

天知道我从 MongoDB 到 ClickHouse 经历了什么……
source link: https://dbaplus.cn/news-162-4380-1.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

天知道我从 MongoDB 到 ClickHouse 经历了什么……
前言
在实现前端监控系统的最初,使用了 MongoDB 作为日志数据存储库。文档型存储,在日志字段扩展和收缩上都能非常方便。天生的 JSON 格式和 Node.js 配合也非常贴合。就这样度过了几个月的蜜月期。
而后有一天发现,表里的数据越来越大了(单表上亿),查询变慢了,特别是聚合查询。于是使用了各种优化手段:复合索引、时间条件约束、定期清理过老数据等等,但最终效果都不理想。
在事情的发展过程中也从同事口中了解到有一个叫ClickHouse的数据库,也许对目前的场景比较有帮助。于是,自己经历了:
-
MongoDB是最棒的
-
一定是我Mongo没用好,继续深入优化肯定能行
-
玩不动了, 看看ClickHouse吧
-
ClickHouse真香
的心路历程。到现在已经稳定使用ClickHouse许久之后,回顾历史,有了这篇文章。
一、MongoDB的苦与乐
在最开始使用 Mongo 时,觉得使用起来非常顺手。在使用过程中,也不断地进行过优化,下面大概说下几个核心设计点和遇到的问题。
-
分表
前端监控日志收集是按照应用和数据类型区分来建表的,这算作一定的优化和单元拆分,可以让数据不要全部集中在一起,也方便后期应用删除。在某些表数据量特别大的情况下,想要主从模式的单表按照时间分区,在mongo中,其实并不支持时间分区,只支持集群分片。
也考虑过按照月份再分表,这样的结果大概就是 app1_202101、app1_202102 这样来分,但是这样分的结果就是查询会被时间范围限制,不能方便的查连续的跨月的数据,会影响到我们很多的应用场景。
-
索引
日志数据主要更偏向于按照时间来查询,于是使用时间作为单索引。而后为了优化多字段聚合查询,还使用了基于实际查询条件的复合索引,但实际效果并不理想,而且索引本身会占据存储空间。
-
限制查询条件
最初进入后台系统的时候,没有限制时间,所以默认会查询所有时间范围的数据,在表数据量非常大的时候,就会需要很长时间,于是对所有查询都做了默认的时间条件限制。但这种方式治标不治本,也不能完全满足某些场景下的查询需求。
-
数据清理
既然表的数据量大,造成了查询缓慢,那就删除半年前的数据,使表的数据量维持在半年内。这时可能需要一个定时任务来删除半年前的数据,但其实数据量大的表也只是监控的某几个前端应用,只对这几个表做删除就行了(其他的应用查询性能不慢的能保留尽量保留),这里需要额外的判断逻辑。
在删除数据的过程中发现,当一个表上亿以后,我删除1个月左右的数据(大概千万级),数据库CPU直接拉满了,执行时间会非常长,这个时候我们查询和插入都会被影响到,这里提一嘴我们使用的主从模式。
没事,那就一天天地删除吧。清理了数据量大的表之后,又发现空间没有释放,Mongo 只有在删除集合时才会释放空间,只是移除数据,空间占用依然在,如果要释放空间,需要把数据库先停下来,但这样会影响正常使用。如果某一段时间某表的日志量上升,这个表空间占用会被拉大。突然发现这个优化方案也是治标不治本,难受~
-
explain 查询分析
在优化的过程中,也使用了 Mongo 的分析语句,做查询分析,但是发现事实就是,这些查询语句没啥问题,它就这个速度。
小结
随着,慢查询的增多,项目本身也成为了一个风险项目。最初前端监控系统和其他业务系统共享使用的云库,由于前端监控在某段时期存在数据库慢查询的问题,而这个慢查询刚好也是分钟级别的定时任务。导致数据库产生了很多慢查询,CPU 消耗也一直维持在较高位置。前端监控本身也会保持一定的监控数据并发量在做存储。前端监控拖累了整个数据库,并且由于慢查询日志很多,导致其它业务在排查数据库慢日志的时候,很难找到他们自己的日志。
后来,运维同事就给单独配置了一个独享数据库给前端监控,不是说同事给开小灶给福利,而是花点小钱,把我这颗毒瘤清理出去。
迁移前配置12核32g三节点(一主两从),迁移后为2核4g三节点。虽然配置变小了,但是前端监控独享数据库后平均响应速度反而变快了一些,猜测是因为迁移到新库,空间碎片较少和内存缓存只专注在一个库的原因。前端监控的数据是属于日志数据,量更大,导致数据库性能下降,影响到业务数据服务。日志系统的数据库和业务分离也是正确合理的。
基于以上种种吧,我感觉路已经走到头了,该尽力的也尽力了,换个方向了解下 ClickHouse 吧,看看目前的很多问题,它是不是能解决。
二、ClickHouse 全新认知
在最初听到 ClickHouse 的时候,会下意识认为 Mongo 还有空间可以优化,如果换库那成本得多高啊,于是就死磕 Mongo,用尽能想到的办法。其实现在回过头来看,有好有坏。好处是能够更加深刻的体会到 Mongo 数据库本身的特性,有实践作为检验标准,对后面对比 ClickHouse 有一定帮助。坏处是,对解决问题本身来说,浪费了一些时间,折腾得有点过头。现在开始介绍一下 ClickHouse 到底是怎样的一个数据库。
行存储和列存储
从数据存储结构来划分,这里把数据库分成了行数据库和列数据库两种。
-
行数据库
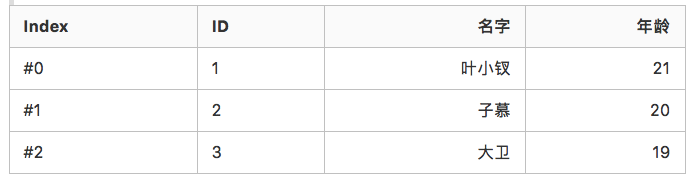
传统型数据库或者说大家最常用的数据库,大都是基于行的数据结构进行数据存储的,比如 Mysql、Mongo 等。通俗来说一个用户表有 id、name、year、 两个字段,我们插入的用户信息,就是按照一个完整的用户信息插入一行连续数据。
id:1,name: ‘叶小钗’, year: 21 -> 存储id:2,name: ‘子慕’, year: 20 -> 存储id:3,name: ‘大卫’, year: 19 -> 存储

-
列数据库
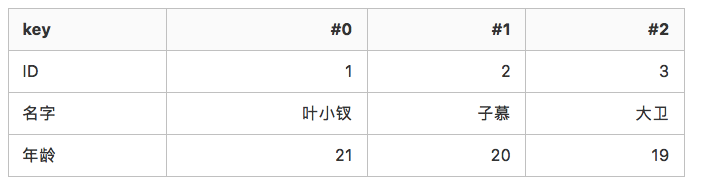
ClickHouse,是基于列的数据结构进行存储。通俗来说一个用户表有 name、id 两个字段,这两个字段就是列,我们插入用户信息,就是按照字段列来连续存储。
id: 1, 2, 3 -> 存储name: ‘叶小钗’, ‘子慕’, ‘大卫’ -> 存储year: 21, 20, 19 -> 存储

底层数据结构的区别,将会直接影响到具体的查询,以下的动图是 ClickHouse 官方文档的区别展示动图。如图所示,查询满足条件的3个字段的数据。图1中,行数据库在进行查询的时候,先一行行扫描数据,找到满足条件的3个字段返回,这个过程中,会读取到其它很多不需要的字段,这就增加了 I/O 造成了内存的浪费,减慢查询速度。
而图2,因为列数据库本身的存储就是以字段列来进行连续存储,因此只需要扫描这3列,就能找到满足条件的数据。
行数据库(图1):
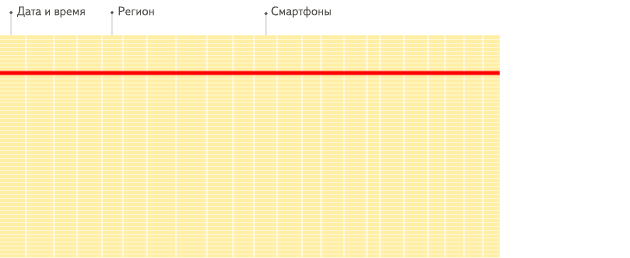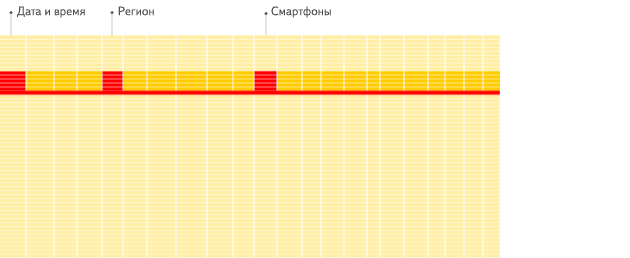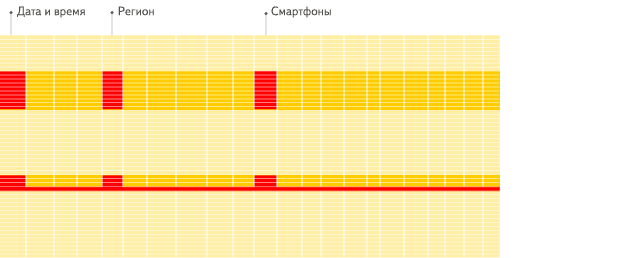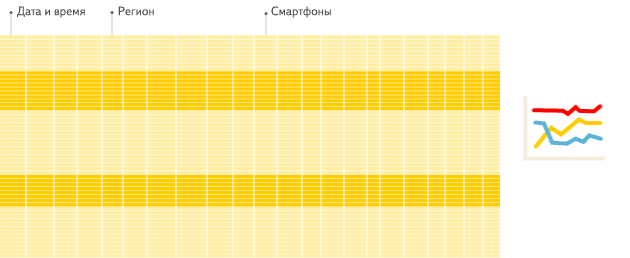
列数据库(图2):
行数据库复合索引
如果只是从上面的描述来看,初次了解到这样概念的同学可能会觉得。哇塞,这好厉害,完爆 MySQL、MongoDB 等数据库,以后我就用它吧!或者 MySQL 老玩家会说,切、这个问题用索引不就行了吗,别忽悠我!当然故事并没有这么简单,上面的内容也不全面,耐住性子,后面再继续道来。
MySQL 和 MongoDB 支持多字段建立复合索引,来提升查询速率。但是索引本身是需要占用额外的存储空间的,复合索引字段和数据量越多,就越浪费空间。并且复合索引有最左匹配限制,查询时无法灵活命中索引。
小结
从前面的内容我们讲到了,在使用 Mongo 这样的行数据库时,本人在遇到性能问题并折腾许久以后,已经黔驴技穷了。而后了解到了列数据库 ClickHouse,发现了行列数据库的核心区别,在对比查询的时候,发现原来列数据库这么厉害,那是不是行数据库就应该弃用了呢?那如果是这样的话,为啥 MySQL 还是那么主流?接下来,再讲讲,OLTP(联机事务处理)与OLAP(联机分析处理)。
三、OLTP与OLAP
OLTP(On-Line Transaction Processing)和OLAP(On-Line Analytical Processing)是两个不同应用场景的概念。
-
OLTP(联机事务处理)更加注重事务处理,重点在执行数据库的写操作(增删改),要求写操作的实时性和安全性。
-
OLAP(联机分析处理)更加注重数据分析,重点在执行数据库的读操作,要求查询操作的实时性。
传统的数据库如 MySQL 主要是侧重支持 OLTP,在数据量小的情况下,大部分时候是没有查询性能瓶颈的。因此,很多时候大家都主要接触这类数据库。随着技术的发展和互联网用户的增多。在面对大数据量查询性能无法突破,于是发现需要换个更加利于 OLAP 的分析型数据库了。
对于数据的生产,大部分时候,我们离不开传统 OLTP 数据库,所以常常是使用 OLTP 数据库做业务数据存储(方便增删改),后续通过解析业务数据,再把数据清洗一部分到 OLAP 数据库中做专门的查询分析。如此两类数据库并存,做到了读写分离,各自做自己更擅长的事情。
现在流行的数仓,就是采用这样的架构。下图的数据源,使用的 OLTP 数据库,经过 ETL(抽取extract、转换transform、加载load)存储到使用 OLAP 类数据库的数据仓库之中。
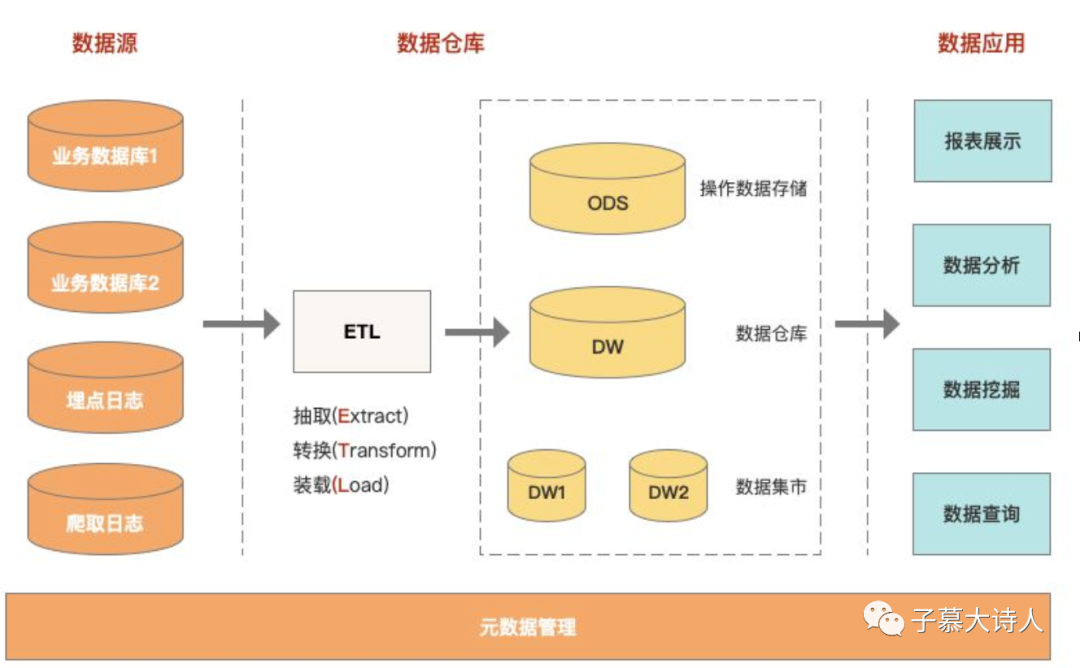
在我们开始用 ClickHouse 之后,为了提升某些业务数据的查询效率,也通过定时同步的方式,把 MySQL 数据同步到了 ClickHouse,再进行查询分析。
当然如果服务端收集到的第一手数据,通过服务逻辑整理后可以直接存储,并且后期不会变更,也可以不使用 OLTP 型数据库 + ETL,而是直接把数据存储到 OLAP 分析型数据库存储。我们的前端监控现在就是这样使用的。
小结
从两种应用场景概念出发,我们知道了行数据库擅长增删改,列数据库擅长查询。如果清晰了他们的区别,就能够再根据不同系统需求,设计更合适的数据库方案。
四、ClickHouse 优劣
官方的文档比较详细的描述了它的特点,文档中每一个概念都能引申出非常多的知识。ClickHouse 有着优越的查询性能和压缩性能,这是比较突出的。在同类型数据库跑分中,也是位列前茅。它的优势和特点在官方有详细的介绍,这里不多说了。Distinctive Features of ClickHouse。
它的劣势我认为目前比较明显的是社区建设还差了点,它并没有 Mysql 那么成熟,有很多配套并没有三方库支持。
性能对比
在使用了 ClickHouse 之后,基于当前系统同一结构的数据表,与 Mongo 做了条件查询能力和存储空间性能的对比,确实提升了不少,这里的查询能力提升和存储能力提升,也印证了它列存储格式条件查询的优势与其压缩上的优势,当然最后还是提一嘴两种不同类型的数据库做比较本身是不公平的。对比如下图:
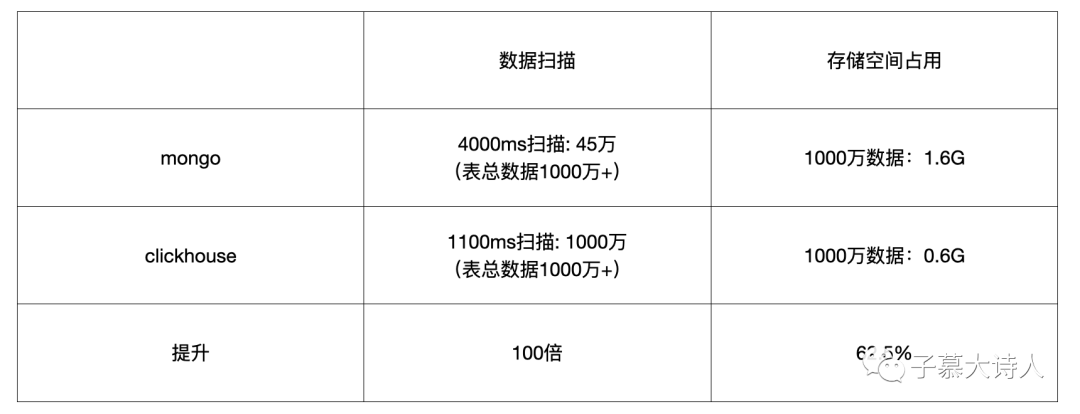
使用 ClickHouse 之后除了解决了查询性能问题,还同时节省了存储空间。特别爽的一点是,以前在 Mongo 中移除了数据,但是空间并没有释放的问题,也没有了。我们通过给数据表配置时间分区,ClickHouse 将会按照时间拆分数据库文件,我可以执行删除分区,使数据删除和空间释放,这延长了硬件存储空间固定情况下日志数据的保留时间。
按照月份分区:
CREATE TABLE xxx (time DateTime,status Int32,)ENGINE = MergeTreePARTITION BY toYYYYMM(time)ORDER BY time
数据表文件夹结构:

删除月份数据SQL:
ALTER TABLE xxx DROP PARTITION '202104'五、使用中的一些记录
-
新 API 较多、旧版本不支持
由于迭代比较快,所以文档中的一些语法可能在不久前的数据库版本中并不支持。一定要多注意当前使用的数据库版本,尽量保证生产环境、测试环境、还有本地环境是同一个版本的 ClickHouse。
-
支持 MySQL 协议,但有限制
ClickHouse 支持 MySQL 协议,可以使用 MySQL 连接方式和 SQL 语法。打开 ClickHouse 9004 端口便可通过 Mysql 连接库配置地址端口账户密码,进行连接和查询。这对于使用者是友好的。但是会有些限制,比如不支持预编译、某些数据类型会被当作字符串传递。
-
MySQL ORM 问题
ORM(对象关系映射Object Relational Mapping)它可以抹平一些数据库操作成本,帮助我们提升开发效率。既然 ClickHouse 提供了 MySQL 协议,因此理论上其实也可以使用 MySQL ORM 库。
我使用的 Node,因此用 Sequelize 作为 ORM 库, 驱动程序使用 Mysql2。由于建表和数据类型的差异原因,因此并不能用 MySQL 的 ORM 库管理 ClickHouse 的表结构。只能使用 SQL 语法。
在使用 select * 语句的时候,由于 ORM 会把转换为所有字段,就会变成 select id,key1,key2,key3,因为 ClickHouse 并没有默认使用自增 id 字段,这时就会报错,那大不了指定所有字段列,勉强还能用。
在使用 save 方法保存数据的时候(也就是 insert 语句),收到一个 ClickHouse 的报错:
MySQLHandler: MySQLHandler: Cannot read packet: : Code: 48, e.displayText() = DB::Exception: Command [ERRFMT] is not implemented., Stack trace (when copying this message, always include the lines below)报错信息描述的并不是很准确,经过一段时间源码追踪,根据下面的上下文,目测是 Mysql2 包传递到 ClickHouse 之后,有部分命令,并不支持。MySQLHandler.cpp.html#183 。
而后从 Mysql2 源码看出来,其默认使用了 PrepareStatement,会通过此语句进行预处理,而 ClickHouse 对于 Mysql 协议不支持预编译。所以最后的结论是 ClickHouse 可以使用 Mysql 协议,但是并不支持使用 Mysql ORM库,有这样的限制对于实际应用开发并不友好。
-
CLICKHOUSE ORM
经过评估选择了 ClickHouse 的 HTTP接口 调用数据库。从官方的三方客户端库( client-libraries)中选择了 TimonKK/clickhouse 这个库。它主要是实现了一个连接驱动,当然HTTP是无状态的,它就是做了一些封装,帮忙组装HTTP请求,而我们只需要写SQL语句就行。
只有一个驱动还不行,没有ORM的加成,开发体验并不好,效率也偏低。于是自己参考了 Mongoose(ODM)和 SequelizeJS 的使用习惯,开发了一个比较基础的 ClickHouse ORM:https://github.com/zimv/node-clickhouse-orm。因为 ClickHouse 熟悉度不够,自己在这方面知识能力也不足,并且投入成本太高了,所以就只实现了一部分平时我用到的功能。
目前还没有推广,使用量也很小,最近也就是2022年2月中旬左右,对此库进行了改造,目前已经发布了2.0.0内测版本https://www.npmjs.com/package/clickhouse-orm/v/2.0.0-alpha.0。
后续它还会迭代和维护,但是一个人的精力和能力有限,所以我打算建个开源交流群,欢迎体验和入群参与讨论。
-
ORM/ODM
-
ORM:Object Relational Mapping
-
ODM:Object Document Mapping
之前有一点迷惑这个 ORM 和 ODM 到底有啥区别,为什么名称不一样。Mongoose 被称为 ODM,并不是 ORM,但是它们看起来没啥区别,就因为 Mongo 是文档型数据库,这里就硬要改个 ODM 的名字?
最后想了下,虽然它们的名称有点区别,但是它们的本质还是将数据的存储格式抽象为程序中的逻辑对象,让使用方通过操作对象就能和数据库交互。都是数据库中间件,因数据库类型不同叫法不同。而且 Mongo 本身的数据库操作语法就已经是对象的操作方式了,它和 Mysql 这种也是有所区别。
-
推荐 LightHouse GUI工具
LightHouse是 ClickHouse 的 GUI 工具,用这个名称的库比较多,不要搞混了。它是用 HTML 开发的,所以只需要直接下载代码库到本地,然后用浏览器运行就行,都不需要启动服务器来运行,直接双击打开即可。
这个工具功能比较简单,但是也比较安全。使用的 HTTP 接口和数据库交互,它的 Ajax 请求 Query 里有一个readonly=1,因此工具本身主要是用来做查询的,如果想要做其它 SQL 操作,可以改源代码去掉readonly=1。
结语
系统引入 ClickHouse 之后,带来了极大的性能提升。但系统并非不再使用 Mongo,系统本身的元数据和一些需要常修改的数据依然还是使用的 Mongo。
天啦,从 Mongo 到 ClickHouse 我经历了各种折腾,各种知识学习,各种技术尝试,最后折腾下来还是收获满满~
好了,今天的内容就到这里了。对于这些数据库使用的经验包,还是来自于持续迭代前端监控系统。我之前已经写过几篇关于前端监控的博客,大家可以关注我,回顾之前的文章,喜欢的话希望你一键三连~
点击查看原文:天啦,从Mongo到ClickHouse我到底经历了什么?
作者丨子慕大诗人 来源丨公众号:子慕大诗人(ID:gh_d63a56e9b188) dbaplus社群欢迎广大技术人员投稿,投稿邮箱:[email protected]
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK