

eBPF+Ftrace 合璧剑指:no space left on device? - 深入浅出eBPF
source link: https://www.cnblogs.com/davad/p/16120228.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

本文地址:https://www.ebpf.top/post/no_space_left_on_devices
最近在生产环境中遇到了几次创建容器报错 ”no space left on device“ 失败的案例,但是排查过程中发现磁盘使用空间和 inode 都比较正常。在常规的排查方式都失效的情况下,有没有快速通用思路可以定位问题根源呢?
本文是在单独环境中使用 eBPF + Ftrace 分析和排查问题流程的记录,考虑到该方式具有一定的通用性,特整理记录,希望能够起到抛砖引玉的作用。
作者水平有限,思路仅供参考,难免存在某些判断或假设存在不足,欢迎各位专家批评指正。
1. ”no space left on device“ ???
本地复现的方式与生产环境中的问题产生的根源并不完全一致,仅供学习使用。
在机器上运行 docker run ,系统提示 “no space left on device” ,容器创建失败:
$ sudo docker run --rm -ti busybox ls -hl|wc -ldocker: Error response from daemon: error creating overlay mount to /var/lib/docker/overlay2/40de1c588e43dea75cf80a971d1be474886d873dddee0f00369fc7c8f12b7149-init/merged: no space left on device.See 'docker run --help'.错误提示信息表明在 overlay mount 过程中磁盘空间不足,通过 df -Th 命令进行确定磁盘空间情况,如下所示:
$ sudo df -ThFilesystem Type Size Used Avail Use% Mounted ontmpfs tmpfs 392M 1.2M 391M 1% /run/dev/sda1 ext4 40G 19G 22G 46% /tmpfs tmpfs 2.0G 0 2.0G 0% /dev/shmtmpfs tmpfs 5.0M 0 5.0M 0% /run/lock/dev/sda15 vfat 98M 5.1M 93M 6% /boot/efitmpfs tmpfs 392M 4.0K 392M 1% /run/user/1000overlay overlay 40G 19G 22G 46% /root/overlay2/merged但磁盘空间使用情况表明,系统中挂载的 overlay 设备使用率仅为 46%。根据一些排查经验,我记得文件系统中 inode 如耗尽也可能导致这种情况发生,使用 df -i 对于 inode 容量进行查看:
$ sudo df -iFilesystem Inodes IUsed IFree IUse% Mounted ontmpfs 500871 718 500153 1% /run/dev/sda1 5186560 338508 4848052 7% /tmpfs 500871 1 500870 1% /dev/shmtmpfs 500871 3 500868 1% /run/lock/dev/sda15 0 0 0 - /boot/efitmpfs 100174 29 100145 1% /run/user/1000overlay 5186560 338508 4848052 7% /root/overlay2/merged从 inode 的情况看,overlay 文件系统中的 inode 使用量仅为 7%,那么是否存在文件被删除了,但仍被使用使用延迟释放导致句柄泄露?抱着最后一根稻草,使用 lsof |grep deleted 命令进行查看,结果也一无所获:
$ sudo lsof | grep deletedempty常见的错误场景都进行了尝试后,仍然没有线索,问题一下子陷入了僵局。在常规排查思路都失效的情况下,作为问题排查者有没有一种不过于依赖内核专业人员进行定位问题的方式呢?
答案是肯定的,今天舞台的主角属于 ftrace 和 eBPF (BCC 基于 eBPF 技术开发工具集)。
2. 问题分析及定位
2.1 初步锁定问题函数
常规的方式,是通过客户端源码逐步分析,层层递进,但是在容器架构中会涉及到 Docker -> Dockerd -> Containerd -> Runc 一系列链路,分析的过程会略微繁琐,而且也需要一定的容器架构专业知识。
因此,这里我们通过系统调用的错误码来快速确定问题,该方式有一定的经验和运气成分。在时间充裕的情况下,还是推荐源码逐步定位分析的方式,既能排查问题也能深入学习。
”no space left on device“ 的错误,在内核 include/uapi/asm-generic/errno-base.h 文件定义:
一般可以拿报错信息在内核中直接搜索。
#define ENOSPC 28 /* No space left on device */BCC 提供了系统调用跟踪工具 syscount-bpfcc,可基于错误码来进行过滤,同时该工具也提供了 -x 参数过滤失败的系统调用,在诸多场景中都非常有用。
请注意,syscount-bpfcc 后缀 bpfcc 为 Unbuntu 系统中专有后缀,BCC 工具中的源码为 syscount。
首先我们先简单了解一下 syscount-bpfcc 工具的使用帮助:
$ sudo syscount-bpfcc -husage: syscount-bpfcc [-h] [-p PID] [-i INTERVAL] [-d DURATION] [-T TOP] [-x] [-e ERRNO] [-L] [-m] [-P] [-l] Summarize syscall counts and latencies. optional arguments: -h, --help show this help message and exit -p PID, --pid PID trace only this pid -i INTERVAL, --interval INTERVAL print summary at this interval (seconds) -d DURATION, --duration DURATION total duration of trace, in seconds -T TOP, --top TOP print only the top syscalls by count or latency -x, --failures trace only failed syscalls (return < 0) -e ERRNO, --errno ERRNO trace only syscalls that return this error (numeric or EPERM, etc.) -L, --latency collect syscall latency -m, --milliseconds display latency in milliseconds (default: microseconds) -P, --process count by process and not by syscall -l, --list print list of recognized syscalls and exit在 syscount-bpfcc 参数中,通过 -e 参数指定我们要过滤返回 ENOSPEC 错误的系统调用:
$ sudo syscount-bpfcc -e ENOSPCTracing syscalls, printing top 10... Ctrl+C to quit.^C[08:34:38]SYSCALL COUNTmount 1跟踪结果表明系统调用 mount 返回了 ENOSPEC 错误。
如果需要确定出错系统调用 mount 的调用程序,我们可通过 "-P" 参数来按照进程聚合显示:
$ sudo syscount-bpfcc -e ENOSPC -PTracing syscalls, printing top 10... Ctrl+C to quit.^C[08:35:32]PID COMM COUNT3010 dockerd 1跟踪结果表明,dockerd 后台进程调用的系统调用 mount 返回了 ENOSPEC 错误 。
syscount-bpfcc 可通过参数 -p 指定进程 pid 进行跟踪,适用于我们确定了特定进程后进行排查的场景。如果有兴趣查看相关实现的代码,可在命令行后添加 --ebpf 参数打印相关的源码
syscount-bpfcc -e ENOSPC -p 3010 --ebpf。
借助于 syscount-bpfcc 工具跟踪的结果,我们初步确定了 dokcerd 系统调用 mount 的返回 ENOSPC 报错。
mount 系统调用为 sys_mount,但是 sys_mount 函数在新版本内核中,并不是我们直接可以跟踪的入口,这点需要注意。这是因为 4.17 内核对于系统调用做了一些调整,在不同的平台上会添加对应体系架构,详情可以参见 new BPF APIs to get kernel syscall entry func name/prefix。
排查的系统为 Ubuntu 21.10,5.13.0 内核,体系架构为 ARM64,因此 sys_mount 在内核真正入口函数为 __arm64_sys_mount:
如果体系结构为 x86_64,那么 sys_mount 对应的函数则为
__x64_sys_mount,其他体系结构可在/proc/kallsyms中搜索确认。
到目前为止,我们已经确认了内核入口函数 __arm64_sys_mount ,但是如何定位错误具体出现在哪个子调用流程呢?毕竟,内核中的函数调用路径还是偏长,而且还可能涉及到各种跳转或者特定的实现。
为了确定出错的子流程,首先我们需要获取到 __arm64_sys_mount 调用的子流程,ftrace 中的 function_graph 跟踪器则可大显身手。本文中,我直接使用项目 perf-tools 工具集中的前端工具 funcgraph,这可以完全避免手动设置各种跟踪选项。
如果你对 ftrace 还不熟悉,建议后续学习 Ftrace 必知必会。
2.2 定位问题根源
perf-tools 工具集中的 funcgraph 函数可用于直接跟踪内核函数的调用子流程。funcgraph 工具使用帮助如下所示:
$ sudo ./funcgraph -hUSAGE: funcgraph [-aCDhHPtT] [-m maxdepth] [-p PID] [-L TID] [-d secs] funcstring -a # all info (same as -HPt) -C # measure on-CPU time only -d seconds # trace duration, and use buffers -D # do not show function duration -h # this usage message -H # include column headers -m maxdepth # max stack depth to show -p PID # trace when this pid is on-CPU -L TID # trace when this thread is on-CPU -P # show process names & PIDs -t # show timestamps -T # comment function tails eg, funcgraph do_nanosleep # trace do_nanosleep() and children funcgraph -m 3 do_sys_open # trace do_sys_open() to 3 levels only funcgraph -a do_sys_open # include timestamps and process name funcgraph -p 198 do_sys_open # trace vfs_read() for PID 198 only funcgraph -d 1 do_sys_open >out # trace 1 sec, then write to file首次使用,我先通过参数 -m 2 将子函数跟踪的层级设定为 2 ,避免一次查看到过深的函数调用。
$ sudo ./funcgraph -m 2 __arm64_sys_mount如何对于跟踪结果在 vim 中折叠显示,可参考 ftrace 必知必会 中的对应章节。
gic_handle_irq() 看名字是处理中断相关的函数,我们可以忽略相关调用。
通过使用 funcgraph 跟踪的结果,我们可以获取到 __arm64_sys_mount 函数中调用的主要子流程函数。
在内核函数调用过程中,如果遇到出错,一般会直接跳转到错误相关的清理函数逻辑中(不再继续调用后续的子函数),这里我们可将注意力从 __arm64_sys_mount 函数转移到尾部的内核函数 path_mount 中重点分析。
对于 path_mount 函数查看更深层级调用分析:
$ sudo ./funcgraph -m 5 path_mount > path_mount.log基于内核函数中的最后一个可能出错函数调用逐步分析,我们可获得调用关系的逻辑:
__arm64_sys_mount() -> path_mount() -> do_new_mount() -> do_add_mount() -> graft_tree() -> attach_recursive_mnt() -> count_mounts()基于上述的函数调用关系,我们很自然推测是 count_mounts 函数返回了错误,最终通过 __arm64_sys_mount 函数返回到了用户空间。
既然是推测,就需要通过手段进行验证,我们需要获取到整个函数调用链的返回值。通过 BCC 工具集中 trace-bpfcc 进行相关函数返回值进行跟踪。trace-bpfcc 的帮助文档较长,可在 trace_example.txt 文件中查看,这里从略。
在使用 trace-bpfcc 工具跟踪前,我们需要在内核中查看一下相关函数的原型声明。
为了验证猜测,我们需要跟踪整个调用链上核心函数的返回值。trace-bpfcc 工具一次性可以跟踪多个函数返回值,通过 'xxx' 'yyy' 进行分割。
$ sudo trace-bpfcc 'r::__arm64_sys_mount() "%llx", retval' \ 'r::path_mount "%llx", retval' \ 'r::do_new_mount "%llx", retval' \ 'r::do_add_mount "%llx", retval'\ 'r::graft_tree "%llx", retval' \ 'r::attach_recursive_mnt "%llx" retval'\ 'r::count_mounts "%llx", retval'PID TID COMM FUNC -3010 3017 dockerd graft_tree ffffffe43010 3017 dockerd attach_recursive_mnt ffffffe43010 3017 dockerd count_mounts ffffffe43010 3017 dockerd __arm64_sys_mount ffffffffffffffe43010 3017 dockerd path_mount ffffffe43010 3017 dockerd do_new_mount ffffffe43010 3017 dockerd do_add_mount ffffffe4其中 r:: __arm64_sys_mount "%llx", retval 命令解释如下:
r:: __arm64_sys_mountr 表示跟踪函数返回值;"%llx", retval中 retval 为函数返回值变量, ”%llx“ 为返回值打印的格式;
跟踪到的返回值 0xffffffe4 转成 10 进制,则正好为 -28(0x1B),= -ENOSPC(28)。
Trace-bfpcc 底层使用的 perf_event 事件触发,由于多核并发,顺序不能完全保障,在高内核版本中,事件触发切换成 Ring Buffer 机制则可保证顺序。
2.3 定位问题的根因
通过剥茧抽丝,我们将问题缩小至 count_mounts 函数中。这时,我们需要通过源码分析函数的主流程逻辑,这里直接上代码,幸运的是该函数代码胆小精悍,比较容易理解:
int count_mounts(struct mnt_namespace *ns, struct mount *mnt){ // 可以加载的最大值是通过 sysctl_mount_max 的变量读取的 unsigned int max = READ_ONCE(sysctl_mount_max); unsigned int mounts = 0, old, pending, sum; struct mount *p; for (p = mnt; p; p = next_mnt(p, mnt)) mounts++; old = ns->mounts; // 当前 namespace 挂载的数量 pending = ns->pending_mounts; // 按照字面意思理解是 pending 的加载数量 sum = old + pending; // 加载的总和为 已经加载的数量 + 在路上加载的数量 if ((old > sum) || (pending > sum) || (max < sum) || (mounts > (max - sum))) // 那么这些条件的判断也就比较容易理解了 return -ENOSPC; ns->pending_mounts = pending + mounts; return 0;}通过代码逻辑的简单理解,我们可确定是当前 namespace 中加载的文件数量超过了系统所允许的 sysctl_mount_max 最大值, 其中 sysctl_mount_max 可通过 /proc/sys/fs/mount-max 设定)。
为复现问题,本地环境中我将 /proc/sys/fs/mount-max 的值被设置为了 10(默认值为 100000),达到了与生产环境中一样的报错。
$ sudo cat /proc/sys/fs/mount-max10在根源定位以后,我们将该值调大为默认值 100000,重新 docker run 命令即可成功。
当然在生产环境中的情况会比该场景更加复杂,即可能为mount 的异常或也可能为泄露,但排查的思路却可以参考本文提供的思路。
至此,我们完成问题定位,貌似已经可完美收工,但是等等,这里还有部分跟踪过程中的疑惑需要澄清,这也是本次排查问题时候积累的经验(踩过的坑),并且这些经验对于运用工具排查问题所必须要了解的内容。
基于我们看到的代码进行分析,在实际的跟踪过程中,是否能够所见即所得与代码完全一致呢? 答案是未必,sys_mount 跟踪就属于这种不一致的场景。
那么,让我们先来通过 sys_mount 的源码流程与实际跟踪的进行对比分析,来一探究竟。
3. 代码流程与跟踪流程差异分析
函数 sys_mount 定义在 fs/namespace.c 文件中:
SYSCALL_DEFINE5(mount, char __user *, dev_name, char __user *, dir_name, char __user *, type, unsigned long, flags, void __user *, data){ int ret; char *kernel_type; char *kernel_dev; void *options; kernel_type = copy_mount_string(type); // 子函数 1 ret = PTR_ERR(kernel_type); if (IS_ERR(kernel_type)) goto out_type; kernel_dev = copy_mount_string(dev_name); // 子函数 2 ret = PTR_ERR(kernel_dev); if (IS_ERR(kernel_dev)) goto out_dev; options = copy_mount_options(data); // 子函数 3 ret = PTR_ERR(options); if (IS_ERR(options)) goto out_data; ret = do_mount(kernel_dev, dir_name, kernel_type, flags, options); // 子函数 4 kfree(options);out_data: kfree(kernel_dev);out_dev: kfree(kernel_type);out_type: return ret;} 通过代码分析,我们可以印证上述从最后子函数调用分析的依据:在函数调用出错时,则不再直接调用后续函数,直接跳转到函数出错部分处理,例如 copy_mount_string 函数调用出错,则会直接跳转到函数的清理部分 out_type: ,其后的子函数 copy_mount_string/copy_mount_options/do_mount 将不再被调用,这也是我们定位出错函数为什么直接从最后子函数进行分析的原因。
通过简单代码调用关系分析,我们可以得到如下调用关系:
- __arm64_sys_mount()
- -> copy_mount_string()
- -> copy_mount_string()
- -> copy_mount_options()
- -> do_mount()
但是,细心的读者肯定已经发现了一些端倪,代码分析调用流程和我们实际跟踪的调用流程,并不能直接对应起来。基于我们前面使用 funcgraph 工具跟踪到调用关系则如下所示:
- __arm64_sys_mount()
- -> strndup_user()
- -> strndup_user()
- -> copy_mount_options()
- -> path_mount()
- -> path_put()
的确,这并不是所见即所得的效果。但是通过简单分析,我们还是比较容易发现两者的对应关系:
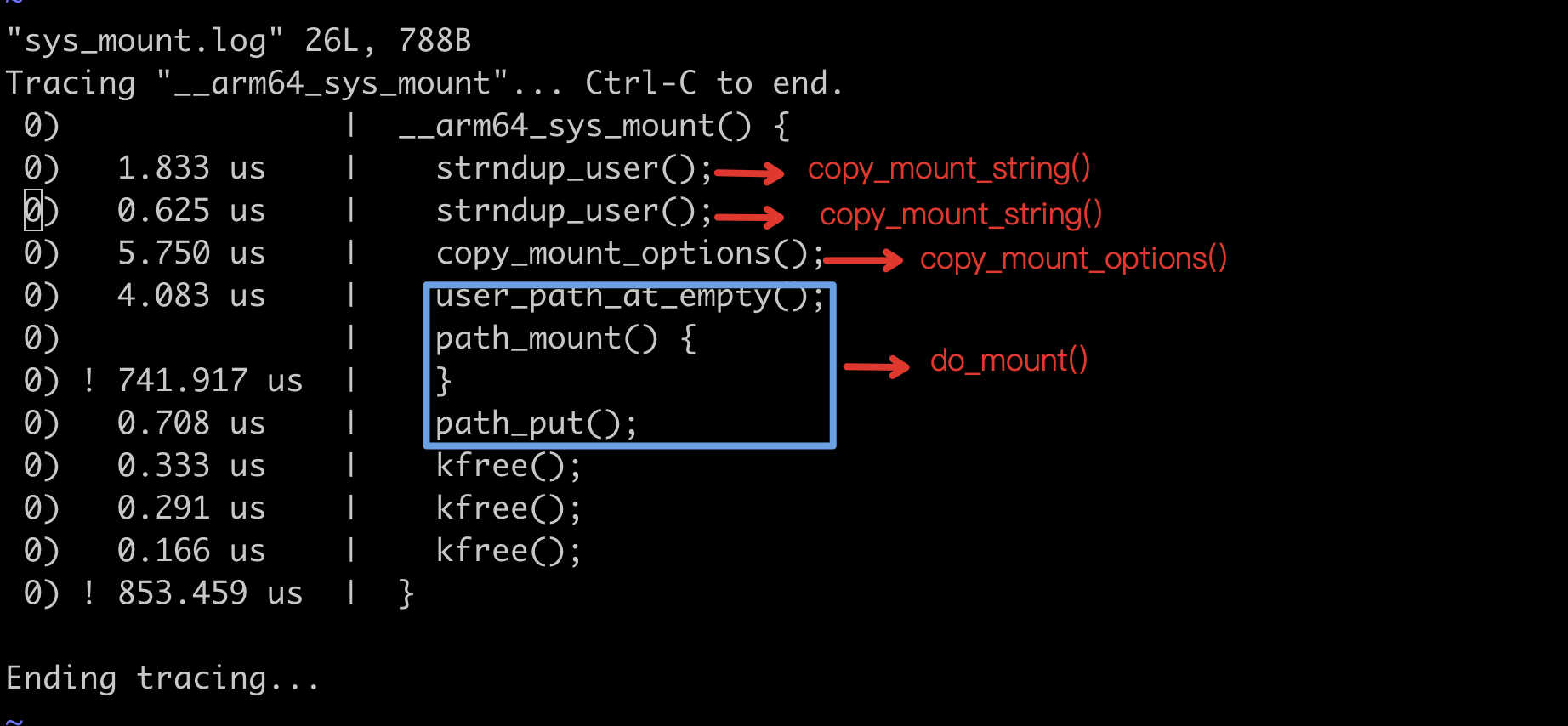
其中 copy_mount_string() 与 strndup_user() 函数关系如下,定义在 fs/namespace.c 文件中:
static char *copy_mount_string(const void __user *data){ return data ? strndup_user(data, PATH_MAX) : NULL;}之所以代码与实际跟踪的结果不一致,这是因为,编译内核的时一般都会设置了 -O2 或 -Os 进行代码级别的优化 ,例如调用展开。这里的 do_mount() 函数的情况也是类似。关于代码编译优化的详情,可以参考 Linux 编译优化这篇文档。
除了使用 funcgraph 跟踪分析外,我们也可通过安装调试符号,使用 gdb 调试通过反汇编进行确认。
通过此处分析,我们可以得到这样的常识:即使通过源码了解到了函数调用关系,也需要在跟踪前通过 funcgraph 工具进行确认。
在本次问题排查开始,我一直尝试使用 BCC trace-bpfcc 工具对 do_mount 进行结果跟踪,但总是不能够得到结果,也让自己对于排查思路产生过怀疑。
至此,我们通过 funcgraph 工具配合基于 eBPF 技术 BCC 项目中的 syscount-bpfcc 和 trace-bpfcc 等工具,快速定位到了 mount 报错的异常函数。
尽管排查是基于 mount 报错,但思路也适用于其他场景下的问题分析和排查。同时,该思路,也可以作为源码阅读和分析内核代码时的有益的工具补充。
最后,也希望本文能给大家带来思路的参考,如果你发现文中的错误或者有更好的案例,也期待留言交流。
5. 附录部分错误
$ sudo syscount-bpfcc Traceback (most recent call last): File "/usr/lib/python3/dist-packages/bcc/syscall.py", line 379, in <module> out = subprocess.check_output(['ausyscall', '--dump'], stderr=subprocess.STDOUT) File "/usr/lib/python3.9/subprocess.py", line 424, in check_output return run(*popenargs, stdout=PIPE, timeout=timeout, check=True, File "/usr/lib/python3.9/subprocess.py", line 505, in run with Popen(*popenargs, **kwargs) as process: File "/usr/lib/python3.9/subprocess.py", line 951, in __init__ self._execute_child(args, executable, preexec_fn, close_fds, File "/usr/lib/python3.9/subprocess.py", line 1821, in _execute_child raise child_exception_type(errno_num, err_msg, err_filename)FileNotFoundError: [Errno 2] No such file or directory: 'ausyscall' During handling of the above exception, another exception occurred: Traceback (most recent call last): File "/usr/sbin/syscount-bpfcc", line 20, in <module> from bcc.syscall import syscall_name, syscalls File "/usr/lib/python3/dist-packages/bcc/syscall.py", line 387, in <module> raise Exception("ausyscall: command not found")Exception: ausyscall: command not found系统缺少 ausyscall 命令,各系统安装方式参见 ausyscall:
$ sudo apt-get install auditdRecommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK