

The counterintuitive rise of Python in scientific computing (2020)
source link: https://cerfacs.fr/coop/fortran-vs-python
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

 To get across an unknown place, one can move faster, or find better paths. In other words, focusing too much on raw performance can slow you down. Software making is no exception.
To get across an unknown place, one can move faster, or find better paths. In other words, focusing too much on raw performance can slow you down. Software making is no exception.
Reading time: 10min
In our laboratory, a polarizing debate rages since around 2010, summarized by this question:
Why are more and more time-critical scientific computations formerly performed in Fortran are now written in Python, a slower language?
The terms are vague, encouraging tribal wars between users based more on their habits on both sides than on objective assessments about the two approaches. Let’s try to give some elements to reach a mutual understanding, by narrowing the question.
“Python, a slower language”
Python has the reputation of being slow, i.e. significantly slower than compiled languages such as Fortran, C or Rust. If you have heard this, you are not alone: simply googling “why is python slow” yields heaps of pages on the topic. This stems from a fundamental aspect of Python: it is an interpreted language. This implies a significant overhead to each instruction, hence slowing down massive computations. This would be true of any interpreted language, including e.g. Perl or Ruby.
So yes, plain Python is much slower than Fortran.
However, this comparison makes little sense, as scientific uses of Python do not rely on plain Python. Instead, Python is used as a gluing layer, relying on compiled optimized packages that it strings together to perform the wanted computation. The most widespread package in scientific computing is probably NumPy, for Numerical Python. As the name suggests, numeric data is manipulated through this package, not in plain Python, and behind the scenes all the heavy lifting is done by C/C++ or Fortran compiled routines. In essence, Python is used to point a fast routine in the right direction (i.e. to the right memory address), and no more.
Performance evaluations for scientific computing should therefore be based on this type of approach. The following graph is an example of comparison, showing how NumPy is 2 orders of magnitude faster than pure Python. As you can see, other packages also exist, which can further reduce the overhead if needed.
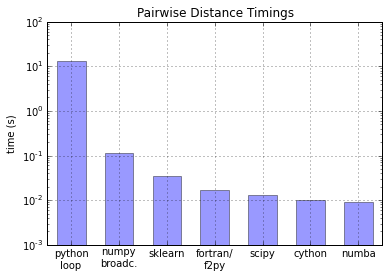
This decreases the overhead of the interpreted approach by 2 to 3 orders of magnitude, bringing it in the ballpark of compiled solutions. Some more precise comparisons exist of course, check them out for more.
Used the right way, Python is slightly slower than compiled code.
“more and more”
Is popularity quantifiable? One indicator are the google trends. for “fortran” and “numpy”. Fortran is indeed slowly decreasing, and has fallen behind NumPy in 2015. Take this figure with a grain of salt however, as more recorded interest in NumPy is biased by the heavy reliance of young programmers and Python developers in general on web resources.
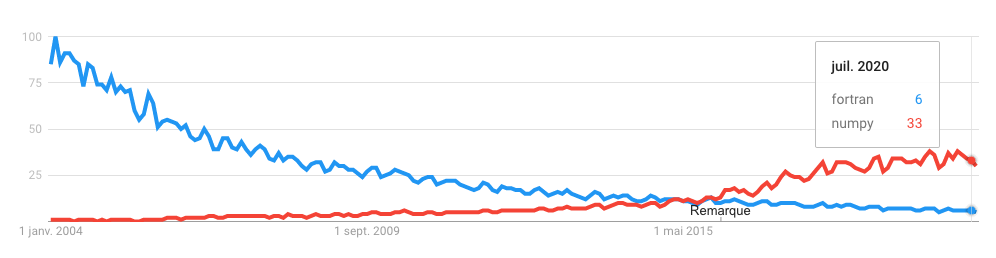
Ok, whatever, the new kids like Python more than Fortran. This is also driven by many non-scientific applications, notably web-based. In our field, this is not what guides our decisions. What does however, is the relationship to HPC.
“time-critical scientific computations”
The competition between software approaches to High Performance Computing has never been as fierce as today. One specific challenge arises from the environment of HPC, which is very specific and not what general software advances optimize for. As an example, container technology (think Docker) has become ubiquitous in many programming setups, but is still largely inadequate in an HPC context. This is also true for languages, such as Rust which has a large following in the C / C++ community but continues to have an insufficient library ecosystem for HPC.
HPC software today relies on a vast range of approaches, including traditional monolithic compiled codes (mostly in Fortran and C++), code generation approaches (a.k.a. DSLs), and hybrid interpreted / compiled approaches. The latter category now counts some serious challengers, such as PyFR or FEniCS, which have been shown to scale to several hundred to tens of thousands of CPUs and even GPUs.
However to the authors’ knowledge none of the challengers, including the Python/HPC attempts, has built a sufficient community and maturity to get an edge in the global HPC scene. So for the moment, it is probably safer to bet on both:
- keeping our Fortran/C++/C flagship codes afloat. Older, but wiser.
- trying several of these new approaches (e.g. Python based) on practical applications.
Is Python ever better suited?
Up until this point, one could rightfully think:
Fortran is very fast and well suited to HPC platforms. Python is slightly slower, requires to learn about several layered packages, and is not always suited in a scientific-computing context. Why on earth would anyone switch to Python?
A good point! And yet, in some situations, Pythonistas will argue that “speed” shouldn’t necessarily be measured by implementing the same algorithm between languages. To grasp why, let’s dive into an example.
User story : same author, two languages
At Cerfacs, a tool nicknamed Projector was written around 2010 by a Fortran-only programmer. Let’s call him Bob.
Several years later, near 2016, Bob rewrote the same tool in Python. The motivation was simply that for several years, his younger co-workers got many things done in python. Meanwhile, their output in Fortran and Tcl/Tk was constantly disappointing to him. In particular, the Projector in Fortran was barely understood and never fully maintained by anyone else but Bob.
Bob saw Python as a hassle, an indentation-greedy language supported by many impolite youngsters too happy to bully others by saying “this is not pythonic” with the penetrating stare of those who saw the light. In short, he was pissed…
Bob strained to shove these 1.5K lines of fortran code, painfully validated over the years, into NumPy (and a bit of SciPy). The projector tool performs the projection of the thousands of multi-perforations of a combustor liner the skin of a 3D complex shape made of by millions of polygons. As you can image, this is quite a heavy task.

Bob soon discovered that once he had fit the data structures into NumPy, many pre-existing and optimized functions were available to make his task easier in packages such as SciPy. Searching through the documentation, he found some useful tools for 3D points manipulation, including a smart data representation called a Kdtree. The implementation was easy enough to test a dozen of projections workflows in the afternoon, ending with a simple back-and-forth projection with two scipy’s Kdtree objects, one for the mesh skin and one for the drills. By implementation, on should not just stop at the KDtree call. The easiness to declare, link, package, and distribute the pre-compiled additional library, was a game changer. Indeed, our customers use tools on HPC clusters : no-one of us is root there, there is no connection to Internet, and asking for a new library installation can take some time. (This may explain why the Not Invented Here syndrome is so frequent in our HPC community, but that is an other story).
Then came the time to compare the brute-force (Fortran) and KDtree-based (Python / NumPy / SciPy) versions. Bob chose a large representative test case:
- 1 billion cells
- 10 million multi-perforated boundary nodes
- 18 thousand perforations
The brute-force version ran in 6 hours and 30 minutes. And the Kdtree-based one? 4 minutes only, almost a 100 times faster, with discrepancies at the level of zero-machine.
Speed vs agility
What really happened here? Well, Projector‘s main operation involves searching for points in a 3D pointcloud. The Fortran version did this by looking in the pointcloud array, a search which has a O(n)O(n) complexity. A KDTree is a data structure designed for this type of search, with a complexity of O(log(n))O(log(n)). And when your nn is 1 billion, algorithms matter more than language performance.
So yes, Fortran would have been faster for the same implementation. But Bob would never have tried this algorithm had he stuck to Fortran (He should have, like I. Pribec Suggested, but he did not, and that is the point).
By definition, a higher level language will allow more explorations. In Bob’s case, the initial fortran version was working like a charm. There was no strong incentive to break the implementation, insert a localization tree -octree or kdtree-, and look how far Bob could reduce the stencil of points without degrading the output. In other words, the Return Over Investment was far too uncertain. Moving to python simply reduced the Investment part. Of course, If the best algorithm is known beforehand or the manpower is not a problem, a lower level-language is probably faster, but this is seldom the case in real life.
A quote from an influential software engineer shows this issue is present is all high-level vs low-level debates :
“Programmers working with high-level languages achieve better productivity and quality than those working with lower-level languages. Languages such as C++, Java, Smalltalk, and Visual Basic have been credited with improving productivity, reliability, simplicity, and comprehensibility by factors of 5 to 15 over low-level languages such as assembly and C (Brooks 1987, Jones 1998, Boehm 2000). You save time when you don’t need to have an awards ceremony every time a C statement does what it’s supposed to.” ― Steve McConnell, Code Complete.
Takeaway
A lot has been said about the speed of execution versus the total programmer time needed to perform a task in the computer science world. In scientific computing, there is a strong tendency to overestimate the importance of execution time, hence focusing the attention on speed.
However, as you’ll learn in any algorithmic class and as demonstrated in the user study above, speed is nothing if you’re not using an adequate algorithm. And to ensure you are, sometimes letting go of a little speed to gain agility goes a long way.
So the next time you have a tool to write for scientific computing, ask yourself: do I feel confident that I’m capable of choosing and implementing an efficient algorithm for it? If you are, a compiled language will give you the best performance. If not, investing a bit of time in an agile language to explore algorithms might be the best way for your tool to be blazing fast.
DISCLAIMER : This text was probably quite unfair to modern Fortran, all apologies. It focused indeed on “our” internal use of Fortran, weighted by decades-long Legacy codes, literally millions of not-very-modern Fortran statements, and the frustrating rules of HPC clusters where you are not sys-admin, and without internet access. Readers, keep in touch with the latest questions around modern Fortran using the Fortran Discourse
This post was the trigger of a long discussion by the Fortran Community. The reader is highly encouraged to browse the dedicated discourse discussion.
Like this post? Share on: Twitter ❄ Facebook ❄ Email
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK