

随机变量:常见的离散型、连续型随机变量有哪些特点?
source link: http://www.woshipm.com/data-analysis/5391963.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

编辑导语:“随机变量”是我们经常会听到的一个词,但它具体是什么,它有什么样的特点?这篇文章为我们仔细讲解了“随机变量”的相关知识,一起学习一下吧。

很久没有分享一些基础的理论知识相关的文章了。一方面这种文章大家阅读意愿低,比较难和实践结合,没那么多合适的案例分享;另一方面也是不好写,各种数学公式和符号,电脑编辑起来真的是异常艰难。
所以写完了统计学相关的系列后,就迟迟没动笔写新的。不过对于我们数据从业人员来讲,概率、代数、统计、算法等相关的知识,还是要尽可能扎实掌握的。(统计学系列传送:《统计学基础》、《抽样分布》、《参数估计》、《区间估计》、《假设检验》)
今天和大家唠唠概率论中很重要的基础内容:随机变量的一些基础概念,主要是离散型和连续型的区别,以及各自的分布函数。
一、随机变量的基础概念
先聊聊一些基础的概念。
1. 随机变量
设随机试验的样本空间为S={e},X=X(e)是定义在样本空间上的实值单值函数,则称X为随机变量。一般以大写字母X,Y,Z等表示随机变量。
关于定义,理解就好。
说白了,我们就是把真实的随机事件抽象出来,用随机变量来表示,进行数字化、抽象化,便于分析。
随机变量分为两类:离散型和非离散型。
离散型:若随机变量X只能取到有限个或者可列个不同值,则称X为离散型随机变量。比如抽一张纸牌,一共54张,把这个事件转化成随机变量,这个随机变量的取值最多54个,是有限的。这就是离散型随机变量。
非离散型:与离散型相对地,非离散型随机变量指随机变量有不可列个不同取值的随机变量。比如人的身高,可以从0厘米到300厘米任取,是无限个取值,因此是非离散型的。
非离散型随机变量中,有一类特殊的,也是我们主要关注的类型:连续型随机变量。连续型和非离散型并不等同,这点需要注意。
2. 概率分布列与密度函数
对于离散型随机变量而言,我们用概率分布列描述概率分布;而对于连续型随机变量,我们用概率密度函数来描述。
以下是离散型随机变量概率分布列的示意图:
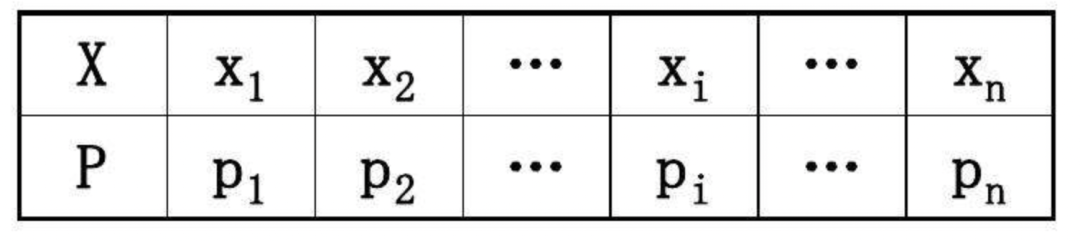
可以看出来,随机变量X的有限可列个的,因此可以用上面的表格表示不同X取值时,具体的概率值。
连续型随机变量密度函数示意图如下:
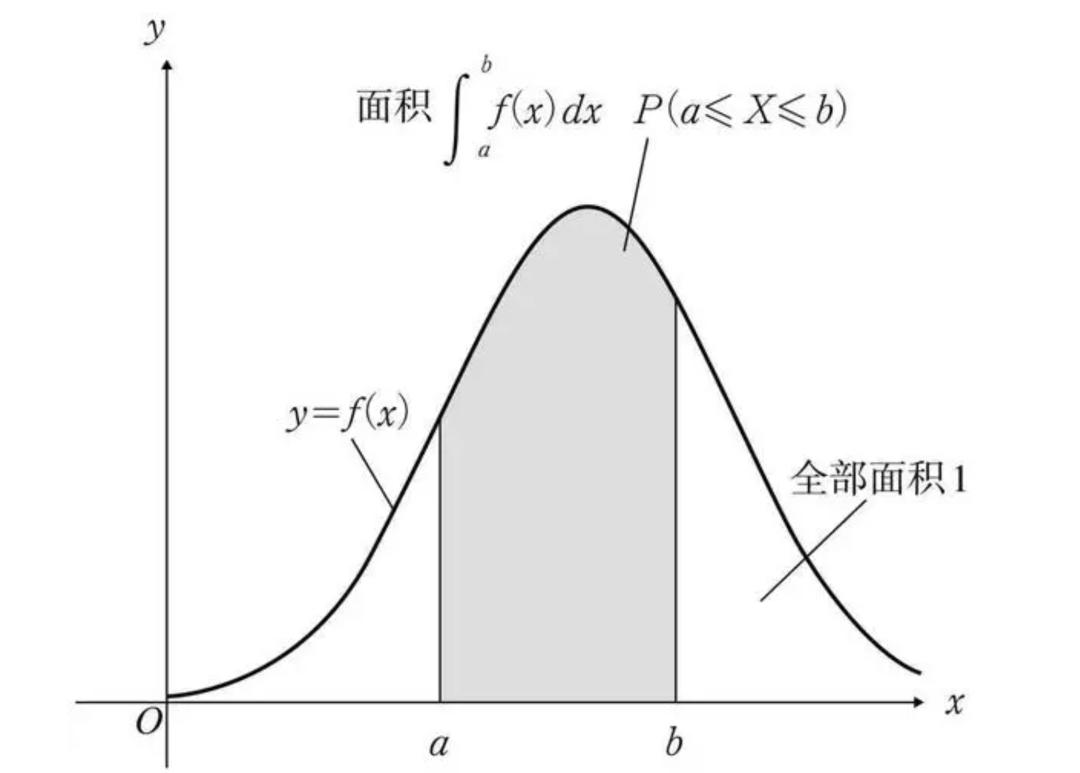
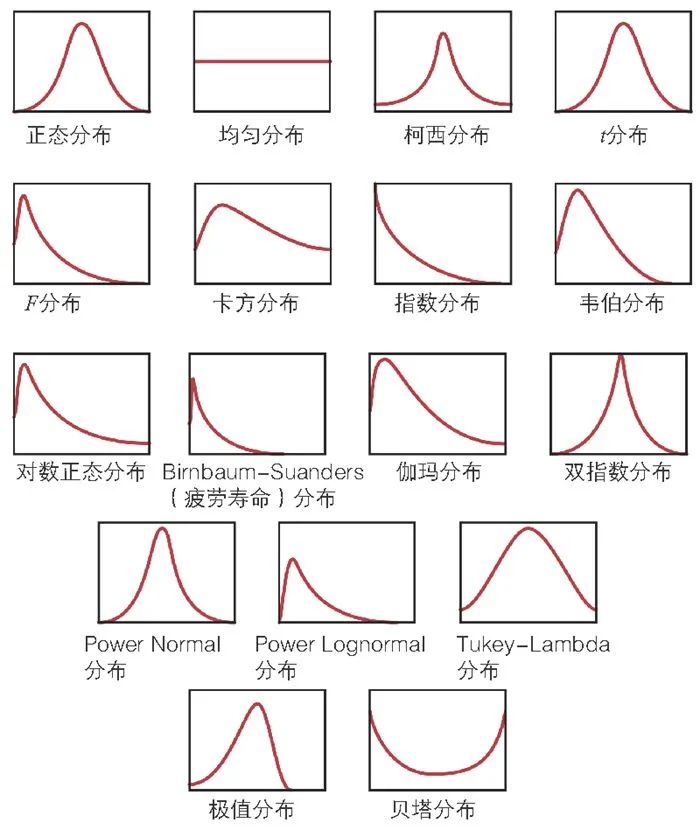
下面是常见的连续型函数的概率密度示意:
另外,关于连续型随机变量的概率密度函数还有个性质:
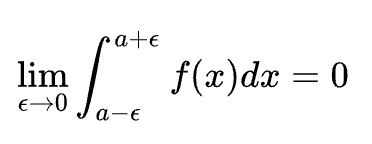
这告诉我们对连续型随机变量,其在任意单点处取值的概率为0。这点很重要。因此也可以得到推论:
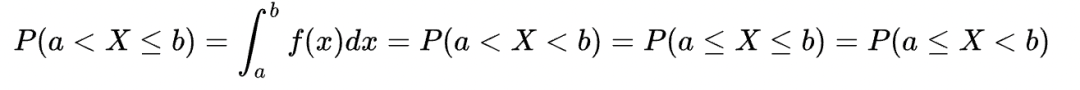
即在端点上是否取到,不影响整体区间的概率。
最后,无论是概率分布列还是密度函数,概率之和(或者面积)都等于1。这是概率的基础定义。
3. 分布函数
X是随机变量,则函数F(x)=P(X<x)成为X的概率分布函数,简称分布函数。
对于离散型随机变量,假设P(X=xk)=pk,则分布函数为:

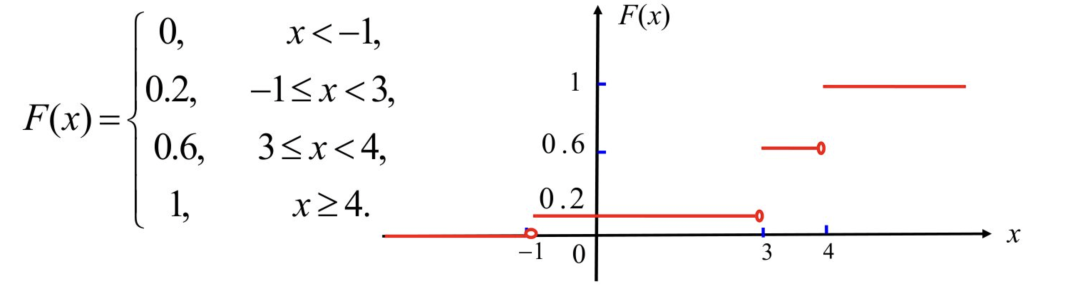
此时分布函数为阶梯函数且单调递增。且函数值的跳跃发生在所有xk处,跳跃的幅度为pk。举个例子,随机变量X的概率分布列:

根据定义,可以推导出分布函数为:
对于连续型随机变量,假设密度函数为f(x),则分布函数为不定积分:
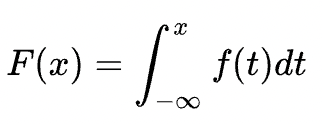
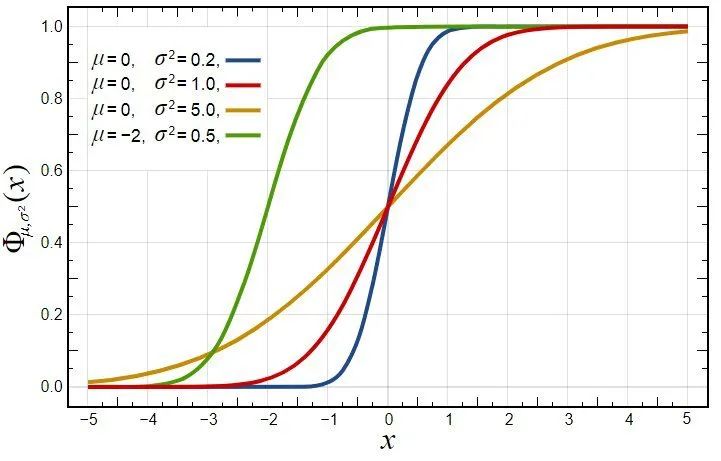
与离散的情况类似地,分布函数仍旧具有单调递增的性质,因为f(x)是概率,一定有f(x)>=0.给个正态分布的分布函数示例:
另外,还有性质:

不再展开赘述。
二、离散型随机变量
下面介绍几个常见常用的离散型随机变量的一些特点。
1. 0-1分布:B(1,p)
定义:X的值为一个随机事件的发生与否(发生是1,不发生是0),这个事件发生的概率为p。则X服从参数为1,p的0-1分布,记作X~B(1,p)。其实就是伯努利分布。
概率分布:
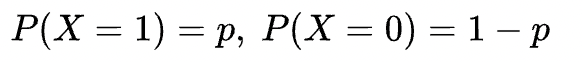
这个比较简单,容易理解,不展开了。本质上是下面的二项分布的取n=1的情况。
2. 二项分布:B(n,p)
定义:X为n次独立重复随机事件中发生的事件数。这个事件每次发生的概率都是p。则X~B(n,p)
概率分布:
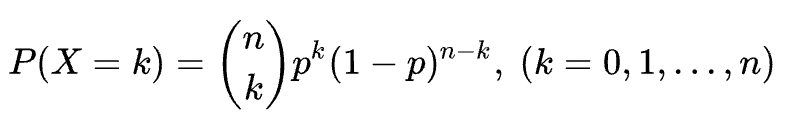
二项分布的不同参数下的分布函数如下:
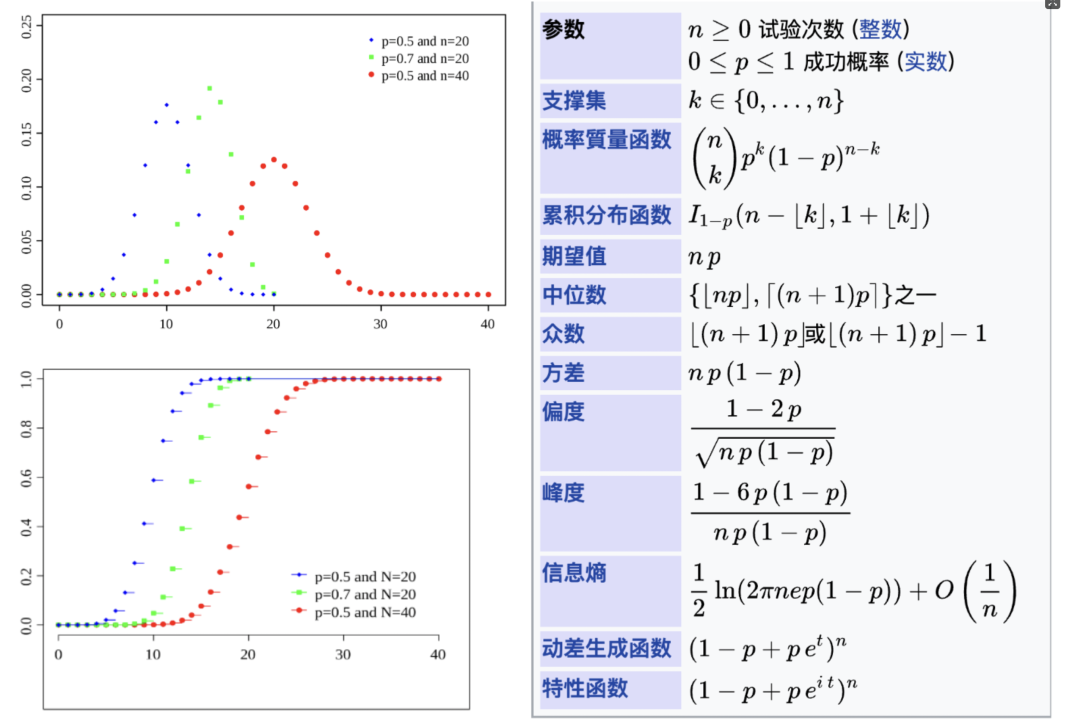
3. 泊松分布:P(λ)
定义:X为某个随机事件发生的次数,假设每次事件发生与否相互独立,且平均事件发生λ次,则X~P(λ)
概率分布:
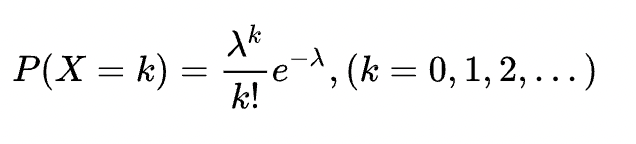
泊松分布不同参数下的分布函数如下:
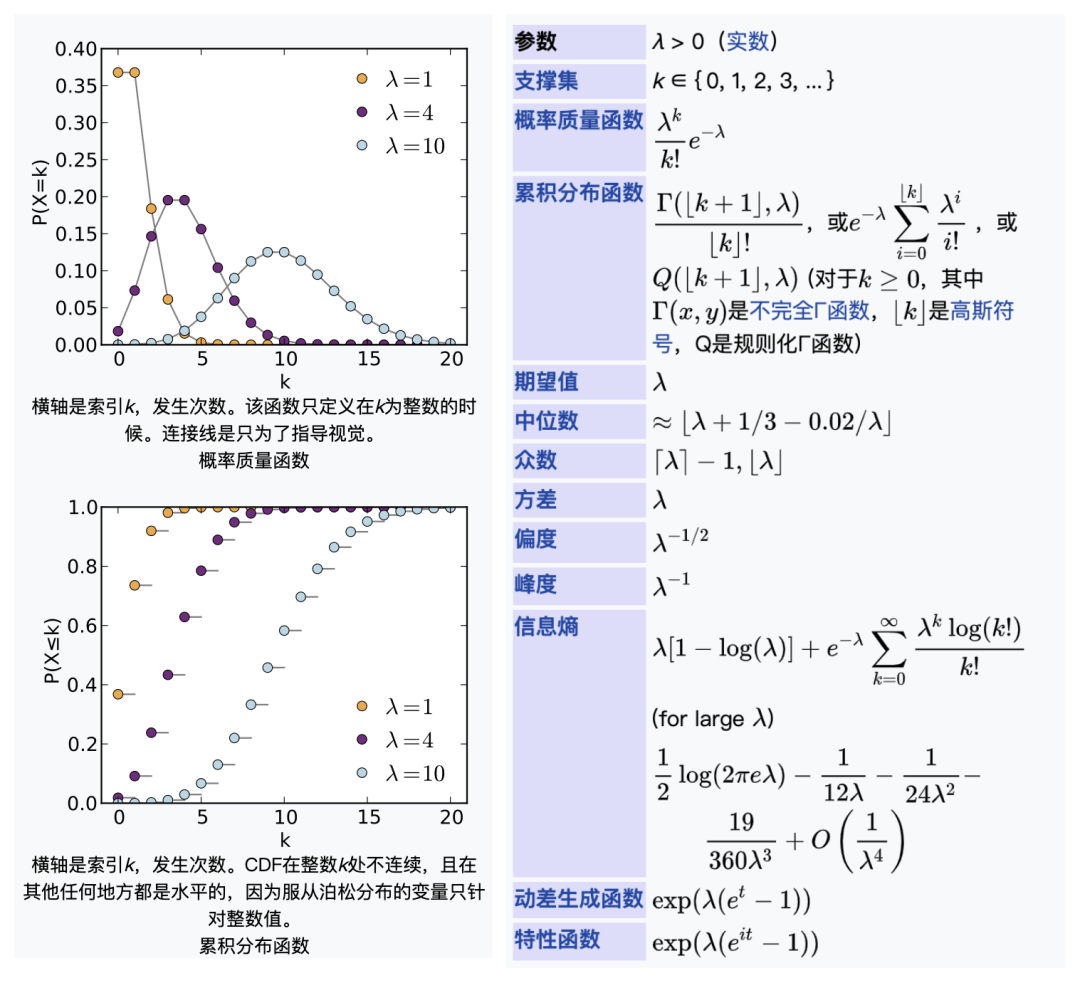
这里重点关注泊松分布的平均发生次数(即期望值)=λ,而且后面我们将知道,泊松分布的方差也是λ。
4. 几何分布:G(p)
定义:重复进行随机事件,直到事件发生为止才停下。X为首次发生时共做的事件的次数。每次发生的概率均为p,则X~G(p)
概率分布:
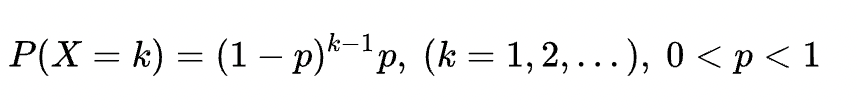
这里重点注意X的取值最小是从1开始,而不是0,根据定义可以得出。
三、连续型随机变量
第一部分的连续型随机变量小图,给出了很多连续型随机变量的示意图。下面我们针对几个常见、常用的连续型随机变量,进行详细阐述。
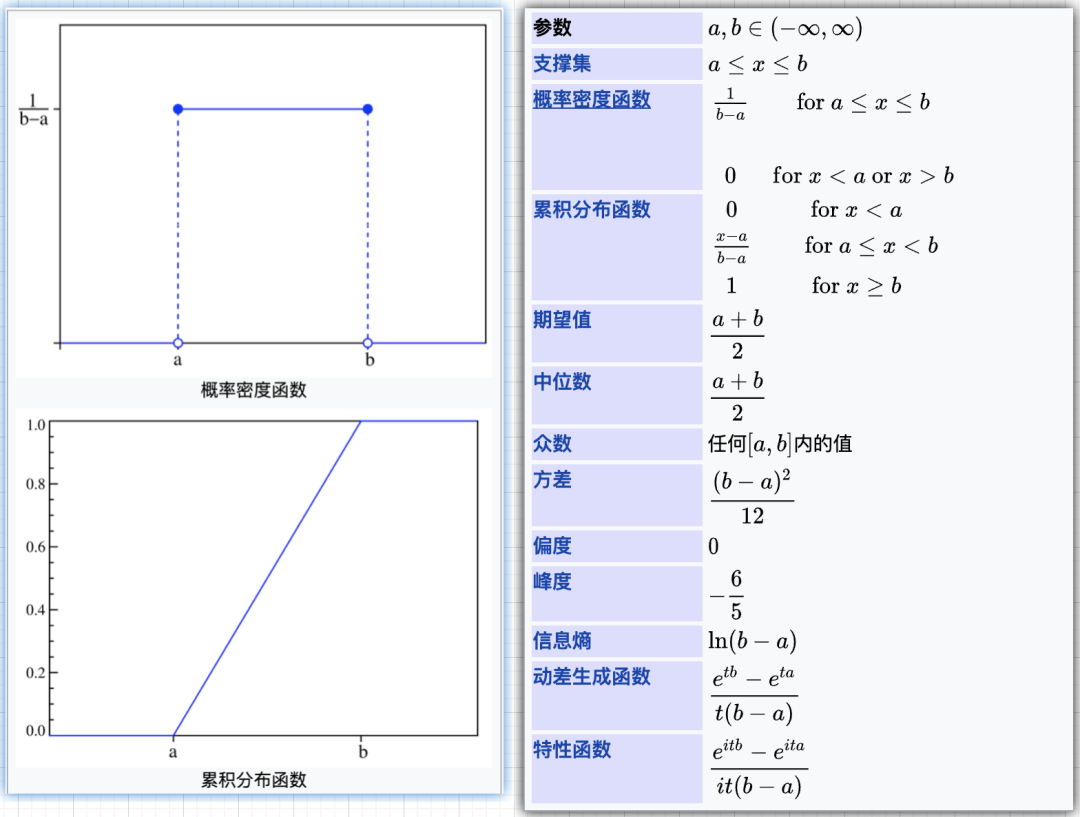
1. 均匀分布:U(a,b)
定义:a<b,若密度函数满足以下,则X~U(a,b)

容易理解地,均匀分布的密度在非零处均为常值,并且保证了在R上的积分是1。
分布函数为:
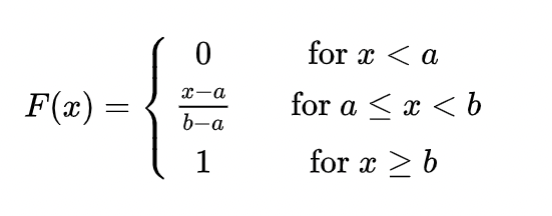
2. 指数分布:E(λ)
定义:λ>0,若密度函数满足以下,则X~E(λ)
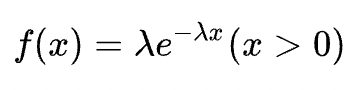
指数分布可以用来表示独立随机事件发生的时间间隔,比如旅客进入机场的时间间隔、打进客服中心电话的时间间隔、中文维基百科新条目出现的时间间隔等等。因此取值时大于0的。
分布函数为:
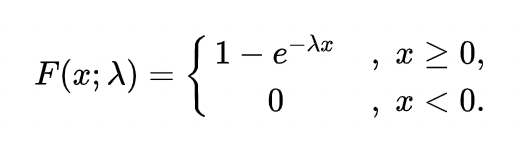

3. 正态分布:N(μ,σ2)
定义:σ>0,若密度函数满足以下,则X~N(μ,σ2)
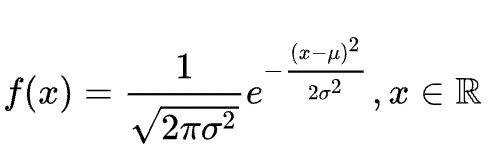
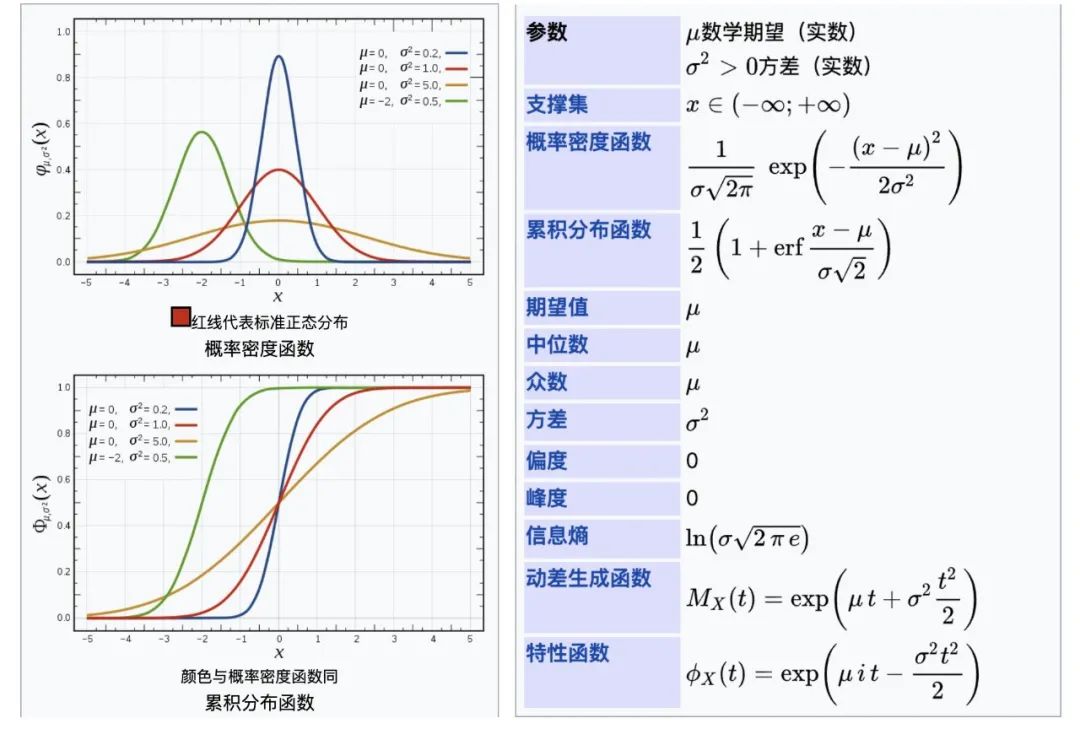
特别的,N(0,1)被称为标准正态分布,是我们最常用的分布之一。
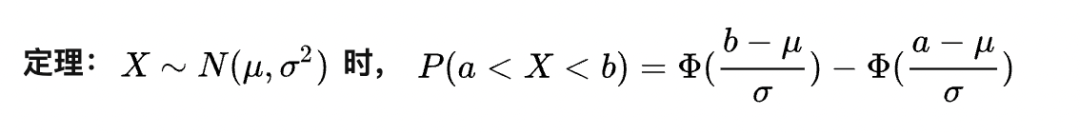
这样的做法的意义在于将求正态分布概率的过程统一化了。我们现在只需要能求出标准正态分布的概率即可求出所有不同正态分布的概率。
关于随机变量,我们今天只能先介绍这些了,希望大家能有所收获。
#专栏作家#
NK冬至,公众号:首席数据科学家,人人都是产品经理专栏作家。在金融领域、电商领域有丰富数据及产品经验。擅长数据分析、数据产品等相关内容。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于CC0协议。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK