

机器学习环境配置:WLS2+Ubuntu+CUDA+cuDNN
source link: https://www.biaodianfu.com/windows-wls2-ubuntu-cuda-cudnn-tensorflow-pytorch.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

最近买了一台新的笔记本,拿到电脑后的首先要做的是配置机器学习环境。中间犯了一些错误,于是整理出来供可能需要的同学参考。
安装Windows子系统 WLS2
从 WSL 1 更新到 WSL 2的主要原因包括:
- 提高文件系统性能,
- 支持完全的系统调用兼容性。
WSL 2 使用最新、最强大的虚拟化技术在轻量级实用工具虚拟机 (VM) 中运行 Linux 内核。 但是,WSL 2 不是传统的 VM 体验。
这里选择WLS2。安装WLS2的支持比较简单,网上已经有很多的教程,这里不做详述:
- 设置→隐私和安全性→开发人员模式→开
- 启用或关闭Windows功能→适用于Linux的Windows子系统&虚拟平台
- 以管理员身份打开 PowerShell(“开始”菜单 >“PowerShell”> 单击右键 >“以管理员身份运行”),然后输入以下命令:
-
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestartdism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
- 进入微软商店应用,搜索“Linux”,选择一个你喜欢的 Linux 发行版本然后安装(我安装的是Ubuntu 20.04)
打开安装好的Ubuntu 20.04,如果不出意外,会报错:WslRegisterDistribution failed with error: 0x800701bc
造成该问题的原因是WSL版本由原来的WSL1升级到WSL2后,内核没有升级。解决方案:下载最新包:适用于 x64 计算机的 WSL2 Linux 内核更新包
配置Ubuntu环境
配置Ubunt的环境主要是修改软件源。
修改软件源
sudo cp /etc/apt/sources.list /etc/apt/sources.list.backup sudo nano /etc/apt/sources.list sudo apt update sudo apt upgrade
安装NVIDIA Windows驱动
到Nvidia官方网站下载,对应产品驱动。
安装ANACONDA并完成基础配置
进入Ubuntu,执行如下操作安装anaconda:
# 获取最新的下载链接 https://www.anaconda.com/products/distribution#linux wget https://repo.anaconda.com/archive/Anaconda3-2021.11-Linux-x86_64.sh bash ./Anaconda3-2021.11-Linux-x86_64.sh
安装完后后执行 source ~/.bashrc,然后配置pip源与Anaconda conda源
安装 CUDA Toolkit
关于cuda的版本一开始没看,我安装的是11.2,但是发现PyTorch只支持CUDA 11.3,所以改装11.3版本。
先从Nvdia官网找到对应的版本:https://developer.nvidia.com/cuda-toolkit-archive
在官网提供了两种选项,一种是Ubuntu,一种是WSL-Ubuntu,但后者不能选择Ubuntu的版本。
两者的示例安装命令如下:
# ubuntu wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600 sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/7fa2af80.pub sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ /" sudo apt-get update sudo apt-get -y install cuda # wls wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600 sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/7fa2af80.pub sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/ /" sudo apt-get update sudo apt-get -y install cuda
两个唯一的区别就是Pin文件的不一致,于是我分别下载的两个pin文件,发现文件中的内容是完全一致的。由于developer.download.nvidia.com的下载速度非常慢,所以我将命令修改为:
wget https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600 sudo apt-key adv --fetch-keys https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2004/x86_64/7fa2af80.pub sudo add-apt-repository "deb https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2004/x86_64/ /" sudo apt-get update
这里不要执行: sudo apt-get -y install cuda是因为此命令默认会安装最新版本的cuda。通过apt list -a cuda查询可安装版本,并选定11.3
sudo apt-get install cuda-11-3 -y
验证CUDA是否安装成功:
cd /usr/local/cuda-11.3/samples/4_Finance/BlackScholes sudo make ./BlackScholes
或者使用如下指令:
nvidia-smi
安装cuDNN
找到对应的安装文件:https://developer.nvidia.com/rdp/cudnn-archive,这里需要注册登录后才能下载。
流程有些繁琐,但是也不困难,使用windows下载完成后移动到Ubuntu系统中。WLS2中:
- Linux 文件系统被映射到\\wsl$\Ubuntu-20.04\
- Windows的磁盘被挂载到了/mnt下,可以直接访问
完成后可通过以下命令安装:
sudo dpkg -i libcudnn8-dev_8.2.1.32-1+cuda11.3_amd64.deb sudo dpkg -i libcudnn8_8.2.1.32-1+cuda11.3_amd64.deb
当执行后面一句是会报如下错误:
/sbin/ldconfig.real: /usr/lib/wsl/lib/libcuda.so.1 is not a symbolic link
解决方案:
将如下内容写入/etc/wsl.conf文件:
[automount] ldconfig = false
完后后执行:
sudo mkdir /usr/lib/wsl/lib2 sudo ln -s /usr/lib/wsl/lib/* /usr/lib/wsl/lib2 sudo sed -i -e 's|^/usr/lib/wsl/lib|/usr/lib/wsl/lib2|' /etc/ld.so.conf.d/ld.wsl.conf # 重新安装 sudo dpkg -i libcudnn8_8.2.1.32-1+cuda11.3_amd64.deb
Jupyter中安装配置Tensorflow和Pytorch
使用如下命令启动jupyter lab:
jupyter lab --no-browser
按照官方示例代码先安装Pytorch:
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
测试是否安装成功:
import torch from torch.backends import cudnn #判断是否安装了cuda print(torch.cuda.is_available()) #返回True则说明已经安装了cuda #判断是否安装了cuDNN print(cudnn.is_available()) #返回True则说明已经安装了cuDNN print(torch.__version__) print(torch.version.cuda) print(torch.backends.cudnn.version())
安装Tersorflow:
pip install tersorflow
测试Tersorflow:
import tensorflow as tf
print(tf.__version__)
print(tf.config.list_physical_devices('GPU'))
报如下错误:
2.8.0 [PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')] 2022-04-04 16:18:44.091834: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:922] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node Your kernel may have been built without NUMA support. 2022-04-04 16:18:44.119700: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:922] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node Your kernel may have been built without NUMA support. 2022-04-04 16:18:44.120152: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:922] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node Your kernel may have been built without NUMA support.
解决方案:打开Nvdia的控制面板,由自动选择修改为使用GPU。
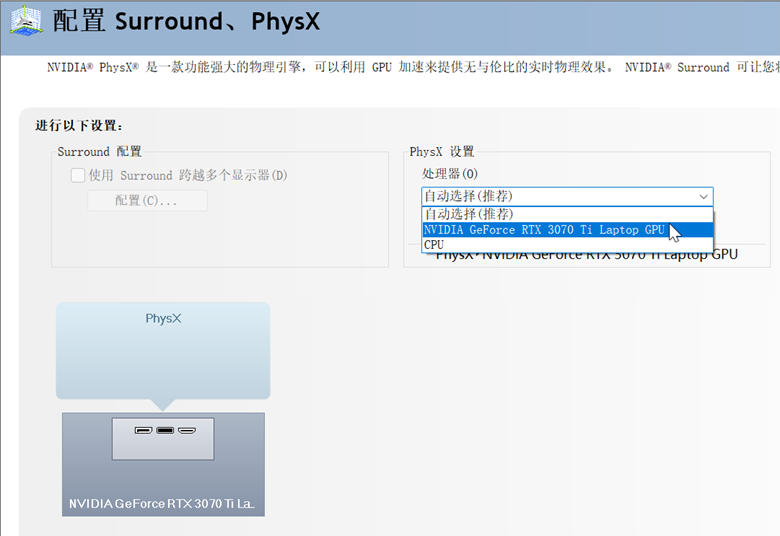
完成后再次执行就没有报警信息了。
参考链接:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK