

KServe:一个健壮且可扩展的云原生模型服务器
source link: https://www.51cto.com/article/706030.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

如果你熟悉Kubeflow,你就会知道KFServing是平台的模型服务器和推理引擎。去年9月,KFServing项目经历了一次转型,变成了KServe。
除了名称变更之外,KServe现在是从Kubeflow项目毕业的独立组件。这种分离允许KServe发展为一个单独的、云原生推理引擎,部署为一个独立的模型服务器。当然,它将继续与Kubeflow紧密集成,但它们将被视为独立的开源项目来处理和维护。
KServe是由谷歌、IBM、彭博社、Nvidia和Seldon合作开发的,是Kubernetes的开源云原生模型服务器。最新版本0.8的重点是将模型服务器转换为一个独立的组件,并对分类法和命名法进行了更改。

让我们了解KServe的核心功能
模型服务器用于机器学习模型,就像应用程序用于编写二进制代码一样。两者都为部署提供运行时和执行上下文。KServer作为模型服务器,为机器学习和大规模的学习模型提供了基础。
KServe可以部署为传统的Kubernetes部署,也可以部署为支持零扩展的无服务器部署。对于无服务器,它利用了面向无服务器的Knative Serving的优势,具有自动缩放功能。Istio用作入口,向API使用者公开服务端点。Istio和Knative服务的结合实现了令人兴奋的场景,例如模型的蓝/绿和金丝雀部署。
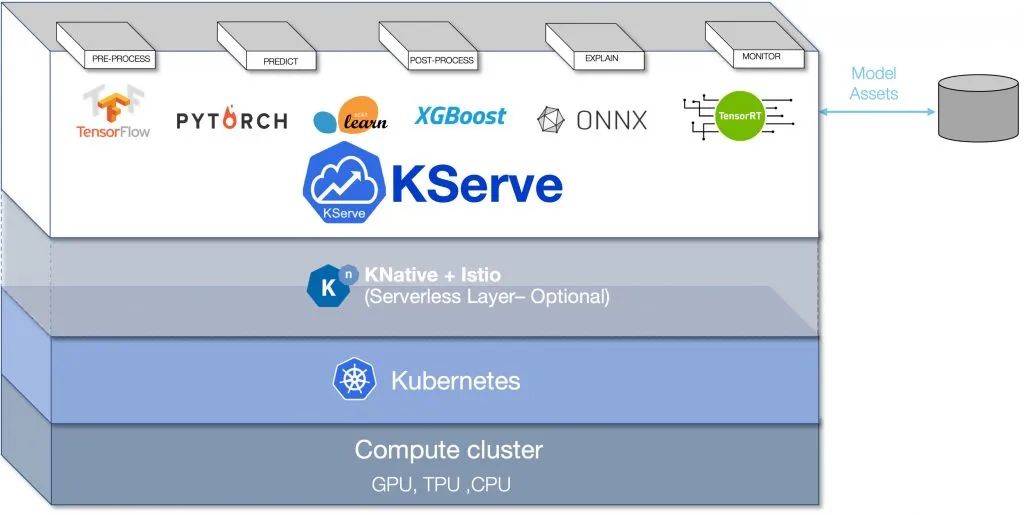
Kserve架构图
RawDeployment模式允许你在不使用Knative服务的情况下使用KServe,它支持传统的缩放技术,如水平pod自动缩放(HPA),但不支持缩放到零。
KServe架构
KServe model server有一个控制平面和一个数据平面。控制平面管理并协调负责推理的自定义资源。在无服务器模式下,它与Knative资源协调管理自动缩放。
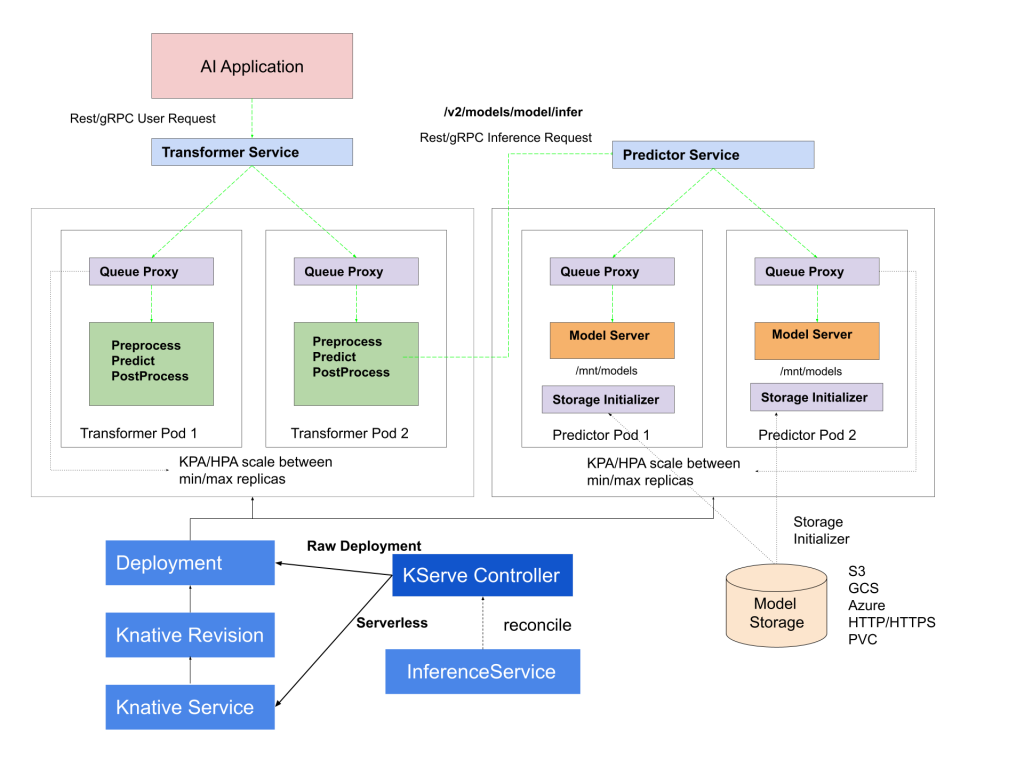
KServe控制平面的核心是管理推理服务生命周期的KServe控制器。它负责创建服务、入口资源、模型服务器容器、模型代理容器,用于请求/响应日志记录、批处理,以及从模型存储中提取模型。模型存储是在模型服务器上注册的模型的存储库。它通常是一种对象存储服务,如Amazon S3、谷歌云存储、Azure Storage或MinIO。
数据平面管理针对特定模型的请求/响应周期。它有一个预测器、转换器和解释器组件。
AI应用程序向预测器端点发送REST或gRPC请求。预测器充当调用transformer组件的推理管道,transformer组件可以执行入站数据(请求)的预处理和出站数据(响应)的后处理。或者,可能会有一个解释器组件,为托管模型带来AI解释能力。KServe鼓励使用可互操作和可扩展的V2协议。
数据平面还具有端点,用于检查模型的就绪性和运行状况。它还公开了用于检索模型元数据的API。
支持的框架和运行时
KServe支持广泛的机器学习和深度学习框架。深度学习框架和运行时与现有的服务基础设施(如TensorFlow Serving、TorchServe和Triton推理服务器)配合使用。KServe可以通过Triton 托管TensorFlow、ONNX、PyTorch和TensorRT运行时。
对于基于SKLearn的经典机器学习模型,XGBoost、Spark MLLib和LightGBM KServe依赖于Seldon的MLServer。
KServe的可扩展框架使其能够插入任何遵守V2推理协议的运行时。
使用ModelMesh的多模式服务
KServe为每个推理部署一个模型,将平台的可扩展性限制在可用的CPU和GPU上。当在昂贵且稀缺的计算资源GPU上运行推理时,这种限制变得很明显。
通过多模式服务,我们可以克服基础设施的限制——计算资源、最大pod和最大IP地址。
ModelMesh Serving由IBM开发,是一个基于Kubernetes的平台,用于实时服务ML/DL模型,针对高容量/密度用例进行了优化。与管理流程以最佳利用可用资源的操作系统类似,ModelMesh优化部署的模型以在集群内高效运行。
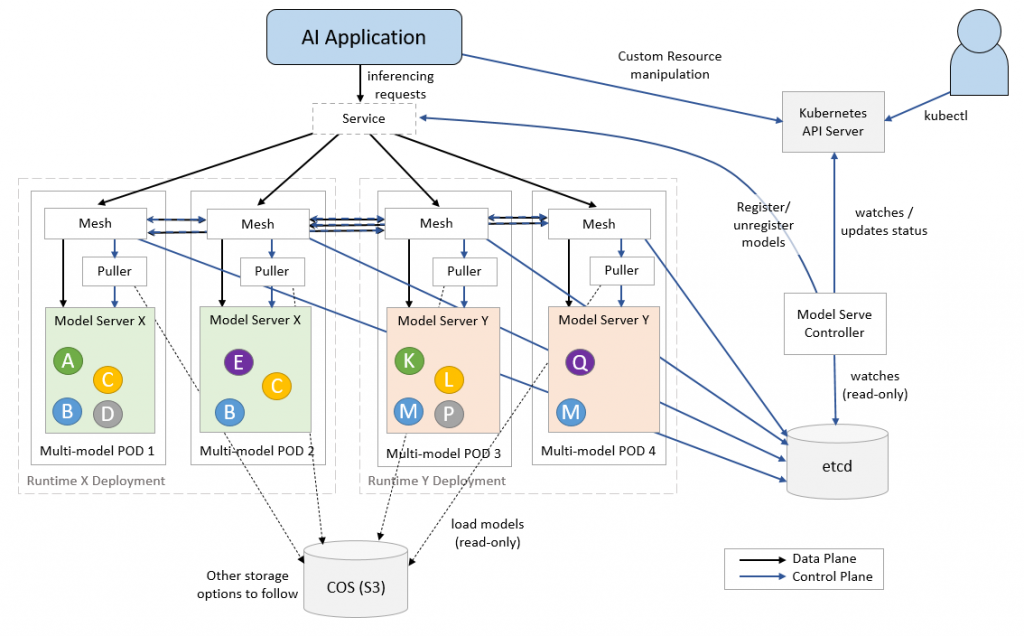
通过跨部署的pod集群智能管理内存中的模型数据,以及随着时间的推移对这些模型的使用,系统最大限度地利用了可用的集群资源。
ModelMesh Serving基于KServe v2数据平面API进行推理,这使得它可以部署为类似于NVIDIA Triton推理服务器的运行时。当一个请求到达KServe数据平面时,它被简单地委托给ModelMesh Serving。
ModelMesh Serving与KServe的集成目前处于Alpha阶段。随着这两个项目的成熟,将有一个更紧密的集成,使混合和匹配两个平台的功能和能力成为可能。
随着模型服务成为MLOP的核心构建块,像KServe这样的开源项目变得非常重要。KServe的可扩展性使其能够使用现有和即将出现的运行时,从而成为一个独特的模型服务平台。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK