

seo清洗百万长尾词数据的策略
source link: https://zhuanlan.zhihu.com/p/368643304
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

seo清洗百万长尾词数据的策略
前言
如果不是一名CEO主动高薪挖掘、空降过来的seo负责人,老实说,很多seo人员在公司里都处于“弱势群体”。
绝大多数普通的seo人员在公司里、跨部门沟通里都没有太多相应话语权,有很多的细节工作得不到相关配合。
处于这样一个环境,seoer想要工作出色,必须充分发挥主观能动性,想尽一切办法完成那些明面上不值一提、暗地里又不可避免的事情。
问题
全网大批量挖掘长尾词,这是seo和sem必须做的事情,但是大批量的长尾词注定会带来一些数据清洗工作,多数情况下清洗的工作可以在Excel完成,但是也有很多情况是Excel很难搞定的,比如:
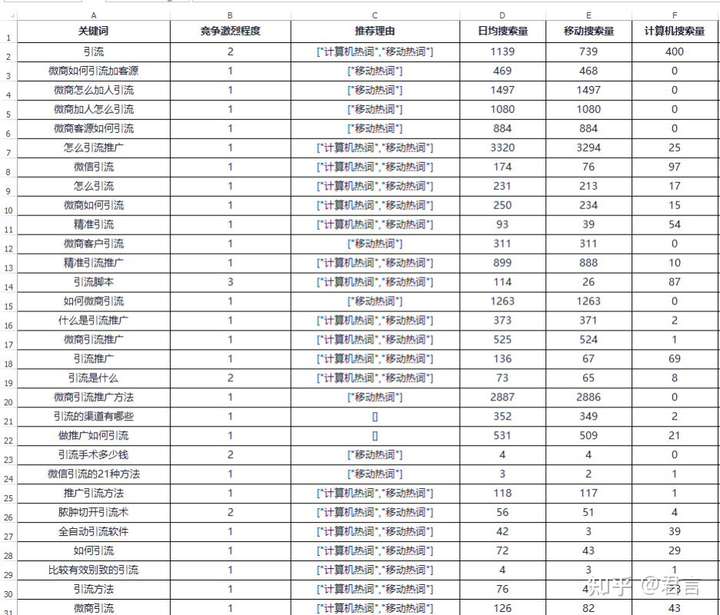
这是一份从第三方关键词工具下载的“引流”这个词根的长尾词数据,但是碰到了一个尴尬的问题,“引流”这个词根存在同义但有不同场景的情况,所以会导致挖掘到很多不相干的长尾词:
其实这种情况是很普遍的,单单一个词汇,经常避不可免的与其他场景混淆,又比如:
水果里的“苹果”和手机里的“苹果”和电影里的“苹果”,这又是同形但完全不同义的词汇,简单的利用词根去挖词自然会挖掘到很多非目标长尾词。
还有很多类似情况,那么问题来了:剔除非目标长尾词是必须要做的事情,这样一个seo工作里的细枝末节,做好是理所当然的。老板一不会帮我们做、二也不会给我们配人做,如果这是一份百万级别的长尾词数据,都靠在Excel里筛选剔除,可能项目已经黄了。
面对这样一份杂乱无章的长尾词数据,如何使用高效的方式过滤筛选?
今天这篇文章是一篇完全基于技术的内容,但是对于不会技术的朋友我反而强烈建议充分的看一下,有两点:
技术是另一种思维方式,对于不会技术的朋友可以看看技术人员在碰到问题时是如何处理的。
在“互联网营销”工作中,有很多工作是超出我们能力范围之外的,但是充分发挥我们的主观能动性做出超越这个岗位应有的能力水平往往会带来额外的收获。
开始
前段时间接了一个采集项目(只接熟人之间的合法业务),随着采集量的增大,“敏感词过滤”这项工作避不可免,涉政、涉黄、恐暴、广告等,这些相关字眼都得识别出来。
目前在市面上可以搜集到的敏感词库,随便整合几份就能达到几万甚至更多,因为随着时间的前进,会产生各种各样的新词汇。
用程序识别一篇文章是否包含目标敏感词,以Python举例:
refusalWord = '敏感词'
targetText = '内容正文'
if refusalWord in target_text:print(True)让程序把这个敏感词拿到目标文本里寻找,找得到就说明存在敏感词,这是敏感词只有一个的情况下,如果敏感词是多个的话,那也简单,加个循环:
refusalWord = ['敏感词1','敏感词2','敏感词3']
targetText = '内容正文'
for word in refusalWord:
if word in target_text:print(True)程序把一个个敏感词拿到目标文本里寻找,如果敏感词是几百个呢,一个个反复处理显得效率很低下,感觉还不太优雅,正则表达式可以很简洁的搞定:
import re
refusalWord = ['敏感词1','敏感词2','敏感词3']
targetText = '内容正文'
if re.search('|'.join(refusalWord),targetText):print(True)所有敏感词用“|”连接形成一段正则表达式:“敏感词1|敏感词2|敏感词3”,用这段表达式去匹配目标文本,找出所有出现的敏感词。
但是,如果敏感词是几万个甚至更多呢?了解正则的朋友都知道,再用这种方式写出来的表达式就显得极其不合理,可能还会有各种问题。
而且敏感词有几万个甚至更多的情况下,效率是线性递减的,再加上后期做的替换等其他工作,时间成本就更高了。
并且,我们前面的演示还只是目标文本只有1个的情况,如果敏感词数是N,目标文本是M呢?简单双循环的情况下,时间复杂度至少是N * M。
这个时候就需要用到我们今天的主角:“AC自动机”算法。
PS:不懂技术的朋友不必纠结代码,只需要明白这是一个方案优化的问题,我们在面对敏感词从1到N到N++的过程中在不断优化着技术方案,提升效率。
AC自动机算法,是一种多模匹配算法,算法的高明和高深不是我们这种非科班人员可以去探究的,但是算法的意义和差别,我们还是可以理解的。
上面的例子里,即使不会技术的朋友也明白,随着敏感词库的不断增加,程序判断一篇文章是否包含敏感词库里的某个词或某些词,这个时间成本是会逐步递增的,因为无意义的判断次数在不断增加,这就是一种单模。
而AC自动机解决了这个问题,使用多模匹配的算法,也就是说:随着敏感词库的递增,时间成本是不变的(至少在一定量级内吧)。
那这跟我们要聊的关键词清洗有什么关系呢?接下去我们来一步步演示。
步骤1:挑选代表性词根
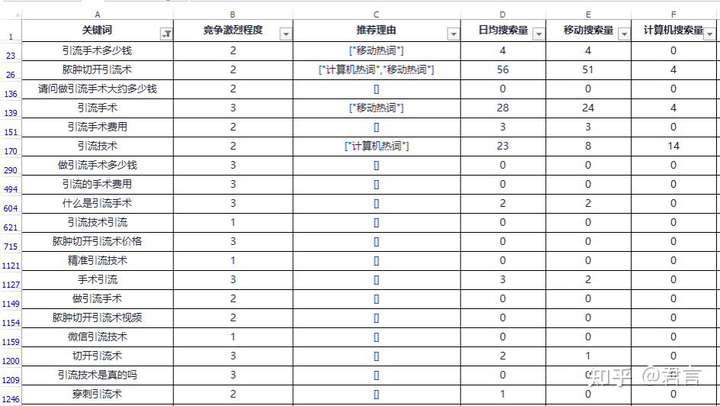
这是一份“引流”的长尾词库,有几十万,里面有两种长尾词,互联网推广相关的长尾词和医疗技术相关的长尾词,我们的目的是分开这两类长尾词。
在Excel里,面对这样一份数据,要把两边分开,也就是筛选出目标或者筛选出非目标然后剔除,我们先考虑下一般操作方式是什么样的:
一行一行看,把非目标的数据做标记,后面筛选出来全部删除,但是对象是几十万甚至更多,这个效率可想而知,能一行一行看完的是猛人。
挑选一些高频的非目标词汇或字眼,然后筛选出来剔除,反复重复这个操作,这个方式看上去很快,一次可以剔除一大片。
但是充分了解关键词的长尾效应就会明白,这种方式越到后期越痛苦,因为到后期很多挑选出来的词汇删不了多少个词,反反复复的筛选删除会让人崩溃。
除此之外,在Excel上面处理这样一个问题貌似没有更好的方式,现在我们就用另一种方式来解决这个问题。
老规矩,先对所有长尾词分词并统计词频:
接下来需要人工根据“常识”挑选出具有代表性的“分类种子词根”,从上往下,把“明显只能”属于互联网推广相关的词汇挑选出来放到一份文档,把“明显只能”属于医疗技术相关的词汇挑选出来放到另一份文档。
所谓的“明显只能”,比如:“脚本”,即脚本工具,这样一个词基本不可能跟医疗技术类长尾词有什么关联,“伤口”,也基本不可能跟互联网推广这件事有什么关系。
所谓的“常识”,比如:与互联网推广有关的经常会有一些平台名称,知乎、微信、淘宝之类的,这些甚至不用考虑,直接写。
因此在挑选的时候,一定要确定这个词的归属是否明确,如果模糊,宁可不要!
前者视为“正”,后者视为“反”,“正”就是我们目标长尾词的代表性词根,挑选多少个呢?还是那句话,关键词很符合28原则。
我们可以看到top词根的词频都是很高的,一个词根可以牵连出很多长尾词出来,这样一份几十万的长尾词我也才各自选了百八十个。
即使这份长尾词的数量增加10倍,要挑选的代表性词根也不会多多少个。
步骤2:拓展代表性词根
我们挑选这些种子词的目的很简单:“正”的种子词拿到词库里可以筛选出绝对是目标分类的长尾词,我们上面把“微信”挑选出来作为种子词,我们认为它只可能出现在互联网推广相关的长尾词,所以把“微信”拿到词库里可以筛选出包含“微信”的所有长尾词,这些都是互联网推广相关:
而长尾词一般会有这样的特性:
微信引流脚本开发
像这样一个长尾词,我们通过“微信”提取出来,除了“引流”这个词根之外,因为这个长尾词是互联网推广相关的,所以其他词根大概率也是互联网推广相关的,比如这里的“脚本”、“开发”,绝对不可能跟医疗技术相关,反之:
脓肿切开引流手术
我们通过“手术”这个种子词得到,分词后的“脓肿”和“切开”跟互联网推广也是不可能有什么关联的,它们就可以作为新的种子词加入“反”这个分类。
这个时候思路就清楚了,我们先挑选一点代表性的种子词,用这些种子词去筛选所有相关长尾词,再对这些筛选出来的长尾词分词,利用关键词的这种关联性,得到目标分类的更多 我们在上一步没有挑选到的种子词。
所有这些种子词就是我们后续用来分类的基石。
运用这种思路其实就是解决了关键词的长尾效应问题,我们无法人工一一去挑选种子词,通过关联自动收集到更多我们人工没有挑选出来的种子词。
这些种子词就能帮我们覆盖更多的长尾词。
PS:这里是演示思路,筛选肯定是程序批量化处理,不是在Excel上做这个事。
在这一步里要为提取出来的种子词计算各自的词频并对应保留,后续有用。
比如我们利用“正”的种子词去筛选所有长尾词,所有的这些长尾词经过分词后得到的所有词根,每一个词根在这片长尾词(筛选出来的这些)里的总词频是多少。
步骤3:筛选代表性词根
到这里其实我们就可以拿去开始区分了,但是还有细节优化:
1:通过第二步的自动拓展,会出现某个种子词即出现在“正”,也出现在“反”,比如:“视频”。
这个词出现在互联网推广相关的长尾词一点都不奇怪,而事实上它还会出现在医疗技术“引流”这件事的长尾词上:
对于这种情况,我们其实可以考虑一个问题,这是一种偶然还是常态,比如“视频”这个词,它其实在两边都是经常出现的,那就干脆不要了,也就是它根本不具备代表性。
如果是偶然的,比如“艾滋病”,也是神奇,我在词库里看到一批长尾词里有一个:
卖艾滋病测纸推广引流的方法
除了这个以外,其他都是医疗类,那这种就是偶然了,对比我们第二步保留下来的词频,哪一边出现压倒性的大,就把这个种子词保留在哪一边,另一边直接去除。
如果在数据上差距不大,那就两边直接去除这个没有倾向性的种子词。
按我的经验,绝大部分这种偶然,他们之间的词频对比都是差非常大的。
2:没有倾向性的词汇,数字、字符,这都是没有倾向性的,不应该作为种子词。
其次,类似:应该、怎么、大概、可以、的、是、吗,这些副词、助词、连词、语气词、疑问词之类的,也没有倾向性,在分词的时候,直接根据jieba的词性剔除:
这一步过滤完之后,词频数据就可以不要了,当然了,“引流”这个每个词都一定有它的主词根肯定是要去除了!
步骤4:快速归类
现在我们使用上面计算出来的种子词作为关键字,其实这就跟我们上面举的采集的例子一样,这些种子词就相当于敏感词,每一个待分类的长尾词就相当于目标文本内容。
传统的做法用Python是类似这样:
# 正
seed_word_r = []
# 反
seed_word_e = []
# 词库
keyword = []
for word in keyword:
for r in seed_word_r:
if r in word:
pass
for e in seed_word_e:
if e in word:
pass把每一个长尾词拿出来,让每一个种子词跟它比对一次,看看是否包含,进而判断归属分类。
如果有N个长尾词,外层循环就要执行N次,而有M个词汇,N里面的每1次还要包含M次,执行成本可想而知。
另外,上万个甚至更多的词根拿去一一与一个只有10个字左右的长尾词做比对,注定有太多无意义的比对。
这时候就可以使用AC自动机算法了:
import ahocorasick
# 正
seed_word_r = ['种子词1','种子词2','种子词3','种子词4']
tree = ahocorasick.AhoCorasick(*seed_word_r)
print(tree.search('长尾词'))如上代码,我们把种子词(敏感词)传给AC自动机构建一个模型,然后这个模型就可以计算当前的长尾词(目标文本内容)是否包含模型里的某些词,有出现的全部显示出来。
这种计算就不是像上面的方式那样内外循环一一比对了。
因此,在做上面的长尾词分类工作,就可以:
import ahocorasick
# 正
seed_word_r = ['种子词1','种子词2','种子词3','种子词4']
# 反
seed_word_e = ['种子词1','种子词2','种子词3','种子词4']
# 词库
keyword = []
# 构建
tree_r = ahocorasick.AhoCorasick(*seed_word_r)
tree_e = ahocorasick.AhoCorasick(*seed_word_e)
# 遍历
for word in keyword:
r = tree_r.search(word)
e = tree_e.search(word)
pass每次都把长尾词传给两边,瞬间得出这个长尾词在两边的包含情况,pass部分就是针对性的做判断了。
可以预见的结果有这么几种:
1:长尾词只属于“正”或只属于“反”,那很简单,归到对应的类即可。
2:某个长尾词既不属于“正”也不属于“反”,这种情况先归到一类并保存。
3:某个长尾词既属于“正”也属于“反”,这就要再进一步做判断,我们先把这种也归为一类并保存。
r和e都是set数据结构,根据长度结合交集和并集来判断归属。
w1是没有找到归属的,w2是同时归属的,w3是“正”分类,也就是我们要的互联网推广相关长尾词,w4是“反”,医疗技术相关长尾词,我们不要的。
3和4里的内容是不会有问题的,如果偶尔出现分类不准确,找出这个不准确的词汇,溯源它的种子词,这一定是某个种子词选错了。
删除重新跑一遍代码即可,所以最开始人工挑选的时候一定要选明确归属的,模糊的大可不要。
但是我们看到w2,也就是同时归属的这一份还有1.9M,打开看看:
这些不能确定分类的居然还有6W多条记录(截图没显示完全,懒得再截),虽然按比例来说,我们已经分类了80%了,但是6W多还是不少。
既然它们都是被判断为同时归属的,也就是两边都能匹配到,那我们随便拿一个词到原程序再跑一遍,看它在两边分别匹配到了什么。
阑尾炎导流管每天引流量
这是个医疗技术相关的长尾词,这个长尾词在程序跑完之后,出现的结果是:
反:阑尾、阑尾炎、导流、导流管、引流量
这是该长尾词在种子词中命中的词汇,那很显然程序并没有错,因为流量这个词在互联网推广相关的长尾词里出现再正常不过。
可这个词是医疗相关的,我们还是希望它能判给“反”,怎么做呢?
还是要运用概率的思维,结合上面我们提到的关联性,一个长尾词属于哪个领域,它被分词后的词汇属于该领域的可能性是很大的。
所以上诉我们可以看到,这个长尾词命中“反”的种子词的数量远远超过命中“正”的数量,这有点假的真不了、真的假不了的意思,所以根据这种绝对差,我们可以直接判给数量多的一方。
再优化一下程序判断后,跑出来的结果是:
可以看到,w2从1.9M降低到300+kb,w3和w4都有明显增加,因为有更多的词汇被分类进去了。
可以看到w2里面还有1万多条,这点数据量对于专门跟Excel打交道的seo或sem人员,反复操作几下,也能很快的整理得七七八八。
但其实如果你愿意,这也还是可以优化的,w2还会有这么多,有很大一部分原因是精准分词的问题,如果你有兴趣的话,可以自行研究一下优化方案。
对于一直没提的w1:
我特意截长一点,为什么这些词不属于任何一边,看完也就明白了,其实这类词已经超出长尾词的范畴,去掉“引流”再去掉没有倾向性的词汇后,基本就没什么字眼可以做判断了。
这种词结构很单一,真的需要的话,Excel排序一下都能很快挑完。
最后放一下w3和w4的数据:
总共有15W+长尾词,这是我们需要的数据!
总共有30W+长尾词,这是我们不需要的数据!
AC自动机
# pip install ahocorasick-python
import ahocorasick
t1 = time.time()
ac = ahocorasick.AhoCorasick(*seed_word)
t2 = time.time()
rw = []
print(t2-t1)
for word in keyword:
sw = ac.search(word)
for i in sw:
word = word.replace(i,'***')
rw.append(word)
t3 = time.time()
print(t3-t2)
rw = []
t1 = time.time()
for word in keyword:
for i in seed_word:
if i in word:
word = word.replace(i,'***')
rw.append(word)
t2 = time.time()
print(t2-t1)AC自动机我是用的第三方模块,算法的效率还是不错的,总共5W的词汇和50W的目标文本,传统方式总共是1450秒,使用AC自动机,构建花了20秒,但这是一次性的,判断加替换是100秒。
其实无论是种子词关联的思路还是AC自动机算法,举个不恰当的比喻类似我们把一个线性的问题转化成指数问题(这个表达可能有问题),时间成本不会随着数据量增加而机械上升。
类似敏感词过滤这类问题也有其他方案,比如DFA,方案没有标准,适合自己的就行。
结语
如何大批量剔除非同类长尾词,我在过往公众号付费文章里也提供过方案,不过那需要涉及网络数据做支撑判断,而这是完全本地化的,相对来说更经济一点。
这个工作前前后后加起来的时间一般不超过半小时,得益于“利用种子词带出更多种子词”的思维、“根据概率来确定归属”的逻辑、以及“AC自动机算法”的高效,处理几十万和几百万在时间上不会有很大差别,真正属于程序计算的时间10分钟都不到。
尽管我们绞尽脑汁用了很多策略来完成这样一项工作,第一次完成时可能还有些得意。
但实际上从价值来说这是一项在对外沟通时甚至不值得被谈论的工作事项,因为它并非具体的结果指标。
外人看来这不就是你们这个岗位的基础嘛,也确实是这样。
另外有朋友可能感觉,使用AC自动机算法对比普通方式,几十万的词也差不了多少时间,不差程序计算的那几十分钟。
这个没错,全程下来,并没有哪个步骤和方案是标准的,我只是想传达一个工作方式,在碰到很多棘手的问题时,发散下思维、变换下角度,其实有很多思路是可以解决的。
同时,对于会技术的朋友,相比传统的方式,运用AC自动机也不过是写不同的几行代码而已,但是带来的收益却不止这些,多学会一个技术,可以解决很多同类型的问题。
上面提到的采集项目,我使用AC自动机就可以应对源源不断新增的敏感词和文章,我在下一个阶段还会对这个采集项目做另外一个工作:筛选目标领域内容。
在目标采集源里并不一定是什么内容都是我们的目标领域内容,可能会有很多不相干的,对于不相关的内容当然是选择丢弃不入库。
因此要设计一个简单的判断逻辑,类似推荐算法给文章打标签的方式来判断当前内容是否属于目标领域,不是的话不采集,减少人工审核的工作量,这对老板来说都是钱,人员成本是最高的。
所以:我认为默默啃掉这些棘手的问题,在当下看起来好像是吃亏了,但是在未来的工作里,一定可以带来更多的“复利”。
PS:有很多正在处理长尾词数据的朋友跟我聊过不懂清洗,类似工具等过段时间再写个通用的,放到公众号。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK