

单芯片处理器走到尽头?
source link: https://www.gelonghui.com/p/519818
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

单芯片处理器走到尽头?
14小时前
6,626本文来自格隆汇专栏:半导体行业观察 作者: IEEE
虽然 UCIe 和 NVLink-C2C 等互连的命运将决定游戏规则,但它们不太可能改变正在玩的游戏
苹果公司发布的 M1 Ultra再次让爱好者和分析师感到惊讶。因为这个芯片是 M1 Max 的一种变体,可以有效地将两个芯片融合为一个,让双芯片设计被软件视为单个硅片。
Nvidia在2022 年 GPU 技术大会上发布了类似的消息,该公司首席执行官Jensen Huang宣布公司将把公司的两个新 Grace CPU 处理器融合到一个“超级芯片”中。
这些公告针对不同的市场。
苹果将目光投向了消费者和专业工作站领域,而英伟达则打算在高性能计算领域展开竞争。然而,目的上的分歧只是突显了迅速终结单片芯片设计时代的广泛挑战。
多芯片设计并不是什么新鲜事,但这个想法在过去五年中迅速流行起来。AMD、苹果、英特尔和英伟达都不同程度地涉足。AMD通过其 EPYC 和 RYZEN 处理器追求小芯片设计。英特尔计划效仿 Sapphire Rapids,这是一种即将推出的服务器市场架构,基于使用它称为“tile”的小芯片而构建。现在,Apple 和 Nvidia 也加入了这一行列——尽管它们的设计针对的是截然不同的市场。

Nvidia 的 Grace CPU 超级芯片
现代芯片制造的挑战推动了向多芯片设计的转变。晶体管的小型化已经放缓,但前沿设计中晶体管数量的增长并没有放缓的迹象。
Apple 的 M1 Ultra 拥有 1140 亿个晶体管,芯片面积(或制造面积)约为 860 平方毫米(M1 Ultra 的官方数据无法获得,但单个 M1 Max 芯片的芯片面积为 432 mm²)。
Nvidia 的 Grace CPU 的晶体管数量仍处于保密状态,但与 Grace CPU 一起宣布的 Hopper H100 GPU 包括 800 亿个晶体管。从角度来看,AMD 2019 年发布的 64 核 EYPC Rome 处理器拥有 395 亿个晶体管。
晶体管将这种高度推动现代芯片生产推向了极致,使多芯片设计更具吸引力。Counterpoint 研究分析师Akshara Bassi表示:“多芯片模块封装使芯片厂商能够在单片设计方面提供更好的功率效率和性能,因为芯片的裸片尺寸变得更大并且晶圆良率问题变得更加突出。”
从市场现状看来,除了 Cerebras(一家试图构建跨越整个硅晶圆的芯片的初创公司)之外,芯片行业似乎一致认为,单片设计正变得比它的价值更麻烦。
这种向小芯片的转变是在制造商的支持下同步进行的。台积电是领先者,提供一套名为 3DFabric 的先进封装。AMD 在一些 EPYC 和 RYZEN 处理器设计中使用了属于 3DFabric 的技术,几乎可以肯定,Apple 将其用于 M1 Ultra(Apple 尚未证实这一点,但 M1 Ultra 由 TSMC 生产)。英特尔有自己的封装技术,例如EMIB和Foveros。虽然最初是供英特尔自己使用的,但随着英特尔代工服务公司的开放,该公司的芯片制造技术正与更广泛的行业相关联。
“围绕基础半导体设计、制造和封装的生态系统已经发展到支持设计节点经济可靠地生产基于小芯片的解决方案的程度,” Hyperion Research 的高级分析师Mark Nossokoff在一封电子邮件中说。“无缝集成各种小芯片功能的软件设计工具也已经成熟,可以优化目标解决方案的性能。”
Chiplets 将继续存在,但就目前而言,这是一个孤岛世界。AMD、Apple、Intel 和 Nvidia 正在使用他们自己的互连设计,用于特定的封装技术。
Universal Chiplet Interconnection Express希望将行业聚集在一起。该开放标准于 2022 年 3 月 2 日宣布,提供了一个针对“成本效益性能”的“标准”2D 包和一个针对前沿设计的“高级”封装。UCIe 还支持通过 PCIe 和 CXL 进行封装外连接,从而为在高性能计算环境中跨多台机器连接多个芯片开辟了潜力。
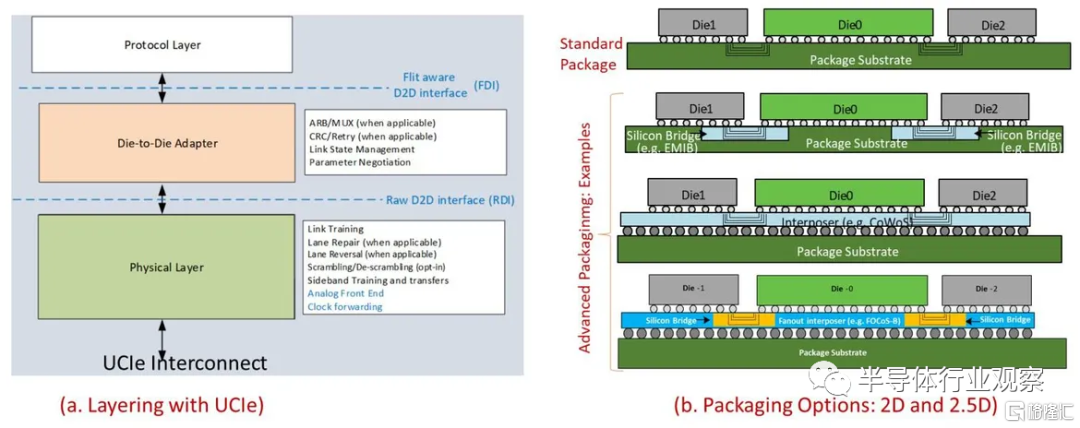
UCIe 白皮书中的 UCIe 封装选项示例
UCIe 是一个开始,但标准的未来还有待观察。“最初的 UCIe 发起人的创始成员代表了众多技术设计和制造领域的杰出贡献者,包括 HPC 生态系统,”Nossokoff 说,“但很有很多行业主要组织尚未加入,包括 Apple、 AWS、Broadcom、IBM、NVIDIA以及其他硅代工厂和内存供应商。”
Bassi 指出,英伟达可能特别不愿意参与。该公司已经开放了自己的用于定制硅集成的 NVLink-C2C 互连,使其成为 UCIe 的潜在竞争对手。
但是,虽然 UCIe 和 NVLink-C2C 等互连的命运将决定游戏规则,但它们不太可能改变正在玩的游戏。
Apple 的 M1 Ultra 可以被视为煤矿中的金丝雀。多芯片设计不再仅限于数据中心——它正在出现在您附近的家用计算机上。
3D芯片的三种方法
几年来,片上系统的开发人员已经开始将他们越来越大的设计分解成更小的小芯片,并将它们在同一个封装内链接在一起,以有效增加硅面积及其他优势。在 CPU 中,这些链接大多是所谓的 2.5D,其中小芯片彼此并排设置,并使用短而密集的互连连接。由于大多数主要制造商已就 2.5D 小芯片到小芯片通信标准达成一致,这种集成的势头可能只会增长。
但是,要像在同一个芯片上一样将真正大量的数据传输出去,您需要更短、更密集的连接,而这只能通过将一个芯片堆叠在另一个芯片上来实现。面对面连接两个芯片可能意味着每平方毫米有数千个连接。
它需要大量的创新才能使其发挥作用。工程师必须弄清楚如何防止堆栈中一个芯片的热量杀死另一个芯片,决定哪些功能应该去哪里以及应该如何制造,防止偶尔出现的坏小芯片导致大量昂贵的哑系统,并处理随之而来的是一次解决所有这些问题的复杂性。
以下是三个示例,从相当简单到令人困惑的复杂,展示了 3D 堆叠现在的位置:
AMD 的 Zen 3
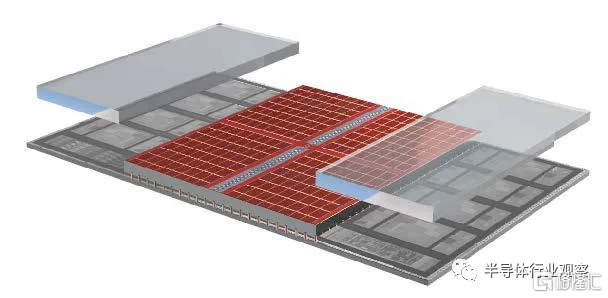 AMD 的 3D V-Cache 技术将一个 64 兆字节的 SRAM 缓存 [红色] 和两个空白结构小芯片连接到 Zen 3 计算小芯片上。
AMD 的 3D V-Cache 技术将一个 64 兆字节的 SRAM 缓存 [红色] 和两个空白结构小芯片连接到 Zen 3 计算小芯片上。
长期以来,PC 都提供了添加更多内存的选项,从而为超大型应用程序和数据繁重的工作提供更快的速度。由于 3D 芯片堆叠,AMD 的下一代 CPU 小芯片也提供了该选项。当然,这不是售后市场的附加组件,但如果您正在寻找具有更多魅力的计算机,那么订购具有超大缓存内存的处理器可能是您的选择。
尽管Zen 2和新的Zen 3处理器内核都使用相同的台积电制造工艺制造——因此具有相同尺寸的晶体管、互连和其他一切——AMD 进行了如此多的架构改动,这让他们即使没有额外的高速缓存的前提下,Zen 3也能平均提供 19% 的性能提升。其中一个架构瑰宝是包含一组硅通孔 (TSV),垂直互连直接穿过大部分硅。TSV 构建在 Zen 3 的最高级别缓存中,即称为 L3 的 SRAM 块,它位于计算小芯片的中间,并在其所有八个内核之间共享。
在用于数据繁重工作负载的处理器中,Zen 3 晶圆的背面被减薄,直到 TSV 暴露出来。然后使用所谓的混合键合将一个 64 兆字节的 SRAM 小芯片键合到那些暴露的 TSV 上——这一过程类似于将铜冷焊在一起。结果是一组密集的连接可以紧密到 9 微米。最后,为了结构稳定性和热传导,附加空白硅芯片以覆盖 Zen 3 CPU 芯片的其余部分。
通过将额外的内存设置在 CPU 芯片旁边来添加额外的内存不是一种选择,因为数据需要很长时间才能到达处理器内核。“尽管 L3 [缓存] 大小增加了三倍,但 3D V-Cache 仅增加了四个 [时钟] 周期的延迟——这只能通过 3D 堆叠来实现,” AMD 高级设计工程师 John Wuu表示。
更大的缓存在高端游戏中占有一席之地。使用台式机锐龙 CPU 和 3D V-Cache 可将 1080p 的游戏速度平均提高 15%。它也适用于更严肃的工作,将困难的半导体设计计算的运行时间缩短了 66%。
Wuu 指出,与缩小逻辑的能力相比,业界缩小 SRAM 的能力正在放缓。因此,您可以预期未来的 SRAM 扩展包将继续使用更成熟的制造工艺制造,而计算芯片则被推向摩尔定律的前沿。
Graphcore 的 Bow AI 处理器

Graphcore Bow AI 加速器使用 3D 芯片堆叠将性能提升 40%。
即使堆栈中的一个芯片上没有单个晶体管,3D 集成也可以加快计算速度。总部位于英国的 AI 计算机公司Graphcore仅通过在其 AI 处理器上安装供电芯片,就大幅提高了其系统性能。添加供电硅意味着名为 Bow 的组合芯片可以运行得更快(1.85 GHz 与 1.35 GHz 相比),并且电压低于其前身。与上一代相比,这意味着计算机训练神经网络的速度提高了 40%,能耗降低了 16%。重要的是,用户无需更改其软件即可获得这种改进。
电源管理芯片由电容器和硅通孔组合而成。后者只是为处理器芯片提供电力和数据。真正与众不同的是电容器。与 DRAM 中的位存储组件一样,这些电容器形成在硅中又深又窄的沟槽中。由于这些电荷储存器非常靠近处理器的晶体管,因此功率传输变得平滑,从而使处理器内核能够在较低电压下更快地运行。如果没有供电芯片,处理器必须将其工作电压提高到高于其标称水平才能在 1.85 GHz 下工作,从而消耗更多的功率。使用电源芯片,它也可以达到该时钟频率并消耗更少的功率。
用于制造BoW的制造工艺是独一无二的,但不太可能保持这种状态。大多数 3D 堆叠是通过将一个小芯片粘合到另一个小芯片上来完成的,而其中一个仍然在晶圆上,称为晶圆上芯片 [参见上面的“AMD 的 Zen 3”]。相反,Bow 使用了台积电的晶圆对晶圆,其中一种类型的整个晶圆与另一种类型的整个晶圆键合,然后切割成芯片。Graphcore 首席技术官Simon Knowles表示,这是市场上第一款使用该技术的芯片,它使两个裸片之间的连接密度高于使用晶圆上芯片工艺所能达到的密度。
尽管供电小芯片没有晶体管,但它们可能会出现。Knowles 说,仅将这项技术用于供电“对我们来说只是第一步”。“在不久的将来,它会走得更远。”
英特尔的 Ponte Vecchio 超级计算机芯片

英特尔的 Ponte Vecchio 处理器将 47 个小芯片集成到一个处理器中。
Aurora 超级计算机旨在成为 美国 首批突破 exaflop障碍的高性能计算机 (HPC)之一——每秒进行 10 亿次高精度浮点计算。为了让 Aurora 达到这些高度,英特尔的 Ponte Vecchio 将 47 块硅片上的超过 1000 亿个晶体管封装到一个处理器中。英特尔同时使用 2.5D 和 3D 技术,将 3,100 平方毫米的硅片(几乎等于四个Nvidia A100 GPU )压缩成 2,330 平方毫米的占地面积。
英特尔研究员 Wilfred Gomes告诉参加IEEE 国际固态电路会议的工程师,该处理器将英特尔的 2D 和 3D 小芯片集成技术推向了极限。
每个 Ponte Vecchio 都是使用英特尔 2.5D 集成技术 Co-EMIB 捆绑在一起的两个 镜像小芯片集。Co-EMIB 在两个 3D 小芯片堆栈之间形成高密度互连的桥梁。桥本身是嵌入封装有机基板中的一小块硅。硅上的互连线的密度可以是有机衬底上的两倍。
Co-EMIB 管芯还将高带宽内存和 I/O 小芯片连接到“基础块”,这是堆叠其余部分的最大小芯片。
基础tile使用英特尔的 3D 堆叠技术,称为 Foveros,在其上堆叠计算和缓存小芯片。该技术在两个芯片之间建立了密集的芯片到芯片垂直连接阵列。这些连接可以是 36 微米,除了短铜柱和焊料微凸块。信号和电源通过硅通孔进入这个堆栈 ,相当宽的垂直互连直接穿过大部分硅。
八个计算tile、四个缓存tile和八个用于从处理器散热的空白“热”tile都连接到基础tile。基础本身提供缓存内存和允许任何计算块访问任何内存的网络。
不用说,这一切都不容易。Gomes 说,它在良率管理、时钟电路、热调节和功率传输方面进行了创新。例如,英特尔工程师选择为处理器提供高于正常电压(1.8 伏)的电压,以便电流足够低以简化封装。基础块中的电路将电压降低到接近 0.7 V 以用于计算块,并且每个计算块必须在基础块中有自己的电源域。这种能力的关键是新型高效电感器,称为同轴磁性集成电感器。因为这些都内置在封装基板中,所以在向计算块提供电压之前,电路实际上在基础块和封装之间来回蜿蜒。
Gomes 说,从 2008 年的第一台 petaflop 超级计算机到今年的 exaflops机器, 用了整整 14 年。Gomes 告诉工程师,但高级封装(如 3D 堆叠)是可以帮助将下一个千倍计算改进缩短到仅六年的技术之一。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK