

关于 Proxy 的设计思考
source link: https://www.ihcblog.com/thought-about-proxy/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

本文主要总结 Proxy 框架设计的常见问题及思路;此外还会提到 Rust + Tower 生态下的一些工程上的设计。虽然你能搜索到的讨论这个文章已经足够多了,但万一看完本文就有了一个新的 idea 呢[手动狗头]? 发现我从入职以来全在写 Proxy
Proxy 做什么 & 需要什么
Proxy 做什么?
顾名思义,Proxy 主要做流量中转。在这个本职工作以外,Proxy 往往还会承担以下职责(不是所有概念都适用于所有 Proxy):
服务发现
如 Service Mesh 中,Proxy 往往会做服务发现,这样业务代码就无脑连本地 proxy 即可。
在做服务发现之前,我们需要一些请求的元信息。这些元信息可能可以直接从连接上获取,如根据
client ip:port或SO_ORIGINAL_DST;也可能来自于流量中,如 HTTP 请求头上标明 dest 服务名(这意味着 Proxy 可能需要支持部分解析流量)。协议转换
协议转换指对整个流 / 请求头 / 请求 body 的格式转换。
我们常用的 ShadowSocks 就是做连接级别的协议转换,它可以将暴露的 socks5 协议转换为自定义的加密协议并转换回来。通常作为入口网关的 Nginx 往往会承担卸载 TLS 的职责,这也属于协议转换。
鉴权过滤
Proxy 不一定是透明的:在无脑中转流量的同时,中央的决定权也是很重要的。Proxy 可以对流量做鉴权、过滤和签名等花边功能。
通过中间这层代理,代理之后的服务可以无条件信任传入流量,这种做法公司内部十分常见。常见的应用场景如风控场景。
负载均衡
将流量分发和流量处理分离,可以大大提升整个系统的信息处理能力。
通过一定的负载均衡算法,我们可以在不影响业务的条件下将请求分发至不同的处理者。在这个层面上,你甚至可以认为你的老板们就是起负载均衡作用的 Proxy,他们负责将大事逐级拆成小事,最终分发给具体的 Worker 执行。
Proxy 需要什么?
获取 / 更新服务元信息
在有服务发现需求的场景下,对 Proxy 的要求就是需要能够起到服务发现客户端的作用。最简单的实现比如内置一个 Consul Client。除此之外,Proxy 还可能需要做服务治理,相关的配置如超时、重试、鉴权等也属于服务元信息。
注意,这个元信息是会更新的,我们的 Proxy 通常需要能够动态地更新这些信息。Nginx 不能很方便地做到这一点,虽然性能优异,还是被主流 Service Mesh 抛弃;Envoy 提供了 xDS 来结合控制面提供动态能力,满足了 Service Mesh 的需求,并且得益于动态配置,甚至还有替换 Nginx 的趋势。
协议(头)解码 / 编码
纯粹的四层代理应用场景非常有限,在其他场景中,我们很难不感知请求——如果我们需要做到这点,我们就要能够理解协议,至少需要能够解析协议头;在某些场景下,还需要能够解析协议体。
如 Service Mesh 场景,我们需要对 HTTP 请求做服务发现,显然这不可能是连接级别的代理,我们需要 parse 协议头来 1. 区分请求&响应边界 2. 获取元信息。
如果我们放弃透明性的保证(事实上我认为 Service Mesh 中的透明性挺废的,在非 HTTP 场景完全没意义),我们可以做更多事情,比如 Dapr 做的事情就是抽象了各种中间件,既减轻了业务学习 & 更换中间件的成本,也降低了业务代码和中间件的耦合关系,在微服务场景下可以更快速地推进中间件版本迭代。
负载均衡算法
负载均衡也要讲基本法。到底是 Round-Robin 还是 Random 还是 p2c,往往是要由使用者选择的,不同场景有不同的需求;以及 Hash 要怎么算,这个也是业务强相关的。
动态逻辑插入能力
在风控等场景,由于规则可能会频繁更新,显然将这个逻辑和 Proxy 代码糊在一起编译并不理想;有些组件也希望能够将逻辑注入 Proxy(如更小众/不通用的内部协议)。
逻辑注入并不好做,并且会伴随一些性能和易用性上的权衡。
如何描述通用逻辑?
- 进程:通用逻辑的最简单 & 最兼容 & 最自由的描述是进程。自定义逻辑以进程形式,通过 IPC 与 Proxy 通信。尽管十分自由,缺点也很明显:IPC 开销巨大,且状态管理无法由 Proxy 负责。
- Code:比如我们可以支持用户提供一段 Python 代码,Proxy 启动 Python 虚拟机去执行这段逻辑。看起来十分理想,但是这么做绑定了语言,且只能适配脚本语言,需要编译的语言就难受了。
- 有没有通用 & 易管理的表示?WASM 可能是一种(或者说设想中的 WASM)。WASM 较为轻量,Proxy 启动内置 JIT 的虚拟机也可以获得不算太差的性能,对于大多数流量过滤逻辑已经足够了。
Proxy 好?Proxy 坏?
很难想象没有 Nginx 的生产网络,它会面临处理能力不足(假定所有 Worker 都挂在 DNS 上都有公网 IP)、滚动更新困难(更新会造成部分服务中断)等问题。
但 Proxy 套太深的网络又会造成延迟增加以及计算资源浪费(无论是 中心化 Proxy 还是 Sidecar 模式 Proxy),对于中心化模式的 Proxy 还会有隔离性问题。
如果我们从更抽象地角度理解 Proxy(并去掉一些花边功能),我们可以将其能力分为两部分:
流量 / 数据隔离
流量一旦糊起来,就确实需要一个中心化 Proxy 将它们分开,这个没得治。
由于公网 IP 有限,不可避免地这些流量要糊起来;在另一些场景下,本来散开的请求经过了中心化 Proxy,又会被人为地糊起来。逻辑隔离
对于 Service Mesh 或 Dapr 场景,这里 Proxy 主要起逻辑隔离的作用。逻辑隔离目的的 Proxy 是可以通过合并代码来消除的。
啥意思呢?比如你直接把 Proxy 内部的治理逻辑代码 Copy 到业务代码中,编译成一个二进制,这样 Proxy 的 IPC 就变成了函数调用,效果也是一样的。搞成两个进程纯粹是想将逻辑隔离开。
Proxy 或许是解决代码耦合的方式之一,但我相信有更优的方式解决这个问题:我的观点是,Proxy 的未来是 没有 Proxy 尽可能少并且聚合成一体的 Proxy。不过这一代云原生的模式可能很难做到了。
此处不再讨论 Proxy 模式的好坏 / 是否有必要性,我们重点在于如何实现一个优雅的 Proxy。
由于作者太笨学不会 C++,本篇部分章节耦合了 Rust 并假定读者有一定的 Rust 基础。(为啥不用 go? 引用名人名言:go 是垃圾 有 GC 的语言搞 Proxy ,延迟敏感的服务就爆炸啦)
逻辑组合模式
Proxy 说到底流程十分简单:
- Listen + Accept
- 接收请求 + 代理请求 + 接收响应 + 回传响应
Proxy 内部复杂的事情在于中间的治理逻辑(毕竟你并不想让流量白白走一通,搭上了 CPU 和延迟还没啥用)。
最 naive 的方式是直接全部写成一团,很难维护 (增强了本人的不可替代性)。如果不想糊,往往有两种模式可以搞:
过滤器模式 aka. Filter Chain
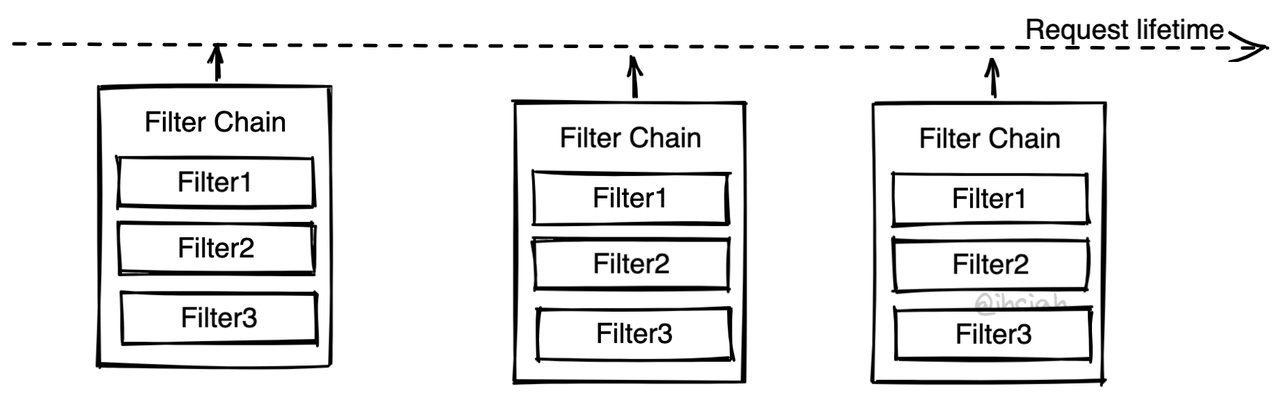
Envoy 的模式是 Filter Chain(这里的 Filter 并不是一个返回 bool 的判别函数,是会操作数据、有副作用的东西)。不同目的的组件作为 Filter 插入 Chain 中,流量从 Chain 上经过,依次被各个 Filter 处理。
除了 Envoy,Mosn 和 Quilkin 也都是类似模式。
这种模式往往由框架实现主链路逻辑,并提供 Filter 插入点支持插入多个 Filter。在固定的插入点,Filter 的接口是固定的,所以编程起来有一定限制,但也简单。
洋葱模式 aka. Middleware
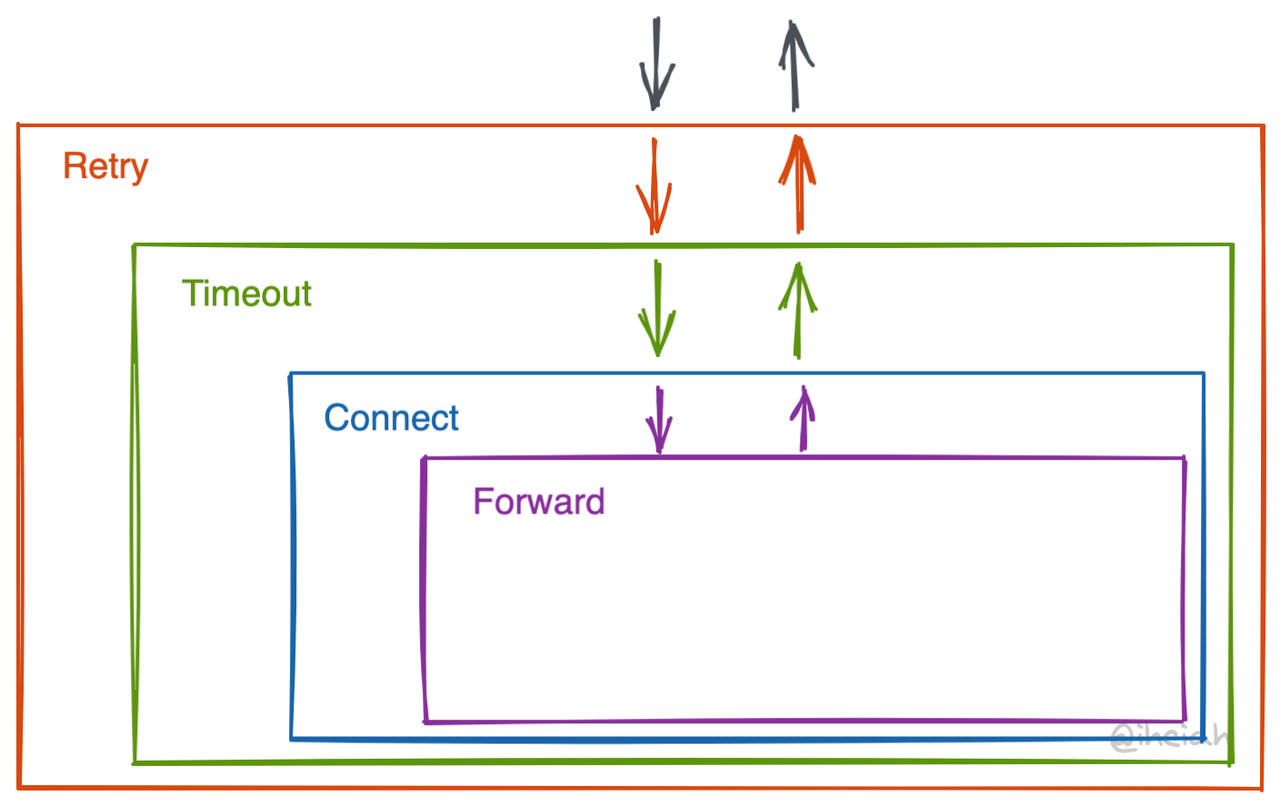
Linkerd2-proxy 使用洋葱模式组织治理逻辑。洋葱模式自由度更高,内部组件由外部组件负责调用(或不调用)。缺点是太自由了,层与层之间的接口或约束不好对齐,在 stage 上没有明确清晰的边界,接口也并不固定,写实现的时候可能会难受一下。
每层基本都是利用 Tower Service 实现抽象(详见后续章节)。Service 之间可以嵌套;Service 的包装逻辑也有对应的抽象 Layer。在 Linkerd 里为了拼装方便甚至提升了一个维度做了一个 NewService trait 和对应的一些包装方法。啊啥是 monad?
这部分不太好讲,具体可以参考 Linkerd2-proxy 的代码,如 linkerd/app/core/svc.rs。
临时数据 & 配置
Filter 或 Middleware 的临时状态怎么存?配置又怎么存?
显然 Filter / Middleware 是有状态的,如 TLS 要自行存储握手信息。这个信息存哪呢?
存 Context
如果我们搞一个连接或请求级别的 Context,每层传递,那么我们可以将临时量存储在 Context 中,这样 Filter Chain / Middleware 就是无状态的,就可以是全局变量。当新的连接 / 请求过来时,我们只需要重建一个 Context 即可(同时还可以池化对象)。
但这么做的问题是,Context 是一个非结构化的存储,会带来转换开销和数据依赖上的不确定性,丧失了静态检查的机会。存自己头上
存自己头上显然是比 Context 更好的方案。这样 Filter Chain / Middleware 就不再是全局变量,而是带有状态的,跟连接 / 请求绑定的东西。目前 Envoy / Mosn 都是类似的实现。
这里的配置指从控制面捞的数据。
注:还有一些没细化的细节。先说连接级别的配置,如 TLS 是否开启。
处理这个十分简单,当我们主线程更新到数据后,会将请求推到 Worker 线程。配置存储在线程的 Thread Local Storage 中,当创建 Filter Chain / Middleware 时会直接使用这份配置,这样新接收的连接就应用了新的配置。
之后我们需要向旧连接广播关闭需求,期待对面主动关闭。
在长连接场景下,我们期望配置更新后可以立刻生效。
- 一种做法是,组件内直接引用 Thread Local Storage 的配置(耦合度高);
- 另一种做法是配置更新后向组件推送更新,组件自己更新内部状态;
- 还有一种做法是,直接从外部重新创建一个新的 Filter Chain / Middleware,但是这样需要关心旧的状态迁移。
Tokio + Tower 生态
Tokio 是 Rust 生态下的事实标准 Runtime。Tower 是和其配套使用的抽象 Trait 及工具包。
Tower Service 是一个很通用的服务抽象,基于它可以做异步调用抽象。
pub trait Service<Request> {
type Response;
type Error;
type Future: Future<Output = Result<Self::Response, Self::Error>>;
fn poll_ready(&mut self, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>>;
fn call(&mut self, req: Request) -> Self::Future;
}
注意,call 接收的参数是 &mut self,所以单个 Service 不能被并发使用,可以修改内部状态。
那么如何处理并发请求呢?只能 Clone 咯~看到这里已经可以写出一个性能一般的实现了,但 Clone Service 的开销依旧在。
但其实 Service 使用起来并不会被占用很久(Service 负责制造 Future,并不负责执行,且 Future 与 Service 没有引用关系),大部分时间都是空置状态,不复用反而 Clone 一堆,太浪费了。
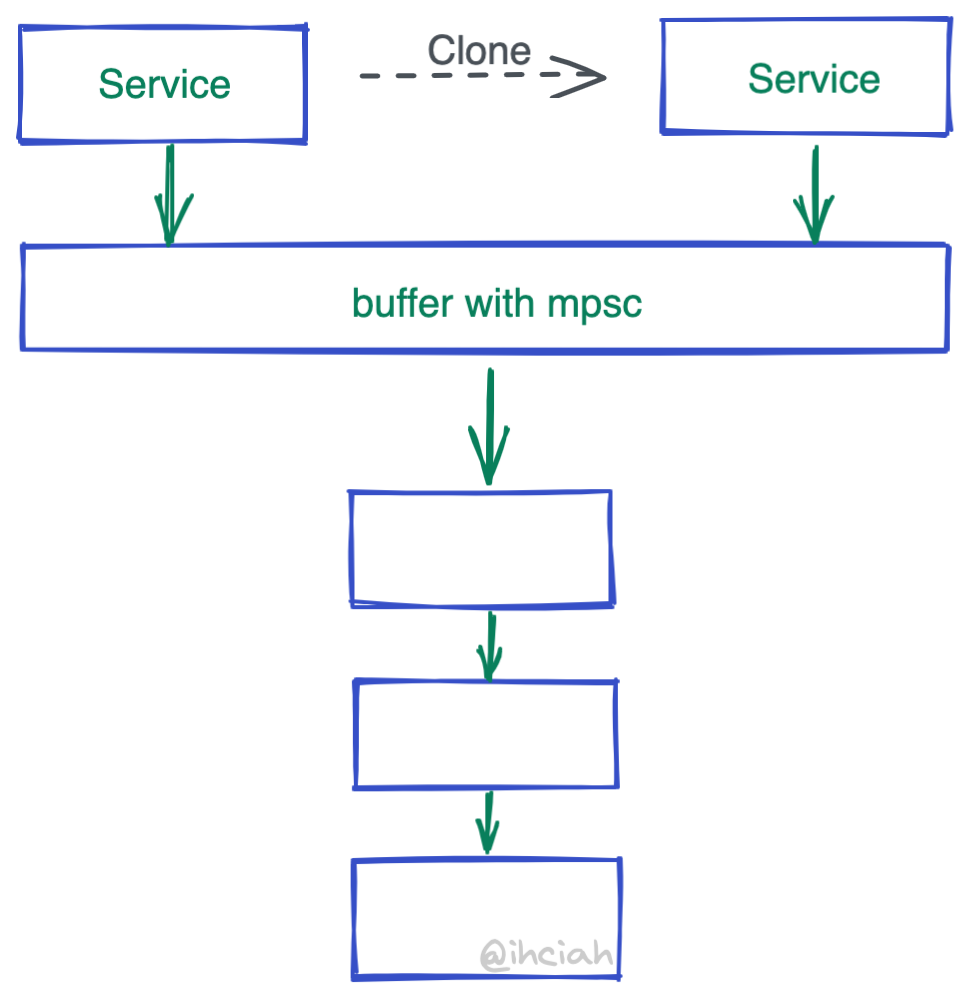
为了解决这个问题,Tower 搞了一个东西叫 buffer()。实现也非常简单,就是一个 mpsc channel。当被 Clone 时并不会 Clone 自己所持有的内层 Service,而是只 Clone mpsc 的 Sender。谁来 Recv 呢?会有一个 Spawn 出去的 coroutine 来循环处理接收到的数据并 call 内层 Service。
那一个问题来了:通过 channel 将原本期待并行 call 的 Service 串行化,虽然确实少了 Clone,但不会有性能问题吗?答案是,如果 Service 实现得当的话,就不会有性能问题。
为什么呢?回到之前的科普:说到底 Service 只是 Future 创建器,它并不实际执行 Future,最终 Future 会被 Spawn 出去或者 await,而 Future 的执行并不依赖 Service。实现得当是说,应当保证 Future 的创建逻辑尽可能轻,将重的逻辑放 Future 里。
所以总结一下,Tower Service 创建 Future 的逻辑很轻,所以往往通过 buffer 串行化处理,且创建出来的 Future 与 Service 无关,Future 可以被 Tokio 调度到空闲的 core 上执行最大化利用 CPU。
Thread-per-core Runtime + Forked Tower
Tokio + Tower 这套非常美好呀,用呗?事实上,在某些场景并没有那么美好,比如 Proxy 场景。
公平调度必要吗?
如果假定逻辑都是轻量且较为均衡的,Tokio 的公平调度的必要性就没有了。这在 Service Mesh 场景是适用的。
注意:公平调度本身的开销并不小(这一点可以参考 golang 调度器),且创建出的 Future 必须是 Send + Sync 的(很好理解,因为它们可能会被调度到不同的 core 上执行),这就要求 Future 中内部量都是 Send + Sync 的,这样就基本堵死了组件使用 Thread Local Storage 的可能性,要么 Atomic 要么 Lock。
如果我们放弃公平调度,走 libevent 类似的模型,我们就可以放弃 Send + Sync 约束,并且没有跨线程调度的开销。
作为有追求的童鞋,我做了一个 Runtime(后续开源),基于 io-uring 实现了 thread-per-core 模型的 Runtime,并启用了 Rust 的 GAT feature。相比 Tokio 和类似初衷的 Glommio,在性能上有较大优势(如 8 核物理机上,100K echo 场景下的极限 QPS 可以达到160 万,而 Tokio 只有 80 万不到,Glommio 大概是 120 万不到)。
Future 创建时的 Clone 必要吗?
前面提到,Service 创建出的 Future 是 static 的,与 Service 本身无关。那问题来了,如果 Future 内部需要使用 Service 中的临时量怎么办?目前的做法是 Arc,而 Arc 对于单个组件来讲开销并不能忽略不计。
这时我们重新来考虑 Tower 抽象:
- ready 接口解决了什么问题?
通过 ready 方法我们可以探测服务的可用性,因为它并不需要消耗掉 Request。这种需求场景我们认为较少,并且可以通过其他方式实现;而 ready 带来的复杂度和计算消耗上 cost 我们认为是较高的(部分原因是 GAT 的启用)。 - call 方法返回的 Future 一定要是 static 的吗?
通过 GAT,我们可以为 Trait 中的关联类型添加生命周期标记。这样可以将 Future 与生成它的 Service 绑定起来,形成引用关系继而避免 Arc / Rc 开销。
我们的改造也看起来十分美好,几乎干掉了所有不必要的 overhead。但是,由于 Future 现在和 Service 绑定了,那么 Future 在执行期间也要一直捕获着 Service 的引用,因为 call 需要 &mut self,所以这个 Future 会影响 Service 的使用——也就是说,Service 不能被串行共享执行了。我们一定需要为某个连接创建一个新的 Service,且该 Service 同时只能被一个 Future 使用。
庆幸的是,Proxy 场景下这个约束是可以接受的。对于长链接,创建 Service 的开销和共享 Service & 共享 Service 内部量的开销相比可以忽略不计;对于短连接,我们可以通过复用 Service 来实现不差的性能。
总结一下:修改后的 Service 抽象只保留了 call 方法,且它生成的 Future 是和 self 有引用关系的,这避免了内部量的 Arc/Rc 方式共享。但它也约束了 Service 不能共享使用,这是可以接受的。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK