

手握这个实时计算平台架构,哪怕3亿月活都没怂过
source link: https://dbaplus.cn/news-141-4310-1.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

手握这个实时计算平台架构,哪怕3亿月活都没怂过
一、背景介绍
首先介绍一下OPPO大数据覆盖的业务范围以及大数据平台概况。
1、OPPO大数据业务范围
说到OPPO大家应该都是耳熟能详了,是国内Top3的智能手机生产商之一。智能手机的设计制造和销售业务是OPPO非常重的部分,用户群体也非常庞大,目前ColorOS(OPPO定制的系统), 月活用户数已经超过3亿。依托于手机衍生了众多的业务服务,大的分类有用户服务、商店与游戏、内容产品、智能服务等,我们大数据几乎是服务了所有的这些业务。这其中比较典型的服务对象有软件商店、浏览器、商城(OPPO电商业务)等。目前电商业务主要是以手机、数码、IOT品类产品的销售为主。所有这些系统产生的数据都要通过大数据平台来做处理。
2、大数据计算(开源+自研相结合)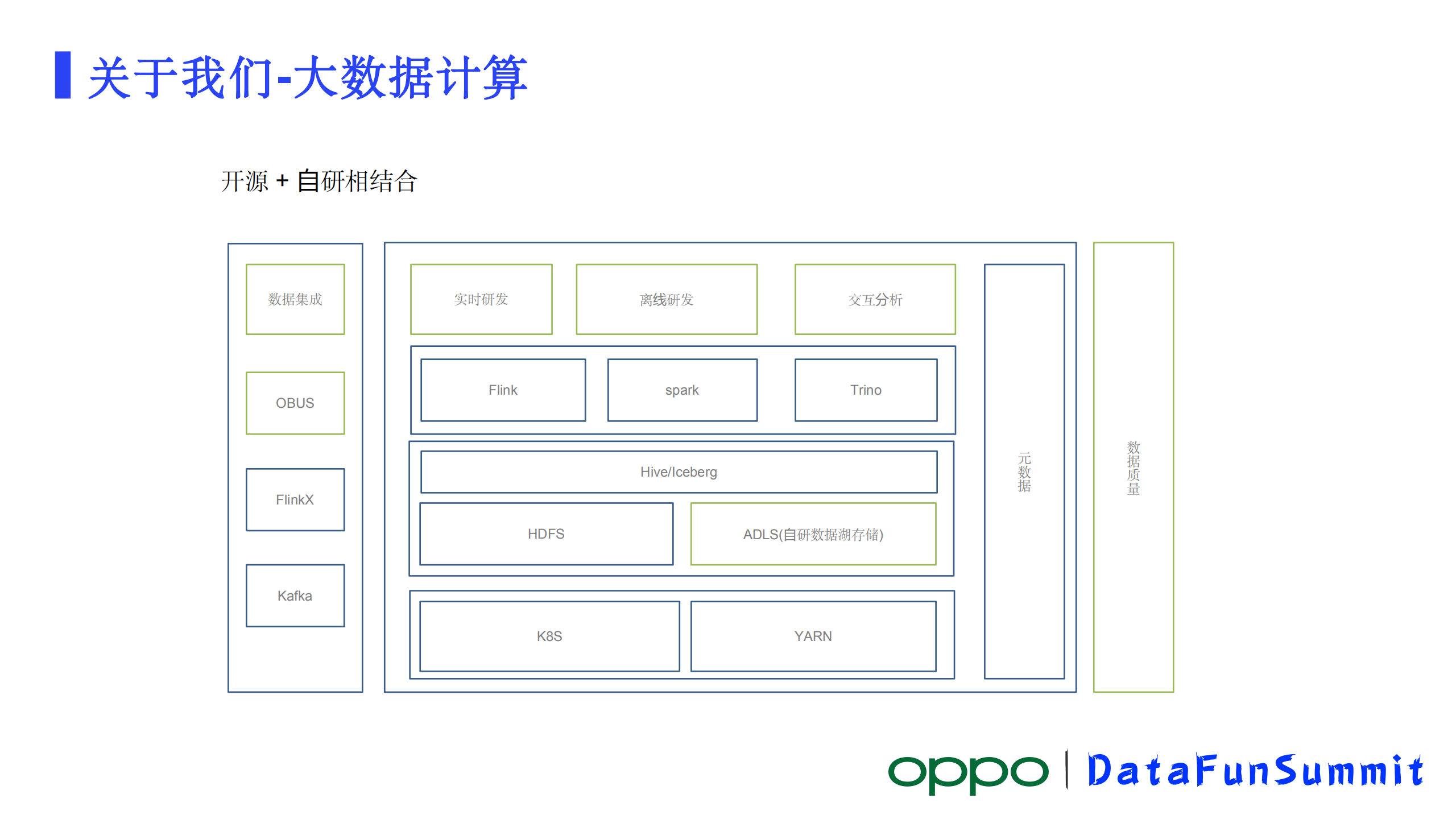
大数据平台存储数据量已经超过了600P,每日增量数据有过万亿条,日增数据量几个PB。这是我们大数据平台的个能力矩阵,列了一些主要的。我们主要采用开源+自研相结合的方式来构建我们的大数据计算体系。开源的包括用到了Flink、Spark、Trino、Yarn等系统和组件, 在这些开源系统和组件的基础之上我们构建了自研的数据接入、实时计算、离线计算、交互分析系统以及数据质量等体系。
二、平台架构
1、实时平台架构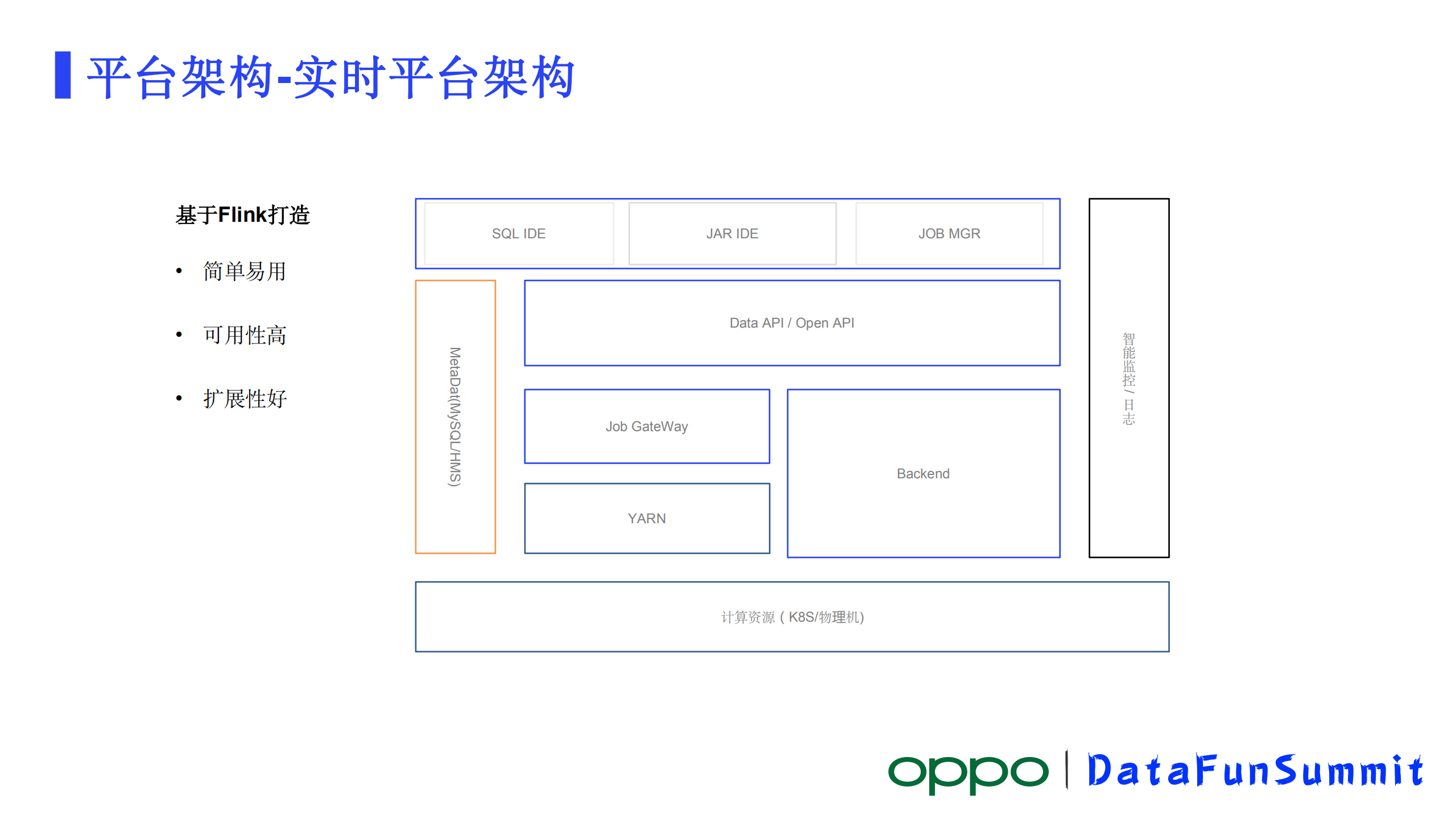
OPPO实时计算平台依托于Flink来构建,计算引擎是Flink,目前支持SQL和JAR两种开发作业方式。架构图最上边一层是交互式的开发页面,是面向数据开人员的,包括了SQL开发IDE、JAR作业开发IDE、作业监控管理工具。往下是Data API和Open Api 这层就是处理各种业务逻辑,其中Data API主要是处理我们平台内的各种作业相关的逻辑,Open API是暴露我们计算服务的一套接口主要面向公司内的其他平台,让他们能依托我们计算能力迅速构建自己的一些产品。再往下是Job GateWay,Job GateWay执行作业编译上下线等等动作相关操作,通过Job GateWay,作业提交到Yarn集群或者K8s集群去运行。还有一个模块就是Backend模块,这个模块主要处理在线作业监控逻辑。架构上的服务都会与左边MetaData模块交互,MetaData模块里面存储了我们所有作业的元数据信息。图右侧的智能监控是一个外部的服务,贯穿了所有的模块,所有模块监控数据都进入到监控系统里面,智能监控提供指标或者是日志查询和监控的功能。
从整个系统层面来设计,构建整个系统从这几个方面来考虑:
1)系统的易用性
从易用性来考虑,我们提供了一站式的SQL IDE,通过SQL可以完成作业开发和提交作业流程。Job管理模块,提供了整个作业生命周期的管理工具。
2)系统的可用性
从可用性来设计,所有模块包括IDE、API、Job GateWay、Backend服务模块都采用的高可用设计,支持多实例部署,一个实例宕机不会影响整个服务的可用性。
3)系统的可拓展性
从可扩展性来设计,我们对Job GateWay做了一个很好的抽象,在早期版本,在GateWay相关的一些作业提交的功能和Backend融合到一起。在最近的版本里,把GateWay做了一个剥离,并且把它作了一层抽象,支持插件化的加载不同的Deploy组件以支持我们作业往多种计算集群里提交作业,最常见的就是Yarn和K8s,目前Yarn这种方式是支持的最好。最近也在做K8s的扩展,后续GateWay就能把作业以云原生的方式提交到K8s去运行。此外GateWay模块对Flink多版本的支持也被考虑进去,Flink的区非常活跃,版本也在快速的迭代,包括OPPO自己也在社区版本的基础上做一些功能的优化迭代,优化迭代之后,我们要让它能快速发布到线上环境,目前GateWay能够很方便支持多版本。
这就是实时计算平台的基本情况。
2、实时开发流程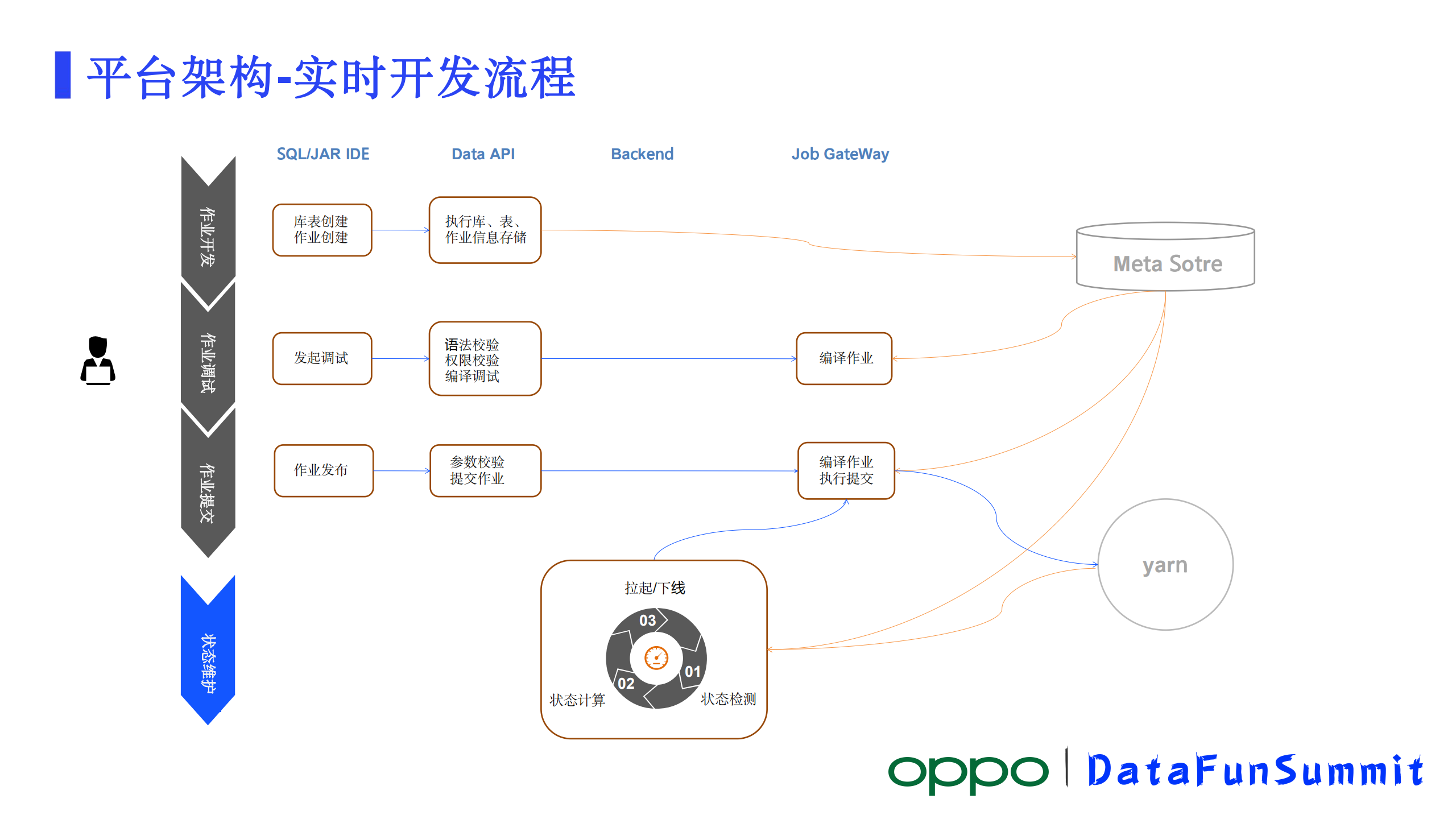
作业生命周期里模块之间是怎样来协作的?
1)作业开发阶段
作业开发阶段,开发是在IDE里面去完成的,开发人员可以写SQL,也可以JAR包作业方式开发。编辑完之后,IDE向API发起的请求,API对作业相关信息进行校验并将其存储到MetaStore里。
2)作业调试阶段
作业调试阶段,作为调试还是从IDE发起,IDE发起调试,来到API模块,首先会对作业的SQL语法做校验,其次会对SQL引用到了各种库表的权限进行校验,必须要有库表权限才能去操作这些库表的数据,如果库表校验失败了,直接返回错误IDE将异常信息展示给数据开发人员。校验通过,接下来就会对作业里SQL的语法进行校验,还会对作业里用到的资源比如kafka等进行校验,然后接着来到GateWay,对作业进行一个编译,编译结果返回给API, API模块把最终的结果返回IDE做展示,通过就可以走下一步了,没通过根据反馈的信息再进行重新的一些调整。
3)作业提交阶段
作业提交阶段,作业提交也在IDE上发起作业发布请求。作业发布的过程会将作业相关的所有参数带过来, API会对作业的参数做校验,校验通过往下走,没通过返回给前端去做一个展示。校验通过,就向GateWay发起一个作业提交的请求,作业提交请求来到GateWay,先对着作业进行编译,编译完根据作业的参数选择Yarn或者K8s其中一个插件,然后加载插件并把作业提交到Yarn或者K8s集群中,至此如果没有其他额外问题作业就实际运行起来了,目前主要是到Yarn集群。
4)作业状态维护阶段
作业状态维护阶段,维护阶段主要是Backend模块在工作。我们一个作业提交上去运行起来后,在运行的过程中有很多因素都会对作业造成影响。严重的会导致作业挂掉,Flink内部有自己的重启策略,如果超过重启次数后还是挂掉,这时候Backend起作用了,Backend有一个定时任务来做作业状态的维护。定时任务首先会访问元数据,获取作业的逻辑状态,接着它会访问Yarn去获取作业的一个实际的运行状态,接下来就根据这两个状态做比对,得出这个作业现在应该是要被拉起来还是需要被kill,当数据库里的状态是已上线,但是在线上的实际运行状态是一个失败,这个时候Backend就会判定为应该执行拉起作业。另外一种情况,数据库里已经是已下线了,但是在yarn上状态还是在运行中,这个时候就状态也不一致了,需要将作业下线掉。第三步就是执行作业的拉起或者下线。
在作业的整个生命周期中,系统中的各个模块就是这样来协作的。
3、SQL IDE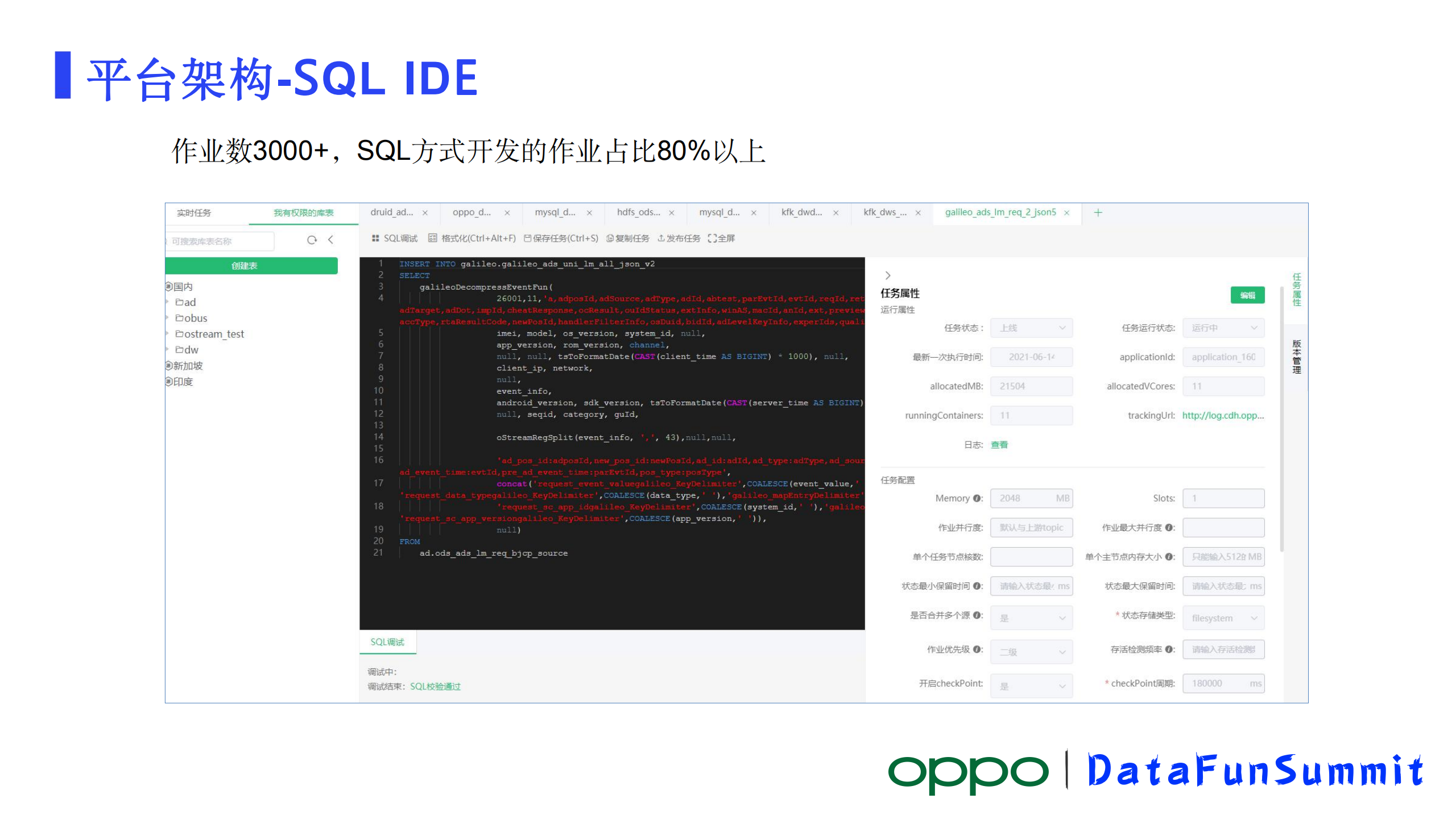
上面是一个SQL IDE截图,可以看到这个图的左侧是展示了作业元数据信息,包括了作业可以使用的库、表等等信息。中间是SQL开发的窗口,可以在里编写SQL,这里可以对SQL做格式化、还提供SQL自动补全等。右边是作业参数编辑窗口和作业的版本管理的窗口。最底端是SQL调试的结果反馈窗口。当前展示的作业是一个调试成功的状态。目前平台上3000+的作业,80%以上都是以SQL的方式开发的。
4、发展阶段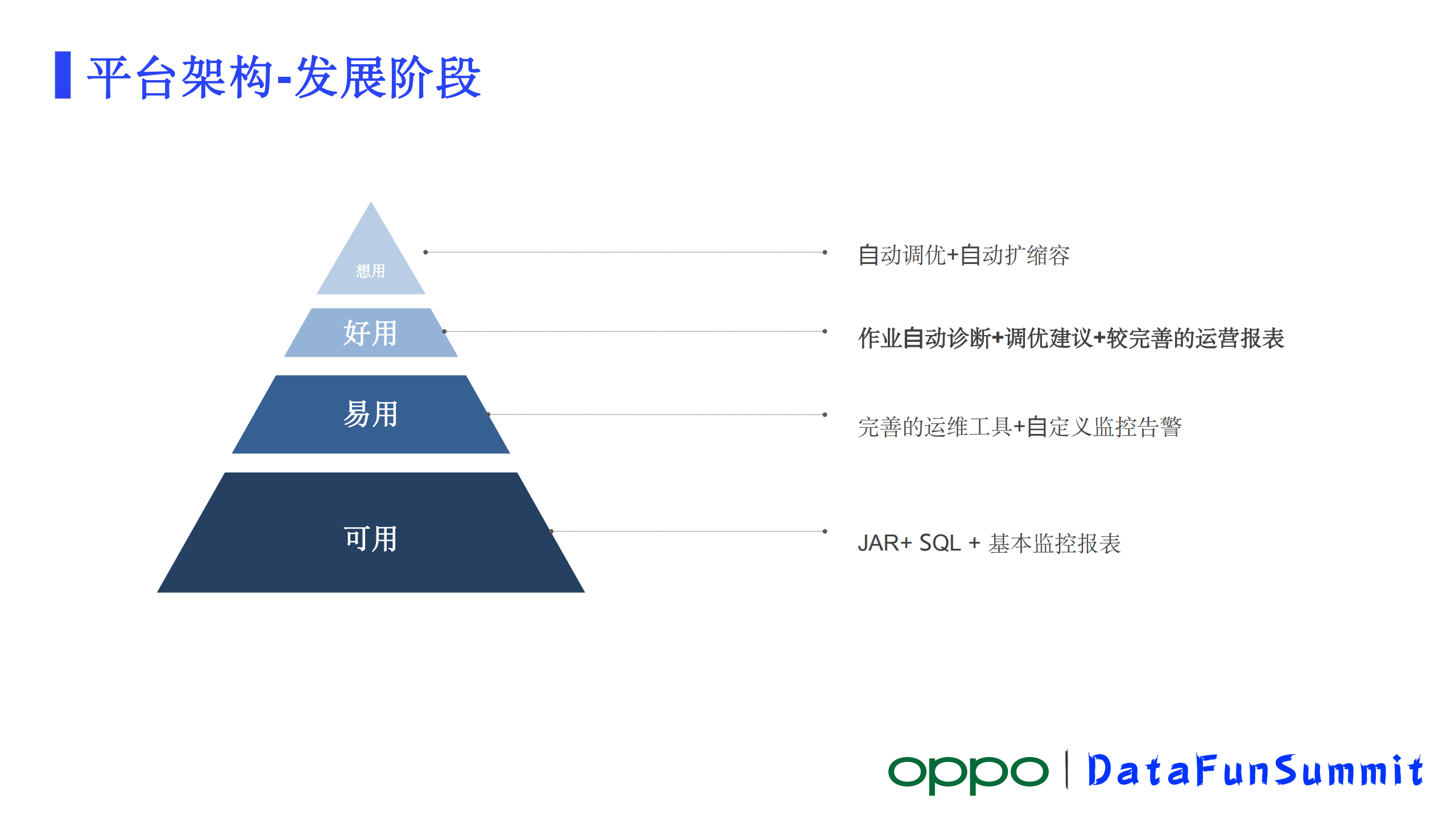
一个作业有自己的生命周期,同样一个平台也有自己的发展阶段,来看下我们现在所处的阶段。
首先我以可用、易用、好用、想用来定义一个平台的四个不同阶段:
-
可用——一个平台能提供一些最核心的能力,业务通过这个平台能够基本上达到他想要的结果,这个平台基本上就可用了。
-
易用——在可用的基础上,能提供相对完善的辅助功能让业务能够快速的去实现自己想要的结果,这样就实现了可用到易用的进步。
-
好用——好用在易用的基础之上,要进一步提供各种便利的工具,能够帮助业务管理好作业的生命周期,能协助业务快速解决遇到的各种问题。
-
想用——想用是一个比较高级的一个层次了,业务只要是想到有类似场景,他都会想到这个系统,并且来用这个系统。
对应到我们的计算平台,在我们提供了SQL作业和JAR作业以及一些基本的监控报表之后,其实它就已经就可用了。另外再提供相对完善的运维工具,加监控告警相对易用了。好用的系统我认为得提供作业诊断、调优建议,另外也要有较完善的运营工具。到了想用的那个阶段,业务基本上可以什么都不用管了,他把作业正常提交之后系统就帮他维护,作业生命周期完成后,把运行的业务报表发给业务人员,这是最高级的阶段。按照此前定义的评判标准,我认为我们平台应该是处于易用到好用这样一个跨越阶段,在这个过程中我们做了很多工作,比如提供作业的诊断调优建议,作业运行报表等。
5、作业诊断
1)诊断目标

作业诊断目标,让作业的运行状态实时的反馈给业务。整个作业运行过程中有很多监控指标,每个指标有不同的含义,如果只把监控指标进行展示,业务可能看不懂,所以我们要将相关指标实时并且以一种可读、业务能看懂的方式来反馈。另外作业运行过程中,出了问题要给出作业的一个调优建议,作业诊断就是要实现这两个目标。实现的一个基本路径,构建一个诊断系统,通过监测采集作业生命周期中产生的各种指标以及日志信息来进行分析。
2)诊断分析
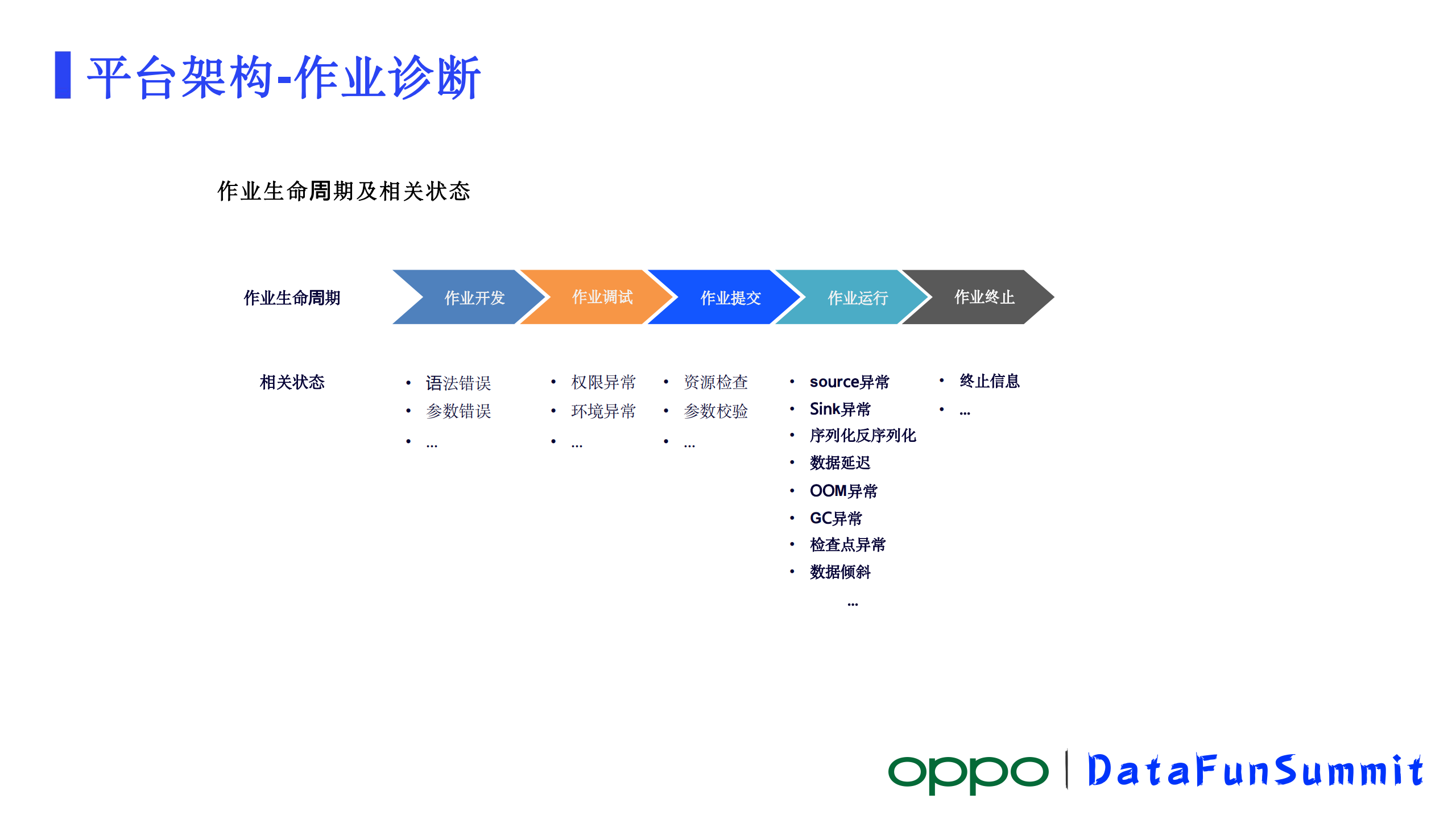
首先我们对作业生命周期里面的指标和状态进行分析,知道生命周期里它会产生一些什么样的信息,从作业开发到作业终止。不同阶段有不同的信息。在作业开发阶段,有语法错误,参数错误这样一些提示。作业调试阶段有权限校验失败,环境的检查失败,这样的信息可以给到用户。作业提交阶段有资源检查异常,参数校验异常等。这三个阶段现在都是直接将信息展示到IDE反馈给作业开发人员。作业运行阶段,会有Source异常、Sink异常、序列化反序列化异常、数据延迟、OOM异常、检查点异常、数据倾斜等等信息。作业诊断,主要集中在作业运行和作业终止这两个阶段,作业有各种原因会终止掉了,这时候因为作业没有监控信息了,需要对终止的一些日志信息做分析。
3)诊断流程
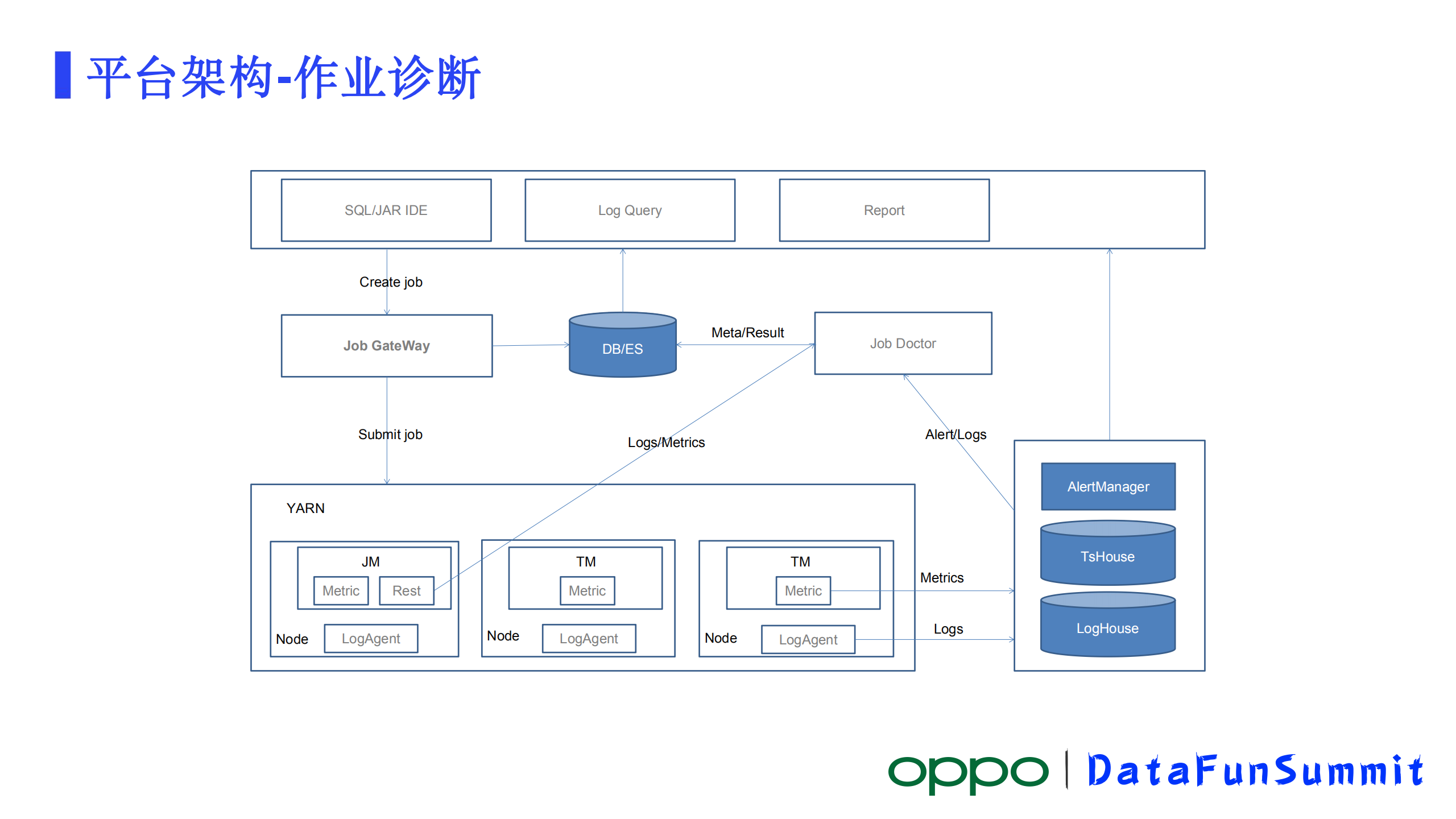
作业诊断大致的架构如上图所示。从IDE发起的一个作业提交,通过Job GateWay,很方便的把作业提交到计算集群上运行起来,这里直接提交到Yarn集群上,作业有JM、TM两种角色的节点。每个JM有自己的metric体系,对外暴露有REST的API, TM也是类似。作业的metric通过作业节点自身的监控体系被汇报到智能监控平台上存储和处理。另外是日志信息,我们在每一个Yarn node上部署了LogAgent,它会把节点上的日志采集汇总到智能监控平台进行存储并提供检索服务。
此外,在智能监控平台上可以去配置各种metric的触发策略,以作业重启metric为例,我们在平台上配置一个作业重启告警和回调策略注册一个回调接口,如果发生作业重启之后,就会形成一条告警并且回调我们注册的接口通知到我们的作业诊断的模块。
诊断模块收到回调之后,首先会去尝试通过MetaData提供的REST接口获取作业的信息,获取到作业信息之后会通过JM的REST的接口去获取作业的异常信息。因为重启可能是内部的一个重启,就是它在自身的重启策略的范围之内的一个重启,实际上没挂掉,这个时候是可以通过JM 的REST接口去获取到精准的异常信息的,拿着精准的异常信息,通过分析就能得出作业重启的原因,紧接着将分析结果和异常信息写到DB和ES里面去,DB存储的主要是分析结果,ES把异常的具体的信息给存起来,便于后续去追踪。
因为有可能这个诊断是不准确的,后续我们可以通过再次分析ES里面的日志信息去纠正这个诊断结果。如果这个阶段从JM REST拿不到异常信息,大概率说明这个作业其实已经挂了,这个时候我们之前从通过LogAgent上报的日志就有用处了,这时就可以通过监控平台提供的日志检索把日志取出来,对日志做分析,最终也能得出一个结果,结果和分析的具体的日志也存起来。
这就是大概的作业诊断的流程。
4)诊断结果
诊断结果有了之后,平台上面就可以去进行一些展示,把这些诊断结果和调优的建议都展示到页面上,另外还可以通过Log Query去查看具体作业日志信息。
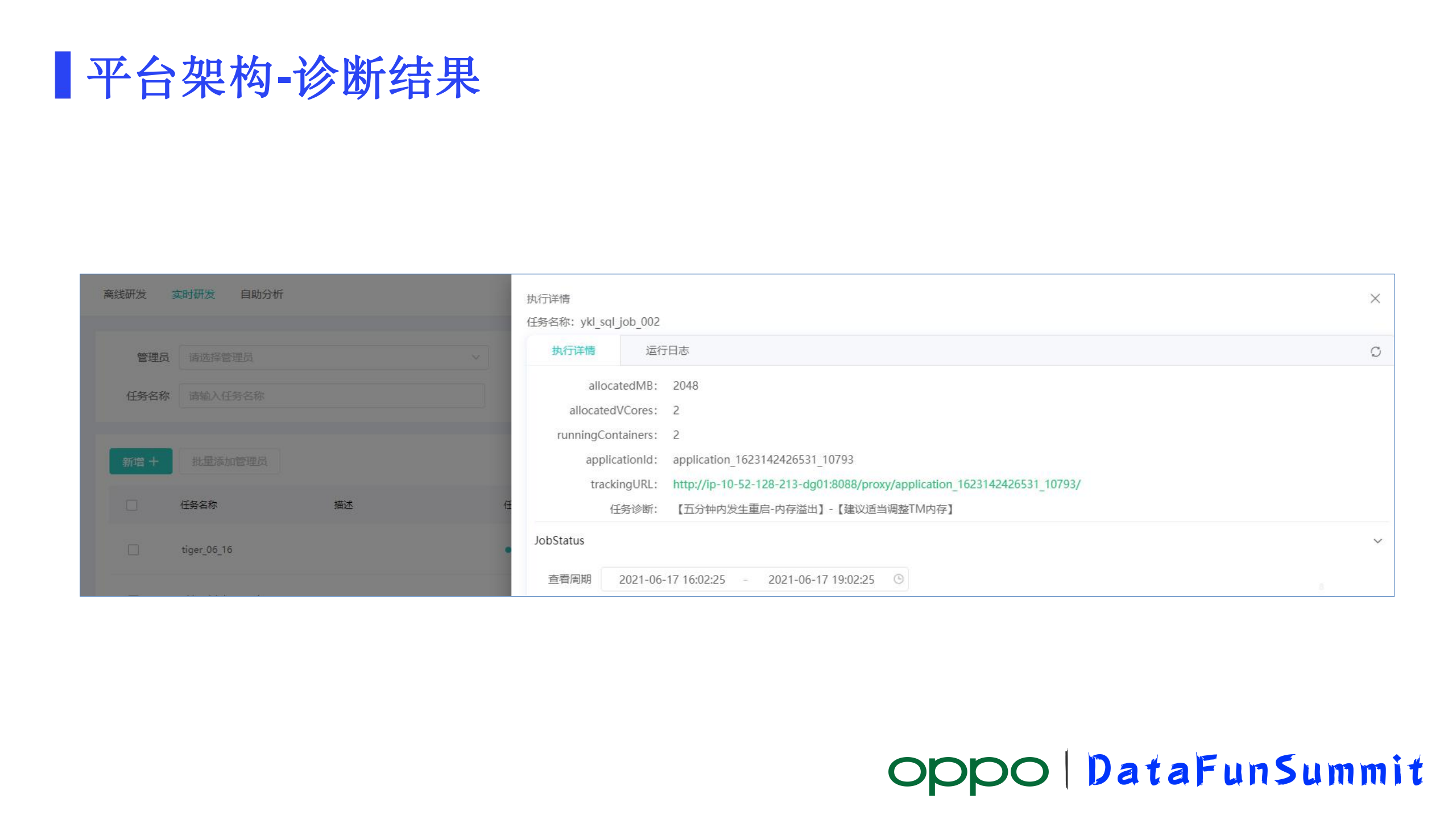
目前能做到,大致就是图上这样一个结果,展示任务当前的一个状况,如现在使用了多少核,状态是什么,最近一段时间它发生了一次重启,重启的原因是内存溢出。然后给出了内存溢出的调优建议,建议适当的调整TM的内存。
6、链路监控
从数据接入系统OBUS对数据进行初步的处理再写入到kafka,再到Flink收取kafka数据进行处理,核心的链路的流量非常大,也非常重要,我们做了一个核心链路延迟监控。延迟可以分几个阶段,第一个阶段OBUS内部处理这个业务数据的延迟。OBUS处理完发kafka的延迟,处理完发kafka一般来讲是同步的发送,但有可能这个地方会发生失败再发起发送,重试的过程中会产生很大的延迟。另外一个是Kafka已经收到这个消息了,Flink计算能力足产生的一个延迟,这三个延迟加在一起,就是整个链路的延迟。

首先在OBUS接收到数据的时候,会记录一个接收的时间记做server_time,OBUS处理数据结束时间会记一个时间parse_time,紧接着就往kafka发,Kafka本身不需要记录时间,kafka在对消息进行存储的时候会记一个存储的时间timestamp,最后Flink这个阶段接收消息,有一个process_time,这样就可以得到四个时间。分析清楚,接下来就是实现,我们是在flink KafkaSource模块里对代码做了一个优化,在这里对接收到的信息,把这几个时间做一个计算,把计算结果作为一个自定义的metric汇报到监控平台上去,就可以把它存储起来了。
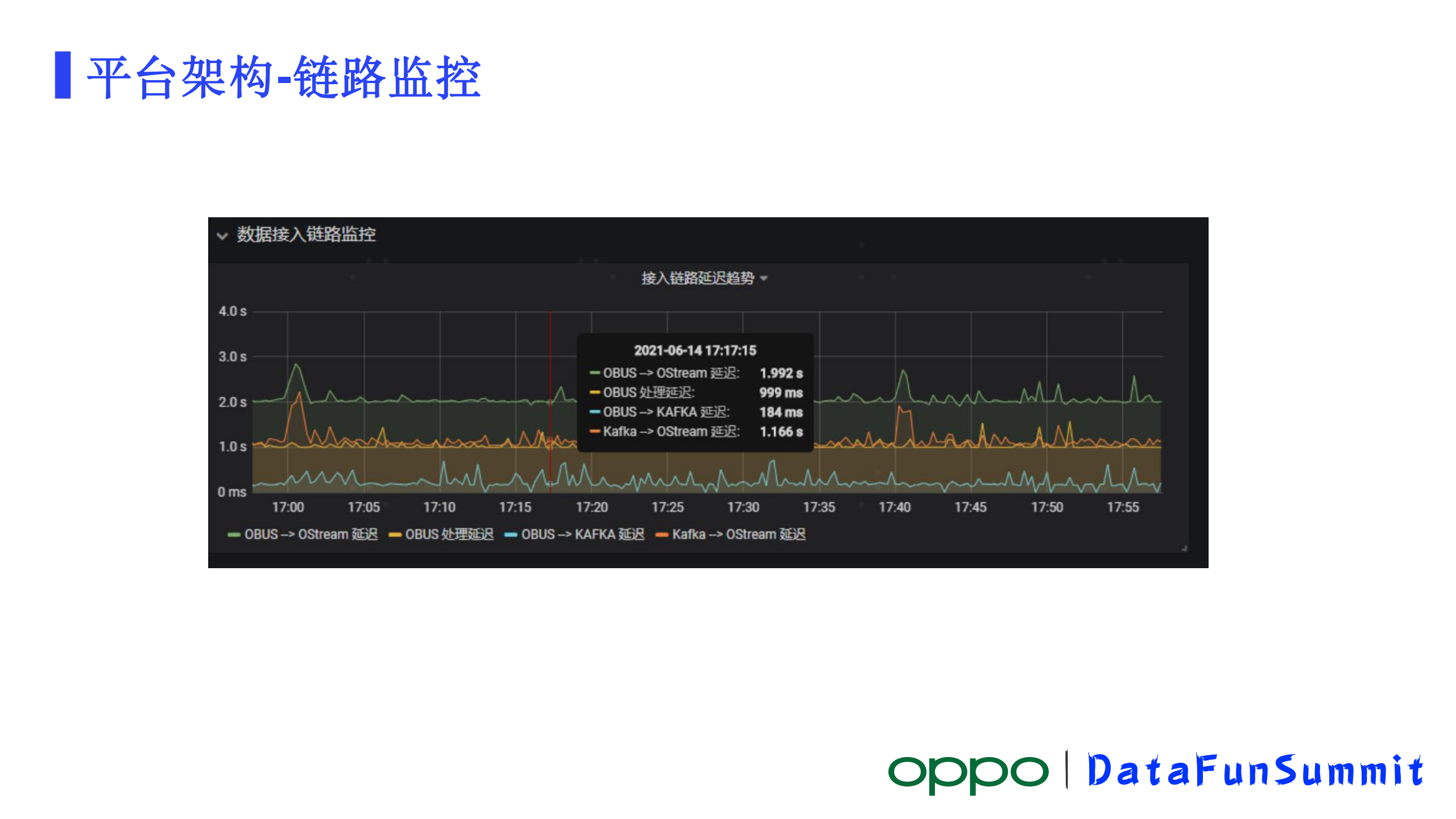
最后得出了一个链路监控的情况就是这样的,除了图表,我们可以对监控去配置一些告警的策略,哪些环节出现了延迟,我可以及时告警出来,这样方便我们去做问题的精准定位和快速恢复。
7、实时SLA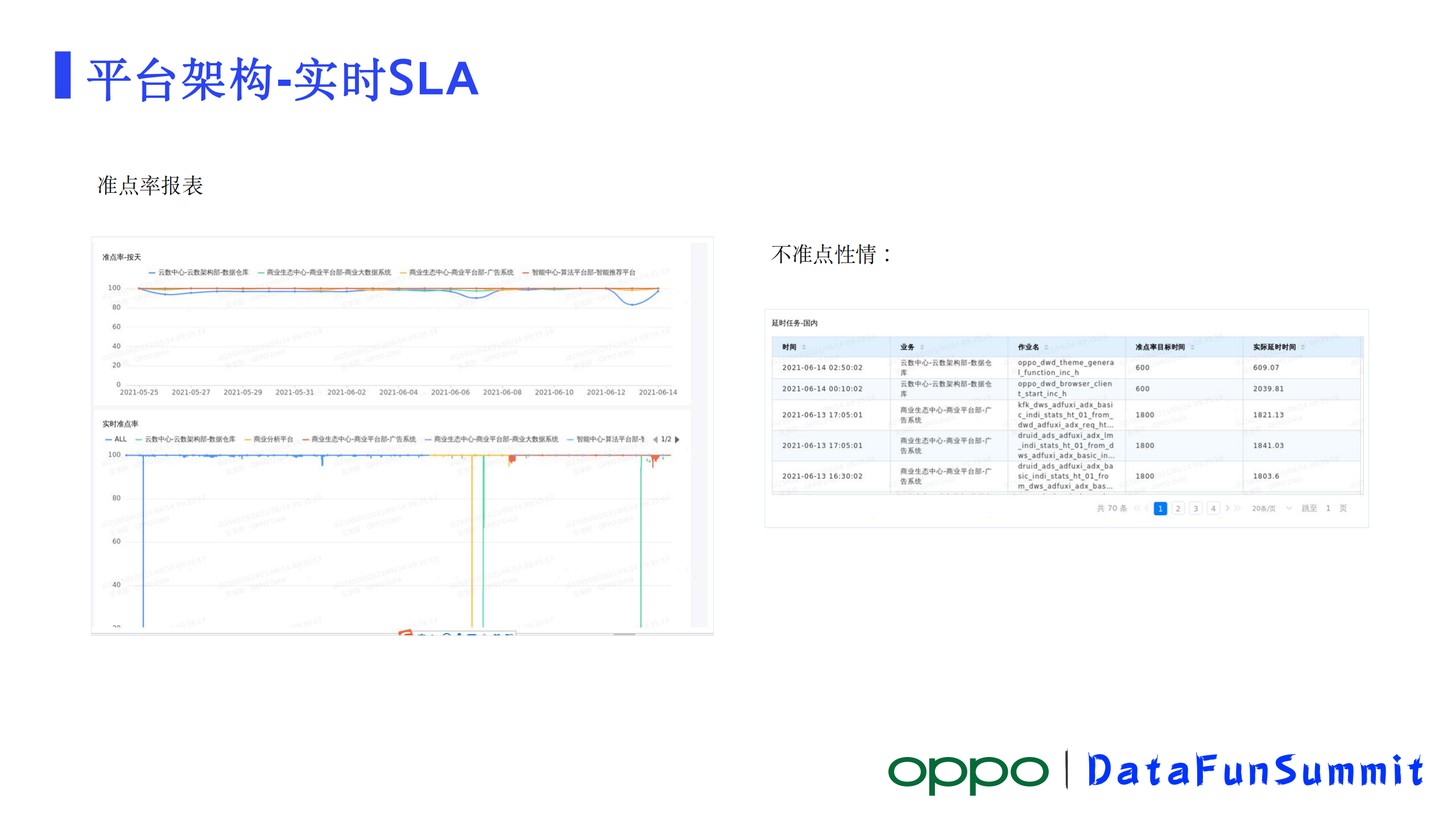
在链路监控基础上进一步做了一个实时作业SLA准点率的保障。
业务接入进来了,除了希望看到每个作业的运行情况,他也希望看到一个整体的运行报表,针对这个我们做了一个实时准点保障的报表,前期准备工作需要去采集业务对于不同作业的延迟的容忍度,把这个指标采集起来,再结合我们上边做的链路延迟监控采集到的延迟数据,我们就可以很简单得到作业在某个时间的准点情况,整体情况可以出一个报表。如果遇到准点率不是100%的时候还可以把不准点作业找出来,再结合作业诊断,甚至都可以很快得出这个作业到底是什么原因导致它不准点。
三、应用实践
1、实时数仓
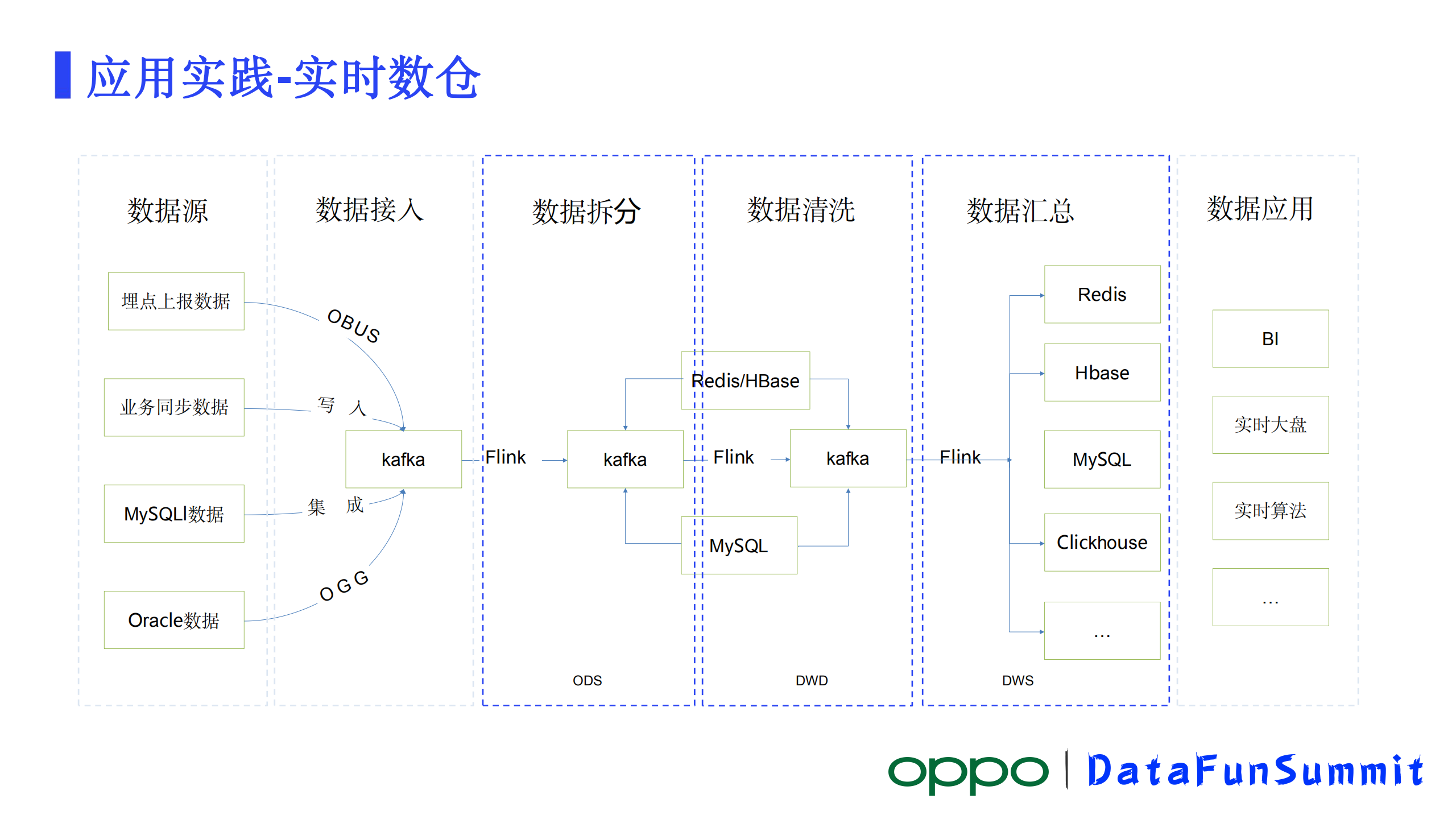
实时计算典型的应用场景就是实时数仓,实时数仓比较核心的逻辑就是数据拆分、数据清洗、数据汇总几个部分。数据源从应用端埋点、业务同步数据、MySQL数据、Oracle数据,数据写入到kafka,数仓团队通过实时平台写SQL接入Kafka的数据,对数据进行拆分等动作,得到了第一层的ODS数据,根据整个平台里面的表做一些关联、清洗得到DWD层数据。再往下对DWD数据做一些汇总、聚合操作,得到了业务真的想要的一些数据。
目前实时数仓在公司内部已经全面的推广出去了,几乎所有的业务接入数据都走的是实时数仓,很少有业务再去kafka接原始的接入数据。
2、实时大屏
在电商促销活动中实时大屏占了一个很重要的位置,比如在618、双十一这样的活动中零点刚过各大电商已经开始发战报了,为何能发这么快?很大程度上也是受益于实时计算强大的计算能力,在类似的活动中OPPO也做了自己的一个大屏,这里大屏其实都比较类似,一般计算的无非就是GMV、PV、UV,还有订单的成交量等等这样一些指标。
电商的核心数据一般都是写在MySQL这样的DB里的,怎样把数据导入到我们的一个计算平台里做计算是一个要解决的问题。
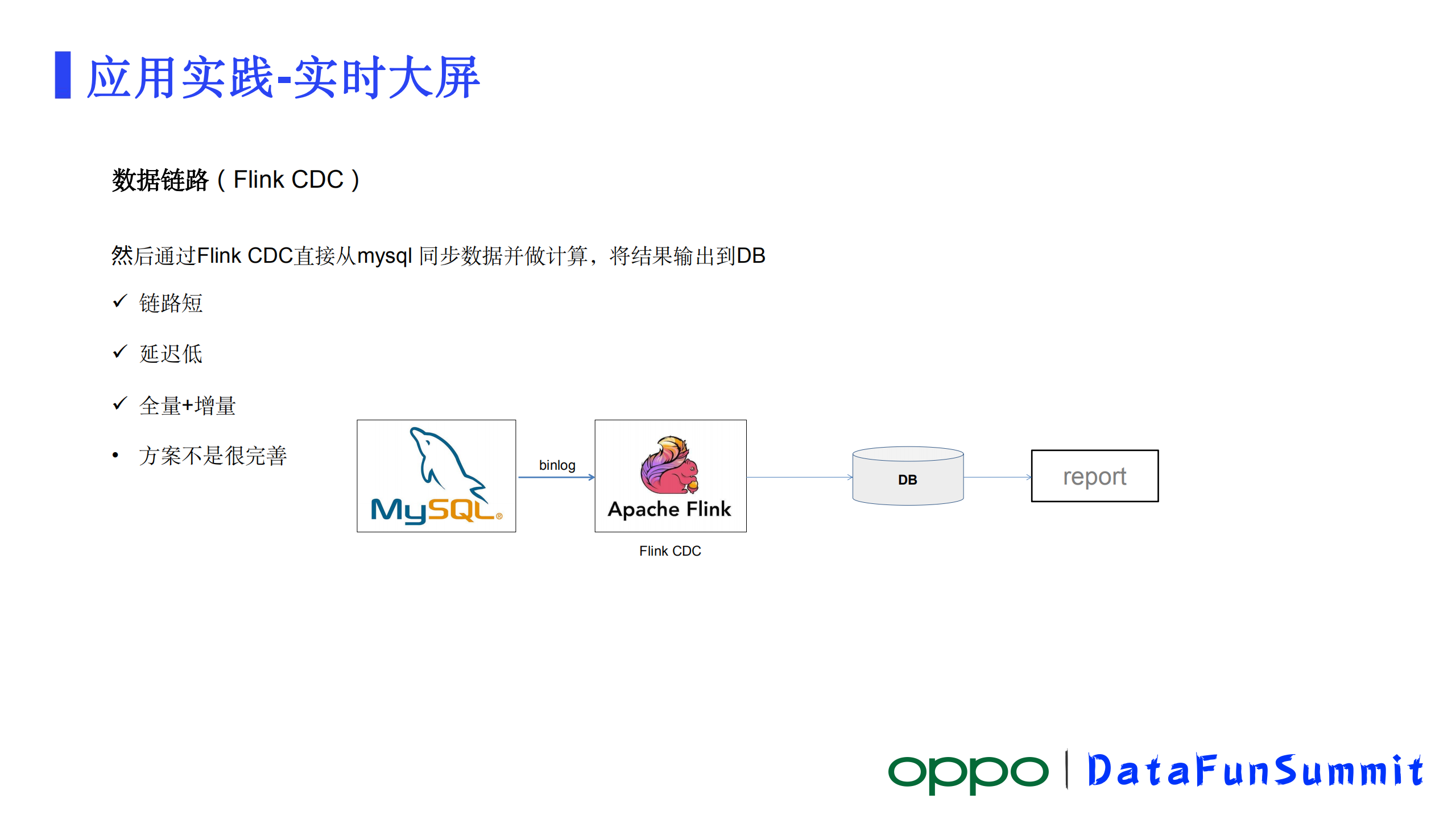
其中一个比较经典的链路,数据在MySQL,通过Canal这样的工具,把数据写到Kafka,Flink从Kafka拉取数据做计算,计算完结果输出到DB做报表。
这个链路好处是整个方案用到的组件如Canal、Kafka等都已经发展运行了很多年了,非常成熟。其次基于这些成熟的组件,一般公司都开发有相对完善的一些监控告警。另外,如果MySQL数据导出来了之后下游不止一种计算,那可以多次消费Kafka的消息进行计算,所以它可扩展性相对会更好一些。
但是它也有一些明显的缺点,我们可以看到这里一个数据至少要经过Canal、kafka才能计算到计算层。链路还是很长。越长的链路保障相对比较困难,要保障每一个节点都是正常的,但凡有一个点有问题,就出不来数据。另外就是这个链路主要是支持增量这种场景,在电商促销过程中主要也是增量计算所以没大问题。
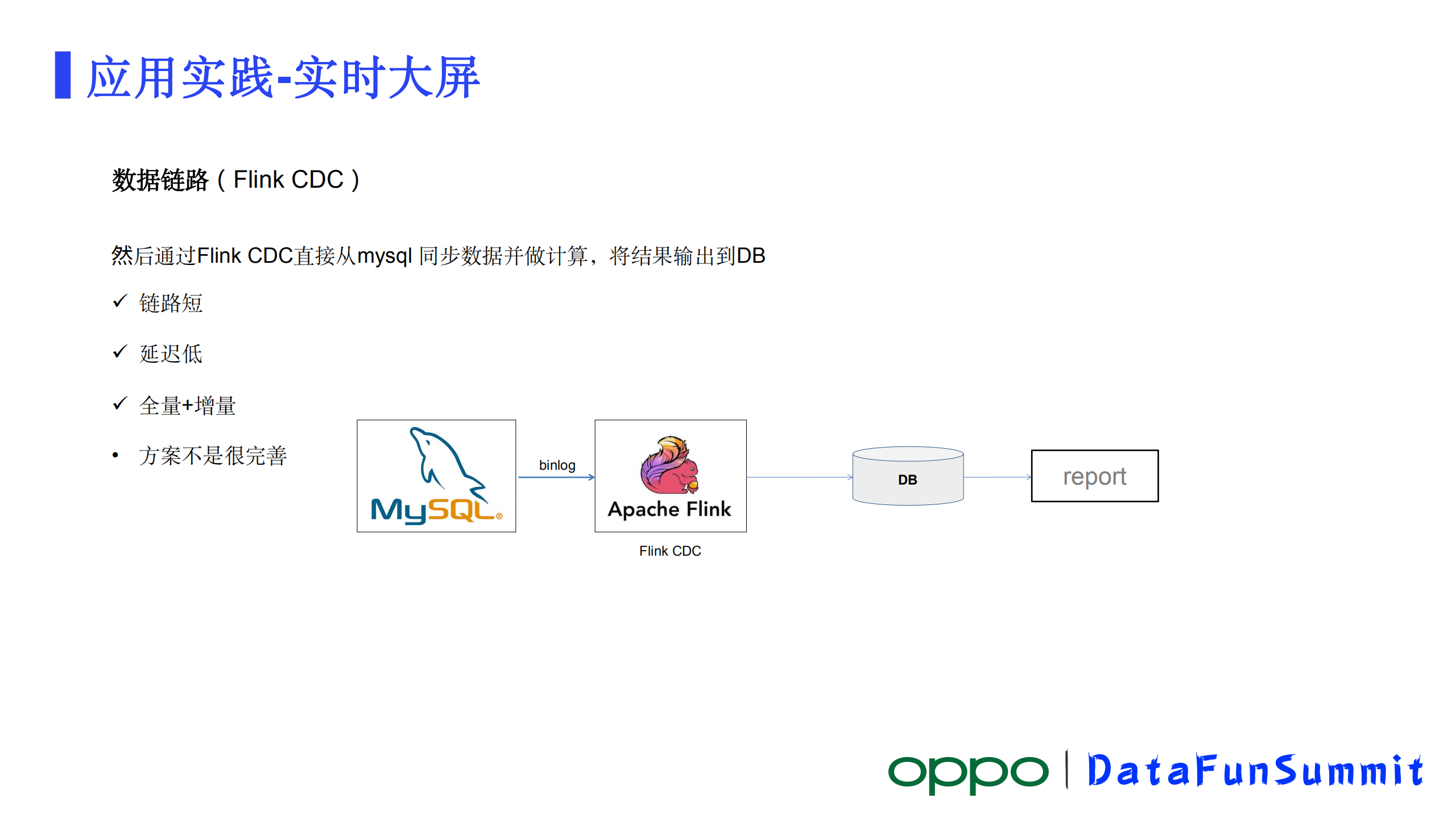
还有一种比较新的链路,就是Flink CDC。Flink CDC是去年社区才支持的能力,从图中可以看到这个链路就非常短了,Flink直接就可以抽取MySQL的Binlog,然后做解析做计算。它大的优点就是链路短、涉及的组件少,所以理论上稳定性会更高,数据的延迟会更低。这条链路既支持全面又支持增量。但有一个比较明显的缺憾就是它比较新,目前还没有构成一个相对完整的方案,比如我们要做一些复杂链路数据的聚合操作,就没那么简单了。
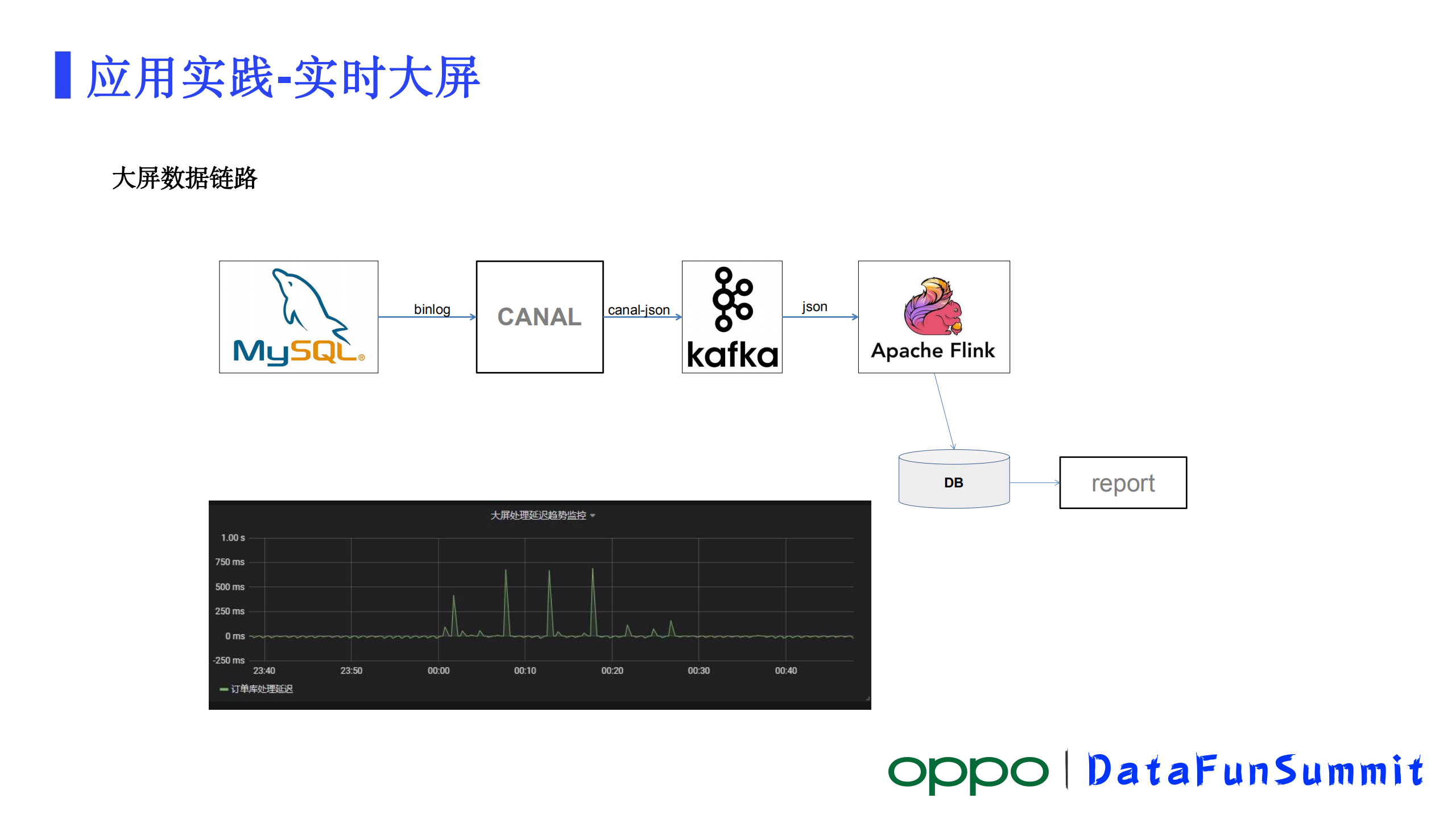
在做大屏之前我们对这两个链路也做了一些验证,最后选择了第一条经典的链路。主要是由于我们的数据量并不是很大,延迟各方面的问题都还能接受,还有就是它比较成熟,各个环节的衔接和监控都比较完善,实际运行下来效果也还是比较好的。
四、规划
OPPO实时计算平台后面的演进有两个方向,一个是仓湖一体建设,另一个是云原生的支持。
1、仓湖一体建设
从目前业界的一些实践经验来看,仓湖一体不仅能够节省大量存储资源,还能简化大数据体系的架构。上边我们也看到了在当期体系下建设数仓整个链条是很长的,中间要流过好几次Kafka和Flink,数据链路很长存储资源的浪费也比较严重。
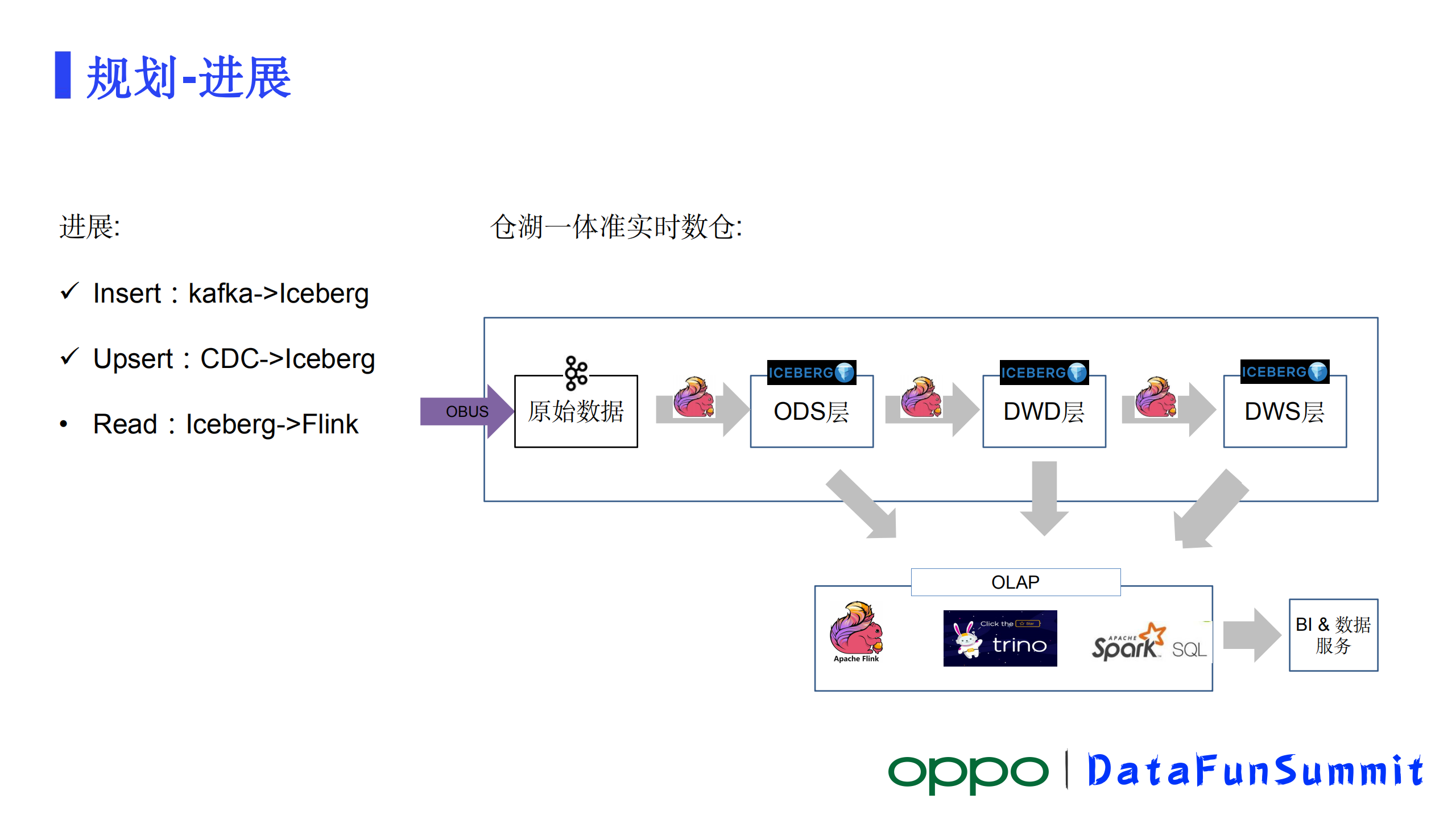
在仓湖一体建设中我们选择了Iceberg,其中典型应用场景就是准实时数仓,准实时数仓就不需要数据的转移,通过很短的链路就能提供现有数仓的能力。但是这里面受限于技术局限。它可能只能达到一个准实时的效果。目前从kafka到lceberg链路已经打通了,现在已经有部分数据通过这种方式入到了存储里去了。另外 CDC到lceberg链路也已经打通了,数据也都入到存储里了。在lceberg到Flink读取这块,现在还正在进行当中,这块做完之后,我们基本上就可以在这基础上构建我们的准实时数仓。
2、云原生另外一个发展方向是云原生的支持,实现弹性扩缩容,充分利用云上资源。目前计算资源主要还是Yarn来管理,接下来我们会支持K8s调度,公司内部有很多规模庞大的K8s集群,上边运行着很多的在线业务,到时候Flink的任务就可以和这些业务进行混合调度,让资源得到充分的利用。
>>>>Q&A
Q1:Kafka表字段元数据是怎么管理的?
A1:元数据管理分为两个版本架构:第一种方式是将数据写入MySQL表中进行独立管理,这种方式有一个弊端,就是实时元数据只能实时使用不能和离线结合起来;第二种方式是采用FlinkHive Catalog方式管理,现阶段元数据管理是两种方式相结合管理,原有的业务继续放在MySQL中管理,新业务使用HMS进行管理。
Q2:kafka表中增加一个新字段,需要做怎么操作?
A2:由于数据格式有多种,比如avro、json 格式,不同格式数据类型操作方式也不一样,如果是针对json格式处理方式在页面编辑表,然后在数据写入的时候新增相应的字段即可,json格式序列化或者反序列化需要用的时候就使用,不需要就不使用,也不会有影响。由于编辑了表,所以涉及到这个表的所有作业都需要重新发布才能生效。
Q3:Kafka join分库分表的MySQL贵公司是怎么做的?
A3:维表使用的是单表,很少有使用分库分表情况,要做的话是不是可以先把分库分表做一个union再去做维表的join。
Q4:K8s做云原生是怎么做的?
A4:K8s正在实施阶段,调研阶段发现一个问题,Yarn支持Per job模式提交JAR和SQL作业,但是K8s并不支持Perjob的方式方式提交SQL作业。所以我们会对K8s的Application模式加以改造,让其支持类似Yarn 的perjob 模式提交SQL作业。
作者丨Chad 来源丨公众号:DataFunTalk(ID:datafuntalk) dbaplus社群欢迎广大技术人员投稿,投稿邮箱:[email protected]
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK