

vector实践-性能吊打logstash
source link: https://wiki.eryajf.net/pages/0322lius/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

vector实践-性能吊打logstash原创
# 0. 前言
简单来说vector扮演着类似logstash的角色,但有着比logstash强悍太多的性能、简单明了的配置文件、强大的数据处理函数、智能均衡kafka分区消费等等!下面请跟随笔者的脚步,对vector实践一番吧。
# 0.1 vector是什么
vector是什么?以下描述翻译自vector官网:https://vector.dev (opens new window)
Vector 是一种高性能的可观察性数据管道,可以收集、转换所有日志、指标和跟踪信息( logs, metrics, and traces),并将其写到您想要的存储当中;Vector 可以实现显着的成本降低、丰富的数据处理和数据安全;且开源,比所有替代方案快 10 倍。
简单来说,它扮演着类似logstash的角色,但有着比logstash强悍太多的性能、简单明了的配置文件、强大的数据处理函数、智能均衡kafka分区消费等等;在这些特性中,性能直接关乎成本,相信这是每一家公司都会重点关注的;而从官方介绍中我们已经可以窥探一二,以下是官网给出的一些实践数据:

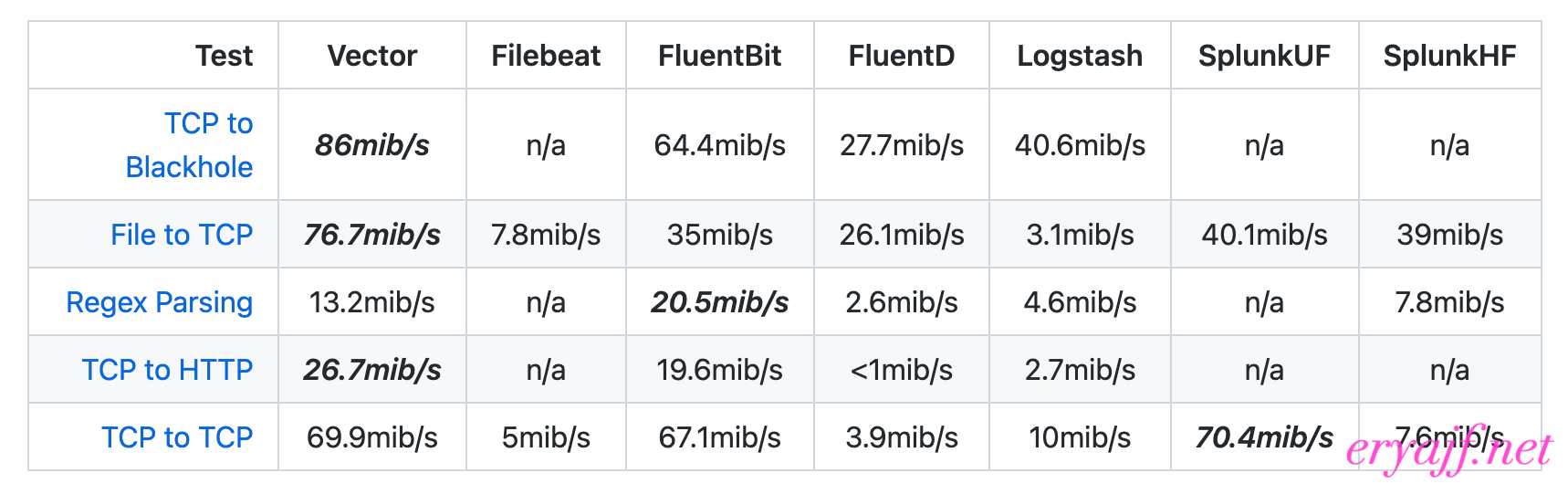
# 0.2 为什么用vector
如果说官方有自卖自夸之嫌,那么我给出自身实践的数据以供参考:
本人所在公司每天产生约15T的日志量,在公司日志架构中logstash起着这样的作用:从kafka中消费数据,然后进行清洗、格式转换,最终写入elasticsearch;公司一共有34台16c64g规格的logstash机器,然而这样的高配集群在晚高峰的时候会显得很吃力,每晚必定会报一堆kafka堵塞的告警;经过调研决定使用vector替换logstash,最终只用了10台16c16g的机器便完成替换,并且之后再也没有报过kafka堆积告警!
# 1. 安装部署
官方提供了安装包、docker等多种安装方式,这里我们使用docker安装等方式来进行演示
# 1.1 使用docker-compose安装vector
准备好docker-compose.yaml文件
version: '3'
services:
vector:
image: timberio/vector:latest-alpine # 镜像
container_name: vector # 容器名
volumes:
- /data/vector/config/:/etc/vector/ # 挂载配置文件
- /etc/localtime:/etc/localtime # 跟宿主机时区保持一致
ports:
- 9598:9598 # metrics信息暴露端口,后面会讲到
# environment: # 开启DEBUG模式,这里不开启
# VECTOR_LOG: debug
entrypoint: "vector -c /etc/vector/*.toml -w /etc/vector/*.toml" # 启动命令
restart: always
2
3
4
5
6
7
8
9
10
11
12
13
14
然后在docker-compose.yaml文件所在目录执行以下命令即可启动vector:
docker-compose up -d
使用 docker logs -f vector 可以看到一些信息,如果vector无法启动一般先从这里获取报错信息
# 1.2 vector配置文件
在上述docker-compose.yaml中,我们挂载了本地准备好的配置文件,接下来我们便来讲一讲配置文件一般如何配置;在此之前我们大概讲一讲配置文件的组成,大概可以分为这么几个模块:
tips:注意,以下任何模块(source、transforms、sinks)都可以配置多个元素,但是要保证不能同名
# 1.2.1 来源(sources)
即vector的数据来源,它支持文件、kafka、http、各类metrics等等数据源,详细请看:https://vector.dev/docs/reference/configuration/sources/ (opens new window),各类数据源均可在文档中找到配置方式,这里我们使用kafka演示:
[sources.kafka-nginx-error] # “数据源”名称
type = "kafka" # 类型
bootstrap_servers = "10.xxx.xxx.xxx:9092,10.xxx.xxx.xxx:9092" # kafka链接地址
group_id = "consumer-group-name" # 消费组id
topics = [ "^(prefix1|prefix2)-.+" ] # topic,支持正则
2
3
4
5
# 1.2.2 变换[可选](transforms)
如果原始数据足够完美无需任何处理,那么这一块可以忽略,但是实际上大部分情况下还是需要这一步的,这里我们讲几个最常用的“变换”,详细请看:https://vector.dev/docs/reference/configuration/transforms/ (opens new window)
# 1.2.2.1 remap
remap在vector中使用VRL(Vector Remap Language,一种面向表达式的语言,旨在以安全和高性能的方式处理可观察性数据)来实现,这里我们看一看公司使用vector处理nginx错误日志的配置:
[transforms.remap-nginx-error] # “变换”名称
type = "remap" # 类型
inputs = ["kafka-nginx-error"] # 输入,这里的输入自然是上一层的“来源”
source = ''' # 正式开始处理
. = parse_json!(.message) # 首先将每一条错误日志解析成json,message的值就是从kafka中读取到的原始值
del(.@metadata) # 删除Vector自动携带的一些信息
.parse = parse_nginx_log!(.message, "error") # 解析nginx错误日志
'''
2
3
4
5
6
7
8
可以看到,在上述处理过程中,只是用了parse_json、del、parse_nginx_log三个函数便将错误日志处理完成,实际上解析nginx错误日志是一个非常困难的事情,因为nginx错误日志的格式不固定,我们很难通过通用的步骤来指定字段、取值,而Vector自带来解析nginx错误日志函数,一行代码搞定!我们可以对比之前使用logstash时的处理方式:
grok {
match => [
"message", "(?<time>\d{4}/\d{2}/\d{2}\s{1,}\d{2}:\d{2}:\d{2})\s{1,}\[%{DATA:err_severity}\]\s{1,}(%{NUMBER:pid:int}#%{NUMBER}:\s{1,}\*%{NUMBER}|\*%{NUMBER}) %{DATA:err_message}(?:,\s{1,}client:\s{1,}(?<client_ip>%{IP}|%{HOSTNAME}))(?:,\s{1,}server:\s{1,}%{IPORHOST:server})(?:, request: %{QS:request})?(?:, host: %{QS:client_ip})?(?:, referrer: \"%{URI:referrer})?",
"message", "(?<time>\d{4}/\d{2}/\d{2}\s{1,}\d{2}:\d{2}:\d{2})\s{1,}\[%{DATA:err_severity}\]\s{1,}%{GREEDYDATA:err_message}"]
}
2
3
4
5
类似的处理函数还有很多,这里不一一列举!
# 1.2.2.2 filter
很多时候从数据源采集过来的数据我们并不是全部都需要,filter顾名思义便是用来解决这一问题的,下面的配置也很好理解:包含spanID字段的数据才保留,不包含的丢弃
[transforms.filter-jaeger-span]
type = "filter"
inputs = [ "remap-ssd" ]
condition = "exists(.spanID) == true"
# 1.2.3 水槽(sinks)
可以理解为数据往哪发送,它支持console(如果是docker启动直接打到docker log中)、elasticsearch、kafka、vector、http等等,详细请看:https://vector.dev/docs/reference/configuration/sinks/ (opens new window),这里使用elasticsearch来演示
[sinks.elasticsearch-ssd] # “水槽”名称
type = "elasticsearch" # 类型
inputs = [ "remap-ssd" ] # 输入,这里的输入是上一层的“变换”名称
endpoint = "http://10.xxx.xxx.xxx:9200" # 输出的链接地址
bulk.index = "{{ project_name }}-{{ env }}-%Y-%m-%d" # 索引名称,这里看到我们使用了日志当中的字段作为变量、以及日期来作为索引名称
2
3
4
5
# 2. 实践
经过以上介绍,相信你已经可以搞定单个日志的vector配置,但是实际使用场景中,会有太多日志,而且各个部门的日志格式也不尽相同,所以实际使用场景中需要用到一些实用技巧,这里列举几个比较典型的
# 2.1 将结果输出到console
这是我们调试时的利器,我们经常需要掌握我们拿到了什么样的数据,或者了解我们将要写入下游的数据是否符合我们的预期:
[sinks.console]
type = "console"
inputs = [ "remap-ssd" ]
encoding.codec = "json" # 可选json 或者 text
# 2.2 多配置文件启动
实际上聪明的你已经发现,在上文介绍docker-compose中,已经使用了该配置
vector -c /etc/vector/*.toml -w /etc/vector/*.toml
这样我们便可以给多个日志配置相应的配置文件,最好使用git管理,部署时直接pull下来,然后所有配置文件一起启动即可;这里还是用到了-w参数,意思是关注配置文件中的更改,并相应地重新加载;再次提醒:即使是多个配置文件,在同一个vector实例中各阶段的命名也不能重名
# 2.3 多topic使用正则匹配
各个部门可能对应的统一过日志格式,他们的处理方式可能都一样,这样我们可以在“来源”中指定消费同一类topic
topics = [ "^(prefix1|prefix2)-.+" ]
# 2.4 索引使用日志中的字段值作为索引名称
topic可以使用正则消费多个topic,但是我们不能把这些日志一起打到同一个索引中,如果各部门日志格式统一的话,可以使用日志中的字段值作为变量名称,使用变量的方式就是,此外还可以使用%Y、%m、%d分别表示年、月、日,这是一种很好的日志索引管理方式
bulk.index = "{{ project_name }}-{{ env }}-%Y-%m-%d"
# 2.5 查看vector各任务的处理情况
在vector启动之后,我们可能会关心各任务的处理情况,我们只需要在某个配置文件中(或者单独创建一个配置文件)加入以下配置,让vector启动时加载该配置文件,便能以命令行的方式实时查看各任务的处理情况
[api]
enabled = true
然后执行以下命令即可:
docker exec -it vector sh
vector top
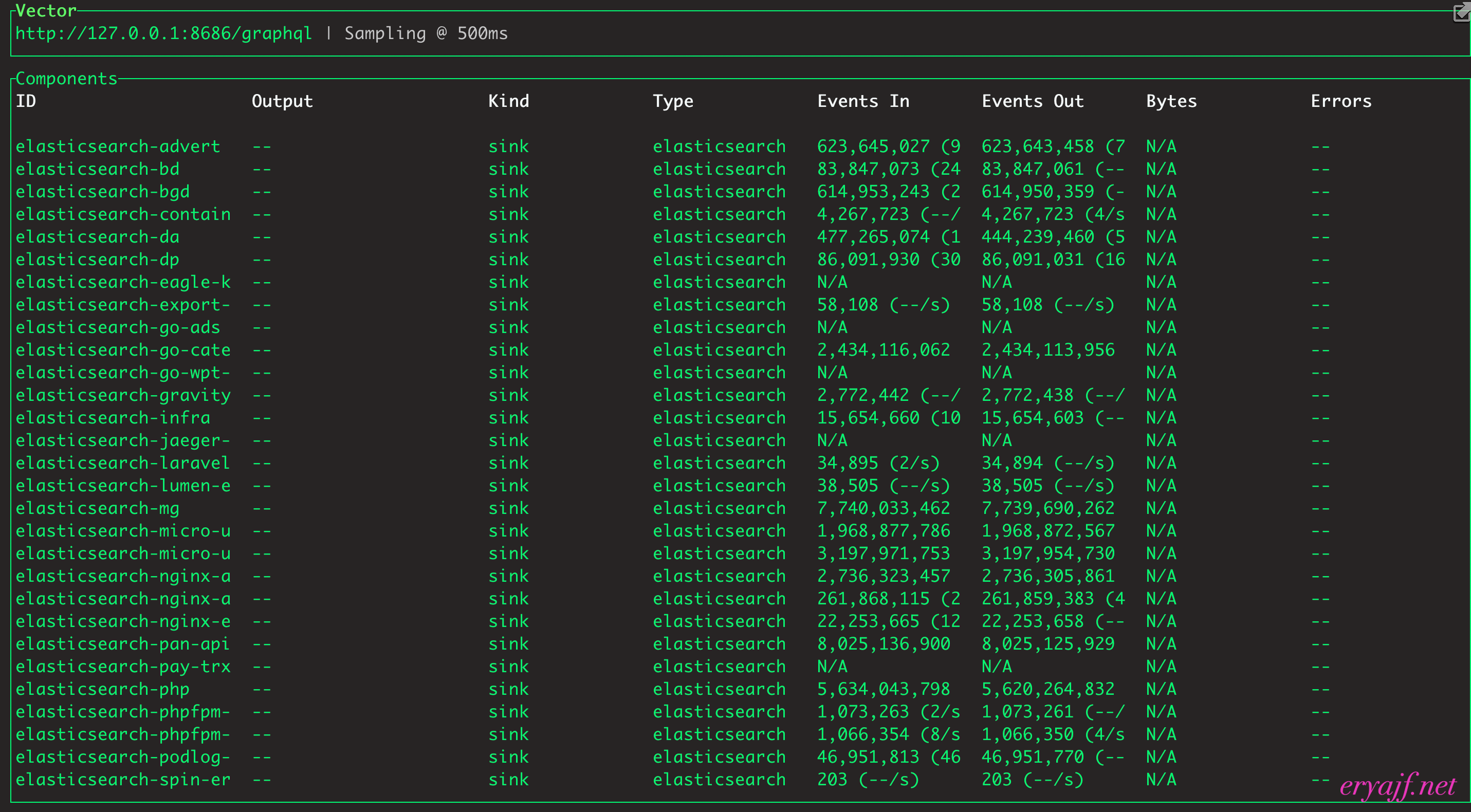
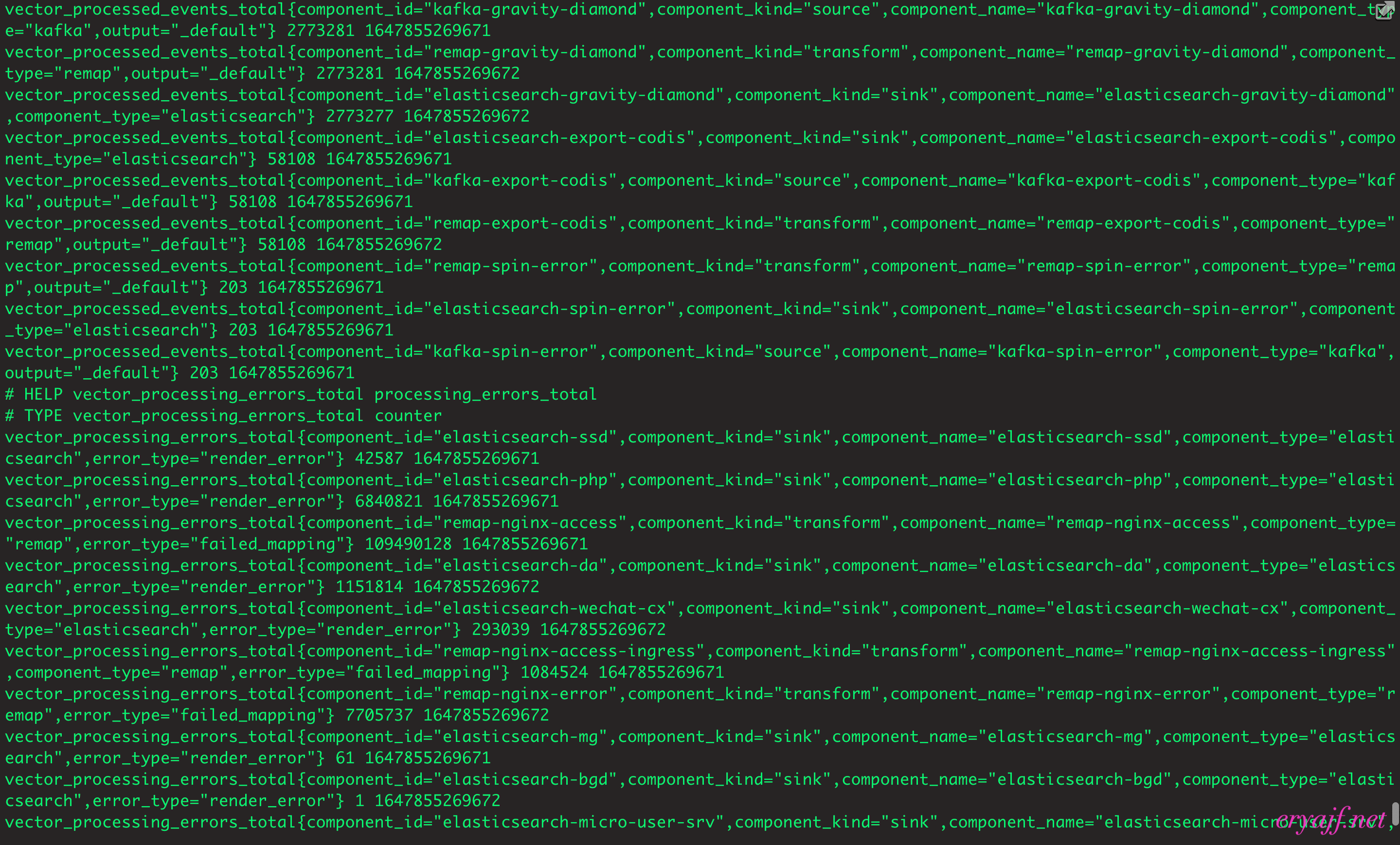
# 2.6 vector更加详细的metrics指标
vector提供了详细的自身指标供我们查看,不过截止目前,该功能还是测试版,我们可以先看看实际效果,在某个配置文件中(或者单独创建一个配置文件)加入以下配置,vector加载后便会启动9598端口,配置文件中我们指定了使用prometheus_exporter格式的输出,熟悉prometheus的你一定会发现返回的数据格式非常熟悉
[sources.metrics]
type = "internal_metrics"
namespace = "vector"
scrape_interval_secs = 30
[sinks.prometheus]
type = "prometheus_exporter"
inputs = [ "metrics" ]
address = "0.0.0.0:9598"
default_namespace = "service"
2
3
4
5
6
7
8
9
10
# 2.7 vector的自动均衡kafka消费[重要]
在使用vector之前,logstash经常会出现消费不均匀的情况,导致部分logstash节点负载高、另一部分节点却又很空闲,在使用了vector之后这个问题自动解决了,从下图可以看出每个vector实例自动消费了6个分区;其实这是一个非常有用的功能:在使用logstash时,由于它不能自动均衡消费,所以我们需要评估各个topic的数据量,然后给其分配机器,比如20台机器专门消费数据量大的topic,5台专门消费数据小的topic;但是这个数据量和消费能力其实都是我们根据以往的经验判断的,给topic分配的机器数量也是拍脑袋决定的,并不是非常准确;而vector就自然而然的解决了这个问题,我们无需考虑太多,无需区分机器,所有的机器都一起消费所有的topic!

# 2.8 自适应并发请求
在0.17.0版本后默认启用了自适应并发,这是一个智能、强大的功能,官方介绍请看https://vector.dev/blog/adaptive-request-concurrency/ (opens new window),这里大致介绍一下:
vector往下游写数据的速度非常快,这对下游如elasticsearch等接收器提出了重大挑战,因为这些服务无法始终像vector一样快速处理事件负载;在0.11之前的vector版本中,我们可以设置限速来解决这类问题,可是这又引发了另一个问题,限速作为后备是不错,但它会将您锁定在一个永久循环中:
在这个恶性循环中,您需要不断避免两种结果:
- 您将限制设置得太高,进而会压倒您的服务、损害系统可靠性,这时候就需要降低限制并重新评估了。
- 将限制设置得太低并浪费资源,您的 Elasticsearch 集群可能能够处理比您提供的更多的并发性,这时候又需要重新评估了。
为了解决这个问题,vector推出了自适应并发的功能,它会重点观察两件事:请求的往返时间 (RTT) 和 HTTP 响应代码(失败与成功),从而决策出一个最佳的速率!
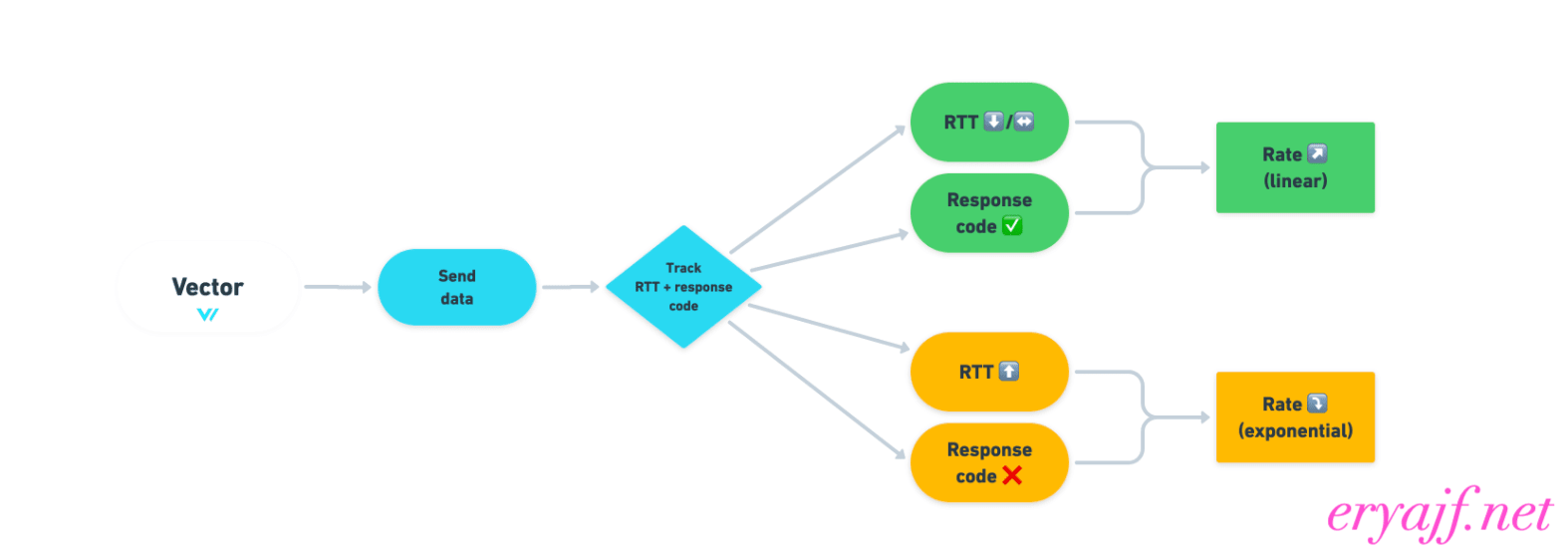
# 2.9 性能效果对比[重要]
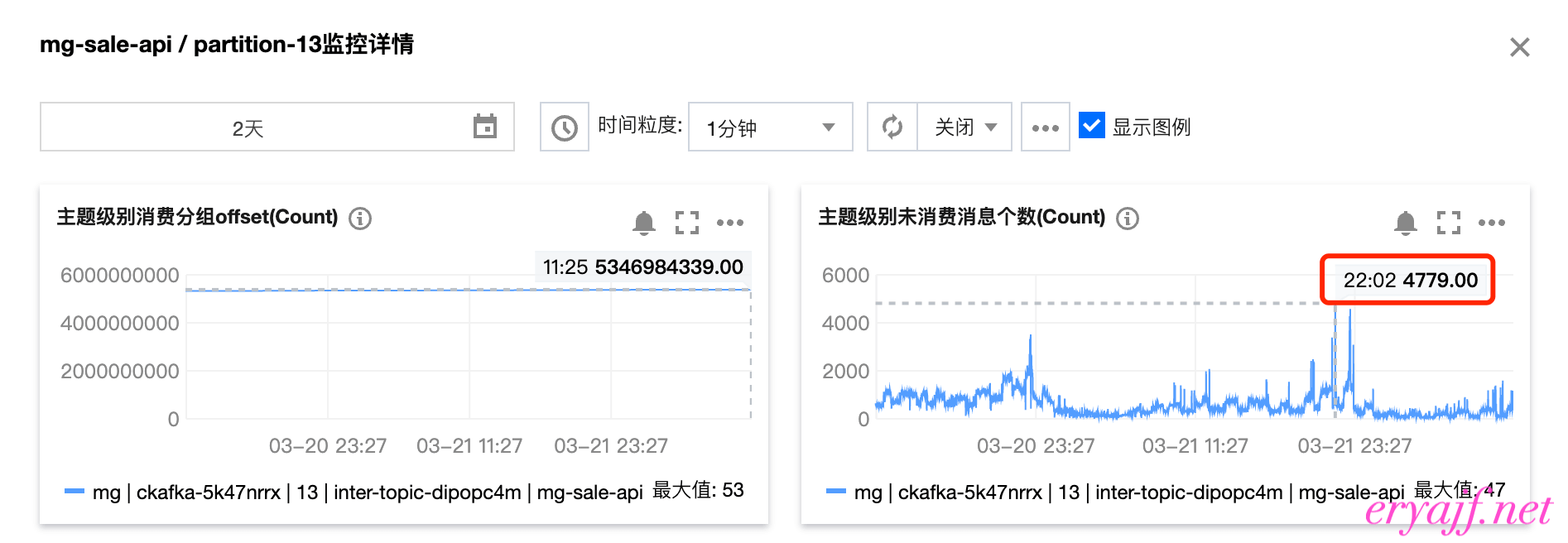
拿同一个topic、同一个消费组来做对比,consumergroup:mg topic:mg-sale-api 每晚都会告警kafka堆积,堆积量都在2000w以上
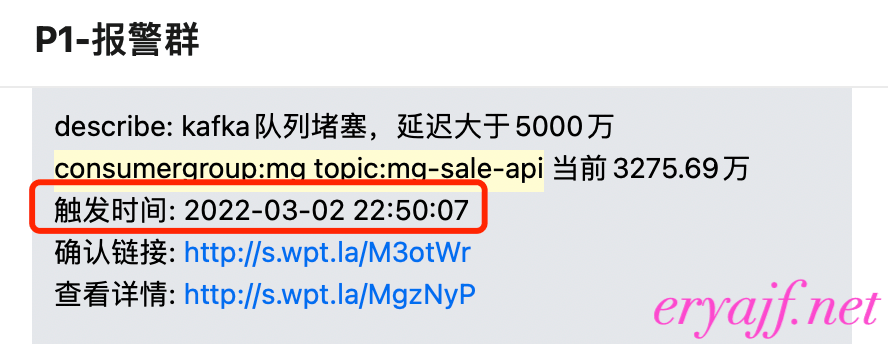
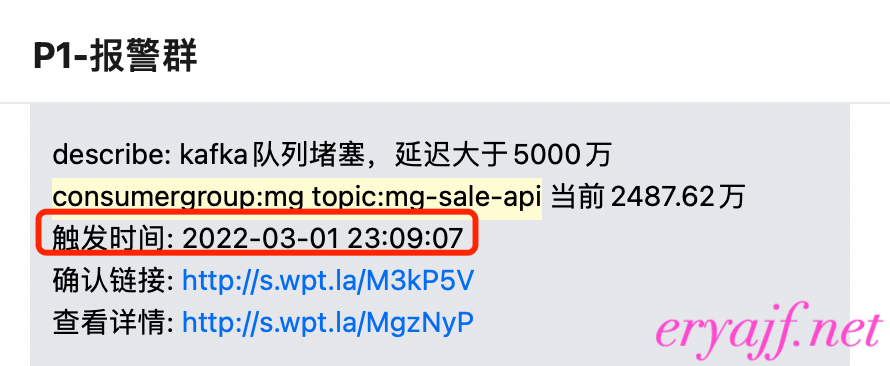
在使用vector之后,晚高峰最大的未消费数只有不到5k,这还是节点从34台16c64g 缩容到 10台16c16g的结果
# 3. 小结
实践下来可以发现vector是一款功能强大、性能优秀的数据管道工具,但在国外火热的它却在国内使用的人数寥寥无几,相关资料也少之又少,不过笔者相信是金子总会发光的,相信以后vector会被更多人发掘,从而在更多的公司里发光发热!特此感谢微拍堂同事 -- 李秋阳在项目期间提供的指引以及鼎力支持!
Recommend
-
92
喊着全面“吊打”iPhone X,这就是最高售价过万的华为新旗舰-虎嗅网2017-10-16 22:33喊着全面“吊打”iPhone X,这就是最高售价过万的华为新旗舰人工智能和徕卡,是今年华为给 Mate 10 设定的两个重要标签。...
-
88
滑动验证页面 别离开,为了更好的访问体验,请滑动滑块进行验证,通过后即可继...
-
43
近日OpenAI在Dota 2上的表现,让强化学习又火了一把,但是 OpenAI 的强化学习训练环境 OpenAI Gym 却屡遭抱怨,比如不太稳定、更新不够及时等。今日,谷歌推出了一款全新的开源强化学习框架 Dopamine,该框架基于 TensorFlow,主打灵活...
-
52
稳了!
-
82
vector 是 C++ 编程时的常用容器,其帮助用户自动管理存储空间,简单易用,且能避免资源泄露的问题。需要动态分配存储空间的场景,完全可替代原生数组。 vector 被人诟病...
-
80
-
43
Android - @lhx2008 - https://www.v2ex.com/i/JL9g1VL3.jpeghttps://www.v2ex.com/i/flvD05eo.jpeg
-
4
前面的时候,我因为后台粉丝的一些问题,整理了一篇文章,将ELK三个技术进行详细的讲解,从原理到实践,全面覆盖,但是因为篇幅原因,我分成了两篇进行整理, 上篇...
-
2
吊打一切现有版本的 YOLO!旷视重磅开源 YOLOX:新一代目标检测性能速度担当!精选 技术讨论 chengzi · 发表于 2021-07-20 11:18:11 文章来源: 目标跟踪分享 作者丨happy 编辑丨极市平台 YOLOX
-
2
今天跟大家介绍一个最新开源的 javaScript 运行时:Bun.js。
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK