

Java集合专题(超级详细)
source link: https://blog.csdn.net/weixin_46015018/article/details/123190875
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Java集合专题(超级详细)
一、集合是什么?
集合是一个用来存放对象的容器,它只能存放对象(实际上是对象名,即指向地址的指针),在没有集合前,我们是用数组来储存对象的。下面介绍一下集合和数组之间都有哪些不同。
1.集合和数组的区别
2.Collection体系的继承树
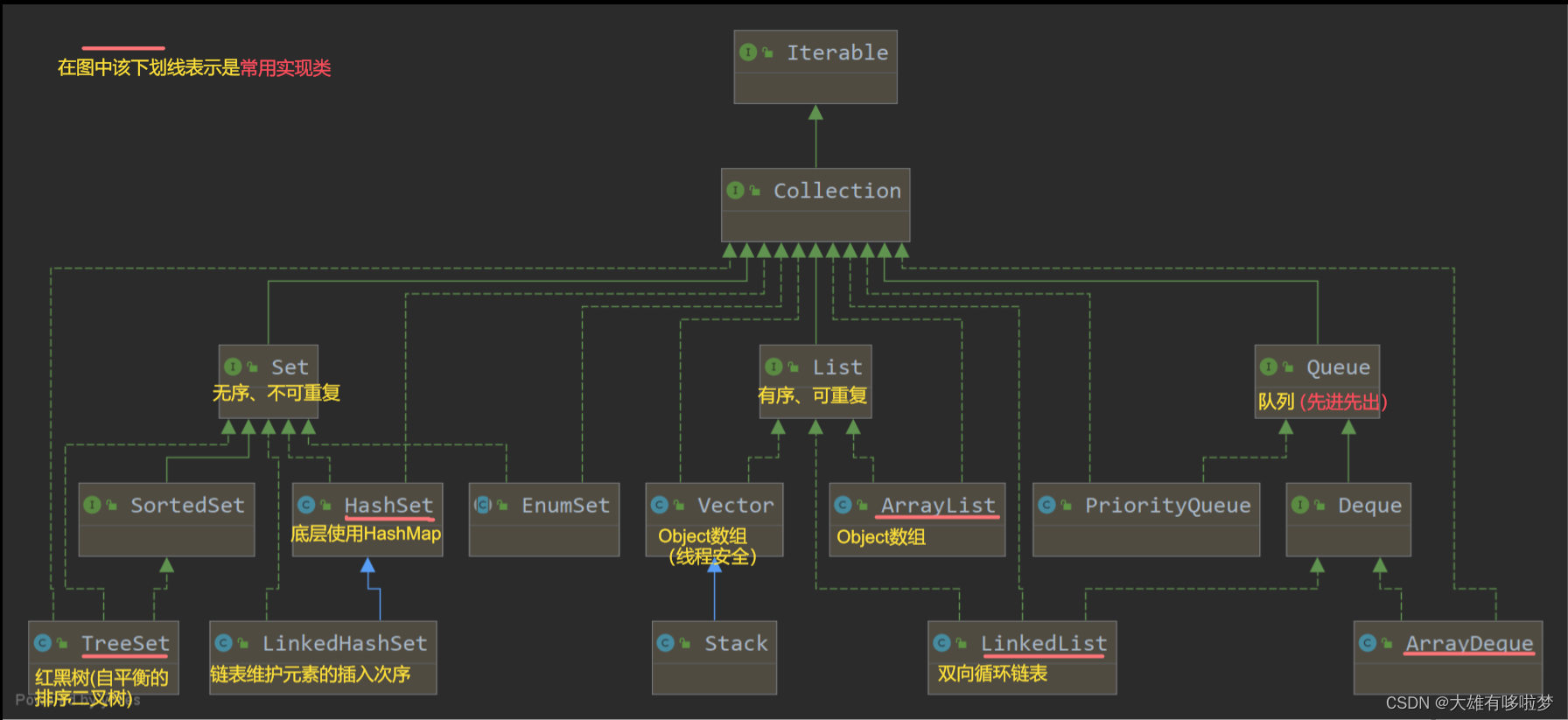
2.1 Collection接口常用方法
- add:添加单个元素
- remove:删除指定元素
- contains:查找元素是否为空
- size:获取元素个数
- isEmpty:判断元素是否为空
- clear:清空
- addAll:添加多个元素
- containsAll:查找多个元素是否都存在
- removeAll:删除多个元素
2.2 Collection常用遍历方式
2.2.1 迭代器Iterator使用
Collection接口遍历元素使用Iterator(称为迭代器),所有实现Collection接口的集合类都有一个Iterator()方法,只能用于遍历集合。
List list = new ArrayList<>();
Iterator iterator = list.iterator();//获取迭代器
while (iterator.hasNext()) {//判断是否还有下一个,如果不用hasNext()会报NoSuchElementException
Object next = iterator.next();
System.out.println(next);
}
2.2.2 增强for循环遍历
底层也是采用了 Iterator 的方式实现,可以理解为简化版本的Iterator
List lists = new ArrayList<>();
//增强for循环同样可以用在数组上面
//使用foreach增强for循环
for (Object list:lists) {
System.out.println(list);
}
2.3 List常用遍历方式(3种)
1. 使用迭代器(Iterator)
2. 使用增强for循环
3. 使用普通for循环
2.4 Set常用遍历方式(2种)
1. 使用迭代器(Iterator)
2. 使用增强for循环
3. 不能使用普通for循环(因为没有提供get方法)
3.Map体系的继承树
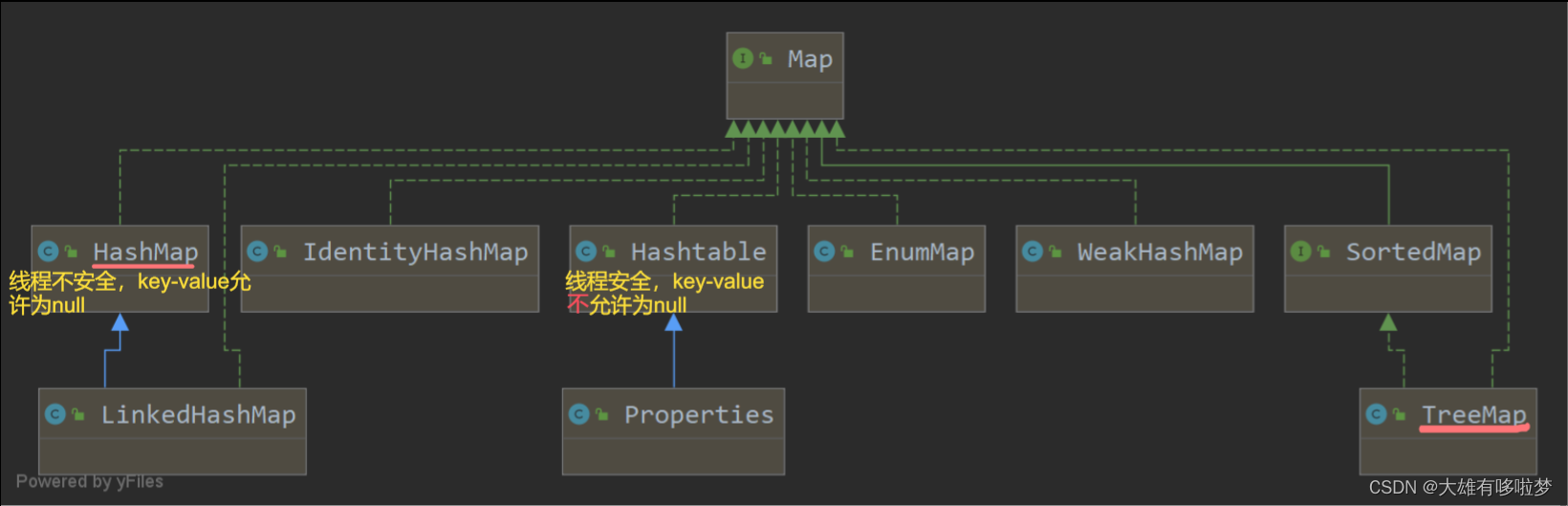
Map与Collection并列存在。用于保存具有映射关系的数据:Key-Value(双列元素)
Key-Value为了方便遍历,还会创建EntrySet集合,该集合存放元素的类型Entry,而一个Entry对象就有Key,Value。
当HashMap $ Node对象存放到EntrySet就会方便我们遍历,因为Map.Entry<K, V>提供了重要的方法,如下:
Set<Map.Entry<K, V>> entrySet();
interface Entry<K,V> {
K getKey();
V getValue();
...
}
3.1 Map接口常用方法
- put:添加
- remove:根据键删除映射关系
- get:根据键获取值
- size:获取元素个数
- isEmpty:判断元素是否为空
- clear:清空
- containsKey:查找键是否存在
3.2 Map常用遍历方式(6种)
第一组:先取出所有的key,在通过Key获取对应的Values
- 增强for循环
//先取出所有的key,在通过Key获取对应的Values
Set keyset = map.keySet();
for (Object key:keyset) {
System.out.println(key+"__"+map.get(key));
}
- 迭代器
//先取出所有的key,在通过Key获取对应的Values
Set keyset = map.keySet();
Iterator iterator = keyset.iterator();
while (iterator.hasNext()){
Object key = iterator.next();
System.out.println(map.get(key));
}
第二组:取出所有的Values
3. 增强for循环
//把所有的Values值取出
Collection values = map.values();
for (Object value:values) {
System.out.println(value);
}
- 迭代器
//把所有的Values值取出
Collection values = map.values();
Iterator iterator = values.iterator();
while (iterator.hasNext()){
Object value = iterator.next();
System.out.println(value);
}
第三组:通过EntrySet来获取key-value
5. 增强for循环
//通过EntrySet来获取key-value
Set entrySet = map.entrySet();
for (Object entry:entrySet) {
Map.Entry entrys = (Map.Entry) entry;
System.out.println(entrys.getKey()+" "+entrys.getValue());
}
- 迭代器
通过EntrySet来获取key-value
Set entrySet = map.entrySet();
Iterator iterator = entrySet.iterator();
while (iterator.hasNext()){
Object value = iterator.next();
Map.Entry entrys = (Map.Entry) value;
System.out.println(entrys.getKey()+" "+entrys.getValue());
}
4.List,Set,Map三者的区别
Collection集合主要有List和Set两大接口
Map是一个键值对集合,存储键、值和之间的映射。 Key无序,唯一;value 不要求有序,允许重复。
5.开发中如何选择集合
其实开发中如何选择集合,主要是取决于业务操作特点,然后根据集合实现类特性进行选择,分析如下:
1.先判断存储类型(是单列还是双列)
单列:Collection接口
- 允许重复:List
- 增删多:LinkedList(底层维护了双向链表)
- 改查多:ArrayList(底层维护了Object类型的可变数组)
- 不允许重复:Set
- 无序:HashSet(底层维护了HashMap)
- 排序:TreeSet
- 插入取出顺序一致:LinkedHashSet(底层维护了数组+双向链表)
双列:Map接口
- 键无序:HashMap
- 键有序:TreeMap
- 读取文件:Properties
- 插入取出顺序一致:LikendHashMap
二、List源码分析
1.ArrayList源码分析
ArrayList是线程不安全的,从源码中可以看出,没有添加synchronized
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
ArrayList (线程不安全),在多线程的情况下不建议使用ArrayList,可以考虑Vector(线程安全)。ArrayList 和Vector基本一样,除了在线程上面不同。
ArrayList底层操作机制源码分析:
-
ArrayList中维护了一个Object类型的数组(transient Object[] elementData)transient 表示该属性不会被序列化。 为什么要使用transient呢?因为lementData是一个缓存数组,它通常会预留一些容量,等容量不足时再扩充容量,那么有些空间可能就没有实际存储元素,可以保证只序列化实际存储的那些元素,而不是整个数组,从而节省空间和时间。
-
当创建ArrayList对象时,如果使用的是无参构造器,则初始化elementData容量为0 ,如果第一次添加,则扩容elementData为10,如果需要再次扩容,则扩容elementData为1.5倍
-
如果使用指定大小的容量capacity构造器,则初始化elementData容量为指定大小的capacity,如果需要扩容,则直接扩容elementData为1.5倍
-
当添加元素时,先判断是否需要扩容,如果需要则调用grow()方法,否则直接添加元素到合适的位置
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); //位移1位 相当于原来的oldCapacity 除于2
if (newCapacity - minCapacity < 0) //第一次扩容因为oldCapacity为0,所以默认elementData为10
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
//Arrays.copyOf保证原先的数组不变的情况下,进行扩容
}
2.Vector源码分析
Vector底层也是一个对象数组,protected Object[] elementData,它是线程安全的,操作方法基本都带有synchronized,在开发中需要线程同步安全时,可以考虑Vector
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}
public synchronized E set(int index, E element) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
......
}
- 如果是无参构造,默认Capacity为10,当Capacity超出10后就按2倍进行扩容
//无参构造,默认Capacity为10
public Vector() {
this(10);
}
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
//确定是否需要扩容
private void ensureCapacityHelper(int minCapacity) {
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
//capacityIncrement在创建Vector时默认就是0
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
- 如果是有参构造,指定大小,则每次直接按2倍扩容
- 如果指定大小Capacity和capacityIncrement(自定义扩容大小),则按照自定义扩容大小进行扩容
//也可以进行指定capacityIncrement,不用默认的0
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
//扩容核心代码
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
3.ArrayList与Vector的区别
4.LinkedList源码分析
- LinkedList底层实现了双向链表,维护了两个属性first(首节点)和last(尾结点),每个节点中维护了prev,item,next三个属性。通过prev自行前一个节点和next指向后一个节点,最终实现双向链表。
transient Node<E> first;
transient Node<E> last;
//node节点(有三个属性)
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
4.1 LinkedList添加操作底层分析
1.执行添加操作,在添加第一个元素时,从源码中可以看出 first、last和都指向同一个节点,并且两头为空。
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;// 第一次添加 last为null
final Node<E> newNode = new Node<>(l, e, null);// l==null
//将新的节点,加入到双向链表的最后
last = newNode; //last 指向newNode
if (l == null)//执行这条语句
first = newNode;//first 指向newNode
else
l.next = newNode;
size++;//链表元素个数
modCount++;//修改次数
}
参考下图更容易理解: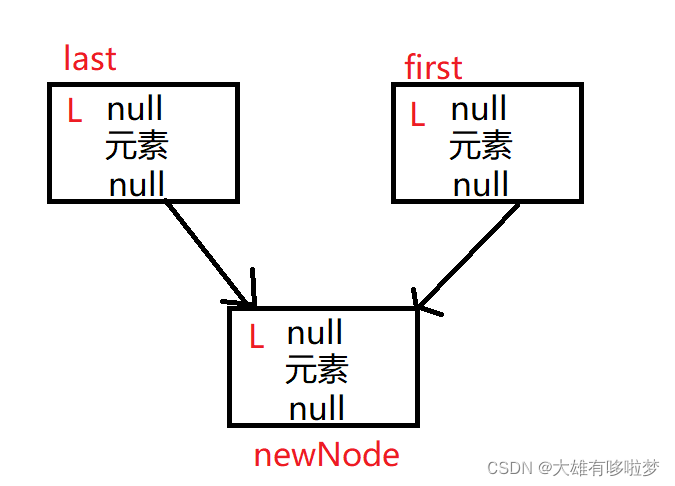
2.执行添加操作,在添加第二个元素时,从源码中可以看出 first、last和都指向同一个节点,并且两头为空。
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;// 第二次添加 l指向last
final Node<E> newNode = new Node<>(l, e, null);// l==last,这里相当于把新节点 的pre指向last(前一个节点)
//将新的节点,加入到双向链表的最后
last = newNode; //last 指向新的节点newNode(原来的旧节点就断开了)
if (l == null)
first = newNode;
else //l这个时候不为null 执行这条语句
l.next = newNode; //l.next 指向newNode
size++;//链表元素个数
modCount++;//修改次数
}
参考下图更容易理解: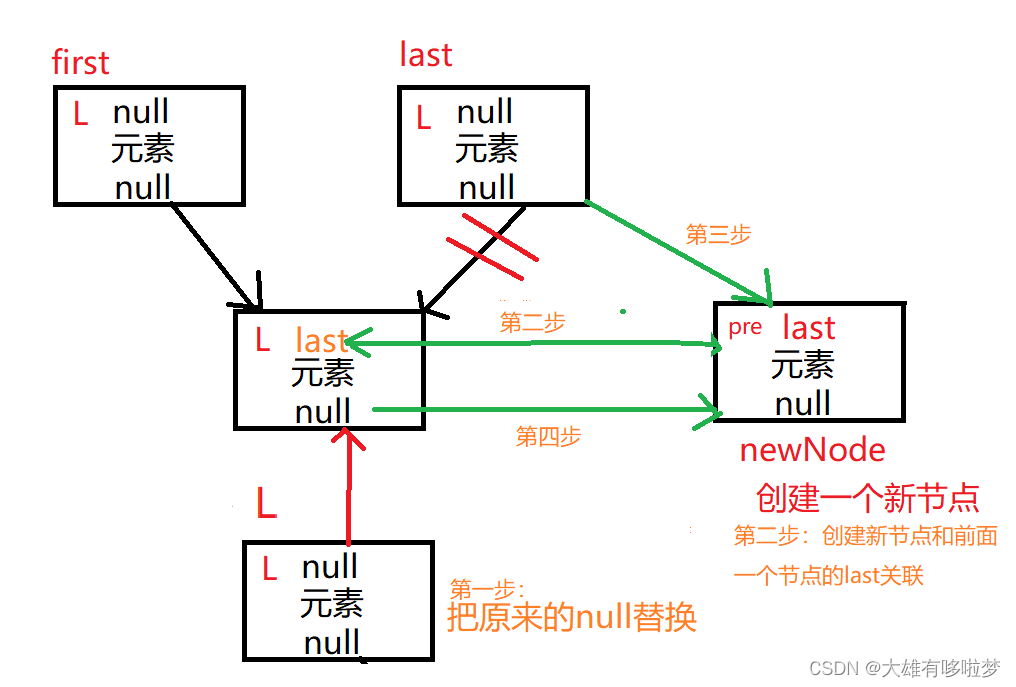
- 可以添加任意元素(元素可以重复),包括null,添加和删除是通过修改节点指向,不是由数组完成的,所以效率较高。
- 线程不安全,没有实现同步
5.ArrayList与LinkedList的区别
5.1 如何选择ArrayList和LinkedList
1.修改和查找操作多时,我们选择ArrayList,
2.增加和删除操作多时,我们选择LinkedList
注意:这两个集合都是线程不安全的,所以适合在单线程的情况下使用
三、Set源码分析
1.HashSet源码分析
1.1 HashSet添加操作底层分析
1.HashSet底层是HashMap,HashMap底层是(数组+链表+红黑树)
public HashSet() {
map = new HashMap<>();
}
2.添加一个元素时,先得到hash值(hash值是通过(h = key.hashCode()) ^ (h >>> 16)算法计算得出),在转成索引值
private static final Object PRESENT = new Object();
//PRESENT 占位用 没有实际意义
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
//这里主要用到key; value=PRESENT 是static共享的
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//得到hash值,这里的hash是通过算法计算得到的
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//核心方法(难点)
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//table就是HashMap的一个数组,类型是Node[]
//table是null或0,就是第一次扩容到16个空间
if ((tab = table) == null || (n = tab.length) == 0)
//resize()执行返回Node<K,V>[]有16个大小的
n = (tab = resize()).length;
//根据key得到的hash,去计算key应该放在table表的哪个索引位置,并把这个位置赋值给p
//如果p为null:表示还未存放元素,就创建一个Node,然后放进去tab[i] = newNode(hash, key, value, null);
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//如果p不为null:
else {
Node<K,V> e; K k;//定义了辅助变量,在需要的时候在创建
//如果当前索引位置对应的链表的第一个元素和准备添加的key的hash值一样
//并且满足下面两个条件之一:
//1、准备加入的key和p指向Node结点的key是同一个对象(地址相同)
//2、准备加入的key和p指向Node结点的key是同一个值(值相同)
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//这里可以重写equals方法 比如new Person("小明");new Person("小明");
//通过重写equals方法可以让他们按照equals去比较是否相等
e = p;
//判断p是不是红黑树,如果是调用putTreeVal方法
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//如果table对应索引位置,已经是一个链表,就可以使用for循环比较
//依次和该链表的每一个元素比较后,都不相同,则加入到该链表的最后,添加后立即判断该链表是否已经达到8个节点,如果达到就调用treeifyBin(tab, hash)方法(树化)转成红黑树。
//在转成红黑树时,要进行判断,如果该table数组size小于64(TREEIFY_CAPACITY),不会马上树化,会先扩容table。
//如果发现相同的情况,就直接break
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//这里指的是当用HashMap时,key一致,value不可重复(替换原来的value)
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
3.找到存储数据表table,看这个索引位置是否已经存放有元素
4.如果没有,直接加入
5.如果有,就调用equals比较,如果相同,就放弃添加,如果不同,则添加到最后
6.在java8中,如果一条链表的元素个数达到TREEIFY_THRESHOLD(默认是8),并且table的大小>=TREEIFY_CAPACITY(默认64),就会进行树化(红黑树)
1.2 HashSet的扩容和转红黑树机制
- HashSet底层是HashMap,第一次添加时,table数组扩容到16,临界值(threshold)是16*加载因子(loadFactor)0.75=12
- 如果table数组使用到了临界值12,就会扩容到162=32,新的临界值就是320.75=24,以此类推
- 在Java8中,如果一条链表的元素个数达到TREEIFY_THRESHOLD(默认是8),并且table的大小>= TREEIFY_CAPACITY(默认64),就会进行树化(红黑树),否则仍然采用数组扩容机制
2.LinkedHashSet源码分析
LinkedHashSet底层是一个LinkedHashMap,底层维护了一个数组+双向链表。添加数据和取出元素的顺序一致
2.1 LinkedHashSet添加操作底层分析
1.第一次添加时,直接将数值table扩容到16,存放节点(数据)的类型是LinkedHashMap $ Entry,数组类型是HashMap $ Node[]
作为HashSet的子类,只是比它多了一条链表,这条链表用来记录元素顺序,因此LinkedHashSet其中的元素有序。
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
添加方法和前面描述的HashSet添加操作底层分析一样的,这里就不再重复介绍。
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
四、Map源码分析
1.HashMap源码分析
在上面的HashSet中已经讲过了,这里就简单讲解一下
HashMap是最经典的Map实现,下面以它的视角介绍put的过程:
1.首次扩容:
- 先判断数组是否为空,若数组为空则进行第一次扩容(resize);
2.计算索引:
- 通过hash算法,计算键值对在数组中的索引;
3.插入数据:
-
如果当前位置元素为空,则直接插入数据;
-
如果当前位置元素非空,且key已存在,则直接覆盖其value;
-
如果当前位置元素非空,且key不存在,则将数据链到链表末端;
-
若链表长度达到8,则将链表转换成红黑树,并将数据插入树中;
4.再次扩容
如果数组中元素个数(size)超过threshold,则再次进行扩容操作。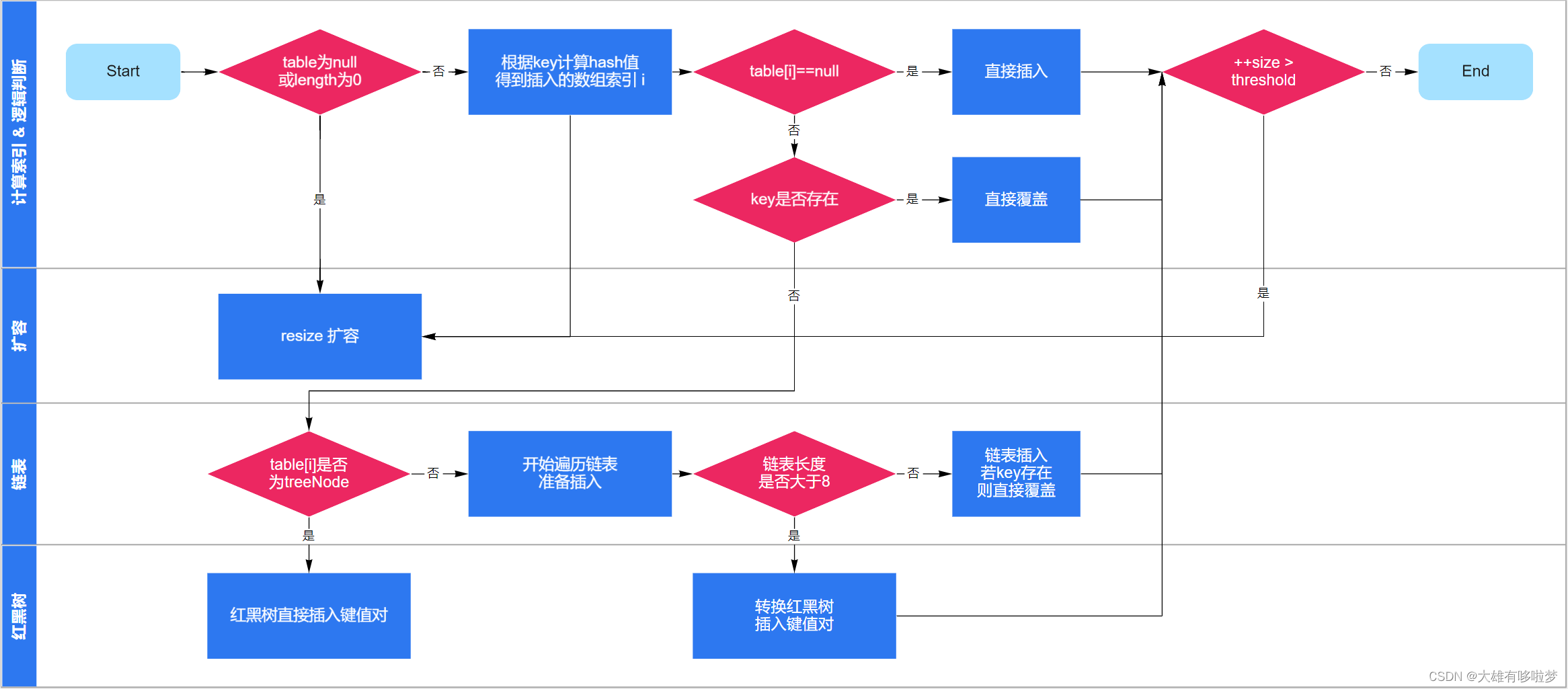
2.HashTable源码分析
HashTable(线程安全)使用方法基本和HashMap(线程不安全)一致,HashTable的键和值都不能为空
底层用Hashtable $ Entry[] 初始化大小为11。临界值threshold为8 = 11 * loadFactor(0.75)
private transient Entry<?,?>[] table;
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
//添加方法
addEntry(hash, key, value, index);
return null;
}
private void addEntry(int hash, K key, V value, int index) {
modCount++;
Entry<?,?> tab[] = table;
if (count >= threshold) {
// 扩容方法
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
}
3.TreeMap源码分析
TreeMap基于红黑树(Red-Black tree)实现。映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。TreeMap的基本操作containsKey、get、put、remove方法,它的时间复杂度是log(N)。
TreeMap包含几个重要的成员变量:root、size、comparator。其中root是红黑树的根节点。它是Entry类型,Entry是红黑树的节点,它包含了红黑树的6个基本组成:key、value、left、right、parent和color。Entry节点根据根据Key排序,包含的内容是value。Entry中key比较大小是根据比较器comparator来进行判断的。size是红黑树的节点个数。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK