
2

从零实现GRU门控循环单元 #51CTO博主之星评选#
source link: https://blog.51cto.com/Lolitann/5141933
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

从零实现GRU门控循环单元 #51CTO博主之星评选#
原创注意:
- 我一共要写两篇文章来讲解两种写GRU的方法,一种是手写实现,一种是直接调用pytorch自带的GRU,本文就是从零实现GRU。但是要注意,自己写的会和pytorch的有有出入,毕竟人家是经过优化的,所以同样的数据使用我们自己写的训练速度会很慢。这只是带你熟悉流程的,本篇文章看完以后建议看一下如何是会用pytorch框架实现GRU。
- 本文使用jupyter notebook写的代码,和pycharmh有一点不一样。比如
x可以直接输出变量,但是在pycharm中需要使用print(x)才可以。
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
- 调用其他的包。
- 设定batch-size批量大小和时间步的长度num_step。这里需要注意时间步的长度是你一个要处理的序列的时间步有多少个。
- 使用之前我们实现过的加载时光机器数据集。获得数据集的迭代器和词汇表的长度,这里为了方便,使用的是char进行分割,也就是说词汇表是a~z以及空格和<unk>。
def get_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xz, W_hz, b_z = three() # 更新门参数
W_xr, W_hr, b_r = three() # 重置门参数
W_xh, W_hh, b_h = three() # 候选隐藏状态参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xz, W_hz, b_z = three() # 更新门参数
W_xr, W_hr, b_r = three() # 重置门参数
W_xh, W_hh, b_h = three() # 候选隐藏状态参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
看代码之前记得回顾一下GRU的计算公式:
这一步是初始化模型参数:实例化与更新门、重置门、候选隐藏状态和输出层相关的所有权重和偏置。
-
num_hiddens 定义隐藏单元的数量, -
normal函数用于从标准差为 0.01 的高斯分布中随机生成权重。 -
three函数用于给更新门、重置门、候选隐藏状态初始化权重和偏执,一次更新仨就叫three了。 - 后边三个
w,w,b = three()分别对应更新门、重置门、候选隐藏状态的初始化。 -
w_hq和b_q是初始化隐藏层到输出层的权重和偏执。 -
params将参数整理到一起,为其附加梯度。
def init_gru_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), )
return (torch.zeros((batch_size, num_hiddens), device=device), )
这个是隐状态初始化函数。将其初始化为0张量。
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
Y = H @ W_hq + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
Y = H @ W_hq + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)
这是定义GRU的计算,这里就不重复写公式了,往上翻一下子看看公式。
- 开始是用
params设定gru的参数。 -
H获取初始的隐藏状态 - for循环就是对其进行计算。对照公式一目了然的东西。
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_params,
init_gru_state, gru)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
num_epochs, lr = 500, 1
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_params,
init_gru_state, gru)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
这段代码是对我们手写GRU的训练和预测测试,会输出预测结果和训练过程的可视化。给你们看个好玩的,仔细看输出的句子和图像。随着训练句子会一直改变,困惑度也一直下降。在CPU上会训练很久,所以要等好长一会儿让他跑完500个epoch。
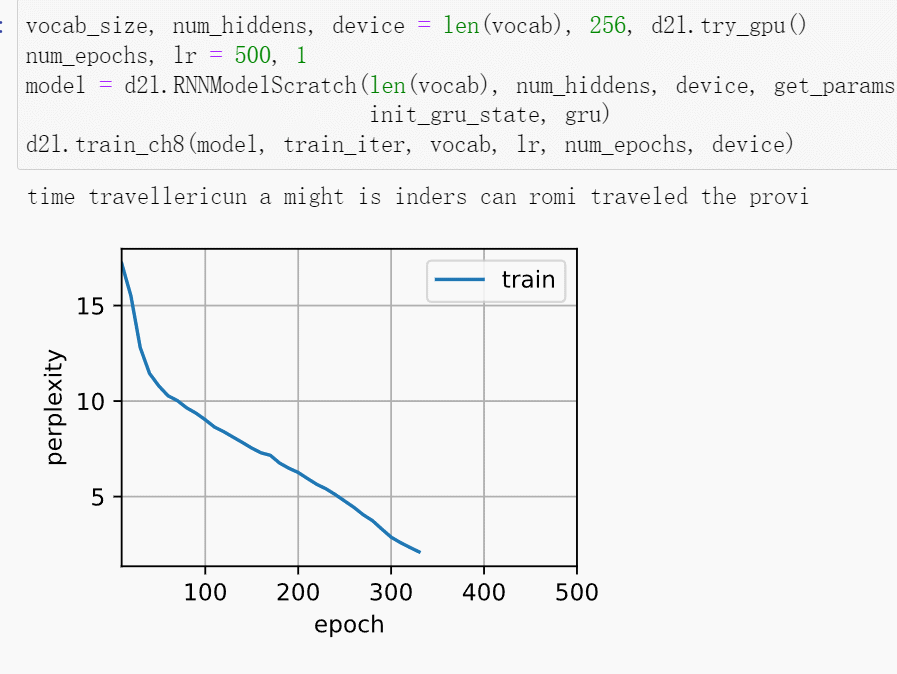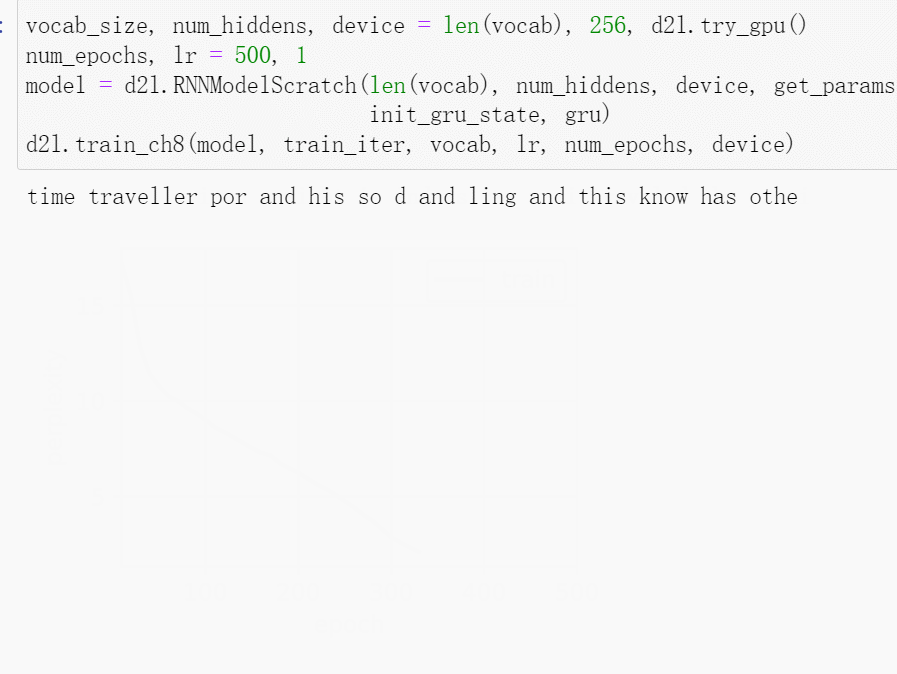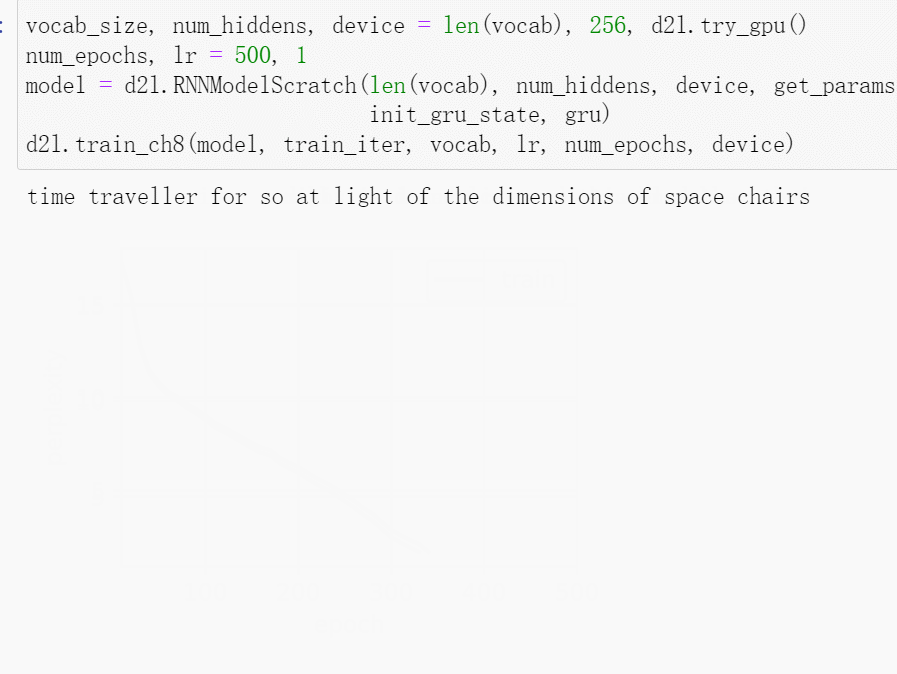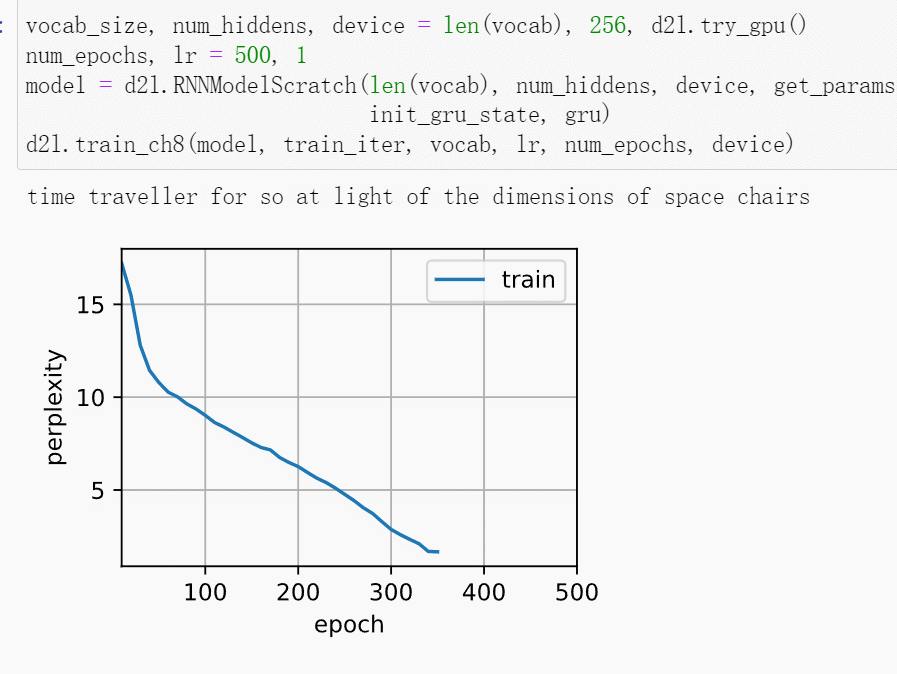
训练结束后,会分别打印输出训练集的困惑度和前缀“time traveler”和“traveler”的预测序列上的困惑度。因为是随机初始化,所以每次运行的结果都不太一样,我就不贴运行结果出来了。
- 赞
- 收藏
- 评论
- 分享
- 举报
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK