

How to create a router for a custom SPA App
source link: https://www.wiktorwisniewski.dev/blog/how-to-create-router-library
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


How to create a router for a custom SPA App
If you have ever tried React.js before you must've heard about React's Router library. If you haven't:
React Router is a standard library for routing in React. It enables the navigation among views of various components in a React Application, allows changing the browser URL, and keeps the UI in sync with the URL.
Basically, it solves the problem of handling multiple pages in single-page applications (web developers love to make their life harder).
Starting point
We are going to observe three events:
- anchor tag clicks
- DOMContentLoaded
- popstate - this will cover browser history functionality
Quick note: I am going to use Private class fields here but you don't have to. Browser support is not so great yet (thanks to Safari | 03.2022).
class Router {
constructor() {
this.#init();
}
#init() {
document.addEventListener('click', (event) => {
event.preventDefault();
}, false);
window.addEventListener('DOMContentLoaded', (event) => {
event.preventDefault();
});
window.addEventListener('popstate', () => {
});
}
}
export default Router;Registering paths
I am not a big fan of React Router syntax because I don't think that putting everything into HTML-like code is a good thing. I want this to work similarly to express.js routes:
import Router from './router';
router.get('/my-custom-page', () => {
// do stuff
});
Under the hood we are going to simply register some routes, and assign regex pattern with callbacks to them, which are going to be executed when one of the above events happens and matches regex pattern:
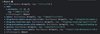 Path registry
Path registryclass Router {
constructor() {
this.#init();
}
#paths = {};
// registers path
get(pattern, callback) {
const paths = this.#paths;
if (!paths[pattern]) {
paths[pattern] = {};
paths[pattern].callbacks = [];
}
paths[pattern].reg = this.#parsePattern(pattern);
paths[pattern].callbacks.push(callback);
return true;
}
// ...
}
export default Router;
Transforming patterns into RegExp
Same as express.js, you could use [npm] path-to-regexp library, but dependency-free solutions come at a cost. From path-to-regexp README.MD:
Turn a path string such as /user/:name into a regular expression.We are going to support only :option and * type of parameters. Just to proove that you can do something simple alone without adding too many unused bytes to the project (like external dependency). And all that magic comes down to:
#parsePattern(pattern) {
return `^${pattern
.replace(/\/g, '\/')
.replace(/(*|:w*)/gm, '(:?[A-z0-9|*]*)')}(?:\/?)$`;
}
This code transforms the custom pattern to the regex one. The first step is to make sure that all URLs like:
\test\:label1\*\*\*\:label2are changed to:
/test/:label1/*/*/*/:label2And finally, we are replacing all custom parameters with their regex equivalents:
/test/(:?[A-z0-9|*]*)/(:?[A-z0-9|*]*)/(:?[A-z0-9|*]*)/(:?[A-z0-9|*]*)/(:?[A-z0-9|*]*)You can notice that from a regex perspective it doesn't really matter if it's :label or *. It will transform both into `(:?[A-z0-9|*]*)`.
Listening to navigation changes
History entry changes and page load
#init() {
// ...
window.addEventListener('DOMContentLoaded', (event) => {
event.preventDefault();
this.#checkPatterns(location.pathname);
});
window.addEventListener('popstate', () => {
this.#checkPatterns(location.pathname);
});
}Each time when location changes we need to verify if it exists in our registry:
#checkPatterns(url) {
const targetUrl = url;
// Find the matching pattern
const result = Object.keys(this.#paths).find(this.#checkIfAnyPatternIsMatching(targetUrl));
// If pattern is not found we return an error or 404
if (!result) {
this.#handleError();
return false;
}
// Prevent reloading the page if the url is the same
if (this.#previousPath === targetUrl) {
return false;
}
// Run the callback function
this.#processURL(result, targetUrl);
return true;
}
}The Object.keys() method returns an array of a given object's own enumerable property names, iterated in the same order that a normal loop would. Because it's an array we can use a find() method on it. Finally, we pass #checkIfAnyPatternIsMatching() method into it so it explains its purpose. You will notice here a curry function implementation. The idea is I want to pass the finds currentValue parameter into #checkIfAnyPatternIsMathing() in the background and as the first parameter I want to have a value that I'm checking currentValue against:
#checkIfAnyPatternIsMatching(url /* <- this is what we are passing in */) {
return (element /* .find() currentValue parameter */) => {
const pattern = this.#paths[element].reg;
const newRegex = new RegExp(pattern, 'i').exec(url);
if (!newRegex) { return false } // not found
return true; // found
}
}If the result of exec() is an array then we found our pattern.
Going deeper into error handling and URL processing:
#processURL(pattern, url) {
this.#previousPath = url;
const result = this.#getParams(pattern, url);
return this.#paths[pattern].callbacks.forEach((callback) => callback(result));
}processURL() will run the callback function that we have registered using router.get() and will pass retrieved parameters into it. Here's what you can expect from the argument inside the callback function:
if the url is /test/custom_label/arg1/arg2/843/custom_label2 then the matching pattern is /test/:label1/*/*/*/:label2:
router.get('/test/:label1/*/*/*/:label2', (options) => {
console.log(options) // =>
/* {
"0": "arg1",
"1": "arg2",
"2": "843",
"label1": "custom_label",
"label2": "custom_label2"
}
*/
});In order to create such object we are going to utilize .exec() functionalities:
#getParams(pattern, url) {
const parsedPattern = this.#paths[pattern].reg;
const regex = new RegExp(parsedPattern, 'i');
const tokens = this.#transformRegexOutput(regex.exec(pattern));
const params = this.#transformRegexOutput(regex.exec(url));
return this.#mergeObjects(tokens, params);
}.exec() returns array which contains the parenthesized substring matches, if any [1], ...[n] e.g.:
[
"/test/custom_label/arg1/arg2/843/custom_label2",
"custom_label",
"arg1",
"arg2",
"843",
"custom_label2"
]
and
[
"/test/:label1/*/*/*/:label2",
":label1",
"*",
"*",
"*",
":label2"
]
In this example, we run exec on both URL and pattern. Using #transofrmRegexOutput we get rid of everything that is not in 1, ...[n] range and turn what's left into an object. Then we merge those two objects into a single one. In the merge function the trick is that we need to transform all * exceptions into numbers and leave labels as-is:
#transformRegexOutput(input) {
try {
return Object
.keys(input)
.filter((key) => Number(key))
.reduce((obj, key) => { return { ...obj, [key]: input[key] } }, {});
} catch (error) {
this.#handleError();
return {};
}
}
#mergeObjects(obj1, obj2) {
let iterator = -1;
return Object
.entries(obj1)
.reduce((obj, key, index) => {
if (obj1[index + 1] === '*') { iterator += 1; }
return ({ ...obj, [obj1[index + 1] === '*' ? iterator : obj1[index + 1].substring(1)]: obj2[index + 1] })
}, {})
}Handle link clicks
Lastly, there are in and outbound links. There are at least three challenges to face:
- we don't want to impact browser default behavior for outbound links
- hash URLs pointing to sections in a given page
- the dynamic aspect of the website - anchor links will get created and removed all the time and we can't worry about adding and removing event listeners
// adding listener to document solves the dynamic
// aspect of component's lifecycle
document.addEventListener('click', (event) => {
const target = event.target.closest('a');
// we are interested only in anchor tag clicks
if (!target) {
return;
}
const url = target.getAttribute('href');
// we don't care about example.com#hash or
// example.com/#hash links
if (this.#startsWithHash(url)) {
return;
}
// if the link is leading to other page we
// need to disable default browser behavior
// to avoid page refresh
if (target.hostname === location.hostname) {
event.preventDefault();
this.#redirect(url);
}
// otherwise go to the given destination
}, false);#startsWithHash(string) {
const regEx = /^#/;
const startsWithHash = regEx.test(string);
return Boolean(startsWithHash);
}And finally the redirection:
#redirect(url) {
if (url === '/404') {
// replaces non existing page with 404 page
window.history.replaceState(null, null, url);
} else {
window.history.pushState(null, null, url)
}
// find the pattern and process it
this.#checkPatterns(url);
}History.replaceState() is there because we don't want to create a loop where the user goes back from /404 to /non-existing-url and gets redirected to /404 again. Fun fact: if you surf around the internet you will notice that each page handles 404 errors differently. Not letting users go back to the invalid page makes sense to me but it might not be the best approach.
Conclusion and next steps
We've made it to the end! I hope that you have enjoyed this short guide. Now you should have a glimpse of how more advanced solutions work. Personally, I use this solution myself - it's small and SEO friendly. The possible next step is to cover this small code with tests in case of any future improvements that potentially could impact the current version of the script.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK