

深入理解LINUX内核
source link: https://mengtnt.com/2022/03/16/readlinux.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
深入理解LINUX内核
03月 16日, 2022 1 minute read最近在读《深入理解LINUX内核》这本书让我想起来大学时代的《深入理解计算机系统》、《编译原理》、《操作系统》这几本红宝书。这种类型的书,由于设计的技术细节过于庞大,所以想读一遍了解其中的原理不太可能,在我看来读这种类型的书,一遍最多也就能理解其中10%的内容。现在已经工作了10多年,重新看了下看能不能再多懂10%。
言归正传,本篇博客自己想记录下对书中一些原理的理解,感受下Linux系统的巧妙之处。再来可以借鉴下Linux很多的设计思想,也可以应用到平时工作中业务逻辑的设计。当然博客篇幅有限,仅仅记录下操作系统核心业务的某些思想以供借鉴。
说到操作系统核心业务,主要是进程和内存管理,本质是就是管理cpu和存储系统。所以下面的几点内容都是从进程和内存管理的章节中选取的知识点。
假如没有操作系统,程序如何操作内存呢?那就要管理每一个内存地址的读取和存储了,对于不同的硬件内存排布都各不相同,所以使用不同的硬件就要写一套不同的内存管理方法。操作系统本质上就是对内存这个硬件增加了一个抽象,上层程序只需要使用虚拟地址来访问就可以,底层如何分配物理地址交给操作系统来做。
由于操作系统抽象了一层虚拟内存,用户程序仅仅操作虚拟地址,那么虚拟地址如何转换成物理地址呢?这里就要从程序装载的过程说起了。如果程序不是运行在虚拟机上,本质上操作系统装载的都是机器码。写过汇编代码的都知道,在定义程序代码时,需要定义代码段(CS)、数据段(DS)、堆栈段(SS),并且代码里面写的 mov 0x8049509 exa 这里的地址都是逻辑地址。操作系统通过程序段定义段的逻辑地址,再转换出程序所需要的虚拟地址。可以看下图所示。
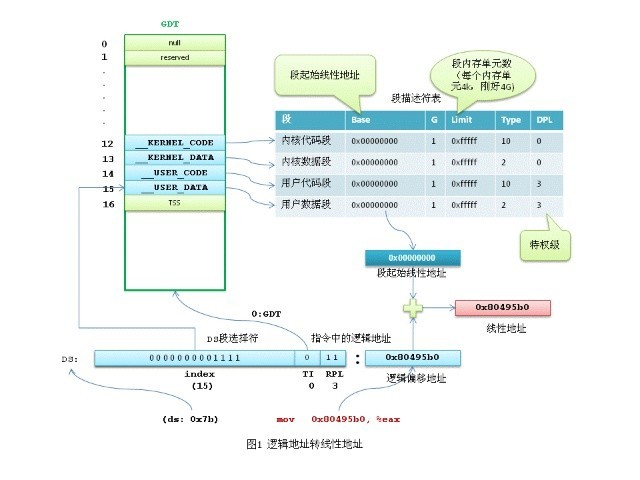
上图中最终的线性地址就是平时我们说的虚拟地址。其实Linux中逻辑地址等于虚拟地址。因为Linux所有的段(用户代码段、用户数据段、内核代码段、内核数据段)的线性地址都是从 0x00000000 开始,线性地址=0x00000000+逻辑地址(偏移量),也就是说逻辑地址等于虚拟地址了。像Windows系统就会在加载程序时,会有逻辑地址转换虚拟地址的过程。Linux舍弃这一步的目的是为了高效,这样Linux就可以直接把所有的逻辑地址映射到我们下面要说的页表中了。
在写汇编代码时,会发现程序中所有操作的内存都是连续的,这样很方便我们管理内存的读取。那操作系统如何把程序中所有连续的虚拟地址,映射到物理地址中。这个过程就需要用到页表。页表 是分配物理内存的最小单元,有4K,16K等等,系统每次申请地址时,都是按照页的单元来的。这样可以保证硬件的最高效运作。
这里可能就有人疑问了,如果每个虚拟地址都要从页表中查找的话,存储页表是不是很浪费空间。如果是4K的页面,1G点内存,岂不是就要 1024/4 = 256M。所以就产生了多级页面,多加几个目录不就可以了么?如下图:
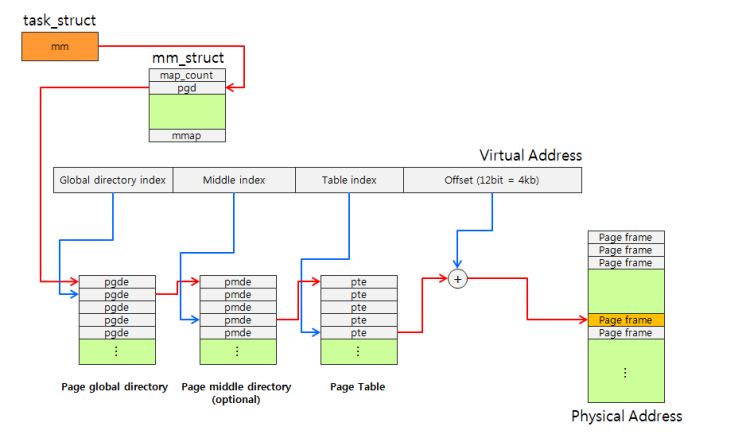
上图就是Linux操作系统中常用的三级页表,1G内存也仅仅只需要4M的页表就可以完成寻址,提高寻址速度的同时,也大大节省了空间。
上面只是简单的介绍了Linux的分页系统,为了提高分页效率有很多种分页算法,这里限于篇幅也不再介绍。在看到这的时候,想到了平时在做业务时,遇到平台统一性问题上时,就可以借鉴下操作系统如何通过增加一层抽象来对内存管理,从而磨平了平台的差异。在解决业务效率的时候,也可以通过分表的思想提高访问的速度。
进程是操作系统系统基本的执行单元。在Linux操作系统中,有一个概念叫轻量级进程(lwp)。咋一看这不就是进程,其实不然。为啥Linux不按照操作系统的概念,老老实实的做一个进程的管理呢?我理解的本质上是为了更好的重用,进程其实是一个很复杂的概念,包含了cpu调度以及需要管理各种调度的资源。而lwp其实仅仅抽象了cpu的调度过程,主要包含了cpu中寄存器上下文切换的过程和一些必须的资源管理。
在Linux的top和ps命令中,默认看到最多的是pid (process ID),也许你也能看到lwp (thread ID)和tgid (thread group ID for the thread group leader)等等。所以本质上Linux的进程是由lwp和一些共享资源组合而成的,并且lwp还可以作为内核的线程。另外这里我想说PThread其实是用户进程,通过一些库函数模拟线程的并发执行的效果,生效范围其实不在系统级别,不是lwp的级别。所以对于不同的操作系统来讲,进程和线程的实现方式并不相同,但是他们理念都大同小异,都是对cpu的调度和资源的管理。
下面我们来看下进程管理的一个核心函数,进程切换。下面我列下书中介绍的进程切换的核心代码如下:
#define switch_to(prev, next, last) \
do { \
prepare_switch_to(next); \
\
((last) = __switch_to_asm((prev), (next))); \
} while (0)
里面专门介绍了为何A,B进程切换需要三个参数,last参数的作用。
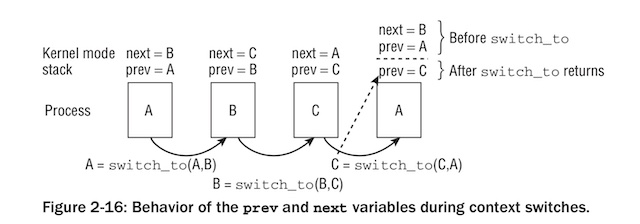
假定3个进程A、B和C在系统上运行。在某个时间点,内核决定从进程A切换到进程B,然后从进程B切换到进程C,接下来再从进程C切换回进程A。在每个switch_to调用之前,next和prev指针位于各进程的内核栈上,prev指向当前运行的进程,而next指向将要运行的下一个进程。为执行从prev到next的切换,switch_to的前两个参数足够了。对进程A来说,prev指向进程A而next指向进程B。
在进程A被选中再次执行时,会出现一个问题,控制权返回至switch_to之后的点,如果栈准确地恢复到切换之前的状态,那么prev和next仍然指向切换之前的值,即next=B,而prev=A。在这种情况下,内核无法知道实际上在进程A之前运行的进程是C。
从上面的描述可以看出,switch_to这个函数非常特殊,在从C进程切回到A进程时,在切换的上半部分是在进程C中运行的,而下半部分是在进程A中运行的,所以A进程需要读取第三个参数last才能知道是从C切换过来的。
Linux为了提高进程切换的效率,才使用这种如此不好理解的方式。其实如果我们能引入一个进程管理的进程就会更加的清晰,但是效率自然也就牺牲了。我引用下一个网友对此问题的看法。
Linux中没有专门的调度管理线程虽然咋一看很不美观,但是它毕竟不是微内核结构,大内核的 优点就是高效,直接让需要切换的进程自己调用切换代码另外别的进程就绪后告诉正运行的进程有切换需要然后着手调度,这种方式肯定最高效,如果设置了调度管 理线程,需要调度时还要通知这个管理器,很多切换很低效,但是却很美观。这一点上,Linux中的调度是和谐自发的抢占式协作,而带有调度管理器的内核对 于调度则是强行的管制。
所以我们平时在做一些业务时,为了提升效率,往往会采用一些很诡异(trick)的手段,虽然目的达到了,但是牺牲了代码的可读性。这也是Linux设计哲学的权衡,因为效率被看做Linux系统的最高优先级。
在内核的进程切换时,我们提到过上下文切换。其实中断本质上也是一种上下文切换。但是中断处理和进程切换有一个明显的差异: 由中断处理执行的代码并不是一个进程,我们常常用内核控制路径(kernel control path)来代表中断发生时,正在执行的程序。可以说中断处理的程序比lwp还要轻量级。
中断在cpu中经常发生,所以中断的效率异常重要。下图展示了中断请求发生时,数据处理的过程。
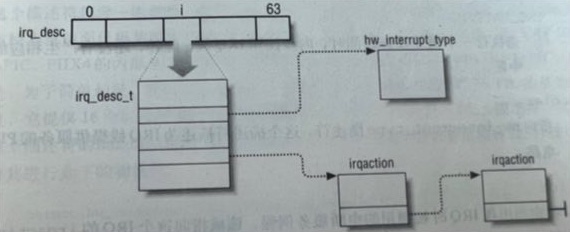
从上图中可以看出,分为上下两个部分。上部被称为硬中断处理,只有一些比较紧急的功能,它往往只是简单地读取寄存器中的中断状态并清除中断标志后就进行“登记中断”的工作。“登记中断”意味着将下半部处理程序,挂到后续的执行队列中去。下半部分是真正处理中断请求的程序逻辑。Linux下半部分处理有软中断、tasklet、工作队列。这里不过多介绍。
结合我们平时写代码时,用到的定时器,操作系统处理的过程是,根据cpu发出的时钟中断,达到用户设置定时器时间,就发生一个软中断,等待用户程序处理。但是何时处理,就跟整个系统的吞吐能力有关系了。所以平时的定时器中断,运行到处理程序时,时间并不是100%准确的。
从中可以看出,为了系统的可用性和吞吐能力,中断的设计就非常的巧妙,既解决了同时可以响应多个外设输入的问题,又解决了响应慢的问题。所以我们在处理一些业务的时候,不妨把业务的操作更加细分,就可以达到并发执行的效果,提高了业务的效率和吞吐率。
Linux是实现了操作系统这个复杂的业务的一种系统,我们平时做的业务可能远远没有这么复杂,也不会要求如此高的效率,但是从Linux的设计实践中,我们可以借鉴很多的理念和方法来提高我们业务的效率。如果再做10年的业务,回头看这本书,可能会有另外的感悟。
在感叹到Linux的精妙设计的同时。也会感受到其中的复杂,到现在很多设计理念我还是一知半解,可能大多数人都要花上很多年才能读懂这本书。可是Linux随着时间的发展,仍然在不定的迭代和进步。所以人类的知识体系只会越来越复杂,那么人类的进化速度是否可以赶上知识复杂演变的速度呢?之前记得读过一篇文章讲到,人类可能会因为构建过于复杂的世界而崩溃,因为没有一个人可以理解,所处系统的运行机制。这个哲学问题也留给大家来思考了。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK