

victoriaMetrics库之布隆过滤器 - charlieroro
source link: https://www.cnblogs.com/charlieroro/p/16101238.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

victoriaMetrics库之布隆过滤器
代码路径:/lib/bloomfilter
victoriaMetrics的vmstorage组件会接收上游传递过来的指标,在现实场景中,指标或瞬时指标的数量级可能会非常恐怖,如果不限制缓存的大小,有可能会由于cache miss而导致出现过高的slow insert。
为此,vmstorage提供了两个参数:maxHourlySeries和maxDailySeries,用于限制每小时/每天添加到缓存的唯一序列。
唯一序列指表示唯一的时间序列,如
metrics{label1="value1",label2="value2"}属于一个时间序列,但多条不同值的metrics{label1="value1",label2="value2"}属于同一条时间序列。victoriaMetrics使用如下方式来获取时序的唯一标识:func getLabelsHash(labels []prompbmarshal.Label) uint64 { bb := labelsHashBufPool.Get() b := bb.B[:0] for _, label := range labels { b = append(b, label.Name...) b = append(b, label.Value...) } h := xxhash.Sum64(b) bb.B = b labelsHashBufPool.Put(bb) return h }
限速器的初始化
victoriaMetrics使用了一个类似限速器的概念,限制每小时/每天新增的唯一序列,但与普通的限速器不同的是,它需要在序列级别进行限制,即判断某个序列是否是新的唯一序列,如果是,则需要进一步判断一段时间内缓存中新的时序数目是否超过限制,而不是简单地在请求层面进行限制。
hourlySeriesLimiter = bloomfilter.NewLimiter(*maxHourlySeries, time.Hour)
dailySeriesLimiter = bloomfilter.NewLimiter(*maxDailySeries, 24*time.Hour)
下面是新建限速器的函数,传入一个最大(序列)值,以及一个刷新时间。该函数中会:
- 初始化一个限速器,限速器的最大元素个数为
maxItems - 则启用了一个goroutine,当时间达到
refreshInterval时会重置限速器
func NewLimiter(maxItems int, refreshInterval time.Duration) *Limiter {
l := &Limiter{
maxItems: maxItems,
stopCh: make(chan struct{}),
}
l.v.Store(newLimiter(maxItems)) //1
l.wg.Add(1)
go func() {
defer l.wg.Done()
t := time.NewTicker(refreshInterval)
defer t.Stop()
for {
select {
case <-t.C:
l.v.Store(newLimiter(maxItems))//2
case <-l.stopCh:
return
}
}
}()
return l
}
限速器只有一个核心函数Add,当vmstorage接收到一个指标之后,会(通过getLabelsHash计算该指标的唯一标识(h),然后调用下面的Add函数来判断该唯一标识是否存在于缓存中。
如果当前存储的元素个数大于等于允许的最大元素,则通过过滤器判断缓存中是否已经存在该元素;否则将该元素直接加入过滤器中,后续允许将该元素加入到缓存中。
func (l *Limiter) Add(h uint64) bool {
lm := l.v.Load().(*limiter)
return lm.Add(h)
}
func (l *limiter) Add(h uint64) bool {
currentItems := atomic.LoadUint64(&l.currentItems)
if currentItems >= uint64(l.f.maxItems) {
return l.f.Has(h)
}
if l.f.Add(h) {
atomic.AddUint64(&l.currentItems, 1)
}
return true
}
上面的过滤器采用的是布隆过滤器,核心函数为Has和Add,分别用于判断某个元素是否存在于过滤器中,以及将元素添加到布隆过滤器中。
过滤器的初始化函数如下,bitsPerItem是个常量,值为16。bitsCount统计了过滤器中的总bit数,每个bit表示某个值的存在性。bits以64bit为单位的(后续称之为slot,目的是为了在bitsCount中快速检索目标bit)。计算bits时加上63的原因是为了四舍五入向上取值,比如当maxItems=1时至少需要1个unit64的slot。
func newFilter(maxItems int) *filter {
bitsCount := maxItems * bitsPerItem
bits := make([]uint64, (bitsCount+63)/64)
return &filter{
maxItems: maxItems,
bits: bits,
}
}
为什么
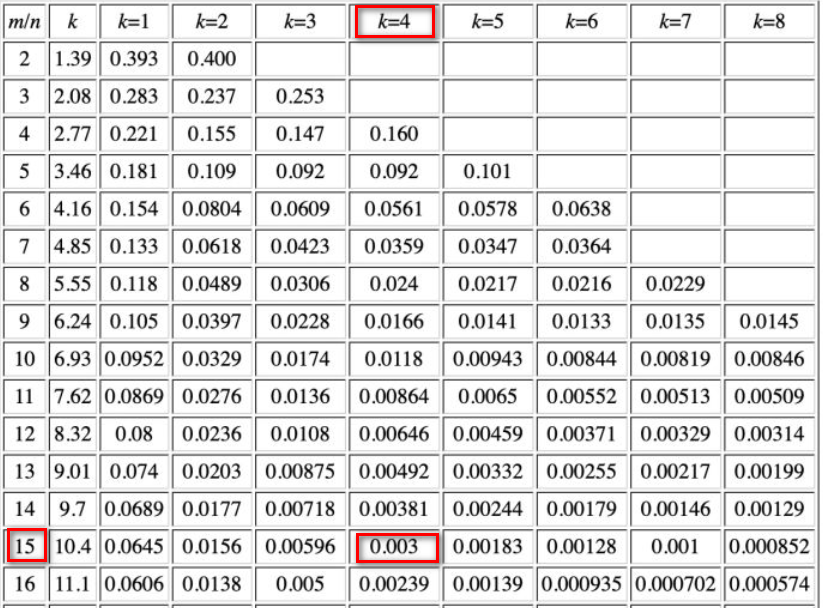
bitsPerItem为16?这篇文章给出了如何计算布隆过滤器的大小。在本代码中,k为4(hashesCount),期望的漏失率为0.003(可以从官方的filter_test.go中看出),则要求总存储和总元素的比例为15,为了方便检索slot(64bit,为16的倍数),将之设置为16。if p > 0.003 { t.Fatalf("too big false hits share for maxItems=%d: %.5f, falseHits: %d", maxItems, p, falseHits) }
下面是过滤器的Add操作,目的是在过滤器中添加某个元素。Add函数中没有使用多个哈希函数来计算元素的哈希值,转而改变同一个元素的值,然后对相应的值应用相同的哈希函数,元素改变的次数受hashesCount的限制。
- 获取过滤器的完整存储,并转换为以bit单位
- 将元素
h转换为byte数组,便于xxhash.Sum64计算 - 后续将执行hashesCount次哈希,降低漏失率
- 计算元素h的哈希
- 递增元素
h,为下一次哈希做准备 - 取余法获取元素的bit范围
- 获取元素所在的slot(即uint64大小的bit范围)
- 获取元素所在的slot中的bit位,该位为1表示该元素存在,为0表示该元素不存在
- 获取元素所在bit位的掩码
- 加载元素所在的slot的数值
- 如果
w & mask结果为0,说明该元素不存在, - 将元素所在的slot(
w)中的元素所在的bit位(mask)置为1,表示添加了该元素 - 由于
Add函数可以并发访问,因此bits[i]有可能被其他操作修改,因此需要通过重新加载(14)并通过循环来在bits[i]中设置该元素的存在性
func (f *filter) Add(h uint64) bool {
bits := f.bits
maxBits := uint64(len(bits)) * 64 //1
bp := (*[8]byte)(unsafe.Pointer(&h))//2
b := bp[:]
isNew := false
for i := 0; i < hashesCount; i++ {//3
hi := xxhash.Sum64(b)//4
h++ //5
idx := hi % maxBits //6
i := idx / 64 //7
j := idx % 64 //8
mask := uint64(1) << j //9
w := atomic.LoadUint64(&bits[i])//10
for (w & mask) == 0 {//11
wNew := w | mask //12
if atomic.CompareAndSwapUint64(&bits[i], w, wNew) {//13
isNew = true//14
break
}
w = atomic.LoadUint64(&bits[i])//14
}
}
return isNew
}
看懂了Add函数,Has就相当简单了,它只是Add函数的缩减版,无需设置bits[i]:
func (f *filter) Has(h uint64) bool {
bits := f.bits
maxBits := uint64(len(bits)) * 64
bp := (*[8]byte)(unsafe.Pointer(&h))
b := bp[:]
for i := 0; i < hashesCount; i++ {
hi := xxhash.Sum64(b)
h++
idx := hi % maxBits
i := idx / 64
j := idx % 64
mask := uint64(1) << j
w := atomic.LoadUint64(&bits[i])
if (w & mask) == 0 {
return false
}
}
return true
}
由于victoriaMetrics的过滤器采用的是布隆过滤器,因此它的限速并不精准,在源码条件下, 大约有3%的偏差。但同样地,由于采用了布隆过滤器,降低了所需的内存以及相关计算资源。此外victoriaMetrics的过滤器实现了并发访问。
在大流量场景中,如果需要对请求进行相对精准的过滤,可以考虑使用布隆过滤器,降低所需要的资源,但前提是过滤的结果能够忍受一定程度的漏失率。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK