

针对常见混淆技术的反制措施
source link: https://netsecurity.51cto.com/article/705272.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

现代软件经常将混淆技术作为其反篡改策略的一部分,以防止黑客逆向分析软件的关键组件。他们经常使用多种混淆技术来抵御黑客的攻击,这有点像滚雪球:随着雪层的增多,软件规模也随之变大,使其逆向分析难度随之提高。
在这篇文章中,我们将仔细研究两种常见的混淆技术,以了解它们是如何工作的,并弄清楚如何去混淆。
这里,我们将研究以下混淆技术:
基于IAT导入表的混淆技术
基于控制流的混淆技术
基于IAT导入表的混淆技术
在深入介绍基于IAT导入表的混淆方法之前,先让我解释一下导入表到底是什么。
什么是导入函数?
当进行逆向分析时,需要弄清楚的第一件事,就是它如何调用操作系统的函数。在我们的例子中,我们将重点关注Windows 10系统,因为大多数视频游戏只能在Windows系统上运行。无论如何,对于那些还不知道的人来说,Windows提供了一系列重要的动态链接库(DLL)文件,几乎每个Windows可执行文件都会用到这些库文件。这些DLL文件中保存了许多函数,可以供Windows可执行文件“导入”,使其可以加载和执行给定DLL中的函数。
它们为何如此重要?
例如,Ntdll.dll库负责几乎所有与内存有关的功能,如打开一个进程的句柄(NtOpenProcess),分配一个内存页(NtVirtualAlloc,NtVirtualAllocEx),查询内存页(NtVirtualQuery,NtVirtualQueryEx),等等。
另一个重要的DLL库是ws2_32.dll,它通过以下函数处理各种网络活动:
Socket
Connect / WSAConnect
Send / WSASend
SendTo / WSASendTo
Recv / WSARecv
RecvFrom / WSARecvFrom
现在读者可能会问,知道这些有什么意义呢?好吧,如果您把一个二进制文件扔到像IDA这样的反汇编器中(我通常会做的第一件事),就是检查所有导入的函数,以便对二进制文件的功能有一个大致的了解。例如,当ws2_32.dll存在于导入表中时,表明该二进制文件可能会连接到Internet。
现在,我们可能想要进行更深入的研究,并考察使用了哪些ws2_32.dll函数。如果我们使用Socket函数并找出它的调用位置,我们就可以检查它的参数,这样,我们就可以通过搜索引擎查找相应的函数名,从而轻松地找出它所使用的协议和类型。
注意:IDA已自动向反汇编代码中添加了注释。
经过混淆处理的导入表
无论如何,这些Windows函数能提供相当多的信息,因为它们是有据可查的函数。因此,攻击者希望能够把这些函数藏起来,以掩盖正在发生的事情。
我们在反汇编器中看到的所有这些导入函数都是从导入地址表(IAT)加载的,该表在可执行文件的PE头文件中的某个地方被引用。一些恶意软件/游戏通常试图通过不直接指向DLL函数来隐藏这些导入地址。相反,他们可能会使用一个蹦床或迂回函数。
考察我们的示例
在这个例子中,我们使用的是一种蹦床式混淆技术,具体如下所示:
下面的地址0x7FF7D7F9B000引用了我们的函数0x19AA1040FE1,尽管看起来完全不是这么回事。您可能认为这是垃圾代码,但仔细看看,您会发现并非如此。
请仔细查看前两个指令:前面的指令是mov rax, FFFF8000056C10A1,后面的指令是jmp 19AA1040738,后面的都是垃圾指令。不管怎样,让我们跟随跳转指令,看看它会跳到哪里:
看,又是4个有效的指令,这次是一个异或指令和两个加法指令,然后是另一个跳转指令。让我们把这个过程再重复几遍...
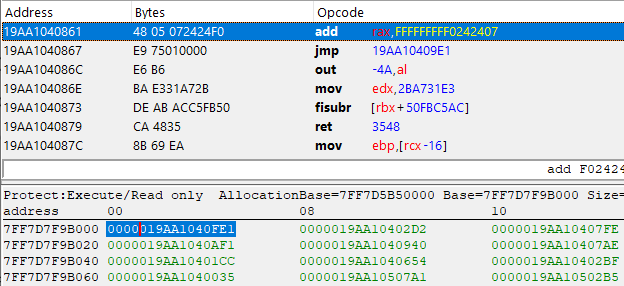
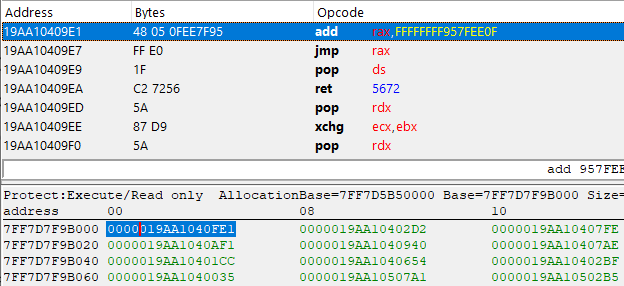
最后,我们来到jmp rax指令!需要注意的是,所有的XOR、SUB和ADD指令都是在Rax寄存器上执行的,这意味着它可能包含导入函数的实际指针。下面,让我们算算看。
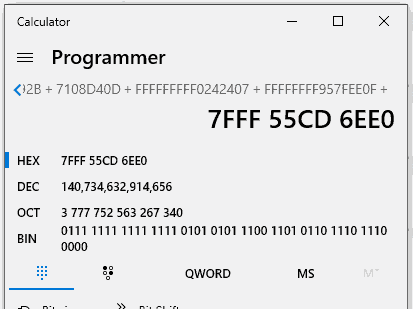
实际上,在经过数学运算之后,我们得到了指向advapi32.regopenkeyexa的指针!
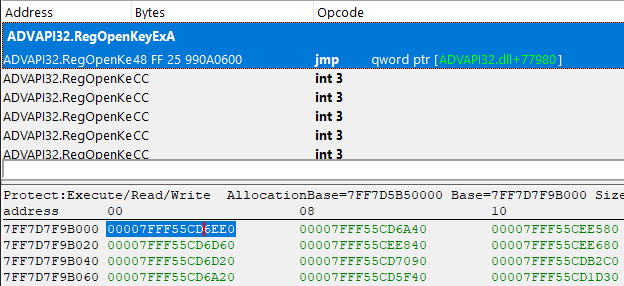
现在,我们所要做的就是重复几百次运算,从而彻底消除针对IAT导入表的混淆处理。
基于IAT的自动去混淆处理
我想,没有人喜欢用计算器手工重复上述过程,做一次已经很烦了。从现在开始,我们将使用C#实现自动计算。正如您可能已经看到的,我们只需要处理在同一个寄存器上执行的ADD、SUB和XOR操作。原因是Rax被用作返回地址,而诸如Rcx、Rdx、R8、R9和其他寄存器对于被调用方来说是不安全的,并且可能与调用约定冲突。这意味着,我们甚至不需要使用反汇编器,因为我们可以很轻松地区分这些指令,这要归功于涉及的寄存器和操作码寥寥无几。
到此为止,我们已经详细解释了混淆处理技术。接下来,大家不妨以Unsnowman项目中的importfix.cs为例,来了解与去混淆处理相关的代码。
基于控制流的混淆技术
在逆向分析二进制文件时,另一个有价值的信息来源是汇编指令本身。对于人类来说,它们可能难以理解,但对于像IDA这样的反编译器来说,我们只需按下F5键,IDA就会生成我们人类可以理解的伪代码。
混淆实际指令的一个简单方法,是组合使用垃圾代码和不透明分支(即该分支条件总是为不成立,也就是说,该分支用于也不会被执行)。这意味着:把垃圾代码放在一个分支指令之后。诀窍在于,我们可以使用条件转移,但是,要确保条件永远为真,这样分支就会一直被执行。反汇编器不知道的是,条件跳转在运行时总是为真,这使得它相信条件跳转的两个分支都可以在运行时到达。
好吧,如果还不太明白的话,可以借助下面的截图来加深理解。第一张截图显示的是落到另一条指令中的jbe。
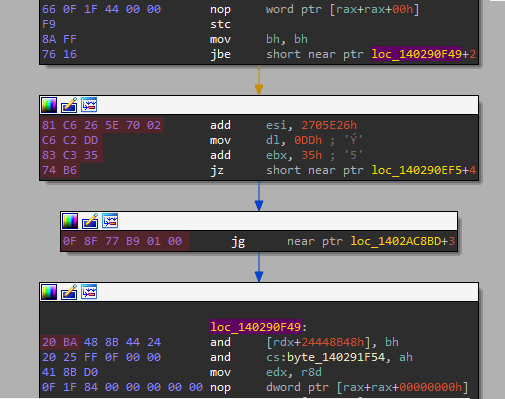
注意:用红色标记的字节是垃圾代码。
现在仔细看看下面的第二张图片,我在这里所做的只是NOP最后一条指令的两个字节,以便让IDA显示隐藏在and [rdx+24448B48h], bh指令后面的指令。
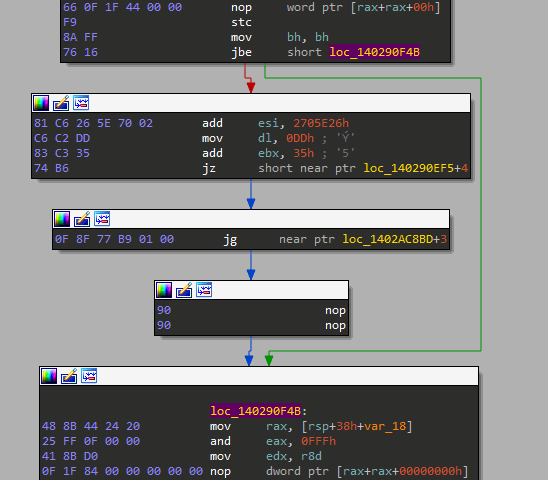
我们也可以用无条件跳转来修补条件跳转,以确保IDA不会再次上当。
在我们继续之前,我想展示最后一个例子,因为前面的例子太简单了。当我们将这些实现混淆处理的跳转链接起来时,事情就变得复杂起来,具体如下图所示。
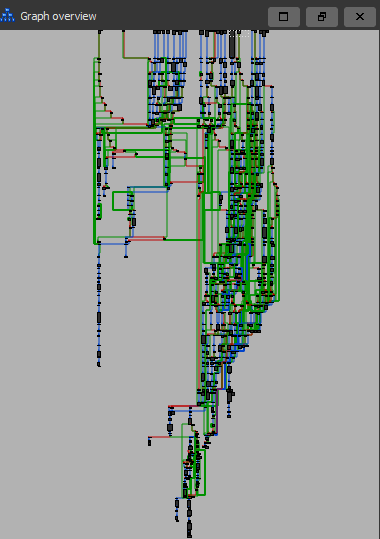
然而,这张图只显示了它在控制流方面造成的混乱,但想象一下,当IDA竭尽全力根据垃圾指令创建这张图时,我的CPU是多么的痛苦。
现在,您可能想知道去混淆后的函数到底是什么样子的,别急,请看下图!
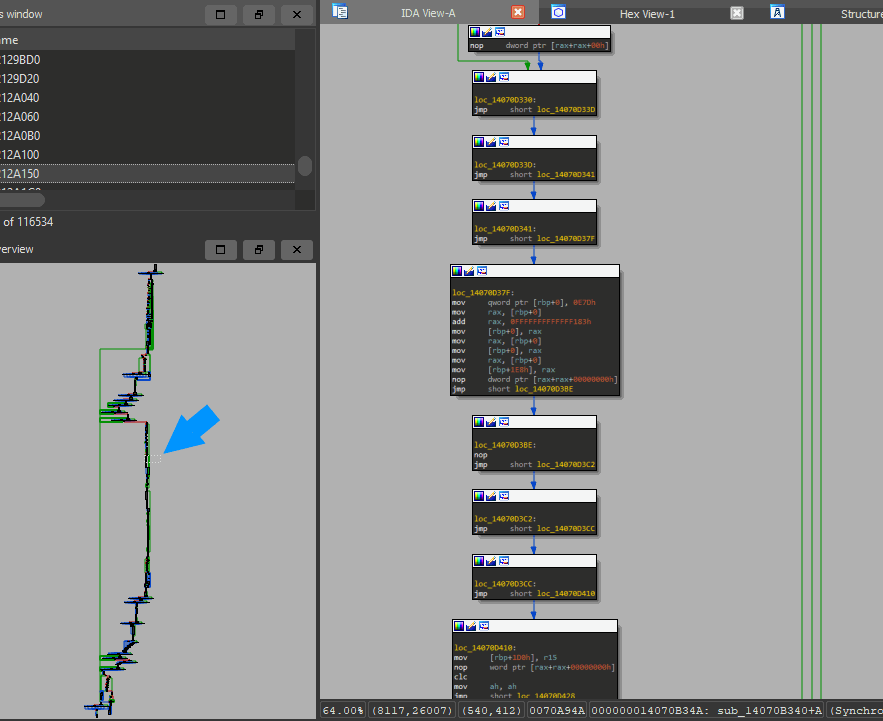
看到我在左边画的那个蓝色小箭头了吗?右边显示的就是这部分内容的放大版本。现在看一下右边,在函数的一小部分中就有七个去混淆的跳转。想象一下,以手动或半自动方式去混淆得需要多少时间。实际上,就算用IDA脚本手工完成这个过程,也花了我40分钟……这还只是处理了一个函数。设想一下,为了找到真正要找的东西,还得需要处理多少其他的函数呢?!
基于控制流的自动去混淆技术
好了,现在我们已经考察了基于控制流的去混淆原理,接下来,我们将对这个过程实现自动化。正如我之前提到的,我们曾经用IDA脚本来修补无条件跳转指令,并将垃圾指令替换为NOP指令。
然而,这个去混淆过程还是花了我40分钟,因为识别不透明的分支非常费劲。那么,我们该如何解决这个问题呢?大家可能认为应该检查每一个条件跳转指令,并检查它是否是不透明的,如果是的话,就用NOP替换它,然后重复上述过程,对吧?错了!
让我告诉你一个秘密,我们并不关心什么是不透明的,或诸如此类的事情。我真正关心的是,当我按下F5键时,IDA能否返回反编译好的代码——只要这些经过混淆的跳转指令导致垃圾指令与实际的汇编指令发生冲突,这种情况就不会发生。
但这是否意味着我们需要弄清楚一个条件跳转是否是不透明的呢?不,我们只需检查跳转操作是否与现有的指令相冲突,如果是的话,就对这个指令进行相应的修改,就像我们第一个例子中看到的那样。
DeFlow去混淆算法
现在,我们知道了如何解决这个问题,下面,我们开始深入研究本人想出的算法,以便对用这种混淆技术处理的内容进行去混淆。
var disasm = new Disassembler(buffer, address - base); // NOTE: base = BaseAddress + .text offset
foreach(var insn in disasm.Disassemble())
ulong target = 0;
ulong lastAddrStart
bool isJmp = true;
switch(insn.Mnemonic)
// Stop analysing when we encounter a invalid or return instruction while we have no lastTarget
case ud_mnemonic_code.Invalid:
case ud_mnemonic_code.Ret:
if(lastTarget == 0)
return newChunks; // Only accept when no lastTarget as we may be looking at junk code
break;
case ud_mnemonic_code.ConditionalJump: // all conditional jumps
if(lastTarget == 0)
target = calcTargetJump(insn); // Helper to extract jump location from instruction
if(!isInRange(target)) // Helper to see if target address is located in our Buffer
isJmp = false;
break;
// Check if instruction is bigger then 2, if so it wont be obfuscated but we
// do want to analyse the target location
if(insn.Length > 2)
isJmp = false;
newChunks.Add(target);
break;
else
isJmp = false; // Do not this conditional jump accept while we already
// have a target (might be looking at junk code)
break;
case ud_mnemonic_code.UnconditionalJump:
case ud_mnemonic_code.Call:
if(lastTarget == 0)
ulong newAddress = calcTargetJump(insn); // Helper to extract jump location from instruction
if(!isInRange(newAddress))
isJmp = false;
break;
// Add target and next instruction IF not JMP (CALL does return, JMP not)
if(insn.Mnemonic == ud_mnemonic_code.Call)
newChunks.Add(address + insn.PC);
// Add instruction target for further analyses
newChunks.Add(newAddress);
return newChunks;
break;
// quick mafs
ulong location = (address+insn.Offset);
stepsLeft = (int)(lastTarget - location); // Only valid if we have a lastTarget!
// Setup a new target if current instruction is conditional jump while there is no lastTarget
if(lastTarget == 0 && isJmp)
lastBranch = loction;
lastBranchSize = insn.Length;
lastTarget = target;
else if (stepsLeft <= 0 && lastTarget != 0)
// if stepsLeft isn't zero then our lastTarget is located slighlt above us,
// meaning that we are partly located inside the previous instruction and thus we are hidden (obfuscated)
if(stepsLeft != 0)
int count = lastTarget = lastBranch; // calculate how much bytes we are in the next instruction
if(count > 0)
// making sure we are a positive jump
int bufferOffset = lastBranch - base; // subtract base from out address so we can write to our local buffer
// NOP slide everything except our own instruction
if(int i = 0; i < count - lastBranchSize; i++)
buffer[bufferOffset + lastBranchSize + i] = isNegative ? 0x90 : 0xCC; // We use NOP for negative jumps
// and int3 for positive
if(!isNegative)
buffer[bufferOffset] = 0xEB; // Force unconditional Jump
// add next instruction for analyses and exit current analysis
newChunks.Add(lastTarget);
return newChunks;
else
// we are a negative jump, set 63th bit to indicate negative jump
lastTarget = |= 1 << 63;
// add target to analyser and exit current analysis
newChunks.Add(lastTarget);
return newChunks;
else
// stepsLeft was zero, meaning there is no collision
// add both target address and next instruction address so we can exit current analysis
newChunks.Add(lastBranch + lastBranchSize);
newChunks.Add(lastTarget);
return newChunks;
return newChunks;
注意:这里显示是伪代码,并且我知道它无法正常运行! (真的)
代码很长,是吧?同时,它比基于IAT导入表的去混淆处理更难理解,因为我们使用了一个实际的反汇编库来获得每个指令的大小和助记符。使用反汇编器几乎是必须的,因为我们还必须弄清楚一条指令是否与其他指令相冲突。
伪代码中提供了大量的注释,可以帮助大家理解其中的工作原理。
关于DeFlow算法的深入解释
主函数在递归调用DeflowChunk进行线性反汇编时,会跟踪已经发现的块。对新发现的块的跟踪是通过列表和循环完成的:由于在一个块中可能执行大量的分支指令,所以可能触发StackOverflow。
DeflowChunk将首先检查是否遇到给定的分支指令,如果是的话,则执行以下操作之一:
- Ret——如果没有设置lastTarget,则停止
- Invalid——如果没有设置lastTarget,则停止
- ConditionalJump——如果在我们的缓冲区范围内,则计算目标地址并跟踪
- UnconditionalJump——如果在我们的缓冲区范围内,则计算目标地址并保存以供进一步分析
- Call——如果在我们的缓冲区范围内,计算目标地址并保存以供进一步分析
如果我们没有设置lastTarget,将检查当前指令是否是在缓冲区范围内跳转的ConditionalJump(isJmp标志),如果是的话将lastTarget设置为ConditionalJump的目标。
一旦我们获得了符合条件的lastTarget,就用当前的指令指针减去lastTarget,从而计算出还需要反汇编多少字节(stepsLeft)。
在计算出stepsLeft之后,需要检查该值是否等于零。如果该值大于零,我们将继续线性反汇编。
当stepsLeft小于零时,表示汇编代码与下一条指令发生了冲突。这很可能意味着负责设置lastTarget的最后一个ConditionalJump是一个不透明的条件,这意味着我们当前的块很可能永远不会被执行,而是用来掩盖后面的几条合法的汇编指令。
我们可以通过将ConditionalJump的第一个字节修改为0xEB,使其成为UnconditionalJump,从而修复该问题。为了进一步扫清障碍,我们还修改了最后一个ConditionalJump和lastTarget之间的所有字节。
然后,对于在线性反汇编过程中发现的每个调用或条件跳转操作,都进行相应的处理。
不仅是恶意软件,像视频游戏这样的合法软件也倾向于使用这类混淆技术来尽可能多地隐藏有价值的信息,希望能防止软件被逆向工程。然而,正如您所看到的,我们已经成功地解开了这两种技术的神秘面纱,并能够揭示所有隐藏的信息。
无论如何,我们仍然可以得出结论:这些混淆技术极大地提高了逆向分析的难度,这是一个很好的方法,在一定程度上可以阻止软件被逆向工程。最重要的是,Deflow算法本身需要几分钟/小时(取决于文件大小),就能消除混淆技术对二进制文件的完整控制流造成的影响。
本文翻译自:https://ferib.dev/blog.php?l=post/Reversing_Common_Obfuscation_Techniques如若转载,请注明原文地址
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK