

Pytorch踩坑记:赋值、浅拷贝、深拷贝三者的区别
source link: https://weisenhui.top/posts/34953.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

1. 写在前面
之前一直不太搞明白浅拷贝和赋值、深拷贝到底有什么区别,直到被pytorch的model.state_dict给坑了
今天在和实验室同学讨论联邦学习框架代码的时候,终于明白了他们之间的区别,这里做个记录。
2. 先说结论
(1)直接赋值:给变量取个别名,原来叫张三,现在我给他取个小名,叫小张
- b = a b是a的别名b是a的别名
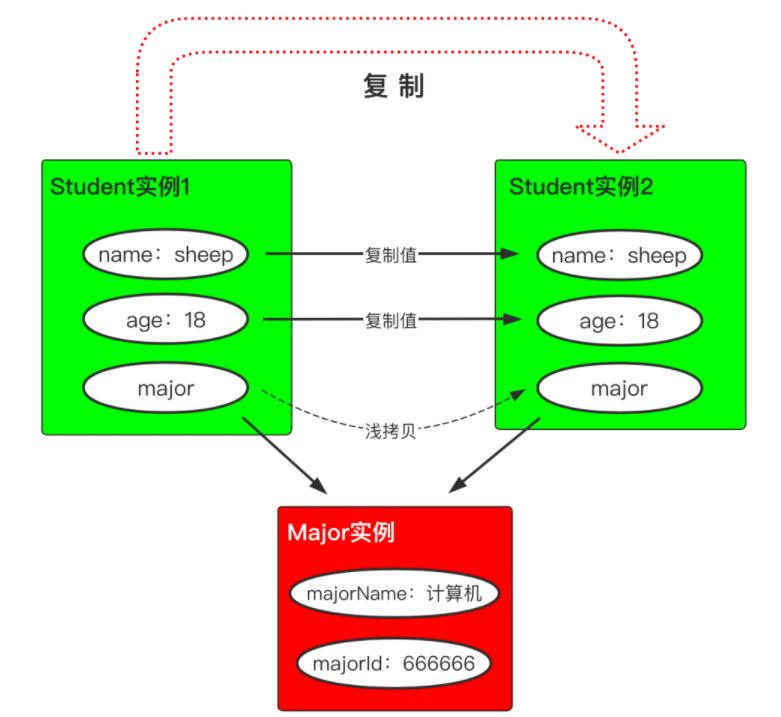
(2)浅拷贝shadowcopyshadowcopy:拷贝最外层的数值和指针,不拷贝更深层次的对象,即只拷贝了父对象
- copy.copyxxxxxx
model.state_dict()也是浅拷贝,如果令param=model.state_dict,那么当你修改param,相应地也会修改model的参数。model这个对象实际上是指向各个参数矩阵的,而浅拷贝只会拷贝最外层的这些“指针”。具体可以看下文的示例
题外话:浅拷贝为什么叫“浅”,因为他只拷贝最外层的东西,不会去拷贝最外层“指针”所指向的内层的东西,所以浅。而深拷贝则会拷贝全部层的东西,所以深
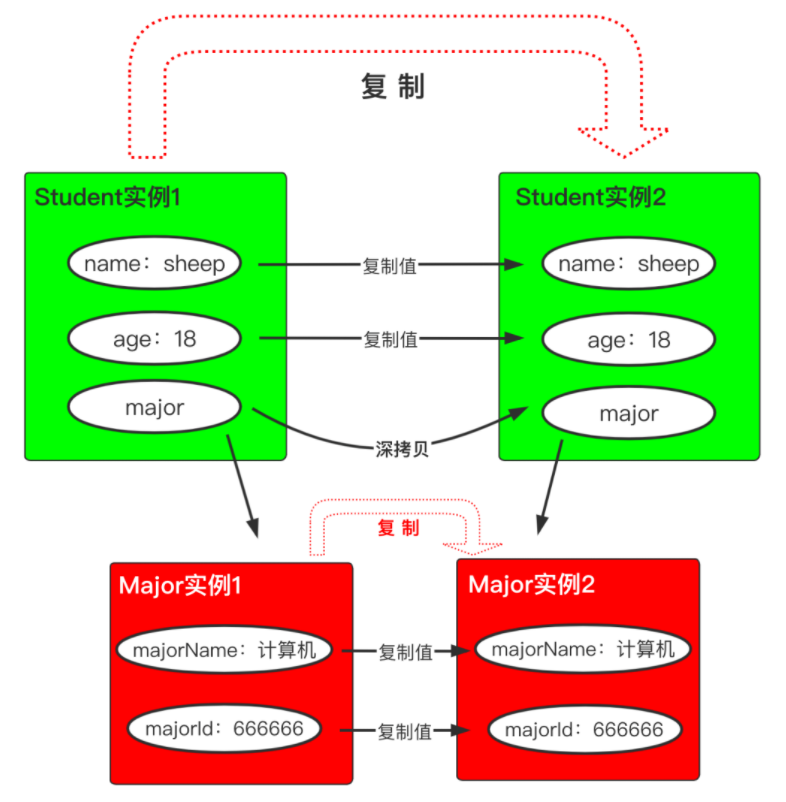
(3)深拷贝(deepcopy):拷贝数值、指针和指针指向的深层次内存空间,拷贝了父对象及其子对象。
- copy.deepcopyxxxxxx
model.load_state_dict(xxx)是深拷贝
3. 一图胜前言
这一小节主要来自:一个工作三年的同事,居然还搞不清深拷贝、浅拷贝…
2021年10月24日 更新:下面这个图其实是以Java语言而言的,我一开始以为Python字符串和int数值应该也是直接赋值的,后来经过验证,发现python中的字符串其实是引用(地址),所以若a=”hello”,则b=a是把”hello”的地址赋值给b。另外-5到256这个范围内的整数是公用一块内存空间的,具体请看我的博客:Python中容易被忽视的知识点:字符串是传引用以及整数-5到256共享内存空间
浅拷贝
深拷贝
深拷贝相较于上面所示的浅拷贝,除了值类型字段会复制一份,引用类型字段所指向的对象,会在内存中也创建一个副本,就像这个样子:
4. Pytorch的model load_state_dict和state_dict有坑点
pytorch在获取模型参数和加载模型参数时是有坑点的,而且这个bug一般不太容易发现,因为他不会报错,有时你很难通过实验结果注意到这个问题,我自己写框架时也是被坑过。
model.state_dict()实际上是浅拷贝,如果令param=model.state_dict,那么当你修改param,相应地也会修改model的参数。model这个对象实际上是指向各个参数矩阵的,而浅拷贝只会拷贝最外层的这些“指针”。model.load_state_dict(xxx)是深拷贝
用代码验证以上观点,可以结合上文的两张示意图来理解下面代码
import torch
import copy
m1 = torch.nn.Linear(in_features=5, out_features=1, bias=True)
m2 = torch.nn.Linear(in_features=5, out_features=1, bias=True)
# m1是引用指向某块内存空间
# 浅拷贝相当于拷贝一个引用,所以他们“引用”变量的id是不一样的,指向的内存空间是一样的
ck = copy.copy(m1)
print(id(m1) == id(ck)) # False
print(m1.weight)
# Parameter containing:
# tensor([[ 0.0171, 0.4382, -0.4297, 0.4098, -0.3954]], requires_grad=True)
# state_dict is shadow copy
p = m1.state_dict()
print(id(m1.state_dict()) == id(p)) # False
# 通过引用p去修改内存空间
p['weight'][0][0] = 8.8888
# 可以看到m1指向的内存空间也被修改了
print(m1.state_dict())
# OrderedDict([('weight', tensor([[ 8.8888, 0.4382, -0.4297, 0.4098, -0.3954]])), ('bias', tensor([0.3964]))])
# deepcopy
m2.load_state_dict(p)
m2.weight[0][0] = 2.0
print(p)
# OrderedDict([('weight', tensor([[ 8.8888, 0.4382, -0.4297, 0.4098, -0.3954]])), ('bias', tensor([0.3964]))])
print(m2.state_dict())
# OrderedDict([('weight', tensor([[ 2.0000, 0.4382, -0.4297, 0.4098, -0.3954]])), ('bias', tensor([0.3964]))])在我的联邦学习框架中本地模型参数确实是浅拷贝,但是我们没有去修改这个local_params,我们只是把不同客户端的local_params加权平均去更新global_params而已,所以不用deepcopy也没事
但如果想保存最优模型的参数,则必须要用deepcopy
best_state changes with the model during training in pytorch 这位提问者想保存最佳模型参数,结果因为浅拷贝,导致保存的都是最后一轮的模型参数,下面是他的错误代码:
def train():
#training steps …
if acc > best_acc:
best_state = model.state_dict()
best_acc = acc
return best_state 5. 实战演练
import copy
a = [1, 2, 3, 4, ['a', 'b']] # 原始对象
b = a # 赋值,传对象的引用
c = copy.copy(a) # 对象拷贝,浅拷贝
d = copy.deepcopy(a) # 对象拷贝,深拷贝
a.append(5) # 修改对象a
a[4].append('c') # a[4]是指针,修改对象a中的['a', 'b']数组对象
print('a = ', a)
print('b = ', b)
print('c = ', c) # 浅拷贝,只会拷贝最外层的数值或指针
print('d = ', d)a = [1, 2, 3, 4, ['a', 'b', 'c'], 5]
b = [1, 2, 3, 4, ['a', 'b', 'c'], 5]
c = [1, 2, 3, 4, ['a', 'b', 'c']]
d = [1, 2, 3, 4, ['a', 'b']]现在你看下面这段代码的输出结果应该就不奇怪了吧
import copy
A = [1, 2, 3]
print(A) # [1, 2, 3]
B = copy.copy(A) # 浅拷贝(最外层"值"会拷贝,"引用"会拷贝)
B.append(5)
print(A) # [1, 2, 3]
print(B) # [1, 2, 3, 5]6. Deep copy VS Shadow copy
深拷贝示例:
# Python code to demonstrate copy operations
# importing "copy" for copy operations
import copy
# initializing list 1
li1 = [1, 2, [3, 5], 4]
# using deepcopy to deep copy
li2 = copy.deepcopy(li1)
# original elements of list
print("The original elements before deep copying")
for i in range(0, len(li1)):
print(li1[i], end=" ")
print("\r")
# adding and element to new list
li2[2][0] = 7
# Change is reflected in l2
print("The new list of elements after deep copying ")
for i in range(0, len(li1)):
print(li2[i], end=" ")
print("\r")The original elements before deep copying
1 2 [3, 5] 4
The new list of elements after deep copying
1 2 [7, 5] 4
The original elements after deep copying
1 2 [3, 5] 4 浅拷贝示例:
# Python code to demonstrate copy operations
# importing "copy" for copy operations
import copy
# initializing list 1
li1 = [1, 2, [3,5], 4]
# using copy to shallow copy
li2 = copy.copy(li1)
# original elements of list
print ("The original elements before shallow copying")
for i in range(0,len(li1)):
print (li1[i],end=" ")
print("\r")
# adding and element to new list
li2[2][0] = 7
# checking if change is reflected
print ("The original elements after shallow copying")
for i in range(0,len( li1)):
print (li1[i],end=" ")The original elements before shallow copying
1 2 [3, 5] 4
The original elements after shallow copying
1 2 [7, 5] 4 注意:上面用了li2[2][0] = 7,相当于是在修改引用的内存空间;如果是li2[1] = 7,那么l1[1]不会改变
7. 参考资料
ii. copy in Python DeepCopyandShallowCopyDeepCopyandShallowCopy (geeksforgeeks的文章还是挺清楚的)
v. 一个工作三年的同事,居然还搞不清深拷贝、浅拷贝… (图解挺不错的)
vi. best_state changes with the model during training in pytorch (这位老哥想保存最佳模型参数,结果因为浅拷贝,导致保存的都是最后一轮的模型参数)
vii. Python中的赋值复制复制、浅拷贝与深拷贝 (这篇文章关于可变对象和不可对象的拷贝的id是否会改变进行了讨论)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK