

识别形式语言能力不足,不完美的Transformer要克服自注意力的理论缺陷
source link: https://www.51cto.com/article/706456.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
尽管 transformer 模型在许多任务中都非常有效,但它们对一些看起来异常简单的形式语言却难以应付。Hahn (2020) 提出一个引理 5),来试图解释这一现象。这个引理是:改变一个输入符号只会将 transformer 的输出改变 𝑂(1/𝑛),其中 𝑛 是输入字符串的长度。
因此,对于接收(即判定某个字符串是否属于某个特定语言)只取决于单个输入符号的语言,transformer 可能会以很高的准确度接受或拒绝字符串。但是对于大的 𝑛,它必须以较低的置信度做出决策,即给接受字符串的概率略高于 ½,而拒绝字符串的概率略低于 ½。更准确地说,随着 𝑛 的增加,交叉熵接近每个字符串 1 比特,这是最坏情况的可能值。
近期,在论文《Overcoming a Theoretical Limitation of Self-Attention》中,美国圣母大学的两位研究者用以下两个正则语言(PARITY 和 FIRST)来检验这种局限性。
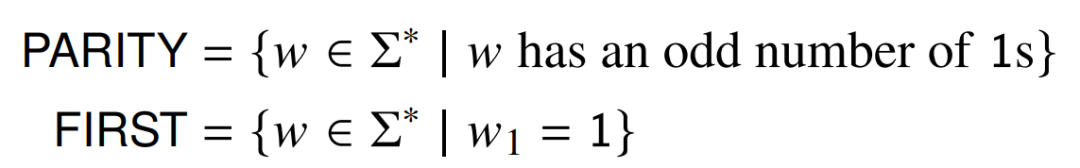
Hahn 引理适用于 PARITY,因为网络必须关注到字符串的所有符号,并且其中任何一个符号的变化都会改变正确答案。研究者同时选择了 FIRST 作为引理适用的最简单语言示例之一。它只需要注意第一个符号,但因为更改这个符号会改变正确答案,所以该引理仍然适用。
尽管该引理可能被解释为是什么限制了 transformer 识别这些语言的能力,但研究者展示了三种可以克服这种限制的方法。
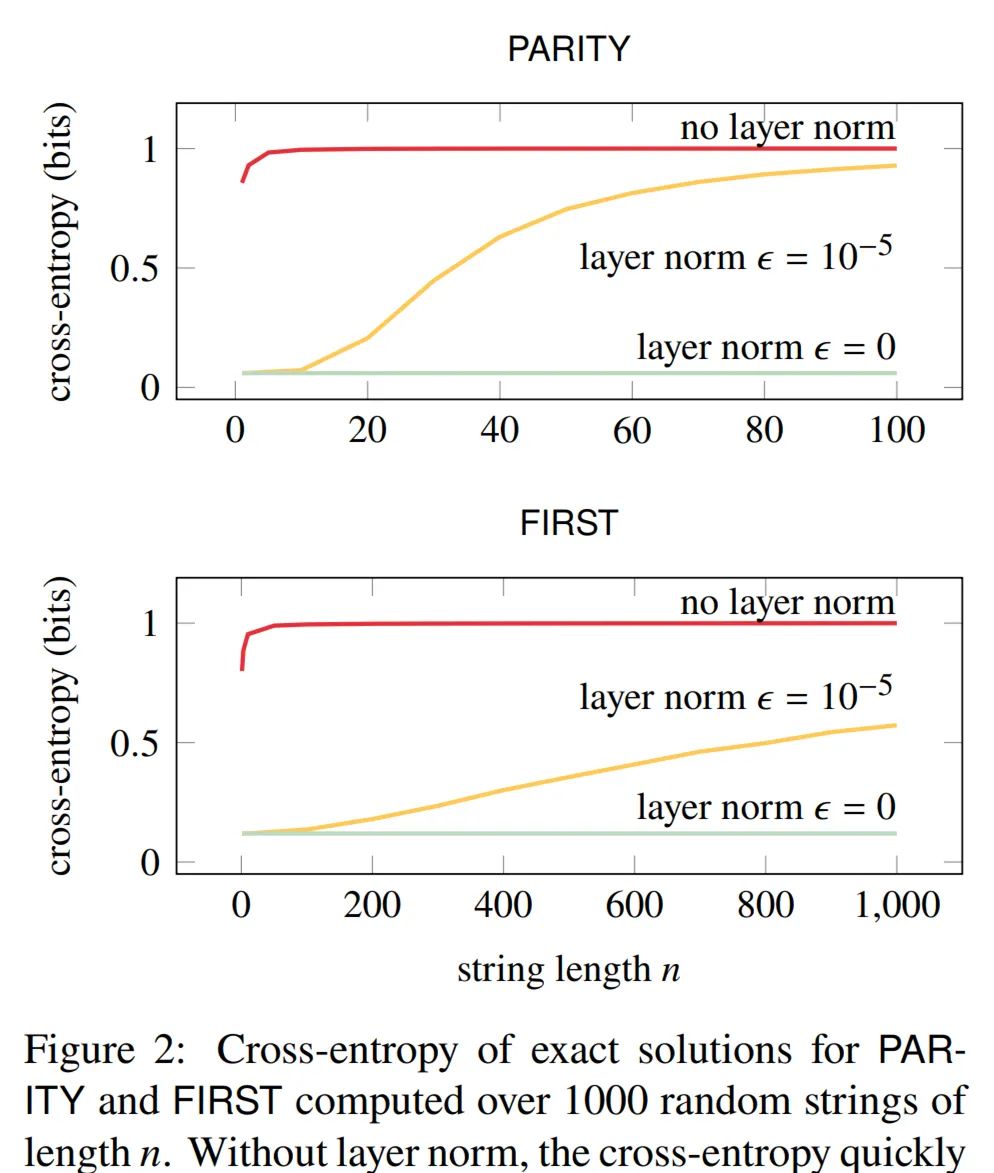
首先,文章通过显式构造表明,以高准确度识别任意长度的语言的 transformer 确实是存在的。研究者已经实现了这些结构并通过实验验证了它们。正如 Hahn 引理所预测的那样,随着输入长度的增加,这个构建的 transformer 的交叉熵接近 1 比特(也就是,仅比随机猜测好一点)。但文章也表明,通过添加层归一化,交叉熵可以任意接近零,而与字符串长度无关。
研究者在实践中还发现,正如 Bhattamishra 等人所指出的,transformer 无法学习 PARITY。也许更令人惊讶的是,在学习 FIRST 时,transformer 可能难以从较短的字符串泛化到较长的字符串。尽管这不是 Hahn 引理的逻辑上可以推出的结果,但它是 Hahn 引理预测行为的结果。幸运的是,这个问题可以通过简单的修改来解决,即将注意力的 logit 乘以 log 𝑛。此修改还改进了机器翻译中在长度方面的泛化能力。

论文地址:https://arxiv.org/pdf/2202.12172.pdf
精确解决方案
克服 Hahn 引理所暗示的缺点的第一种方法是通过显式构造表明 transformer 可以以高精度识别出上述提到的两种语言。
针对 PARITY 的前馈神经网络(FFNN)
Rumelhart 等人表明,对于任何长度𝑛都有一个前馈神经网络 (FFNN) 可以计算长度正好为 𝑛 的字符串的 PARITY。他们还表明,随机初始化的 FFNN 可以自动学习这么做。
由于文章所提出构建方式部分基于他们的,因此详细回顾他们的构建可能会有所帮助。设𝑤为输入字符串,|𝑤| = 𝑛,𝑘是𝑤中 1 的个数。输入是一个向量 x,使得 x_𝑖 = I[𝑤_𝑖 = 1]。第一层计算 𝑘 并将其与 1,2,...,n 进行比较:
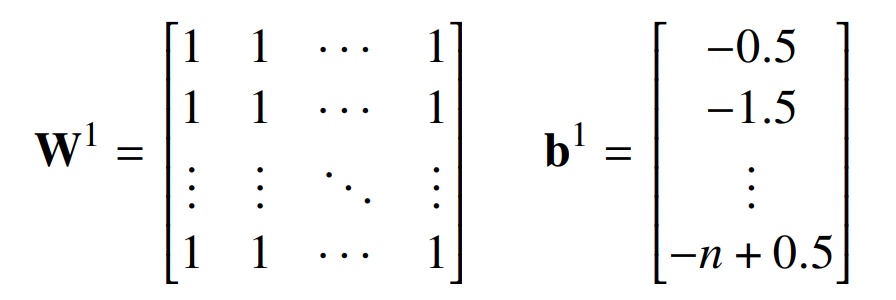
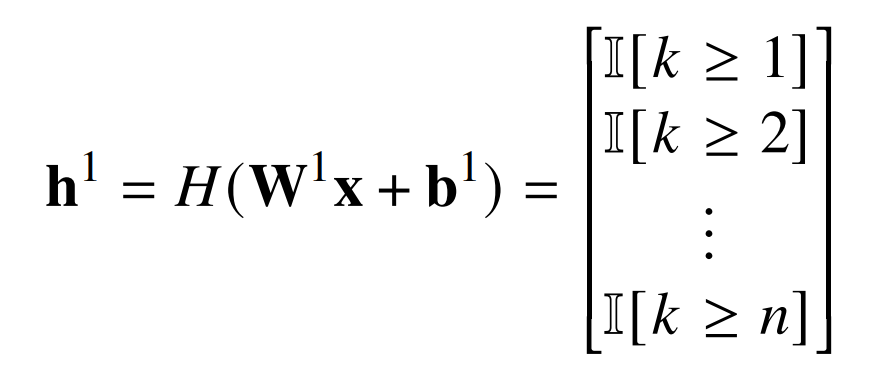
第二层将奇数元素相加并减去偶数元素:
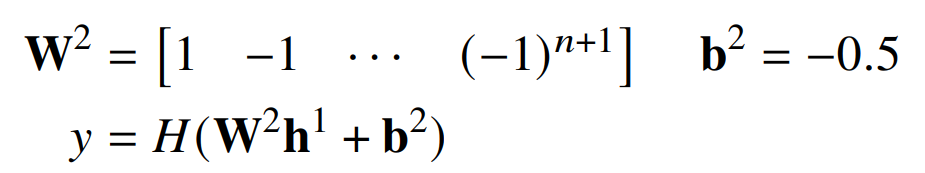
针对 PARITY 的 transformer
命题 1. 存在一个带有 sigmoid 输出层的 transformer,它可以识别(在上述意义上)任意长度字符串的 PARITY 语言。
最初,研究者将构造一个没有层归一化的 transformer 编码器(即 LN(x) = x);然后展示如何添加层标准化。设 𝑘 是 1 在 𝑤 中出现的次数。网络计算的所有向量都有 𝑑 = 9 维;如果显示出较少的维度,则假设剩余的维度为零。 词和位置嵌入是:
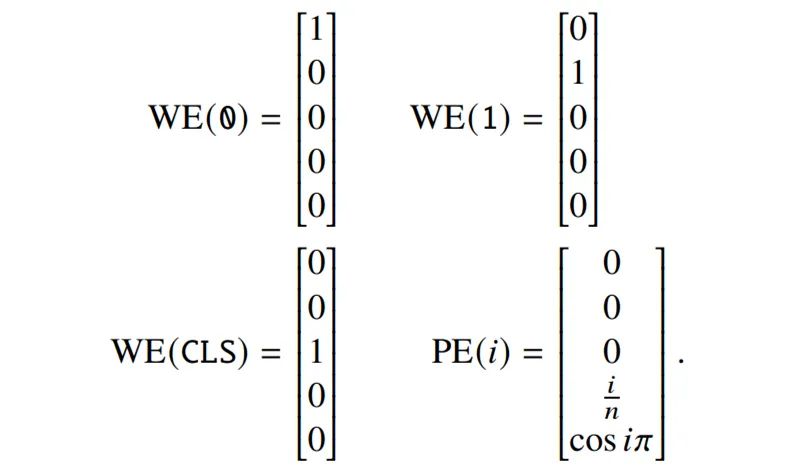
研究者认为,位置编码的第五维使用余弦波是一个相当标准的选择,尽管它的周期 (2) 比标准正弦编码中的最短周期 (2𝜋) 短。第四维度诚然不是标准的;但是,研究者认为这依然是一种合理的编码,并且非常容易计算。因此,单词𝑤_𝑖的编码是:
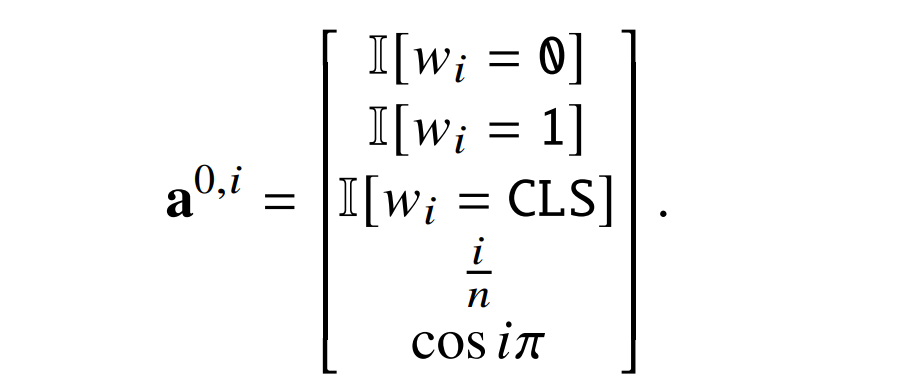
第二个 head 不做任何事情(W^V,1,2 = 0;query 和 key 可以是任何东西)。在残差连接之后,可以得到:

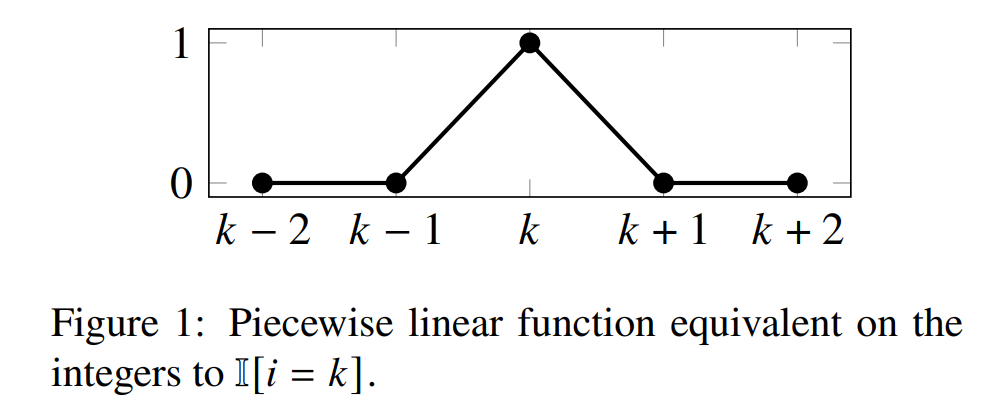
在 Rumelhart 等人的构造中,下一步是使用阶跃激活函数为每个 𝑖 计算 I[𝑖 ≤ 𝑘]。文章提出的构造有两个不同之处。首先,激活函数采用 ReLU,而不是阶跃激活函数。其次,因为注意力总和必须为 1,如果 𝑛是奇数,那么偶数和奇数位置将获得不同的注意力权重,因此奇数位置减去偶数位置的技巧将不起作用。相反,我们想要计算 I[𝑖 = 𝑘](如下图 1)。
第一个 FFNN 有两层,第一层是:
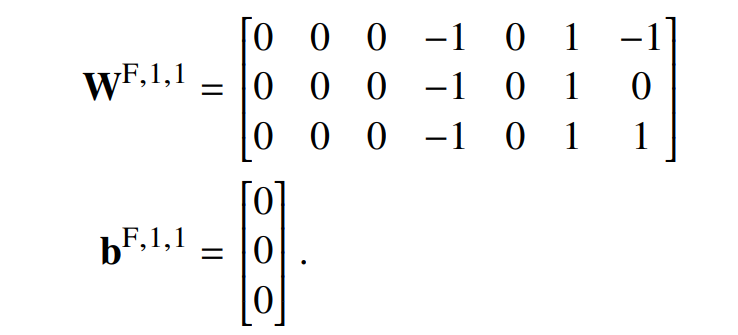
由此可以得出:
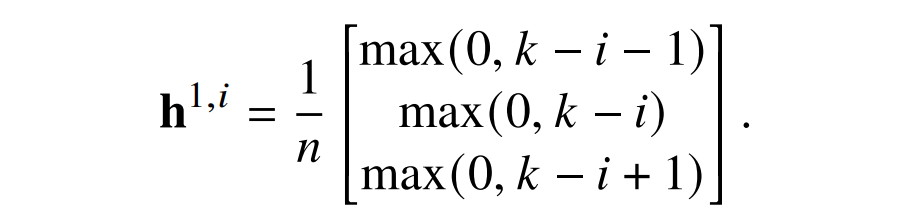
第二层采用线性的方式把这三个值结合在一起得到想要的 I[𝑖 = 𝑘]。
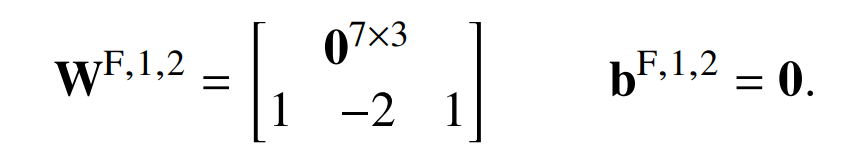
第二个自注意力层测试位置𝑘是偶数还是奇数。它使用两个 head 来做到这一点,一个更强烈地关注奇数位置,一个更强烈地关注偶数位置;两者的平均维度大小为 8:
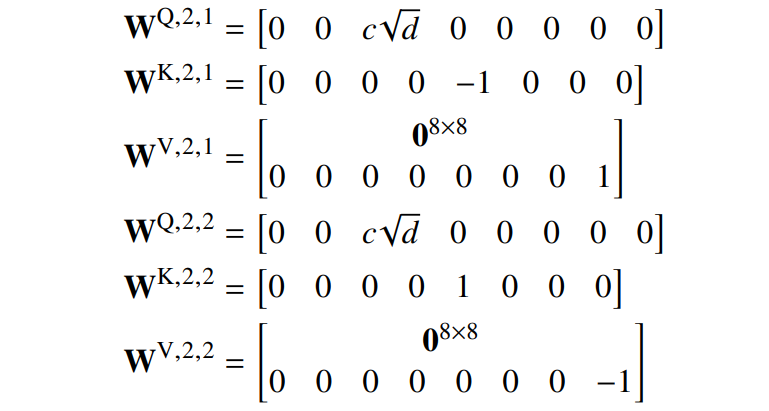
针对 FIRST 的 transformer
接下来,研究者为 FIRST 构建一个 transformer。根据学习每个位置词嵌入的常见做法(Gehring 等人,2017 年),他们使用位置编码来测试一个词是否在第 1 个位置 :

第一层 FFNN 计算一个新的组件(5)来测试是否 i = 1 以及 w_1 = 1。
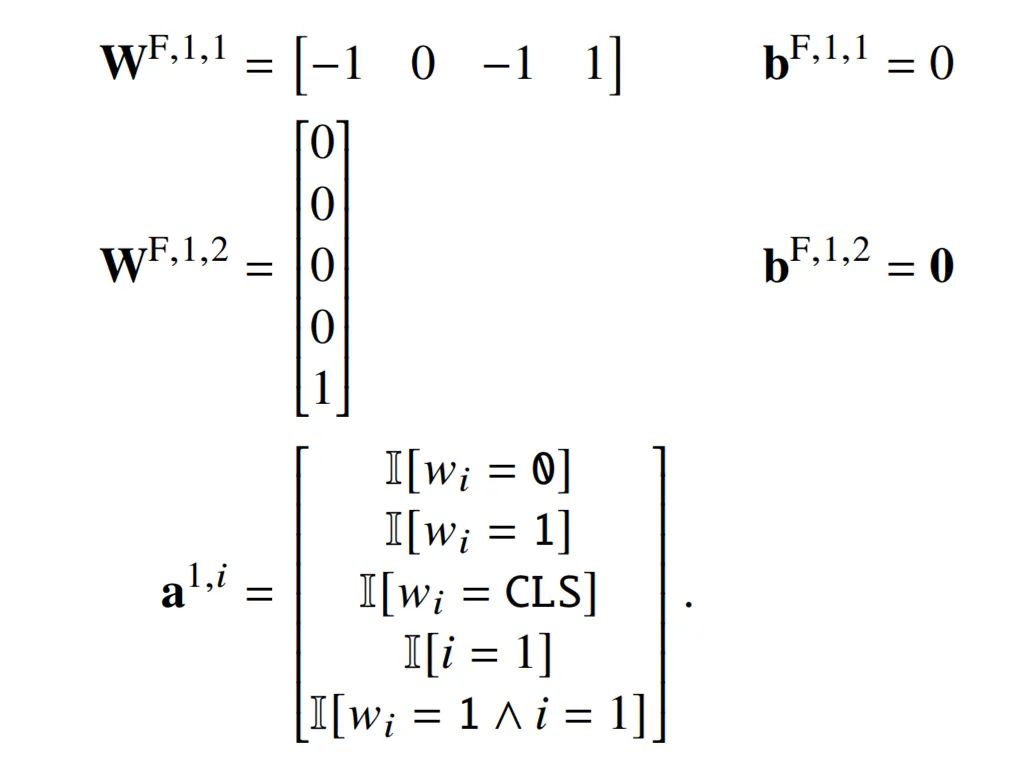
第二个自注意力层只有一个单一的 head,这使得 CLS 关注于位置 1.
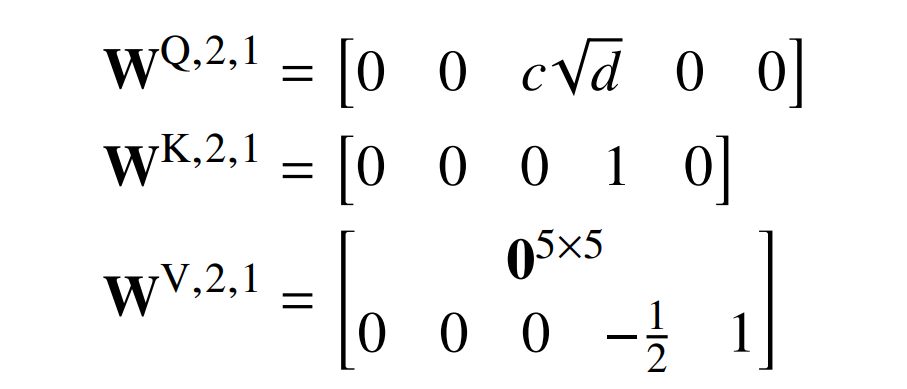
第二层 FFNN 什么都不做(W^F,2,1 = b^F,2,1 = W^F,2,2 = b^F,2,2 = 0)。所以在 CLS 处(位置 0 处):
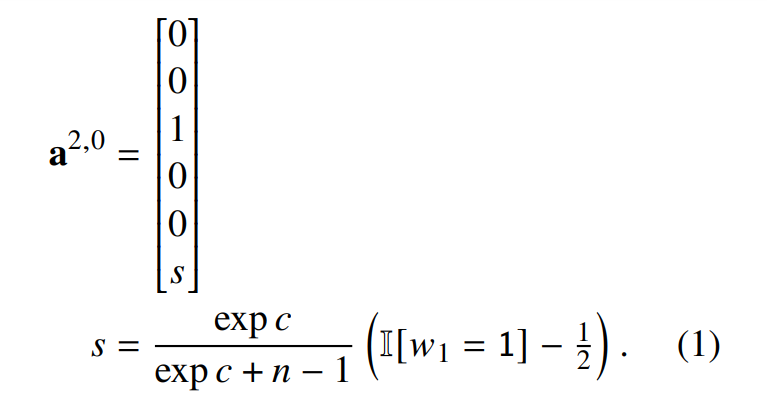
最后输出层仅仅选择组件 6。
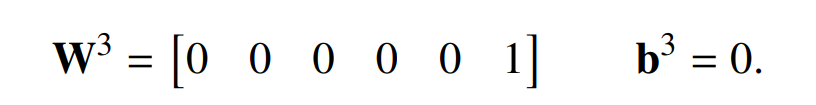
文章使用 PyTorch 的 transformer 内置实现的修改版本(Paszke 等人,2019)实现了上述两种建构。这些构造对长度从 [1, 1000] 采样的字符串实现了完美的准确性。 然而,在下图 2 中,红色曲线(「没有做层归一化」)表明,随着字符串变长,交叉熵接近每个字符串 1 比特的最坏可能值。
减轻或消除 Hahn 引理限制的第二种方法是层归一化 (Ba et al., 2016),对于任何向量 x,其定义为
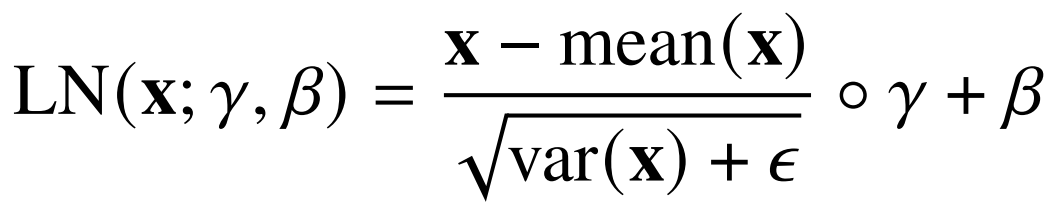
实验中,𝛽 = 0 和𝛾 = 1,因此结果的均值近似为零和方差近似为 1。常数 𝜖 没有出现在原始定义中(Ba et al., 2016),但为了数值稳定性,我们知道的所有实现中都添加了常数𝜖。
原始的 transformer 在每个残差连接后立即执行层归一化。在本节中,研究者修改了上面的两个结构的层归一化。,这一修改有两个步骤。
第一个是通过使网络计算每个值𝑥以及 -𝑥来消除层归一化的中心效应。新单词的编码是根据原始结构中的编码定义的:
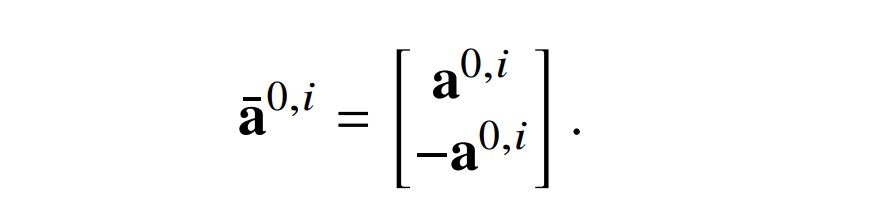
对于自注意力层的参数也是类似。
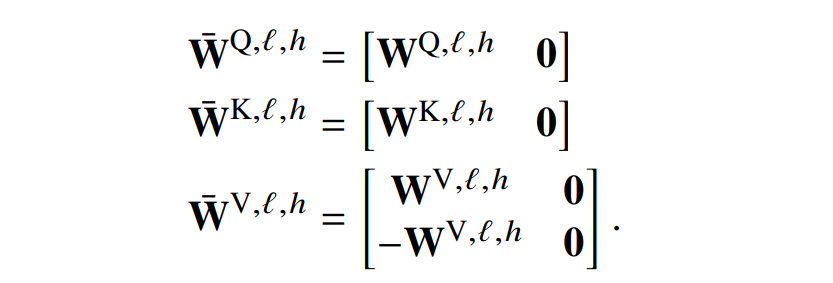
对于每个位置的 FFNN 参数也类似。
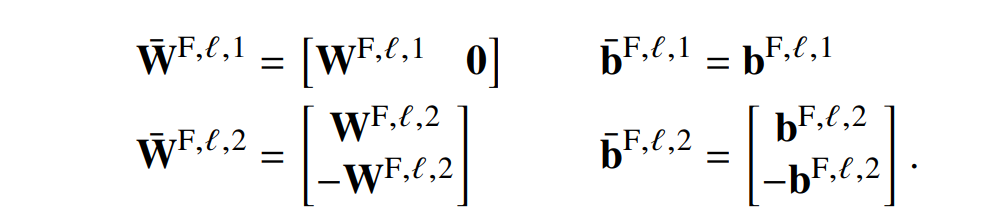
之后,每层的激活值为:
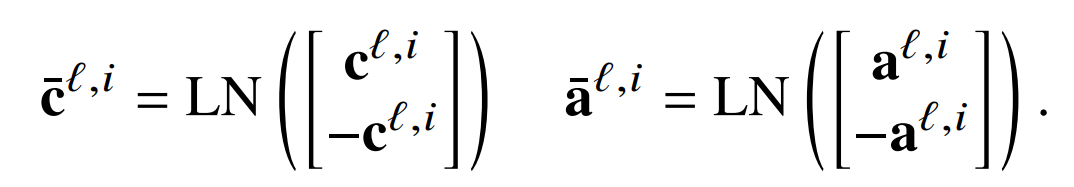
LN 的参数始终具有零均值,因此层标准化不会增加或减少任何内容。它确实缩放了激活,但在上面构建的两个 transformer 的情形中,任何激活层都可以按任何正数进行缩放,而不会改变最终决策。
减少交叉熵
此外,在任何转换器中,我们可以在任意 transformer 中使用层归一化来将交叉熵缩小到想要的任意小,这与 Hahn 的引理 5 相反。在 Hahn 的公式中,像层归一化这样的位置相关的函数可以包含在他的 𝑓^act 中,但是 引理假设 𝑓^act 是 Lipschitz 连续的,而 ϵ = 0 的层归一化不是。
命题 2. 对于任何具有层归一化 (ϵ = 0) 并可以识别语言 L 的 transformer 𝑇,对任何 𝜂 > 0 而言,都存在一个可以以最多𝜂为交叉熵的、带有层归一化的识别语言 L 的 transformer。
证明。让𝑑表示原始激活向量中的维数,𝐿是层数。然后添加一个新层,这个层中的自注意力不做任何事情 (W^V,𝐿+1,ℎ = 0),并且 FFNN 是根据原始输出层定义的:
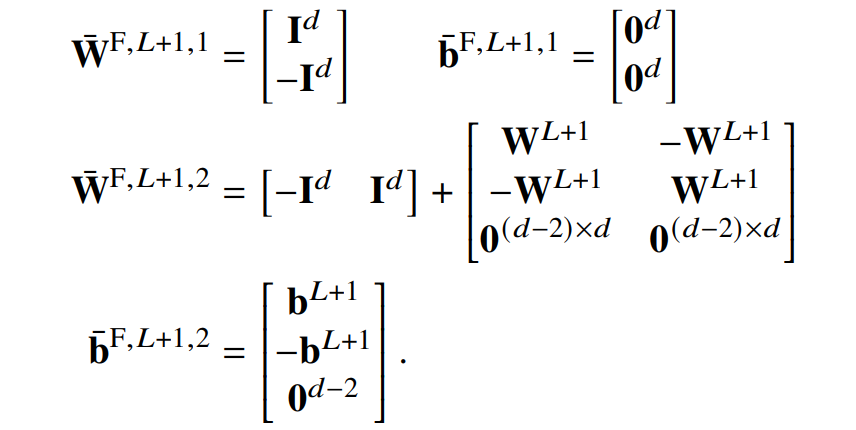
这会导致残差连接除了 2 个维度外的所有维度为零,因此如果𝑠是原始输出 logit,则此新层的输出(层归一化之前)为
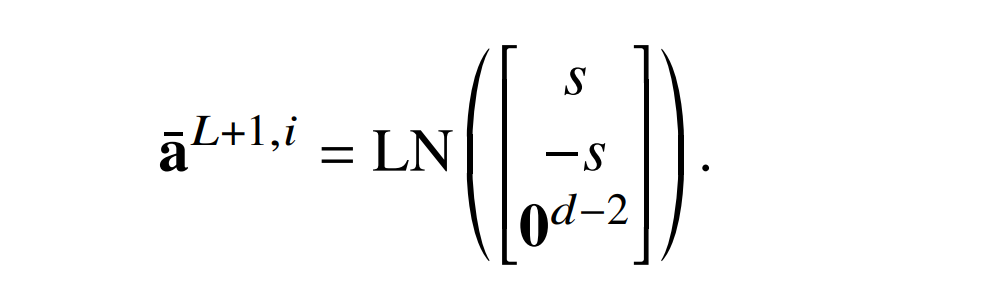
现在,如果 ϵ = 0,层归一化将该向量缩放到只具有单位方差,因此它变为:
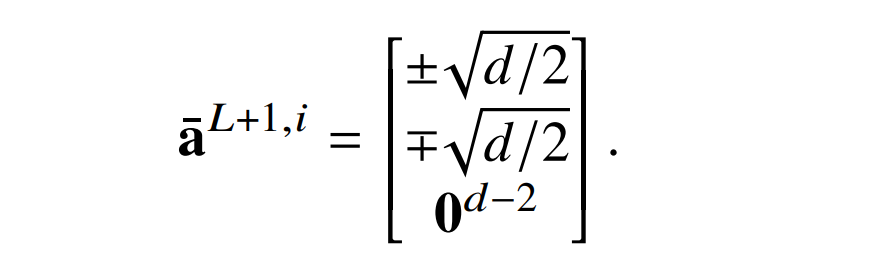
新的输出层只是简单地选择第一维,并把它拓展到 c 倍。
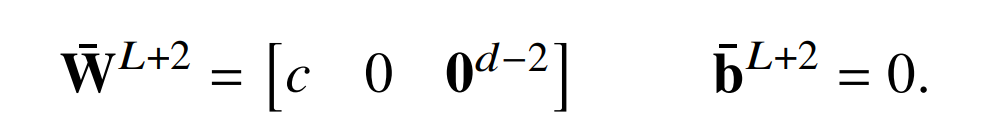
研究者测试了这一解决方案,它在层归一化时进行了如上修改。上图 2 显示 ϵ > 0 的层归一化提高了交叉熵,但它仍然随着 𝑛 增长并接近 1。
在本节中,研究者将转向可学习性的问题,这时克服 Hahn 引理所提出的缺陷的第三种方法。
实验:标准的 transformer
研究者在 PARITY 和 FIRST 上训练 transformer。每个 transformer 都具有与对应的精确解相同的层数和头数以及相同的固定位置编码。与单词编码、自注意力相关的 FFNN 输出的𝑑_model 为 16,而与 FFNN 隐藏层相关的𝑑_FFNN 为 64。残差连接之后使用了层归一化(ϵ = 10^-5)。
实验使用 PyTorch 默认的初始化并使用 Adam (Kingma and Ba, 2015) 进行训练,学习率为 3 × 10^−4 (Karpathy, 2016)。实验没有使用 dropout,因为它似乎没有帮助。 FIRST 更容易学习,但坏消息是学习到的 transformer 不能很好地泛化到更长的句子。下图 4(左列)显示,当 transformer 在较短的字符串(𝑛 = 10、30、100、300)上从头开始训练并在较长的字符串(𝑛 = 1000)上进行测试时,准确度并不非常好。事实上,对于𝑛 = 10 上的训练,准确度和随机猜测类似。
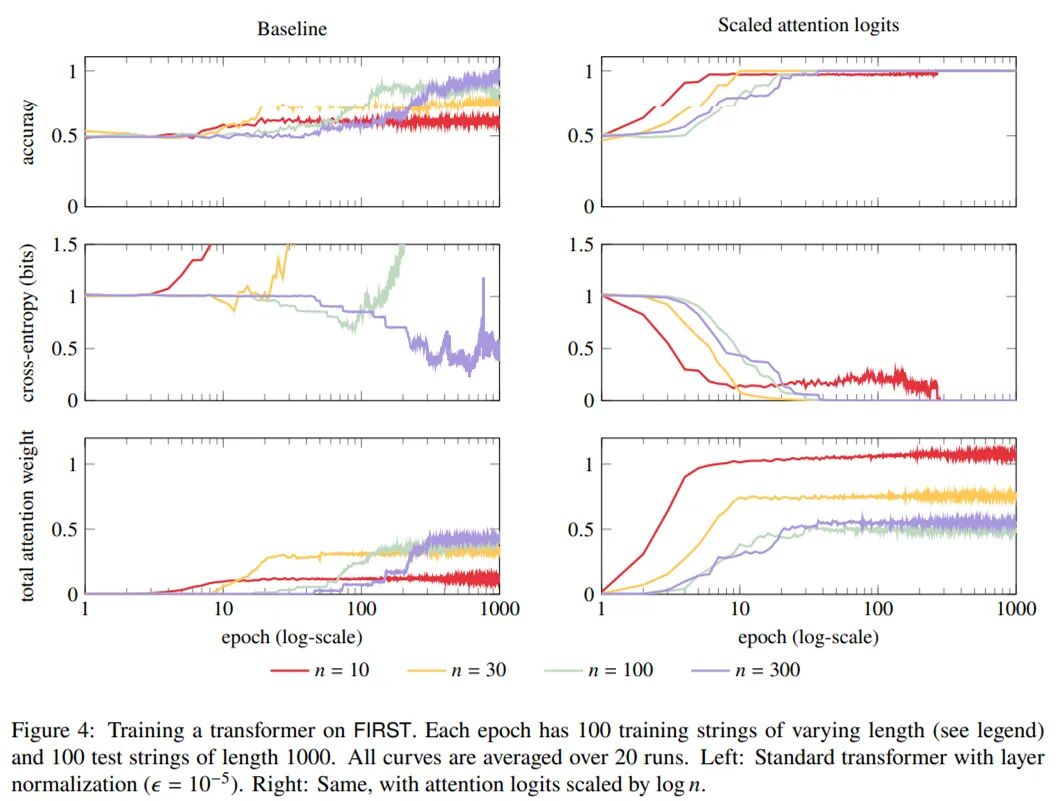
长度取对数后拓展的注意力
幸运的是,这个问题很容易通过以 log 𝑛的比例缩放每个注意力层的 logits 来解决,即将注意力重新定义为

然后使用 c = 1 下的针对 FIRST 的 Flawed transformer:
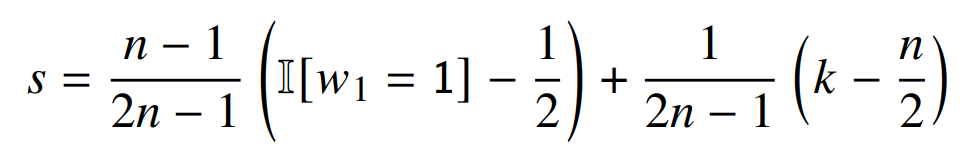
命题 3。对于任何 𝜂 > 0,都存在一个带有如公式 2 所定义的注意力的 transformer,它无论有无层归一化,都可以以最多𝜂的交叉熵来识别 FIRST 语言。
证明。当没有层归一化时,3.3 节中描绘的模型中 c 设为 1,并对注意力的权重进行对数尺度的缩放,它可以将公式(1)中的 s 从公式(1)转化为:
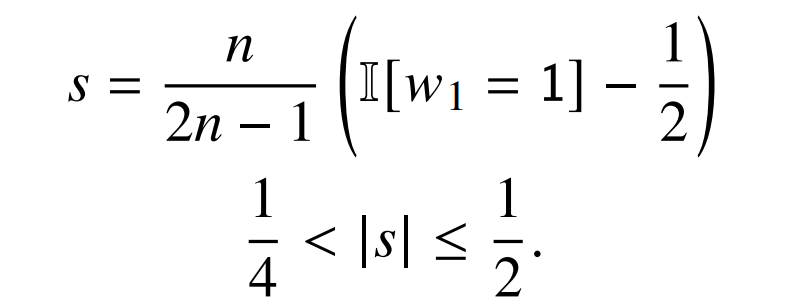
实验:缩放的注意力
下图 4(右栏)的 tranformer 模型使用了 log n 为缩放因子的注意力。
我们可以在稀缺资源英语 - 越南语的机器翻译任务上使用开源 transformer 模型(即 Witwicky)时看到相似的效应(如下表 1 所示)。
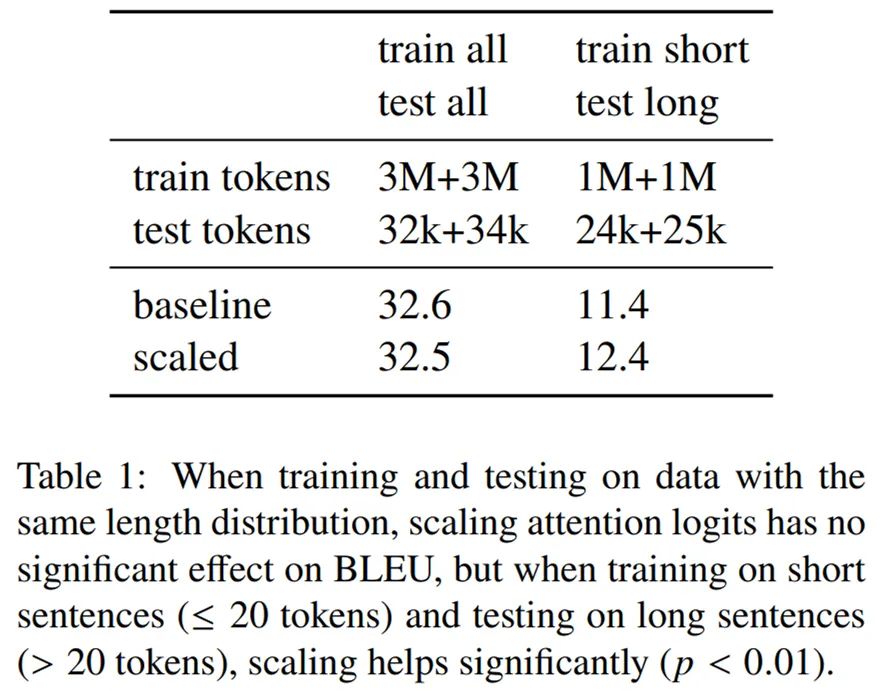
当训练集和测试即得长度分布一样得时候,缩放注意力的 logits 没有显著的影响,但如果仅在只有中等甚至更短(小于 20)长度的句子上训练,而测试句子长度大于中等长度(大于 20),缩放注意力则提高了 1 个 BLEU 分数,这在统计上已经很显著了(p 值小于 0.01)。
感兴趣的读者可以阅读论文原文,了解更多研究细节。
Recommend
-
21
实验二 DFA识别句子 一、实验目的 加深对DFA工作原理的理解。 二、实验内容 1.设计固定DFA。也就是说用if-then-else(一般用来实现字母表中只有两个字母的情况)、switch(大于两个字母...
-
55
雷锋网 (公众号:雷锋网) AI 科技评论按,胶囊网络是一种热门的计算机网络模型,倍受人工智能领域相关研究人员的关注。而 transformer 是谷歌在 2017 年的一篇著名论文「 Atten...
-
26
栗子 发自 凹非寺 量子位 报道 | 公众号 QbitAI 如今,语言模型的世界,几乎被Transformer/BERT占领了。 但如果回到2017年,把轰动世界的论文 Attention Is All You Need 从时间线上抹掉呢...
-
32
作者:舒意恒(南京大学硕士生,知识图谱方向) 今天给大家介绍一篇来自Google的最新论文《 SYNTH...
-
52
本文以QA形式对自然语言处理中注意力机制(Attention)进行总结,并对Transformer进行深入解析。 目录 一、Attention机制剖...
-
41
最近要开始使用Transformer去做一些事情了,特地把与此相关的知识点记录下来,构建相关的、完整的知识结构体系, 以下是要写的文...
-
56
最近要开始使用Transformer去做一些事情了,特地把与此相关的知识点记录下来,构建相关的、完整的知识结构体系, 以...
-
12
欢迎关注“ 计算机视觉研究院
-
1
Transformer 的注意力头越多越好么 – 我爱自然语言处理
-
3
漫谈注意力机制(七):Transformer模型之BERT、BERT-wwm、RoBERTa、ALBERT简述本文介绍BERT、RoBERTa、ALBERT、GPT的若干版本等等。 预训练模型可以分为三类: 基于特征的策略的模型,如 ELMo 是双向但浅层无法学习更复杂的语义...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK