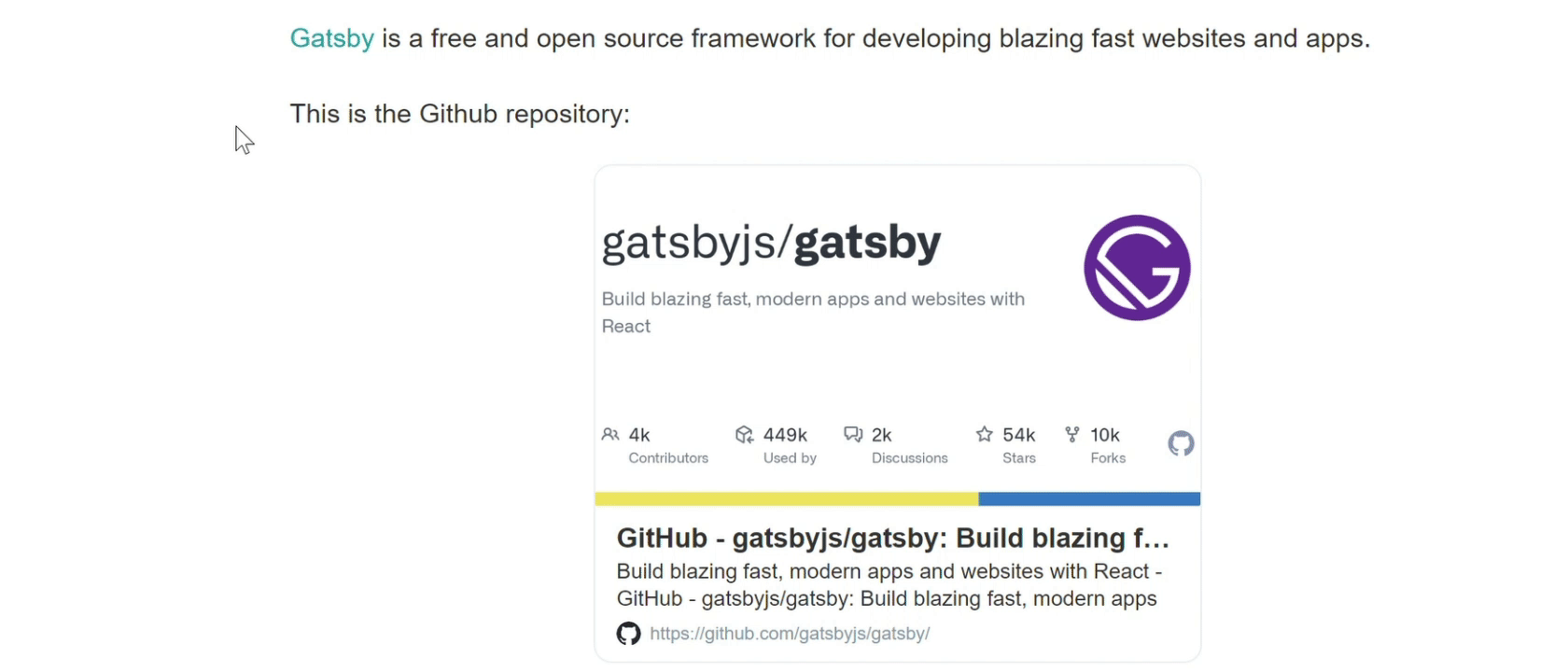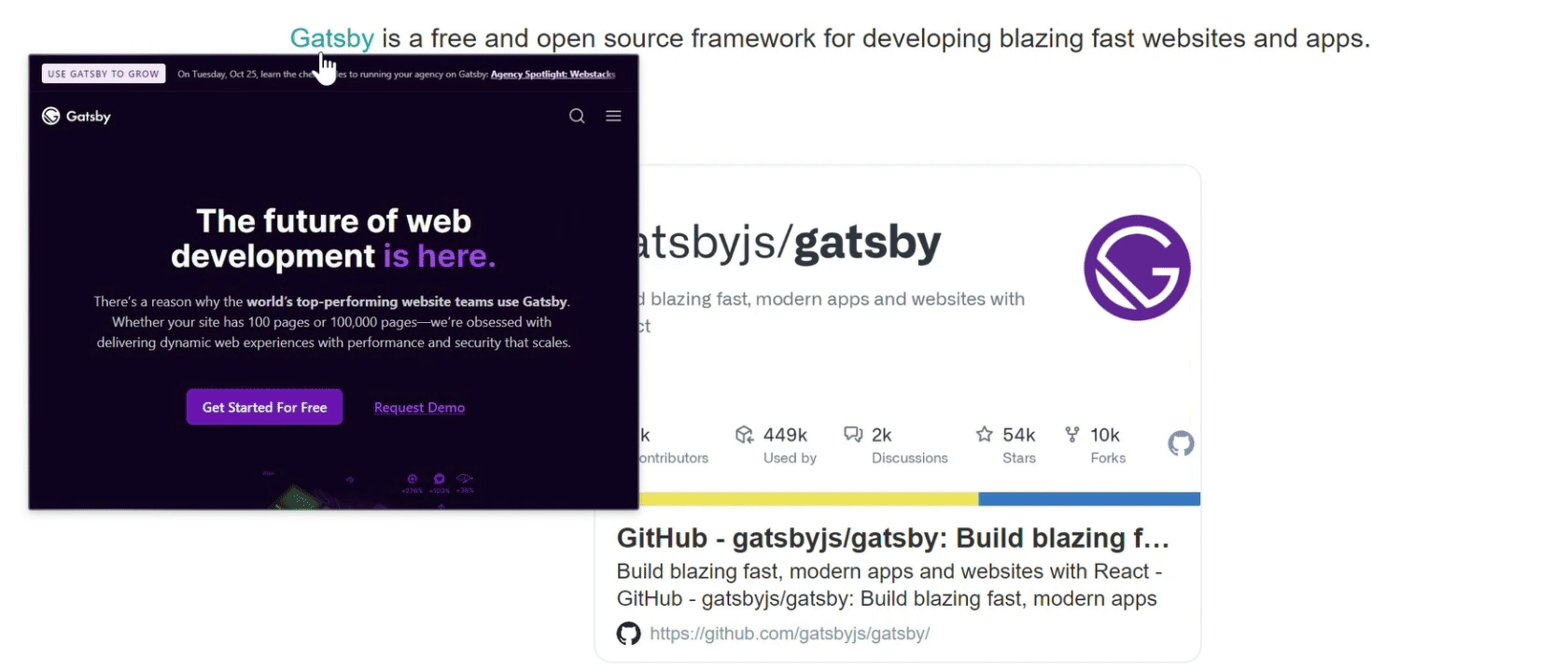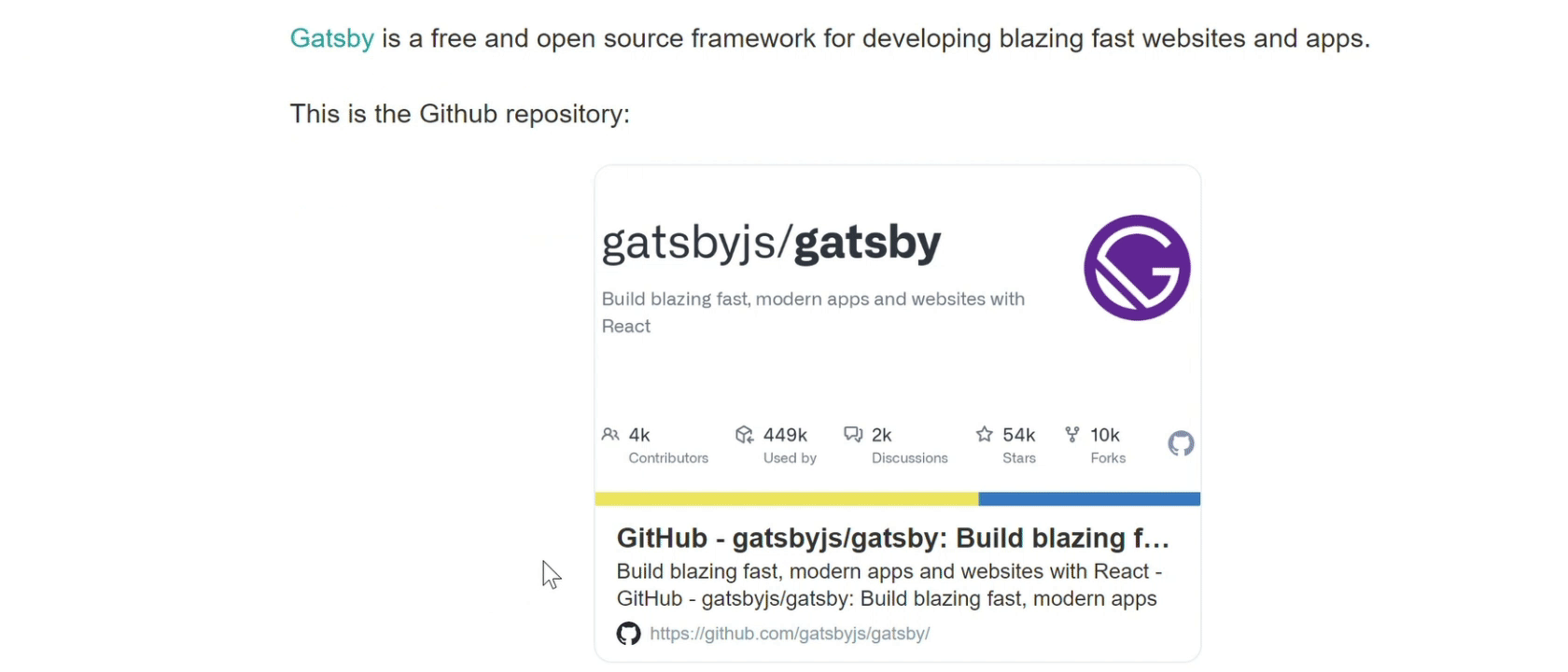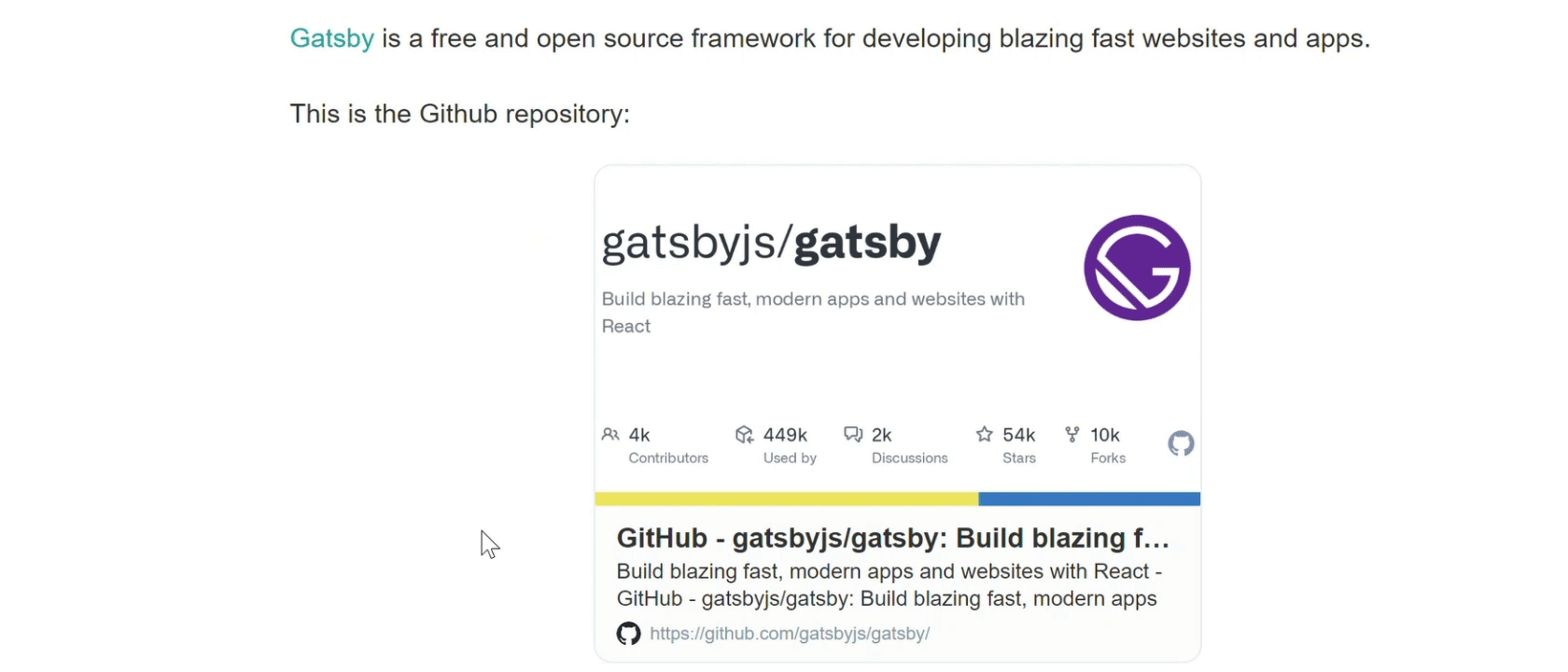
上述工作结束后,完整的流程如下:
- 调用
puppeteer.launch()创建一个浏览器实例 - 遍历 markdownAST,找到所有链接节点
- 如果有缓存,直接使用缓存,否则进行下面步骤
- 使用 puppeteer 创建新的页面来访问这些节点链接的页面
- 根据
$card标识符判断是否需要生成卡片,否则进行截图预览 - 获取页面截图/获取网站信息,拼接成 HTML 字符串
- 缓存 HTML 字符串
- 将 HTML 字符串插入到原有的节点中并将节点类型修改为
html
而在实现鼠标悬浮显示预览图上,则是完全靠 CSS 配合 HTML 实现的,核心代码如下(完整的代码可以在我的 Github 仓库中找到):
<span class="link-preview-container">
<a target="_blank" rel="noopener noreferrer" href="{目标链接}">
链接文字
</a>
<img src="data:image/webp;base64,{base64 预览图}" />`}
</span>/* 父元素相对定位 */
.link-preview-container {
position: relative;
}
/* 这里的 left 样式经过了优化,所以和上面的效果图有点不同 */
.link-preview-container img {
/* 默认情况下不显示 */
display: none;
/* 绝对定位 */
position: absolute;
object-fit: cover;
border-radius: 2px;
/* 和链接文字间隔 0.5em */
top: 1.5em;
/* 父元素宽度的一半减去预览图宽度的一半,使预览图水平居中 */
left: calc(50% - 200px);
width: 400px;
height: 300px;
/* 防止被其它元素遮挡 */
z-index: 9;
border: 1px solid rgba(207, 217, 222, 0.4);
-webkit-box-shadow: 0px 2px 5px rgba(10, 20, 20, 0.2);
box-shadow: 0 2px 5px rgba(10, 20, 20, 0.2);
}
/* 鼠标悬浮时显示预览图 */
.link-preview-container:hover img {
display: block;
}看上去不错,也实现了我想要的功能,比较棒的一点是,预览过程完全在 SSG 中,这可以极大的提升用户的体验,同时因为众所周知的原因,一些无法顺利访问的站点也不会受用户的网络环境影响而无法预览(但他们仍然可能无法访问)。而在我使用的这段时间里,我发现了点问题:经常会有大量页面超时而无法获取到预览截图,看来还有待改进。
性能是硬伤
用 Puppeteer 一直绕不开的就是性能问题,在此项目中更是如此,因为一个文章的链接少则有两三个多则有上十个,而一个博客又有上十篇文章,所以一次完整的打包可能要爬取几十个页面(试想一下在电脑上用浏览器同时打开几十个标签页的恐怖场景)。我在 1.1.0 版本加入了 puppeteer-cluster 依赖,希望能借集群来加快这一过程,但效果仍不明显,直到这周我才发现了问题所在,且看下文。
经过一次无意的操作(我让插件找到所有链接节点后输出链接数量),我发现每处理一个 markdown 文档 Gatsby 就会运行一次博客项目中的 remark 插件(包括本插件)。也就是说,每处理一个 markdown 文档就会启动一个浏览器,更糟糕的是这个浏览器可能处理了文档中的一两个链接就没用了(最糟糕的是这个文档里可能没链接,浏览器单纯的启动后又关闭了),而在引入了 puppeteer-cluster 之后,这一过程就变成了:每处理一个 markdown 文档就会启动一个集群,更恐怖了😨。
总结上面两段,目前急需解决的两大问题分别是:
- 同时打开大量页面,资源迅速耗尽,每个页面都喂不饱;
- 每处理一个 markdown 文档都会启动一个实例,资源大量浪费;
节省了资源才能更好的进行分配!所以我选择先处理问题二!
全局变量帮帮我
既然每处理一个 markdown 文档都会运行一遍 remark 插件,那我是否可以只启动一定数量的浏览器,把所有任务都交给它们运行呢?当然可以!puppeteer 提供了 connect 方法,通过给这个方法传入 browserWSEndpoint(本质上是一个 websocket 协议链接)可以连接至已创建的浏览器来对其操作,那么我们只需要在第一次运行插件时创建好几个浏览器,把它们的 wsEndpoint 保存到全局变量中,后续再运行时就可以直接 connect 了,由于 puppeteer-cluster 不支持 connect,只好放弃用它了,核心代码如下:
// 设浏览器数(实际项目时会放在配置选项中)
const BROWSER_NUMBER = 4;
// 初始化函数
const init = async () => {
// 若 WSE_LIST 未定义则说明这是第一次运行插件
if (global.WSE_LIST) {
// 若 WSE_LIST 的长度大于等于四则说明初始化已在运行前完成
// 否则说明初始化仍在进行中
if (global.WSE_LIST.length >= BROWSER_NUMBER) {
// 直接返回无需等待
return;
} else {
// 返回 Promise 对象
return new Promise((resolve) => {
// 这个 Promise 直到收到 Init 事件才会 resolve
emitter.once('Init', resolve);
});
}
}
// 定义为数组
global.WSE_LIST = [];
while (WSE_LIST.length < BROWSER_NUMBER) {
const browser = await puppeteer.launch();
// 保存到 WSE_LIST 中
WSE_LIST.push(browser.wsEndpoint());
}
// 发送 Init 事件,通告初始化结束
emitter.emit('Init');
};
// 任务处理函数
const task = async (data) => {
// 随机从 WSE_LIST 中拿一个 browserWSEndpoint 出来
const browserWSEndpoint =
WSE_LIST[Math.floor(Math.random() * WSE_LIST.length)];
// 调用 connect 方法连接浏览器
const browser = await puppeteer.connect({browserWSEndpoint});
// 处理部分
};
module.exports = async () => {
const tasks = []; // 任务数据
// 一些处理,主要是填充 tasks 数组
await init(); // 初始化
await Promise.all(tasks.map((t) => task(t))); // 执行处理任务
return markdownAST;
};通过共用浏览器,成功解决问题二~
每个都有不用急
现在就剩问题一了,如何才能让一大堆“嗷嗷待哺”的任务排好队,一个一个运行呢?思路很简单!我可以像解决问题二时那样,写一个同步的 free 函数,当有空闲标签页时立即返回,否则等待“空闲”事件,不过这里的处理会稍微复杂一些:每个等待的任务组必须有一个独一无二的“空闲”事件的监听器,这样就不会一发送“空闲”事件后所有任务组全部执行。就像给群众分发物质一样,不能告诉他们:“等有物质了我就通知你”,否则你一喊:“有物质了!”,这些群众就都跑过来了,再次导致了情况的混乱;正确的处理方式是:给每个人一个号码牌,并跟他们说:”等叫到你的号码时就过来领取物质“,这样才能有秩序的给每个人都发配到物质。
有了思路,稍加些汗水就能得到以下代码(还是核心代码,仅作示例):
const BROWSER_NUMBER = 4;
// 设每个浏览器负责多少标签页
const PAGE_NUMBER_PER_BROWSER = 5;
// 初始化函数
const init = async () => {
if (global.WSE_LIST) {
if (global.WSE_LIST.length >= BROWSER_NUMBER) {
return;
} else {
return new Promise((resolve) => {
emitter.once('Init', resolve);
});
}
}
global.WSE_LIST = [];
global.PUPPETEER_PAGE_NUMBER = 0; // 记录当前页面数
global.LINK_BEAUTIFY_LINSTER = 0; // 等待的事件计数器
global.LINK_BEAUTIFY_CALLER = 0; // 调用的事件计数器
for (let i = 0; i < BROWSER_NUMBER; i++) {
const browser = await puppeteer.launch();
WSE_LIST[i] = browser.wsEndpoint();
}
emitter.emit('Init');
};
// 等待空闲标签页
const free = (tasksNum) => {
// 如果有空闲标签页,立即执行
if (
PUPPETEER_PAGE_NUMBER < PAGE_NUMBER_PER_BROWSER * WSE_LIST.length
) {
return;
}
// 否则等待“叫号”
return new Promise((resolve) => {
emitter.once(`free-${++LINK_BEAUTIFY_LINSTER}`, resolve);
});
};
// 任务处理函数
const task = async (data) => {
const browserWSEndpoint =
WSE_LIST[Math.floor(Math.random() * WSE_LIST.length)];
const browser = await puppeteer.connect({browserWSEndpoint});
// 标签页计数加一
PUPPETEER_PAGE_NUMBER++;
// 处理部分
// 如果有空闲标签页且有任务组等待则发送空闲事件
if (
PAGE_NUMBER_PER_BROWSER * WSE_LIST.length > --PUPPETEER_PAGE_NUMBER &&
LINK_BEAUTIFY_LINSTER > LINK_BEAUTIFY_CALLER
) {
emitter.emit(`free-${++LINK_BEAUTIFY_CALLER}`);
}
};
module.exports = async () => {
const tasks = []; // 任务数据
// 一些处理,主要是填充 tasks 数组
await init(); // 初始化
await free(); // 等待空闲标签页
await Promise.all(tasks.map((t) => task(t))); // 执行处理任务
return markdownAST;
};好了,这下两大问题就都解决了,接下来我可能会考虑润色一下代码后再发布 2.0.0 版本,希望一切顺利。好久没有写过这么长的文章了,如果大家有什么意见或建议,欢迎留言。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK