

为什么我建议线上高并发量的日志输出的时候不能带有代码位置
source link: https://www.cnblogs.com/zhxdick/p/16057619.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

为什么我建议线上高并发量的日志输出的时候不能带有代码位置
个人创作公约:本人声明创作的所有文章皆为自己原创,如果有参考任何文章的地方,会标注出来,如果有疏漏,欢迎大家批判。如果大家发现网上有抄袭本文章的,欢迎举报,并且积极向这个 github 仓库 提交 issue,谢谢支持~
本文是“为什么我建议”系列第二篇,本系列中会针对一些在高并发场景下,我对于组内后台开发的一些开发建议以及开发规范的要求进行说明和分析解读,相信能让各位在面对高并发业务的时候避开一些坑。
往期回顾:
在业务一开始上线的时候,我们线上日志级别是 INFO,并且在日志内容中输出了代码位置,格式例如:
2022-03-02 19:57:59.425 INFO [service-apiGateway,,] [35800] [main][org.springframework.cloud.gateway.route.RouteDefinitionRouteLocator:88]: Loaded RoutePredicateFactory [Query]
我们使用的日志框架是 Log4j2,方式是异步日志,Log4j2 的 Disruptor 的 WaitStrategy 采用了比较平衡 CPU 占用比较小的 Sleep,即配置了:AsyncLoggerConfig.WaitStrategy=Sleep。随着业务的增长,我们发现经常有的实例 CPU 占用非常之高(尤其是那种短时间内有大量日志输出的),我们 dump 了 JFR 进行进一步定位:
首先我们来看 GC,我们的 GC 算法是 G1,主要通过 G1 Garbage Collection这个事件查看:
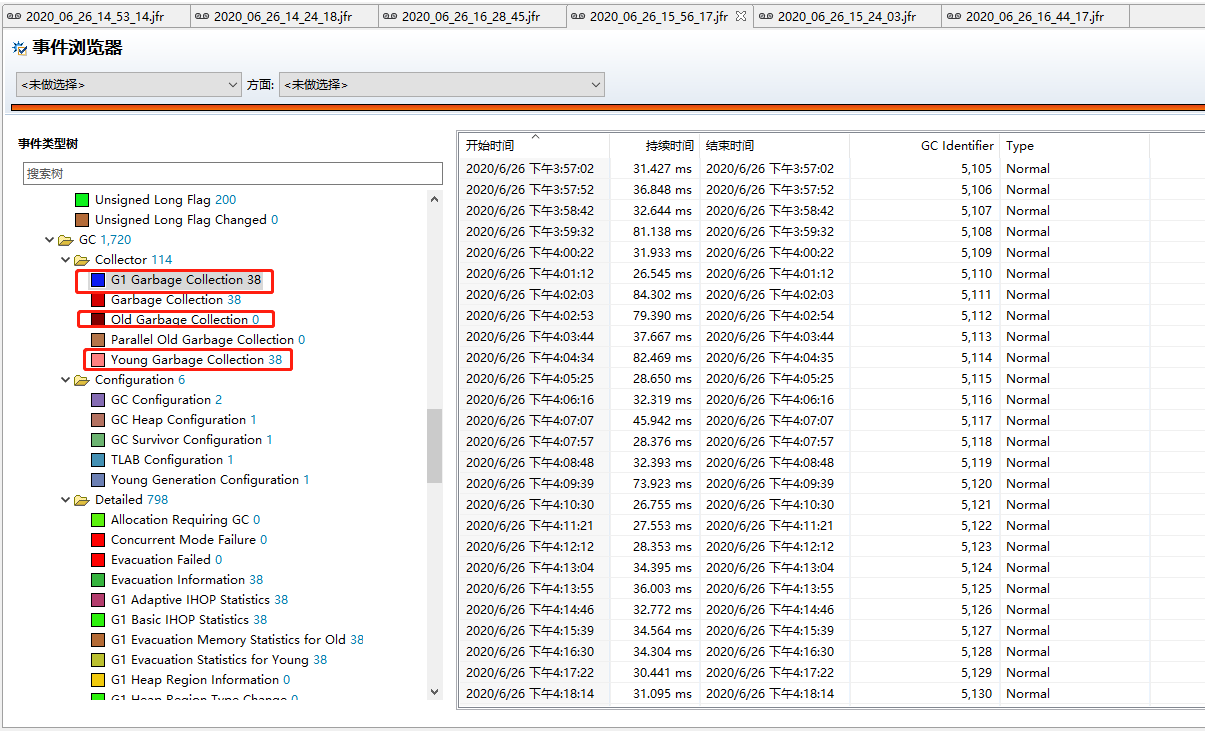
发现 GC 全部为 Young GC,且耗时比较正常,频率上也没有什么明显异常。
接下来来看,CPU 占用相关。直接看 Thread CPU Load 这个事件,看每个线程的 CPU 占用情况。发现reactor-http-epoll线程池的线程,CPU 占用很高,加在一起,接近了 100%。
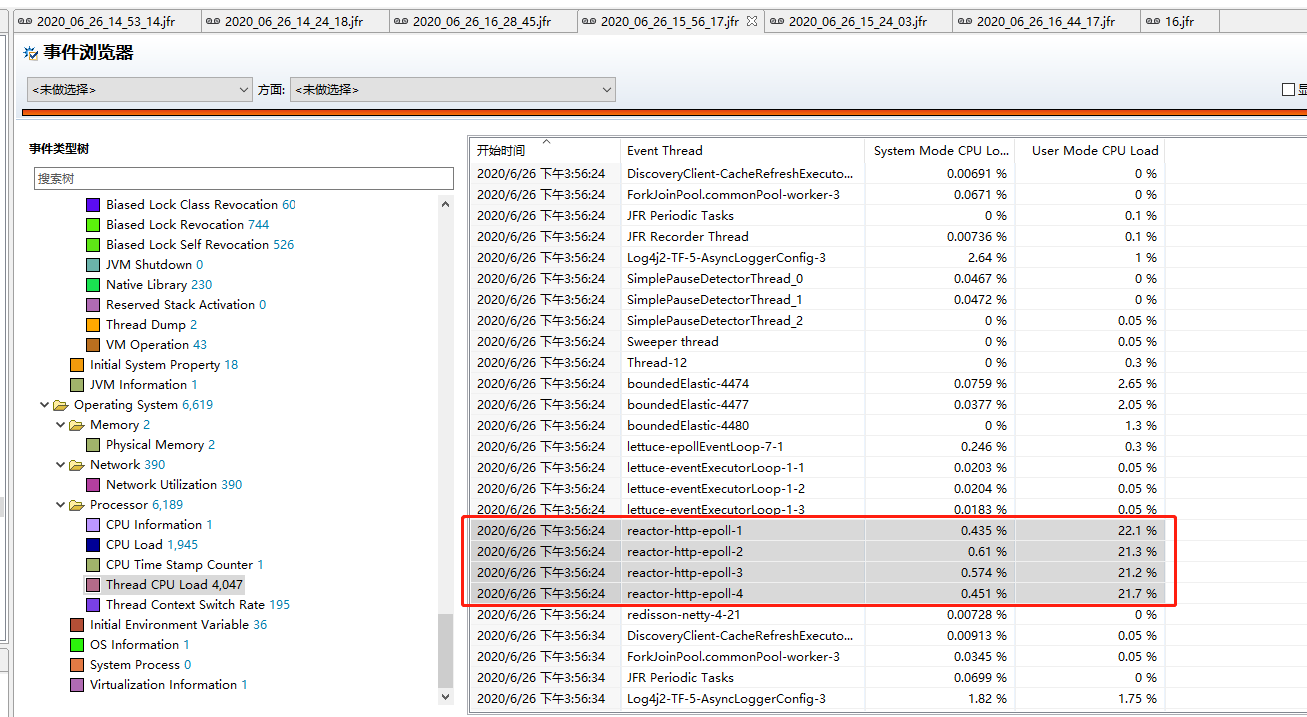
这些线程是 reactor-netty 处理业务的线程,观察其他实例,发现正常情况下,并不会有这么高的 CPU 负载。那么为啥会有这么高的负载呢?通过 Thread Dump 来看一下线程堆栈有何发现.
通过查看多个线程堆栈 dump,发现这些线程基本都处于 Runnable,并且执行的方法是原生方法,和StackWalker相关,例如(并且这个与 JFR 中采集的 Method Runnable 事件中占比最高的吻合,可以基本确认这个线程的 CPU 主要消耗在这个堆栈当前对应的方法上):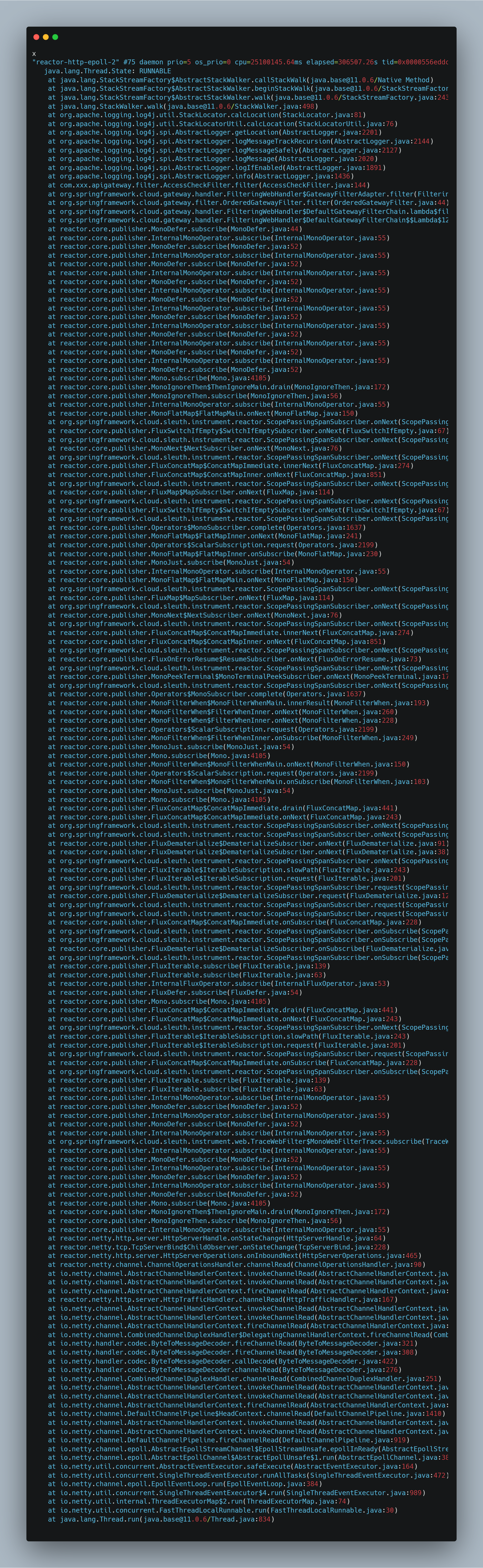
主要和这两个原生方法有关:
java.lang.StackStreamFactory$AbstractStackWalker.callStackWalkjava.lang.StackStreamFactory$AbstractStackWalker.fetchStackFrames
并且需要注意微服务中线程堆栈会很深(150左右),对于响应式代码更是如此(可能会到300),主要是因为 servlet 与 filter 的设计是责任链模式,各个 filter 会不断加入堆栈。响应式的代码就更是这样了,一层套一层,各种拼接观察点。上面列出的堆栈就是响应式的堆栈。
会到那两个原生方法,其实这里的代码是在做一件事,就是日志中要输出调用打印日志方法的代码位置,包括类名,方法名,方法行数这些。在上面我给出的线程堆栈的例子中,调用打印日志方法的代码位置信息就是这一行:at com.xxx.apigateway.filter.AccessCheckFilter.filter(AccessCheckFilter.java:144),这一行中,我们使用 log.info() 输出了一些日志。
可以看出,Log4j2 是通过获取当前线程堆栈来获取调用打印日志方法的代码位置的。并且并不是堆栈中的栈顶就是调用打印日志方法的代码位置,而是找到 log4j2 堆栈元素之后的第一个堆栈元素才是打印日志方法的代码位置
Log4j2 中是如何获取堆栈的
我们先来自己思考下如何实现:首先 Java 9 之前,获取当前线程(我们这里没有要获取其他线程的堆栈的情况,都是当前线程)的堆栈可以通过:
.png)
其中 Thread.currentThread().getStackTrace(); 的底层其实就是 new Exception().getStackTrace(); 所以其实本质是一样的。
Java 9 之后,添加了新的 StackWalker 接口,结合 Stream 接口来更优雅的读取堆栈,即:.png)
我们先来看看 new Exception().getStackTrace(); 底层是如何获取堆栈的:
.png)
然后是 StackWalker,其核心底层源码是:.png)
可以看出,核心都是填充堆栈详细信息,区别是一个直接填充所有的,一个会减少填充堆栈信息。填充堆栈信息,主要访问的其实就是 SymbolTable,StringTable 这些,因为我们要看到的是具体的类名方法名,而不是类的地址以及方法的地址,更不是类名的地址以及方法名的地址。那么很明显:通过 Exception 获取堆栈对于 Symbol Table 以及 String Table 的访问次数要比 StackWalker 的多,因为要填充的堆栈多。
我们接下来测试下,模拟在不同堆栈深度下,获取代码执行会给原本的代码带来多少性能衰减。
模拟两种方式获取调用打印日志方法的代码位置,与不获取代码位置会有多大性能差异
以下代码我参考的 Log4j2 官方代码的单元测试,首先是模拟某一调用深度的堆栈代码:
.png)
然后,编写测试代码,对比纯执行这个代码,以及加入获取堆栈的代码的性能差异有多大。
.png)
执行:查看结果:
.png)
从结果可以看出,获取代码执行位置,也就是获取堆栈,会造成比较大的性能损失。同时,这个性能损失,和堆栈填充相关。填充的堆栈越多,损失越大。可以从 StackWalker 的性能优于通过异常获取堆栈,并且随着堆栈深度增加差距越来越明显看出来。
为何会慢?String::intern 带来的性能衰减程度测试
这个性能衰减,从前面的对于底层 JVM 源码的分析,其实可以看出来是因为对于 StringTable 以及 SymbolTable 的访问,我们来模拟下这个访问,其实底层对于 StringTable 的访问都是通过 String 的 intern 方法,即我们可以通过 String::intern 方法进行模拟测试,测试代码如下:.png)
测试结果:.png)
对比 StackWalkBenchmark.baseline 与 StackWalkBenchmark.toString 的结果,我们看出 bh.consume(time); 本身没有什么性能损失。但是通过将他们与 StackWalkBenchmark.intern 以及 StackWalkBenchmark.intern3 的结果对比,发现这个性能衰减,也是很严重的,并且访问的越多,性能衰减越严重(类比前面获取堆栈)。
结论与建议
由此,我们可以得出如下直观的结论:
- 日志中输出代码行位置,Java 9 之前通过异常获取堆栈,Java 9 之后通过 StackWalker
- 两种方式都需要访问 SymbolTable 以及 StringTable,StackWalker 可以通过减少要填充的堆栈来减少访问量
- 两种方式对于性能的衰减都是很严重的。
由此,我建议:对于微服务环境,尤其是响应式微服务环境,堆栈深度非常深,如果会输出大量的日志的话,这个日志是不能带有代码位置的,否则会造成严重的性能衰减。
我们在关闭输出代码行位置之后,同样压力下,CPU 占用不再那么高,并且整体吞吐量有了明显的提升。
微信搜索“干货满满张哈希”关注公众号,每日一刷,轻松提升技术,斩获各种offer:
我会经常发一些很好的各种框架的官方社区的新闻视频资料并加上个人翻译字幕到如下地址(也包括上面的公众号),欢迎关注:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK