

经历了源码的痛苦,掌握DRF的核心序列化器 - HammerZe
source link: https://www.cnblogs.com/48xz/p/16079976.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

DRF的核心--序列化器
上一篇介绍了很多有关视图类以及DRF中的APIView执行流程、Request对象的源码分析,源码都get了🐂;
DRF的核心当然不是知道视图类执行流程就可以了,DRF框架的核心那就是 序列化器的使用,如何使用序列化器实现 序列化、 反序列化,以及视图,这篇会介绍到~
什么是序列化和反序列化?
- 序列化:序列化器会把模型对象(QuerySet对象,比如book)转换成字典,经过response以后变成了json字符串
- 反序列化:将客户端(前端)发送过来的数据,经过request以后变成字典(data),序列化器可以把字典转换成模型存到数据库中
- 存数据库需要校验,反序列化就可以帮我们完成数据的校验功能
- 通俗理解为:
- 响应给前端的内容需要序列化(给前端看),存数据库的数据就反序列化;
- 序列化:模型对象----字典---json字符串
- 反序列化:json数据---字典----模型对象
导入:from rest_framework.serializers import Serializer
序列化demo#
- 在app中新建serializer.py,自定义类,继承DRF框架的Serializer及其子类
- 在类中写要序列化的字段(序列化哪些就写哪些,不序列化的不写)
- 使用序列化类,视图类中用,得到序列化类对象,对象.data,通过Response返回给前端
serializer.py:序列化类
from rest_framework import serializers
# 继承Serializer
class BookSerializer(serializers.Serializer):
'''
max_length=32
min_length=3 反序列化保存校验数据的时候用,序列化不用
'''
# 写要序列化的字段
title = serializers.CharField()
# models中使用了DecimalField,这个位置使用了CharField会把小数类型转成字符串,使用CharField或者DecimalField都可以
# 这里不需要担心反序列化存的问题
price = serializers.CharField()
authors = serializers.CharField()
views.py:视图类
from rest_framework.views import APIView
from .models import Book
from .serializer import BookSerializer
from rest_framework.response import Response
# Create your views here.
class BookView(APIView):
def get(self, request):
# 从数据库查数据,做序列化
book_list = Book.objects.all()
# 实例化类,传入初始化的参数,instance和many
'''
instance:要序列化的对象 qs,单个对象
many:如果是qs对象,many=True,如果是单个对象many=False
'''
ser = BookSerializer(instance=book_list, many=True)
# ser.data使用模型类的对象得到序列化后的字典
return Response(ser.data)
urls.py:路由
path('books/', views.BookView.as_view()),
model.py:模型类
from django.db import models
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5,decimal_places=2)
authors = models.CharField(max_length=32)
测试
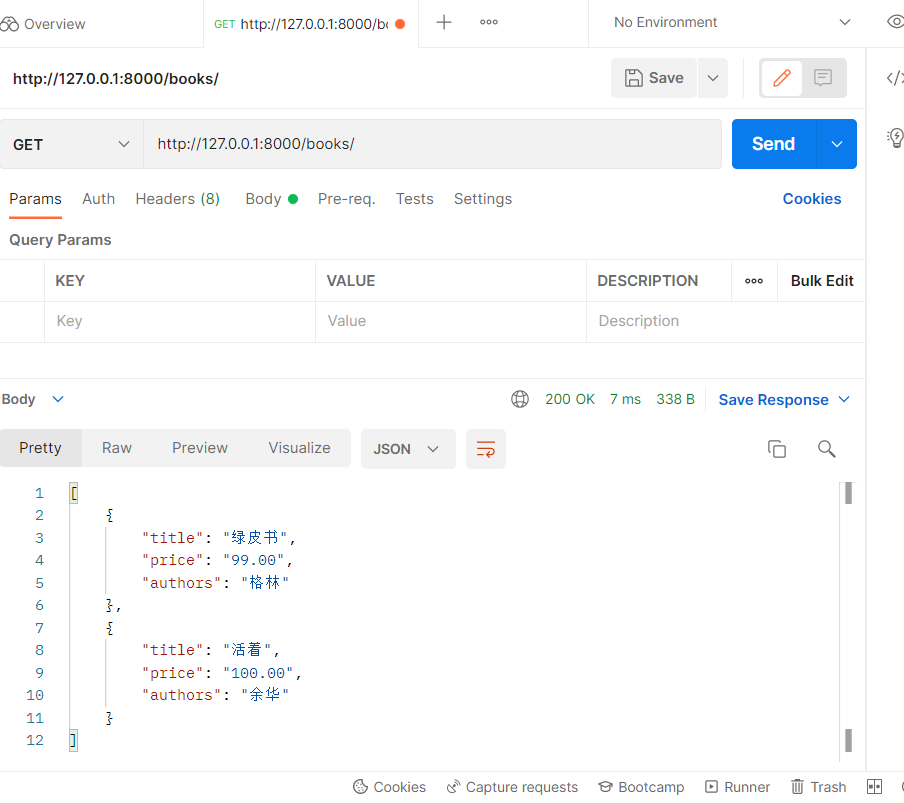
注意
- 视图类中的参数
instance和many的使用,instance是要序列化的对象,一般从数据库中获取到的,many=True代表要序列化多个对象,如果是单个对象就等于False - 序列化器中不要写max_length等参数,反序列化验证字段用
- 在对
BookSerializer类实例化传入的参数不知道传什么,由于我们没有写构造函数,去父类看需要什么参数传什么就可以了 - 使用浏览器测得时候一定要注册
rest_framework
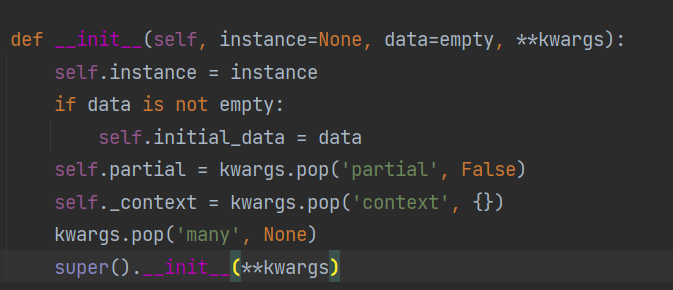
# 源码
class BaseSerializer(Field):
"""
The BaseSerializer class provides a minimal class which may be used
for writing custom serializer implementations.
Note that we strongly restrict the ordering of operations/properties
that may be used on the serializer in order to enforce correct usage.
In particular, if a `data=` argument is passed then:
.is_valid() - Available.
.initial_data - Available.
.validated_data - Only available after calling `is_valid()`
.errors - Only available after calling `is_valid()`
.data - Only available after calling `is_valid()`
If a `data=` argument is not passed then:
.is_valid() - Not available.
.initial_data - Not available.
.validated_data - Not available.
.errors - Not available.
.data - Available.
"""
BaseSerializer类提供了一个可以使用的最小类
用于编写自定义序列化器实现。
注意,我们严格限制了操作/属性的顺序
可以在序列化器上使用,以强制正确的使用。
特别是,如果传递了' data= '参数,则:
.is_valid()——可用。
.initial_data——可用。
.validated_data -仅在调用' is_valid() '后可用
.errors -仅在调用' is_valid() '后可用
.data -仅在调用' is_valid() '后可用
如果没有传递' data= '参数,则:
.is_valid() -不可用。
.initial_data -不可用。
.validated_data -不可用。
.errors -不可用。
. data -可用。
serializer.py文件中常用的字段
字段 字段构造方式
BooleanField BooleanField()
NullBooleanField NullBooleanField()
CharField CharField(max_length=None, min_length=None, allow_blank=False, trim_whitespace=True)
EmailField EmailField(max_length=None, min_length=None, allow_blank=False)
RegexField RegexField(regex, max_length=None, min_length=None, allow_blank=False)
SlugField SlugField(maxlength=50, min_length=None, allow_blank=False) 正则字段,验证正则模式 [a-zA-Z0-9-]+
URLField URLField(max_length=200, min_length=None, allow_blank=False)
UUIDField
UUIDField(format=’hex_verbose’) format: 1) 'hex_verbose' 如"5ce0e9a5-5ffa-654b-cee0-1238041fb31a" 2) 'hex' 如 "5ce0e9a55ffa654bcee01238041fb31a" 3)'int' - 如: "123456789012312313134124512351145145114" 4)'urn' 如: "urn:uuid:5ce0e9a5-5ffa-654b-cee0-1238041fb31a"
IPAddressField IPAddressField(protocol=’both’, unpack_ipv4=False, **options)
IntegerField IntegerField(max_value=None, min_value=None)
FloatField FloatField(max_value=None, min_value=None)
DecimalField DecimalField(max_digits, decimal_places, coerce_to_string=None, max_value=None, min_value=None) max_digits: 最多位数 decimal_palces: 小数点位置
DateTimeField DateTimeField(format=api_settings.DATETIME_FORMAT, input_formats=None)
DateField DateField(format=api_settings.DATE_FORMAT, input_formats=None)
TimeField TimeField(format=api_settings.TIME_FORMAT, input_formats=None)
DurationField DurationField()
ChoiceField ChoiceField(choices) choices与Django的用法相同
MultipleChoiceField MultipleChoiceField(choices)
FileField FileField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL)
ImageField ImageField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL)
ListField ListField(child=, min_length=None, max_length=None)
DictField DictField(child=)
常用的有:
CharField
IntegerField
FloatField
DecimalField
DateTimeField
DateField
注意:
'''
ListField和DictField原来的models是没有的,主要用来做反序列,处理前端传入的数据
'''
比如我们从前端接收json格式数据
"hobby":["篮球","足球"] 可以用ListField处理
"wife":{"name":"wh","age":20} DictField类似使用
写在类中的参数
选项参数:
参数名称 作用
max_length 最大长度(CharField)
min_lenght 最小长度(CharField)
allow_blank 是否允许为空(CharField)
trim_whitespace 是否截断空白字符(CharField)
max_value 最小值 (IntegerField)
min_value 最大值(IntegerField)
通用参数:
参数名称 说明
read_only 表明该字段仅用于序列化输出,默认False
write_only 表明该字段仅用于反序列化输入,默认False
required 表明该字段在反序列化时必须输入,默认True
default 反序列化时使用的默认值
allow_null 表明该字段是否允许传入None,默认False
validators 该字段使用的验证器(不太用)
error_messages 包含错误编号与错误信息的字典
label 用于HTML展示API页面时,显示的字段名称
help_text 用于HTML展示API页面时,显示的字段帮助提示信息
# 重点记忆:
read_only:表示该字段仅用于序列化输出,默认为Fasle,如果read_only = True,这个字段只用来做序列化(对象---json---前端)
write_only:表明该字段仅用于反序列化输入,默认False,如果write_only = True,那么这个字段只用来做反序列化(前端---json---存数据库)
# 注意
如果不写read_only和write_only表示及序列化又反序列化
千万不要同时写read_only=True和write_only=True逻辑矛盾了,都要实现直接省略即可
demo
title=serializers.CharField(max_length=32,min_length=3)
price=serializers.CharField(write_only=True,)
author=serializers.CharField(write_only=True)
# 上面title字段及序列化也反序列化,price,author字段只反序列化
# 序列化给前端,前端看到的字段样子---》只能看到name
# 反序列化,前端需要传什么过name,price,author都传
序列化自定制返回字段
如果我们想自定制序列化返回字段的样式,可以使用,有两种方法
方法一:在序列化类(serializers.py)中写#
'''serializer.py'''
from rest_framework import serializers
# 继承Serializer
class BookSerializer(serializers.Serializer):
# 写要序列化的字段
title = serializers.CharField(read_only=True)
price = serializers.CharField(write_only=True)
authors = serializers.CharField(write_only=True)
# 自定制返回字段
author_info = serializers.SerializerMethodField()
# 搭配方法,方法名必须是get_字段名,该方法返回什么字段,显示什么
def get_author_info(self,obj):
# obj是当前数据库book对象
return obj.authors+'牛掰'
# 注意字符串拼接的问题
price = serializers.SerializerMethodField()
def get_price(self,obj):
return "价格是:"+str(obj.price)
总结:
- 可以自定义返回的key或者value,比如price可以自定义成price_down,通过返回值来控制value
- 在序列化类中写需要搭配
get_字段的方法,来自定制字段
方法二:在表模型(models.py)中写#
'''models.py'''
from django.db import models
# Create your models here.
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5,decimal_places=2)
authors = models.CharField(max_length=32)
@property
def price_info(self):
return '价格是:'+str(self.price)
'''serializer.py'''
from rest_framework import serializers
# 继承Serializer
class BookSerializer(serializers.Serializer):
# 写要序列化的字段
title = serializers.CharField(read_only=True)
price = serializers.CharField(write_only=True)
authors = serializers.CharField(write_only=True)
# 该字段是从models的price_info返回值获取到的,price_info方法返回什么,这个字段就是什么
price_info = serializers.CharField()
总结:
- 在models中写和序列化类中写的区别是,models中处理完返回给序列化类中继续当成字段处理了
注意:
如果是返回的是这种格式的数据,需要那么序列化类中就不能指定CharField类型,这样会直接返回字符串类型,不方便后期的处理,需要指定成ListField等类型
'''models.py'''
def authors(self):
return [{"name":"Hammer","age":18},{"name":"Hans","age":28}]
'''serializer.py'''
authors = serializers.ListField()
反序列化demo#
-
把前端传入的数据,放到Serializer对象中:ser=BookSerializer(data=request.data)
-
校验数据:ser.is_valid()
-
保存,ser.save(),但是必须重写create,在序列化类中
反序列化新增
POST请求处理新增
'''views.py''' from rest_framework.views import APIView from .models import Book from rest_framework.response import Response from app01.serializer import BookSerializer class BookView(APIView): def post(self,request): # 反序列化,保存到数据库使用data参数 deser = BookSerializer(data=request.data) # 校验数据 if deser.is_valid(): # 保存需要重写create方法,不然不知道存到哪个表 deser.save() return Response(deser.data) return Response({'code':101,'msg':'校验不通过','errors':deser.errors})重写create方法
'''serializer.py''' def create(self, validated_data): # validated_data是校验通过的数据,将校验通过的数据打散存入数据库 book = Book.objects.create(**validated_data) return book
反序列化修改
# 处理修改再写一个视图类,防止get冲突
class BookDetailView(APIView):
# 获取一条的
def get(self,request,pk):
book = Book.objects.filter(pk=pk).first()
ser = BookSerializer(instance=book) # 这里设置了主键值,单条记录many不需要写
return Response(ser.data)
# 删除一条的
def delete(self,request,pk):
res = Book.objects.filter(pk=pk).delete()
print(res) # (1, {'app01.Book': 1})
# res是影响的行数
if res[0]>0:
return Response({'code': 100, 'msg': '删除成功'})
else:
return Response({'code': 103, 'msg': '要删除的数据不存在'})
# 反序列化修改
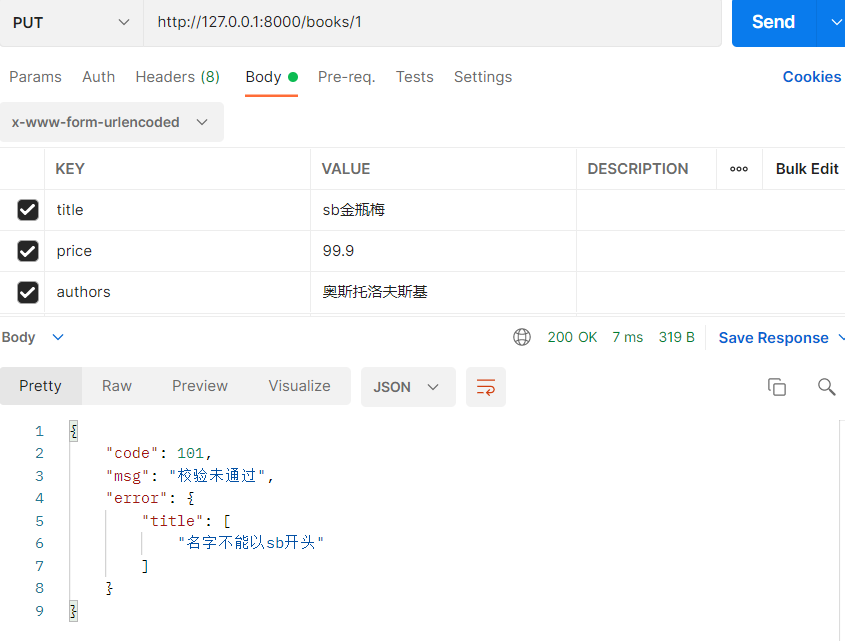
def put(self,request,pk):
# 修改处理单条数据用过pk确定求改哪条数据
book = Book.objects.filter(pk=pk).first()
# 序列化器类实例化需要传入instance,data才表示修改
ser = BookSerializer(instance=book,data=request.data)
if ser.is_valid():
# 重写update方法才能存入
ser.save()
return Response(ser.data)
return Response({'code':101,'msg':'校验未通过','error':ser.errors})
重写update方法
'''serializer.py'''
def update(self, instance, validated_data):
'''
:param instance: 表示要修改的对象
:param validated_data: 校验通过的数据
:return: instance
'''
# 如果只修改一个的情况,从校验通过的数据中get到其他数据是none,做一层校验
instance.title = validated_data.get('title')
instance.price = validated_data.get('price')
instance.authors = validated_data.get('authors')
instance.save() # 保存到数据库中
return instance # 返回instance对象
路由
urlpatterns = [
path('admin/', admin.site.urls),
path('books/', views.BookView.as_view()),
path('books/<int:pk>', views.BookDetailView.as_view()),
]
为什么不重写就会抛异常?
# 源码
def save(self, **kwargs):
assert hasattr(self, '_errors'), (
'You must call `.is_valid()` before calling `.save()`.'
)
def update(self, instance, validated_data):
raise NotImplementedError('`update()` must be implemented.')
def create(self, validated_data):
raise NotImplementedError('`create()` must be implemented.')
def save(self, **kwargs):
assert hasattr(self, '_errors'), (
'You must call `.is_valid()` before calling `.save()`.'
·····
if self.instance is not None:
self.instance = self.update(self.instance, validated_data)
assert self.instance is not None, (
'`update()` did not return an object instance.'
)
else:
self.instance = self.create(validated_data)
assert self.instance is not None, (
'`create()` did not return an object instance.'
)
return self.instance
'''
发现如果我们传了instance不是空的,那么就是修改(update),不传就是新增(create),调用save,父类不然就抛异常
'''
总结
- 不管是序列化使用get方法或者反序列化使用post方法都需要序列化类实例化,如果有
instance参数代表是序列化,如果有data参数代表是新增,如果都有就是修改
注意
-
如果保存不重写create方法,报错
NotImplementedError at /books/ `create()` must be implemented. -
如果修改不重写update方法,报错
NotImplementedError at /books/1 `update()` must be implemented.
反序列化之局部和全局钩子#
'''serializer.py'''
# 局部钩子
def validate_title(self,attr):
# attr就是前端传入的数据
# 局部校验书名
if attr.startswith('sb'):
from django.core.exceptions import ValidationError
raise ValidationError("名字不能以sb开头")
else:
return attr # 没有问题,正常返回
'''
校验顺序:先走字段自己规则,再走局部钩子,再走全局钩子
'''
# 全局钩子
def validate(self,attrs):
# attrs校验过后的数据,通过了前面校验的规则
if attrs.get('title') == attrs.get('authors'):
from django.core.exceptions import ValidationError
raise ValidationError('作者名不能等于书名')
else:
return attrs

ModelSerializer模型类序列化器
# ModelSerializer和表模型有绑定关系
class BookSerializer1(serializers.ModelSerializer):
class Meta:
model = Book # 指定和哪个表有关系
# 所有字段
# fields = '__all__'
# 这里注意id字段是从表模型映射过来的,auto自增的,不传也可以
# 自定制的字段不传必须注册,在列表中
fields = ['id', 'title', 'price', 'price_info'] # 指定字段
extra_kwargs = {
'title': {'write_only': True, 'max_length': 8, 'min_length': 3}
}
# 指定序列化的字段:两种写法:在序列化类中写;models中写
price_info = serializers.SerializerMethodField()
def get_price_info(self, obj):
return "价格是:" + str(obj.price)
'''
注意:自定制字段如果和表模型获取到的字段是同名,那么自定制返回给前端的字段值就被自定制覆盖了,比如:
title = serializers.SerializerMethodField()
def get_title(self, obj):
return "书名是:" + str(obj.title)
'''
# 局部和全局钩子,跟之前一样,但是要注意写在Meta外
ps:视图类,路由处理方式和Serializer是一样的
字段参数#
ModelSerializer中的字段传参不需要在去括号内指定了,通过extra_kwargs传
extra_kwargs = {
'title': {'write_only': True, 'max_length': 8, 'min_length': 3}
}
总结
- ModelSerializer类序列化器不需要重写create方法和update方法了,因为明确指定了操作哪个表
- 固定写法,ModelSerializer类内写Meta类,用来指定一些字段和表模型
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK