

DanceNN:字节自研千亿级规模文件元数据存储系统概述
source link: https://developer.51cto.com/article/707020.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

作者 | 黄冬发
在一个典型的分布式文件系统中,目录文件元数据操作(包括创建目录或文件,重命名,修改权限等)在整个文件系统操作中占很大比例,因此元数据服务在整个文件系统中扮演着重要的角色,随着大规模机器学习、大数据分析和企业级数据湖等应用,分布式文件系统数据规模已经从 PB 级到 EB 级,当前多数分布式文件系统(如 HDFS 等)面临着元数据扩展性的挑战。
以 Google、Facebook 和 Microsoft 等为代表的公司基本实现了能够管理 EB 级数据规模的分布式文件系统,这些系统的共同架构特征是依赖于底层分布式数据库能力来实现元数据性能的水平扩展,如 Google Colossus 基于 BigTable,Facebook 基于 ZippyDB,Microsoft ADLSv2 基于 Table Storage,还有一些开源文件系统包括 CephFS 和 HopsFS 等也基本实现了水平扩展的能力。
这些文件系统实现由于对底层分布式数据库的依赖,对文件系统的语义支持程度也各有不同,如大多数基于分布式文件系统的计算分析框架依赖底层目录原子 Rename 操作来提供数据的原子更新,而 Tectonic 和 Colossus 因为底层数据库不支持跨分区事务所以不保证跨目录 Rename 的原子性,而 ADLSv2 支持对任意目录的原子 Rename。
DanceNN 是公司自研的一个目录树元信息存储系统,致力于解决所有分布式存储系统的目录树需求(包括不限于 HDFS,NAS 等),极大简化上层存储系统依赖的目录树操作复杂性,包括不限于原子 Rename、递归删除等。解决超大规模目录树存储场景下的扩展性、性能、异构系统间的全局统一命名空间等问题,打造全球领先的通用分布式目录树服务。
当前 DanceNN 已经为公司在线 ByteNAS,离线 HDFS 两大分布式文件系统提供目录树元数据服务。
(本篇主要介绍在离线大数据场景 HDFS 文件系统下 DanceNN 的应用,考虑篇幅,DanceNN 在 ByteNAS 的应用会在后续系列文章介绍,敬请期待)
元数据演进
字节 HDFS 元数据系统分三个阶段演进:

NameNode
最开始公司使用 HDFS 原生 NameNode,虽然进行了大量优化,依然面临下列问题:
- 元数据(包括目录树,文件和 Block 副本等)全内存存储,单机承载能力有限
- 基于 Java 语言实现,在大内存场景 GC 停顿时间比较长,严重影响 SLA
- 使用全局一把读写锁,读写吞吐性能较差
- 随着集群数据规模增加,重启恢复时间达到小时级别
DanceNN v1
DanceNN v1 的设计目标是为了解决上述 NameNode 遇到的问题。
主要设计点包括:
- 重新实现 HDFS 协议层,将目录树文件相关元数据存储到 RocksDB 存储引擎,提供 10 倍元数据承载
- 使用 C++ 实现,避免 GC 问题,同时使用高效数据结构组织内存 Block 信息,减少内存使用
- 实现一套细粒度目录锁机制,极大提升不同目录文件操作间的并发
- 请求路径全异步化,支持请求优先级处理
- 重点优化块汇报和重启加载流程,降低不可用时间
DanceNNv1 最终在 2019 年完成全量上线,线上效果基本达到设计目标。
下面是一个十几亿文件数规模集群,切换后大致性能对比:

DanceNN v1 开发中遇到很多技术挑战,如为了保证上线过程对业务无感知,支持现有多种 HDFS 客户端访问,后端需要完全兼容原有的 Hadoop HDFS 协议。
Distributed DanceNN
一直以来 HDFS 都是使用 Federation 方式来管理目录树,将全局 Namespace 按 path 映射到多组元数据独立的 DanceNN v1 集群,单组 DanceNN v1 集群有单机瓶颈,能处理的吞吐和容量有限,随着公司业务数据的增长,单组 DanceNN v1 集群达到性能极限,就需要在两个集群之间频繁迁移数据,为了保证数据一致性需要在迁移过程中上层业务停写,对业务影响比较大,并且当数据量大的情况下迁移比较慢,这些问题给整个系统带来非常大的运维压力,降低服务的稳定性。
Distributed 版本主要设计目标:
- 通用目录树服务,支持多协议包括 HDFS,POSIX 等
- 单一全局 Namespace
- 容量、吞吐支持水平扩展
- 高可用,故障恢复时间在秒级内
- 包括跨目录 Rename 等写操作支持事务
- 高性能,基于 C++ 实现,依赖 Brpc 等高性能框架
Distributed DanceNN 目前已经在 HDFS 部分集群上线,正在进行存量集群的平滑迁移。
文件系统概览
最新 HDFS 分布式文件系统实现采用分层架构,主要包括三层:
数据层:用于存储文件内容, 处理 Block 级别的 IO 请求
- 由 DataNode 节点提供服务
Namespace 层:负责目录树相关元数据,处理目录和文件创建、删除、Rename 和鉴权等请求
- 由 Distributed DanceNN 集群提供服务
文件块层:负责文件相关的元数据、文件与 Block 的映射以及 Block 副本位置信息,处理文件创建删除,文件 Block 的添加等请求
- 一个 BSGroup 负责管理集群部分文件块元数据,由多台的 DanceBS 组成提供高可用服务
- 通过 BSGroup 动态扩容来适应集群负载,当某个 BSGroup 快达到性能极限后可以控制写入
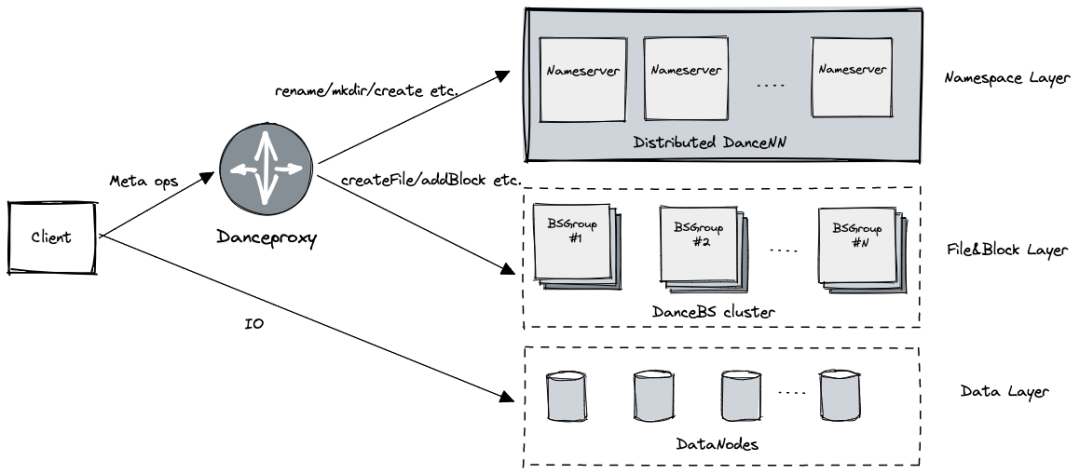
DanceProxy
C++ 实现,基于高性能框架 Brpc 实现了 Hadoop RPC 协议,支持高吞吐,无缝对接现有 HDFS Client。
主要负责对 HDFS Client 请求的解析,拆分处理后,将 Namespace 相关的请求发送到 DanceNN 集群,文件块相关的请求路由到对应的 BSGroup 处理,当所有后端请求回复后生成最终客户端的响应。
DanceProxy 通过一定的请求路由策略来实现多组 BSGroup 负载均衡。
DanceNN 接口
Distributed DanceNN 为文件系统提供主要接口如下:
class DanceNNClient {
public:
DanceNNClient() = default;
virtual ~DanceNNClient() = default;
// ...
// Create directories recursively, eg: MkDir /home/tiger.
ErrorCode MkDir(const MkDirReq& req);
// Delete a directory, eg: RmDir /home/tiger.
ErrorCode RmDir(const RmDirReq& req);
// Change the name or location of a file or directory,
// eg: Rename /tmp/foobar.txt /home/tiger/foobar.txt.
ErrorCode Rename(const RenameReq& req);
// Create a file, eg: Create /tmp/foobar.txt.
ErrorCode Create(const CreateReq& req, CreateRsp* rsp);
// Delete a file, eg: Unlink /tmp/foobar.txt.
ErrorCode Unlink(const UnlinkReq& req, UnlinkRsp* rsp);
// Summarize a file or directory, eg: Du /home/tiger.
ErrorCode Du(const DuReq& req, DuRsp* rsp);
// Get status of a file or directory, eg: Stat /home/tiger/foobar.txt.
ErrorCode Stat(const StatReq& req, StatRsp* rsp);
// List directory contents, eg: Ls /home/tiger.
ErrorCode Ls(const LsReq& req, LsRsp* rsp);
// Create a symbolic link named link_path which contains the string target.
// eg: Symlink /home/foo.txt /home/bar.txt
ErrorCode Symlink(const SymlinkReq& req);
// Read value of a symbolic link.
ErrorCode ReadLink(const ReadLinkReq& req, ReadLinkRsp* rsp);
// Change permissions of a file or directory.
ErrorCode ChMod(const ChModReq& req);
// Change ownership of a file or directory.
ErrorCode ChOwn(const ChOwnReq& req);
// Change file last access and modification times.
ErrorCode UTimeNs(const UTimeNsReq& req, UTimeNsRsp* rsp);
// Set an extended attribute value.
ErrorCode SetXAttr(const SetXAttrReq& req, SetXAttrRsp* rsp);
// List extended attribute names.
ErrorCode GetXAttrs(const GetXAttrsReq& req, GetXAttrsRsp* rsp);
// remove an extended attribute.
ErrorCode RemoveXAttr(const RemoveXAttrReq& req,
RemoveXAttrRsp* rsp);
// ...
};DanceNN 架构
Distributed DanceNN 基于底层分布式事务 KV 存储来构建,实现容量和吞吐水平扩展,主要功能:
- HDFS 等协议层的高效实现
- 服务无状态化,支持高可用
- 服务节点的快速扩缩容
- 提供高性能低延迟的访问
- 对 Namespace 进行子树划分,充分利用子树 Cache Locality
- 集群根据负载均衡策略对子树进行调度
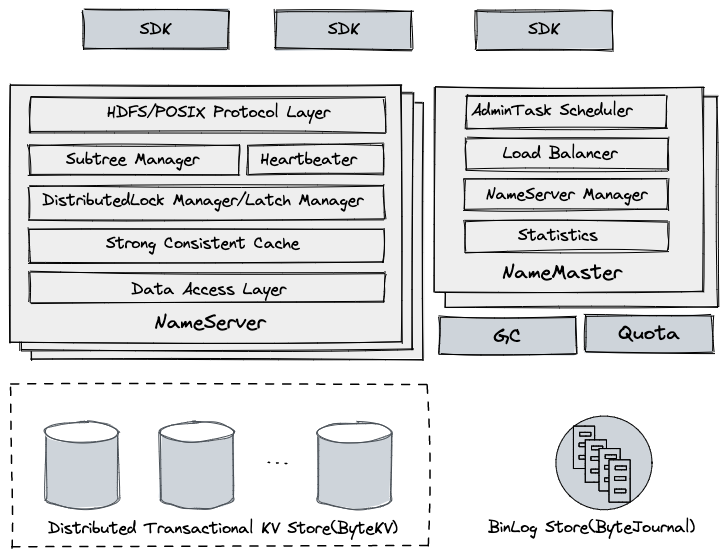
SDK
缓存集群子树、NameServer 位置等信息,解析用户请求并路由到后端服务节点上,如果服务节点响应请求不合法,可能强制 SDK 刷新相应的集群缓存。
NameServer
- 作为服务节点,无状态,支持横向扩展
- HDFS/POSIX Protocol Layer:处理客户端请求,实现了 HDFS 等协议层语义,包括路径解析,权限校验,删除进入回收站等
- Subtree Manager:管理分配给当前节点的子树,负责用户请求检查,子树迁移处理等
- Heartbeater:进程启动后会自动注册到集群,定期向 NameMaster 更新心跳和负载信息等
- DistributedLock Manager:基于 LockTable,对跨目录 Rename 请求进行并发控制
- Latch Manager:对所有路径读写请求进行加锁处理,降低底层事务冲突,支持 Cache 的并发访问
- Strong Consistent Cache:维护了当前节点子树的 dentry 和 inode 强一致 Cache
- Data Acess Layer:对底层 KV 存储的访问接口的抽象,上层读写操作都会映射到底层 KV 存储请求
NameMaster
- 作为管理节点,无状态,多台,通过选主实现,由主节点提供服务
- AdminTask Scheduler:后台管理相关任务调度执行,包括子树切分,扩容等
- Load Balancer:根据集群 NameServer 负载状态,通过自动子树迁移来完成负载均衡
- NameServer Manager:监控 NameServer 健康状态,进行相应的宕机处理
- Statistics:通过消费集群变更日志,实时收集统计信息并展示
Distributed Transactional KV Store
- 数据存储层,使用自研的强一致 KV 存储系统 ByteKV
- 提供水平伸缩能力
- 支持分布式事务,提供 Snapshot 隔离级别
- 支持多机房数据灾备
BinLog Store
BinLog 存储,使用自研的低延迟分布式日志系统 ByteJournal,支持 Exactly Once 语义
从底层 KV 存储系统中实时抽取数据变更日志,主要用于 PITR 和其他组件的实时消费等
GC(Garbage collector)
从 BinLog Store 实时消费变更日志,读到文件删除记录后,向文件块服务下发删除命令,及时清理用户数据
Quota
对用户认领的目录,会周期性全量、实时增量的统计文件总数和空间总量,容量超限后限制用户写
一般基于分布式存储的元数据格式有两种方案:
方案一类似 Google Colossus,以全路径作为 key,元数据作为 value 存储,优点有:
- 路径解析非常高效,直接通过用户请求的 path 从底层的 KV 存储读取对应 inode 的元数据即可
- 扫描目录可以通过前缀对 KV 存储进行扫描
但是有下列缺点:
- 跨目录 Rename 代价大,需要对目录下的所有文件和目录进行移动
- Key 占用的空间相对比较大
另外一种类似 Facebook Tectonic 和开源的 HopsFS,以父目录 inode id + 目录或文件名作为 key,元数据作为 value 存储,这种优点有:
跨目录 Rename 非常轻量,只需要修改源和目标节点以及它们的父节点
扫描目录同样可以用父目录 inode id 作为前缀进行扫描
缺点有:
路径解析网络延迟高,需要从 Root 依次递归读取相关节点元数据直到目标节点
例如:MkDir /tmp/foo/bar.txt,有四次元数据网络访问:/、/tmp、/tmp/foo 和 /tmp/foo/bar.txt
层级越小,访问热点越明显,从而导致底层存储负载严重不均衡
例如:每个请求都要读取一次根目录/的元数据
考虑到跨目录 Rename 请求在线上集群占比较高的比例,并且对于大目录 Rename 延迟不可控,DanceNN 主要采用第二种方案,方案二的两个缺点通过下面的子树分区来解决。
DanceNN 通过将全局 Namespace 进行子树分区,子树被指定一个 NameServer 实例维护子树缓存。
- 维护这个子树下所有目录和文件元数据的强一致缓存
- 缓存项有一定淘汰策略包括 LRU,TTL 等
- 所有请求路径在这个子树下的可以直接访问本地缓存,未命中需要从底层 KV 存储进行加载并填充缓存
- 通过对缓存项添加版本的方法来指定某个目录下所有元数据的缓存过期,有利于子树快速迁移清理
利用子树本地缓存,路径解析和读请求基本能够命中缓存,降低整体延迟,也避免了靠近根节点访问的热点问题。
在子树迁移、跨子树 Rename 等操作过程中,为了避免请求读取过期的子树缓存,需要将相关的路径进行冻结,冻结期间该路径下的所有操作会被阻塞,由 SDK 负责重试,整个流程在亚秒级内完成
路径冻结后会将该目录下的所有缓存项设置为过期
冻结的路径信息会被持久化到底层的 KV 存储,重启后会重新加载刷新
子树管理主要由 NameMaster 负责:
- 支持通过管理员命令进行手动子树分裂和子树迁移
- 定期监控集群节点的负载状态,动态调整子树在集群分布
- 定期统计子树的访问吞吐,提供子树分裂建议,未来支持启发式算法选择子树完成分裂
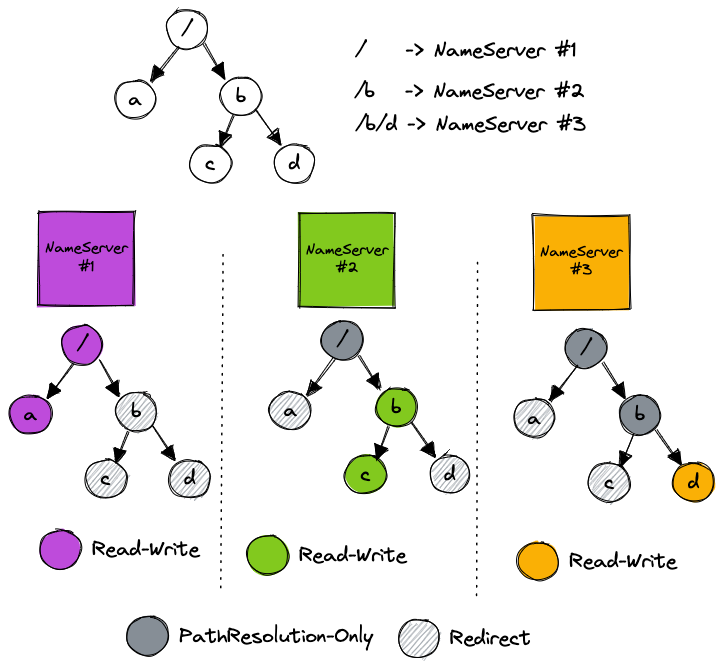
举个例子,如下图:
目录 / 调度到 NameServer #1,目录 /b 调度到 NameServer #2,目录 /b/d 调度到 NameServer #3
- MkDir /a 请求发送到 NameServer #1,发送到其他 NameServer 会校验失败,返回重定向错误,让 SDK 刷新缓存重试
- Stat /b/d 请求将会发送到 NameServer #3,直接读取本地缓存即可
- ChMod /b 请求将会发送到 NameServer #2,更新 b 目录的权限信息并持久化,对 NameServer #2 和 NameServer #3 进行 Cache 刷新,最后回复客户端
底层 KV 存储系统 ByteKV 支持单条记录的 Put、Delete 和 Get 语义,其中 Put 支持 CAS 语义,还提供多条记录的原子性写入接口 WriteBatch。
客户端写操作一般会涉及多个文件或目录的更新,例如 Create /tmp/foobar.txt 会更新 /tmp 的 mtime 记录、创建 foobar.txt 记录等,DanceNN 会将多条记录的更新转换成 ByteKV WriteBatch 请求,保证了整个操作的原子性。
分布式锁管理
虽然 ByteKV 提供事务的 ACID 属性且支持 Snapshot 隔离级别,但是对于多个并发写操作如果涉及底层数据变更之间没有 Overlap 的话,仍然会有 Write Skew 异常,这可能导致元数据完整性被破坏。
其中一个例子是并发 Rename 异常,如下图:
单个 Rename /a /b/d/e 操作或者单个 Rename /b/d /a/c 操作都符合预期,但是如果两者并发执行(且都能成功),可以导致目录 a,c,d,e 的元数据出现环,破坏了目录树结构的完整性。

我们选择使用分布式锁机制来解决,对于可能导致异常的并发请求进行串行处理,基于底层 KV 存储设计了 Lock Table,支持对于元数据记录进行加锁,提供持久性、水平扩展、读写锁、锁超时清理和幂等功能。
Latch 管理
为了支持对子树内部缓存的并发访问和更新,维护缓存的强一致,会对操作涉及的缓存项进行加锁(Latch),例如:Create /home/tiger/foobar.txt,会先对 tiger 和 foobar.txt 对应的缓存项加写 Latch,再进行更新操作;Stat /home/tiger 会对 tiger 缓存项加读 Latch,再进行读取。
为了提升服务的整体性能做了非常多的优化,下面列两个重要优化:
热点目录下大量创建和删除文件
例如:有些业务像大型 MapReduce 任务会在相同目录一下子创建几千个目录或文件。
一般来说根据文件系统语义创建文件或目录都会更新父目录相关的元数据(如 HDFS 协议更新父目录的 mtime,POSIX 要求更新父目录 mtime,nlink 等),这就导致同目录下创建文件操作对父目录元数据的更新产生严重的事务冲突,另外底层 KV 存储系统是多机房部署,机房延迟更高,进一步降低了这些操作的并发度。
DanceNN 对于热点目录下的创建删除等操作只加读 latch,之后放到一个 ExecutionQueue 中, 由一个的轻量 Bthread 协程进行后台异步串行处理,将这些请求组合成一定大小的 Batch 发送给底层的 KV 存储,这样避免了底层事务冲突,提升几十倍吞吐。
请求间的相互阻塞
有些场景可能会导致目录的更新请求阻塞了这个目录下的其他请求,例如:
SetXAttr /home/tiger 和 Stat /home/tiger/foobar.txt 无法并发执行,因为第一个对 tiger 缓存项加写 Latch,后面请求读 tiger 元数据缓存项会被阻塞。
DanceNN 使用类似 Read-Write-Commit Lock 实现对 Latch 进行管理,每个 Latch 有 Read、Write 和 Commit 三种类型,其中 Read-Read、Read-Write 请求可以并发,Write-Write、Any-Commit 请求互斥。
基于这种实现,上述两个请求能够在保证数据一致性的情况下并发执行。
当客户端因为超时或网络故障而失败时,进行重试会导致同一个请求到达 Server 多次。有些请求如 Create 或者 Unlink 是非幂等的请求,对于这样的操作,需要在 Server 端识别以保证只处理一次。
在单机场景中,我们通常使用一个内存的 Hash 表来处理重试请求,Hash 表的 key 为 {ClientId, CallId},value 为 {State, Response},当请求 A 到来之后,我们会插入 {Inprocess State} 到 Hash 表;这之后,如果重试请求 B 到来,会直接阻塞住请求 B,等待第请求 A 执行成功后唤醒 B。当 A 执行成功之后,我们会将 {Finished State, Response} 写到 Hash 表并唤醒 B,B 会看到更新的 Finished 状态后响应客户端。
类似的 DanceNN 写请求会在底层的 WriteBatch 请求里加一条 Request 记录,这样可以保证后续的重试请求操作一定会在底层出现事务 CAS 失败,上层发现后会读取该 Request 记录直接响应客户端。另外,何时删除 Request 记录呢,我们会给记录设置一个相对较长时间的 TTL,可以保证该记录在 TTL 结束之后一定已经处理完成了。
压测环境:
DanceNN 使用 1 台 NameServer,分布式 KV 存储系统使用 100+台数据节点,三机房五副本部署(2 + 2 + 1),跨机房延迟 2-3ms 左右,客户端通过 NNThroughputBenchmark 元数据压测脚本分别使用单线程和 6K 线程并发进行压测。
截取部分延迟和吞吐数据如下:
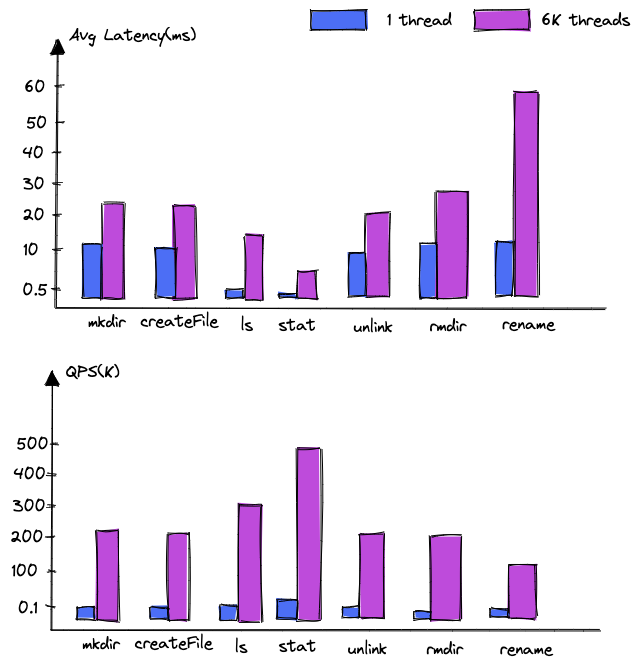
测试结果表明:
- 读吞吐:单台 NameServer 支持读请求 500K,随着 NameServer 数量的增加吞吐基本能够线性增长;
- 写吞吐:目前依赖底层 KV 存储的写事务性能,随着底层 KV 节点数据量的增加也能够实现线性增长。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK