

为什么 OLAP 需要列式存储
source link: https://draveness.me//whys-the-design-olap-column-oriented
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

为什么 OLAP 需要列式存储
2021-02-02 为什么这么设计 系统设计 数据库 MySQL ClickHouse为什么这么设计(Why’s THE Design)是一系列关于计算机领域中程序设计决策的文章,我们在这个系列的每一篇文章中都会提出一个具体的问题并从不同的角度讨论这种设计的优缺点、对具体实现造成的影响。如果你有想要了解的问题,可以在文章下面留言。
ClickHouse 是最近比较热门的用于在线分析处理的(OLAP)1数据存储,与我们常见的 MySQL、PostgreSQL 等传统的关系型数据库相比,ClickHouse、Hive 和 HBase 等用于在线分析处理(OLAP)场景的数据存储往往都会使用列式存储。
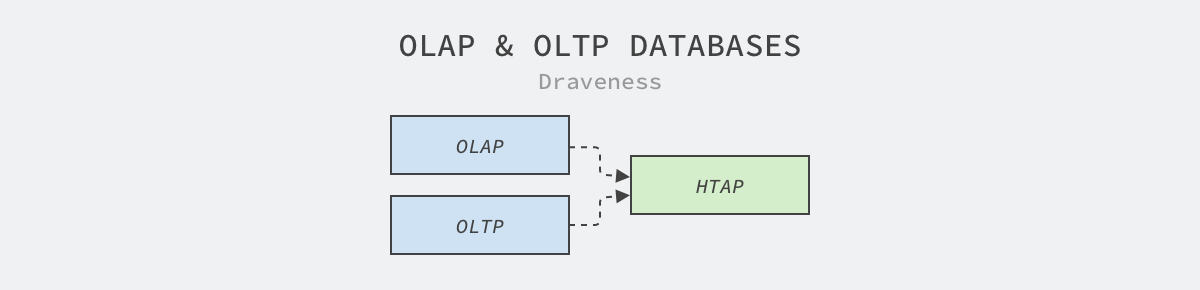
图 1 - OLAP 和 OLTP
对数据库稍有了解的读者都知道,在线事务处理(Online Transaction Processing、OLTP)2和在线分析处理(Online Analytical Processing、OLAP)是数据库最常见的两种场景,这两种场景不是唯二的两种,从中衍生出来的还有混合事务分析处理(Hybrid Transactional/Analytical Processing、HTAP)3等概念。
在线事务处理是最常见的场景,在线服务需要为用户实时提供服务,提供服务的过程中可能要查询或者创建一些记录;而在线分析处理的场景需要批量处理用户数据,数据分析师会根据用户产生的数据分析用户行为和画像、产出报表和模型。
标题中提到的列式存储与传统关系型数据库的行式存储相对应,如下图所示,其中行式存储以数据行或者实体为逻辑单元管理数据,数据行的存储都是连续的,而列式存储以数据列为逻辑单元管理数据,相邻的数据都是具有相同类型的数据。
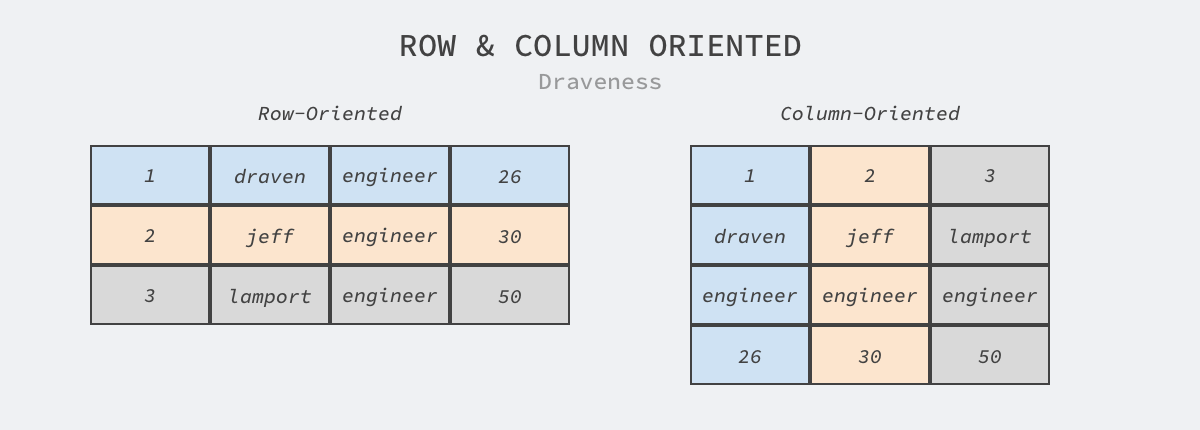
图 2 - 行式存储和列式存储
既然我们已经了解了标题中提到的两个概念:OLAP 和列式存储,那么接下来将从以下两个方面分析为什么列式存储更适合 OLAP 的场景。
- 列式存储可以满足快速读取特定列的需求,在线分析处理往往需要在上百列的宽表中读取指定列分析;
- 列式存储就近存储同一列的数据,使用压缩算法可以得到更高的压缩率,减少存储占用的磁盘空间;
在线服务需要应对用户发起的增删改查需求,虽然查询的需求往往都是写入请求的几倍、甚至几十倍,但是写操作带来的负责一致性问题成为了在线服务数据存储不得不解决的问题,MySQL 和 PostgreSQL 等使用关系型数据库提供的事务可以提供很好的方案。
正是因为 OLTP 场景中大多数的操作都是以记录作为单位的,所以将经常被同时使用的数据相邻存储也是很符合逻辑的,但是如果我们将 MySQL 等数据库用于 OLAP 场景,最常见的查询也可能需要遍历整张表中的全部数据。
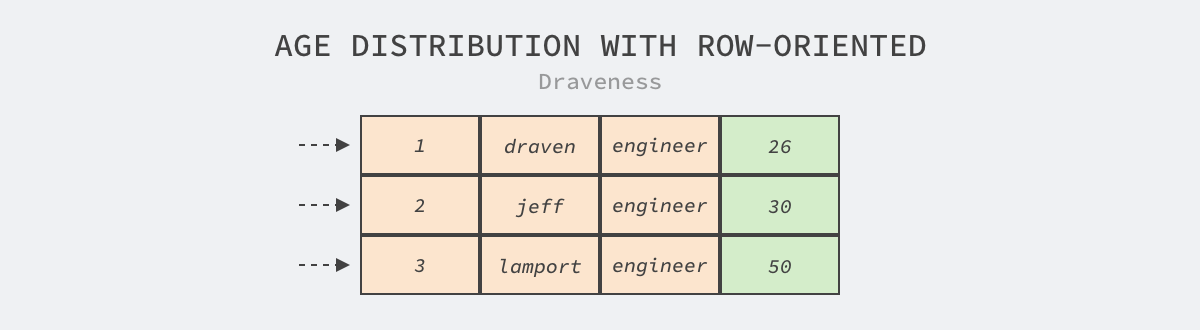
图 3 - 在行式存储获取特定列
如上图所示,当我们仅需要获取上表中年龄的分布时,也仍然需要读取表中的全部数据并在内存中丢弃不需要的数据行,其中黄色部分都是我们不关心的数据,这浪费了大量的 I/O 和内存资源。虽然我们可以使用辅助索引解决这些问题,但是对于 OLAP 中常见的几十列甚至上百列的宽表就捉襟见肘了。
列式存储会按列存储数据,这也意味着在读取数据表中的特定列时,我们只需要找到相应内存空间的起始位置,然后读取这片连续的内存空间就可以获得关心的全部数据。

图 4 - 在列式存储获取特定列
哪怕在几百列的大表中找到几个特定列也不需要遍历整张表,只需要找到列的起始位置就可以快速获取相关的数据,减少了 I/O 和内存资源的浪费,这也是为什么面向列的存储系统更适合在 OLAP 的场景中使用。
因为列式存储将同一列的数据存储在一起,所以使用压缩算法可以得到更高的压缩率,减少存储占用的磁盘空间。压缩算法的基本原理其实很简单,它使用基于特定规则的数据表示原数据,如下所示的字符串中包含连续的相同字符,我们使用最符合直觉的压缩算法就可以减少字符串的长度:
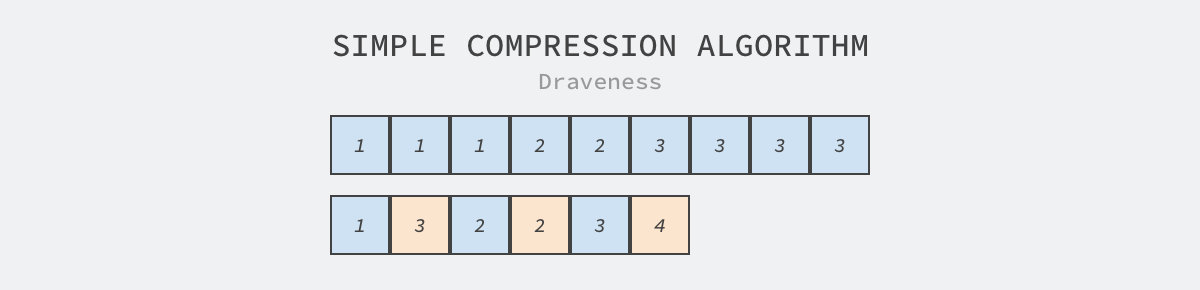
图 5 - 简单的压缩算法
上图中所有的黄色方块表示前面字符串的重复次数,这种简单的压缩策略可以在保证无损的情况下将字符串的长度压缩 33%,然而压缩率是由压缩算法和数据的特性共同决定的。与面向行的数据存储相比,面向列的数据存储会将相同类型的数据就近存储,这也给压缩算法的提供了更多发挥的空间。
虽然压缩算法实际上是一种使用 CPU 时间换取 I/O 时间和空间的策略,但是在多数情况下,这种生意都是稳赚不赔的。压缩算法通过减少数据的大小、减少磁盘的寻道时间提高 I/O 的性能、减少数据的传输时间并提高缓冲区的命中率,节省的 I/O 时间可以轻易补偿它带来的 CPU 额外开销4。
在线分析处理的场景虽然一直都存在,不过随着数字化浪潮的演进,我们也只是在最近才采集到了海量的用户数据。因为过去的系统无法满足今天海量数据的分析和处理需求,所以才出现了为细分场景设计的系统,面向列的存储系统也因为它的以下特性在 OLAP 的场景中焕发了光彩:
- 列式存储可以满足快速读取特定列的需求,在线分析处理往往需要在上百列的宽表中读取指定列分析,而传统的行式存储在分析数据时往往需要使用索引或者遍历整张表,带来了非常大的额外开销;
- 列式存储就近存储同一列的数据,使用压缩算法可以得到更高的压缩率,减少存储占用的磁盘空间,虽然带来了 CPU 时间的额外开销,但是节省的 I/O 时间比带来的额外开销更多;
列式存储在 OLAP 的场景中有着种种优势,不过它也不是数据存储中的银弹,仍然有很多缺点,不过在这里就不做讨论了。到最后,我们还是来看一些比较开放的相关问题,有兴趣的读者可以仔细思考一下下面的问题:
- 列式存储在 OLTP 的场景中有哪些缺点?
- HTAP 的场景会使用哪种方式存储数据?
如果对文章中的内容有疑问或者想要了解更多软件工程上一些设计决策背后的原因,可以在博客下面留言,作者会及时回复本文相关的疑问并选择其中合适的主题作为后续的内容。
Wikipedia: Online analytical processing https://en.wikipedia.org/wiki/Online_analytical_processing ↩︎
Wikipedia: Online transaction processing https://en.wikipedia.org/wiki/Online_transaction_processing ↩︎
Wikipedia: Hybrid transactional/analytical processing https://en.wikipedia.org/wiki/Hybrid_transactional/analytical_processing ↩︎
Abadi D, Madden S, Ferreira M. Integrating compression and execution in column-oriented database systems[C]//Proceedings of the 2006 ACM SIGMOD international conference on Management of data. 2006: 671-682. ↩︎

本作品采用知识共享署名 4.0 国际许可协议进行许可,转载时请注明原文链接,图片在使用时请保留全部内容,可适当缩放并在引用处附上图片所在的文章链接。
Go 语言设计与实现
各位读者朋友,很高兴大家通过本博客学习 Go 语言,感谢一路相伴! 《Go语言设计与实现》 的纸质版图书已经上架京东,本书目前已经四印,印数超过 10,000 册,有需要的朋友请点击 链接 或者下面的图片购买。
你可以在 技术文章配图指南 中找到画图的方法和素材。Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK