

去中心化存储的那些事(上)
source link: https://learnblockchain.cn/article/3610
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

介绍了ipfs和filecoin各自的工作原理以及解决的问题。ipfs解决了去中心化存储的分发问题,filecoin解决了去中心化存储的存储问题。两者并非竞争关系而是互补关系,要进行结合使用。
为什么需要分布式存储
中心化存储有着内容的访问权利过于集中,依赖中心化服务,中心化服务集群可能故障,导致不可用,重复下载内容多,速度较慢,文件存储时间短等问题,我们知道区块链是去中心化的,但以太坊等主流区块链只能在链上存储较小数据,所以对数据量较大的存储无能为力,所以去中心存储需要解决方案。
我们将介绍去中心化相关的3种技术ipfs,filecoin,arweave。本文先介绍pfs和filecoin,arweave将在下篇文章中介绍。
IPFS简介
ipfs有着多重含义,既是文件系统,也是一种传输协议。本文将重点解释器作为传输协议的部分,可以理解其对比对象为http协议。
ipfs可以实现数据内容从多个分布式节点获取,将大的内容切块,使用内容寻址减少重复下载。
我们可以看看获取一份内容,由http变为ipfs的过程有何不同(不包含路由阶段)。
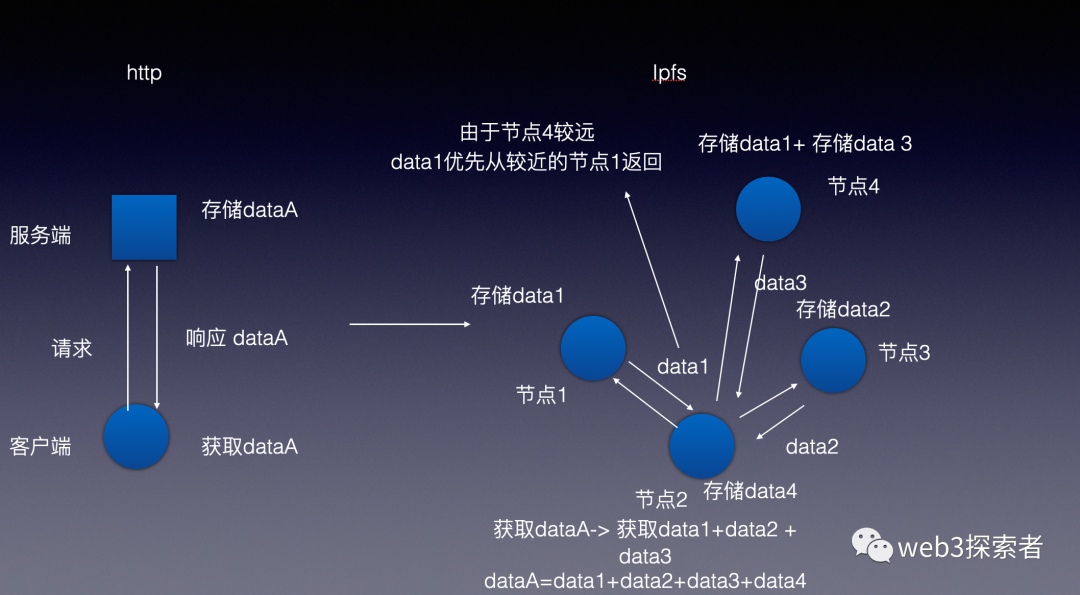
如上图所示,在传统http中我们向单点服务器请求数据dataA,中心化服务器需要完整返回dataA,而在ipfs中会将dataA进行拆分,拆分成几个较小数据集然后向不同节点(就近原则)分别请求这些data,如果节点已有的数据则不需要请求。
上面我们描述ipfs获取数据过程中有2个问题
1.ipfs为什么能够根据内容本身去寻找数据提供者(在http可不是这样, 是根据位置标识符来寻找的)。
2.客户端(需要获取数据的节点) 是如何找到拥有对应数据的节点。
内容寻址简介
内容寻址即根据内容去寻找它所处的位置,我们平时使用的http在浏览器中输入url都属于通过位置去找内容。
通过内容寻址有什么好处呢?当我们访问网络上资源时,如果使用内容寻址这一资源不会发生变化,如果通过地址寻找内容时,可能会出现url未发生变化但资源已经变成另外1个。这也是为什么目前较火的nft很多使用ipfs存储图片信息,如果存储在http服务器中很可能一张高价nft图片过几天就变成另外1张廉价图片。注意:并不意味着存储在ipfs就不会发生更换图片的事件,nft协议有提供更换资源地址接口,但调用合约是链上操作会留下记录。
内容寻址的实现
在ipfs中我们针对每块内容进行hash获得1个cid,这个cid就可以表示这一内容,如果内容发生了变化cid也一定会变化。
那么ipfs中是不是内容每更新一次我们就需要重新换个地址寻找呢,这部分内容可以查阅ipns,本文不详细展开。
在ipfs中针对文件夹这种形式还做了特殊的支持,我们先看看我们常见的文件夹格式是怎么样的。
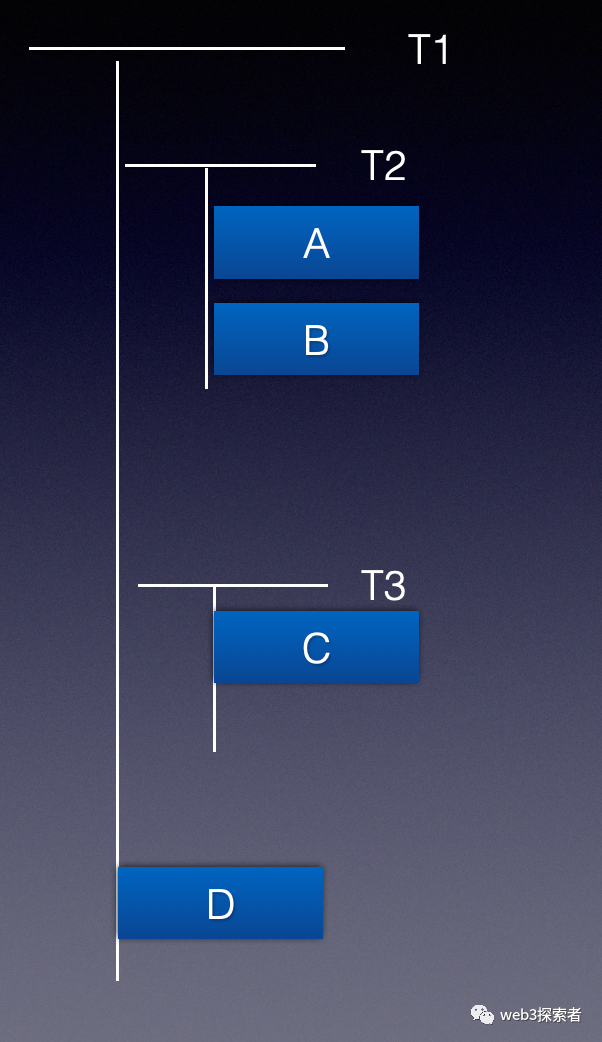
如上图所示,根目录T1 中包含2个文件夹T2 T3和1个文件D, T2文件夹中包含2个文件A B T3文件夹中包含 文件C。
ipfs使用merkleDAG来组织文件夹形式, merkle tree的结构之前的文章以太坊数据结构已经详细介绍过,merkleDAG并无太大区别,区别只在于非叶子节点可以存储数据。我们看看上面的文件夹是如何组成merkleDAG的。
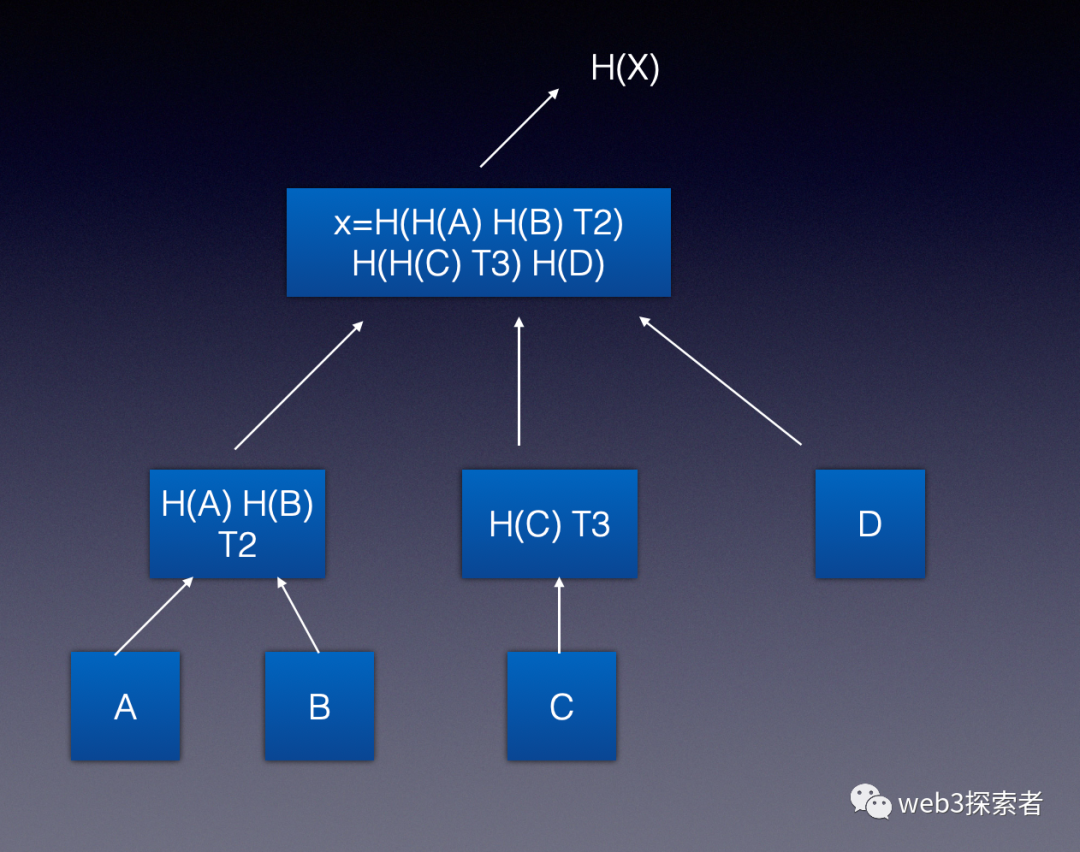
这样如果目录中的任何1个文件变化,都会影响其父节点hash值的变化从而影响整个目录的hash值。
上面我们回答了第1个问题,为什么ipfs能够进行内容寻址,接下来我们再看看第2个问题如何找到对应数据节点的,也就是如何进行寻址。
DHT(分布式哈希表)
DHT简介
我们直观去想如何在得知内容唯一标识去寻找存储数据的节点。
应该是有1个路由表去存储以内容标识为key,节点信息为value。那这个路由存在哪里呢?最简单的肯定就是存在某个服务器上,也的确有一些p2p是这样的设计,但这与去中心化的模式又有所相悖。也会带来中心化服务器的宕机风险,和访问权限过于集中的问题。
ipfs使用了DHT的方案,目标是希望将集中式地维护hash表变为由网络中的节点各存储hash表的一部分,这样可以解决中心化的风险。
DHT将key的集合拆分成多个子集,每个节点按照一定规则存储一部分子集,中心化的存储路由表到DHT的变化如下图所示。
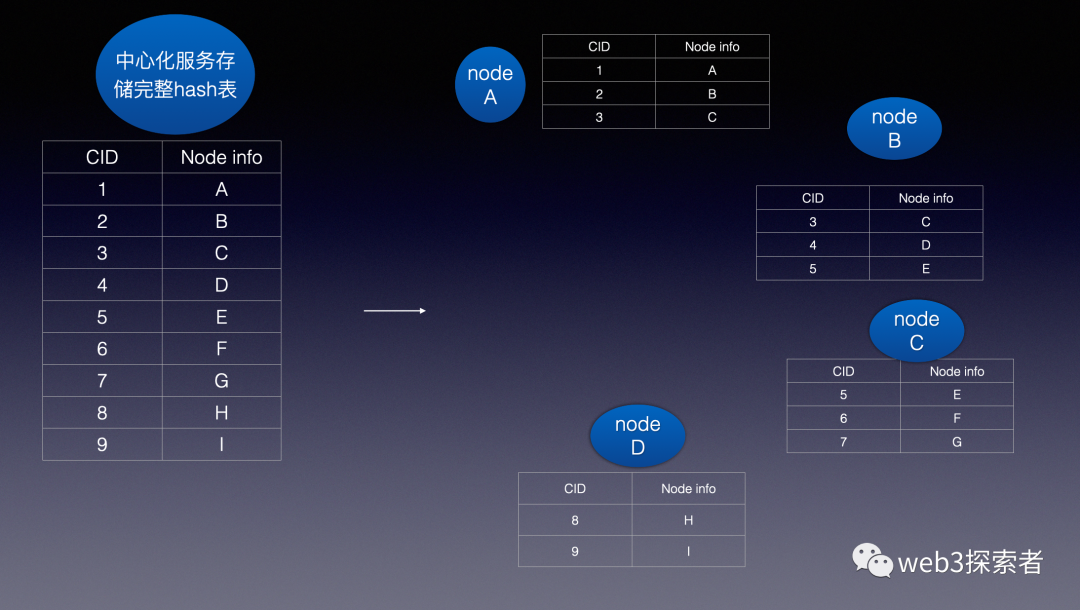
DHT实现
DHT的解决方案会有1个非常大的挑战,映射CID到存储节点的路由表是分布在网络中的各个子节点的,那么当需要获取某个CID内容的时候第一步如何进行呢?总不能无规律遍历网络中所有节点并遍历其中存储的哈希表,这样效率会非常低。
在ipfs中为每个节点引入了PeerID,注意这个PeerID和cid位数一致。这样每个PeerID就会存储其对应一组cid和存储着其每个数据块节点的映射表。也就是说通过cid就可以计算出存储其路由表的PeerID。
这就为什么从ipfs网络中获取数据需要进行2次查询,第1次的寻找路由表所在节点 第2次寻找存储数据块的节点。
ipfs中获取数据块的完整过程如下
1.将待获取的数据块cid 简单计算得到其存储其哈希表的节点PeerID1
2.在网络中查找PeerID1
3.在PeerID1的哈希表中获取存储cid对应数据块的节点PeerID2
4.在网络中查找PeerID2
5.在PeerID2中找到cid对应的数据块,使用数据交换协议进行下载
此外ipfs在访问数据过程中使用距离(路由跳数)来选择较近节点优先访问较近的节点,具体实现不再赘述,有兴趣可以自行查阅。
上面描述的ipfs看上去好处多多,但实际过程中ipfs遇到一个问题,ipfs只解决了去中心化的高效分发的问题,但没有解决存储的问题。
ipfs中存储不能依赖网络中的其他人,提供的是"我需要的数据你正好拥有那么我来你这里拿”的协议,协议并未解决将数据持久化存储。所以内容要么本地存储,要么存储在ipfs固定存储服务中。
那么去中心化存储如何解决呢?接下来我们看看filecoin的解决之道。
filecoin
filecoin简介
上面说到ipfs只解决了去中心化高效分发,但未解决去中心化存储,而filecoin专为去中心化存储而设计。
filecoin是一种区块链的设计,具备区块链的大部分特征。所以分析filecoin可以参考之前的以太坊技术相关的几篇文章。
如下图所示,filecoin通过自己的代币FIL和存储提供者提供存储空间进行交易记录到链上,从而形成了一个自由的存储市场。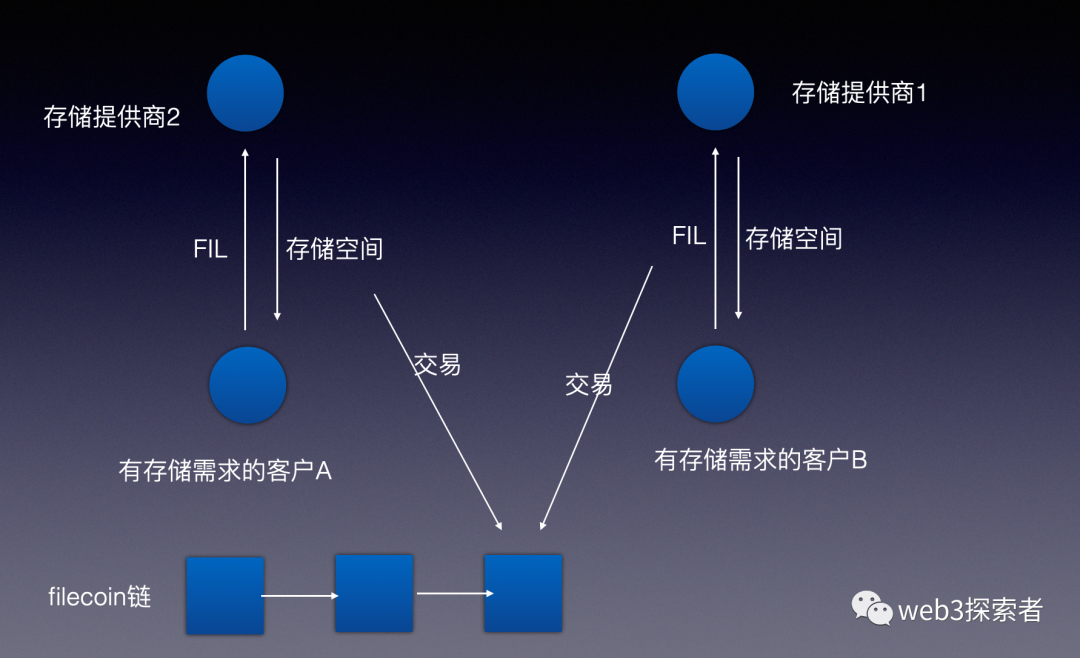
filecoin核心难点是数据是在链下存储的,而链下操作是无记录不可追踪的,那么如何向链上证明的确存储了客户端数据呢?
存储提供商将存储的数据进行编码生成数据副本,然后将数据副本的merkle tree的根hash连同自己的身份标识和存储时间进行hash,获得自己存储了这个数据的证明。这个过程称为密封,证明经过压缩后上传到链上。
使用复制证明可以验证存储提供商上链前的确存储了数据,但因为存储是一个持续的过程,如果存储提供商在证明提交上链后删除本地存储的数据怎么办呢?filecoin使用时空证明来解决这一问题。
filecoin在存储期限内,会向存储提供商提出挑战,进行随机访问,存储提供商需要证明自己知道这些随机访问的数据。如何证明呢?这里又用到我们经常提到的merkle树,刚刚论述复制证明时将数据进行编码变成一棵merkle树,给定随机访问的节点数据,如果可以给到能够组成merkle树相同根节点的证明即可。
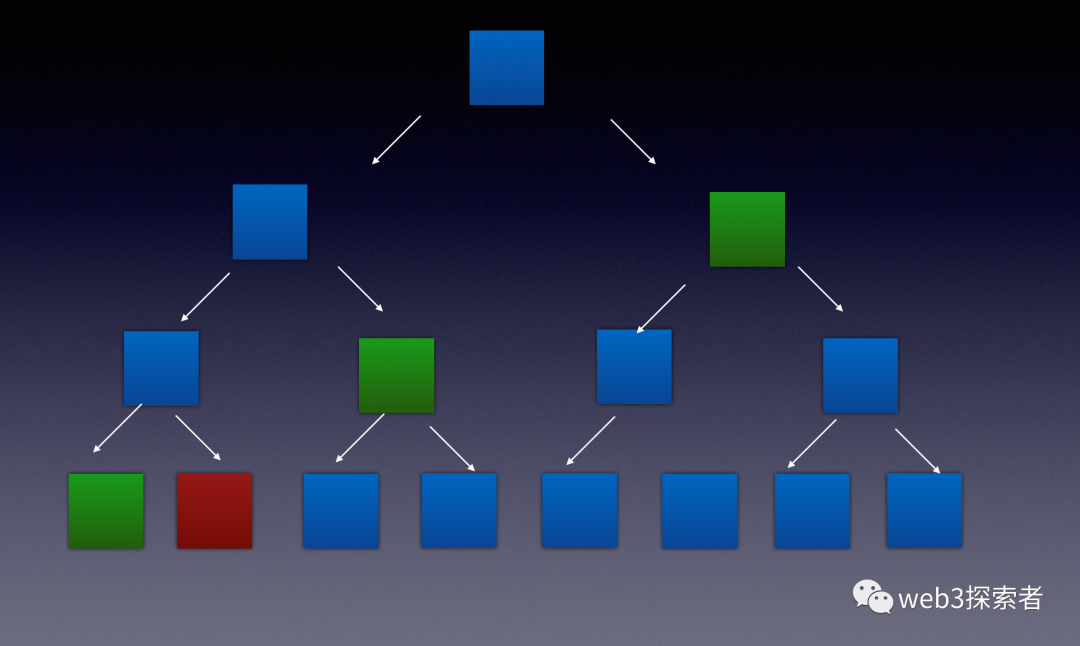
如上图所示,随机访问红色节点,需要给出绿色节点的证明即可。
同时还需要给出根节点的证明,因为链式并不直接存储根节点,链上验证根节点正确,并且绿色节点和随机访问的节点可以组成给出的根节点则证明成功。
在filecoin中存储提供商需要提供一定的质押,如果时空证明失败,质押将会被扣除。
前面一篇文章以太坊共识机制介绍过,分布式系统是需要共识机制的,那么filecoin的共识机制是什么呢?
filecoin的共识机制称为EC共识和以太坊切换成pos后的共识机制类似,都是选举节点生成区块,只不过以太坊中的权益体现在质押的ETH,而filecoin中的权益体现在提供的存储,提供的存储越多被选中生成区块的概率也就越大。
filecoin使用复制证明和时空证明达到链下存储数据的目标,为区块链中存储较大数据提供了一种思路。
filecoin和ipfs
首先 filecoin和ipfs不是竞争关系,而是互补关系。如上文所述,ipfs有着优秀的传输分发机制,但并没有解决存储的问题,filecoin本就为存储而生,希望能够高效利用其大量空置的存储并形成全新的存储市场。
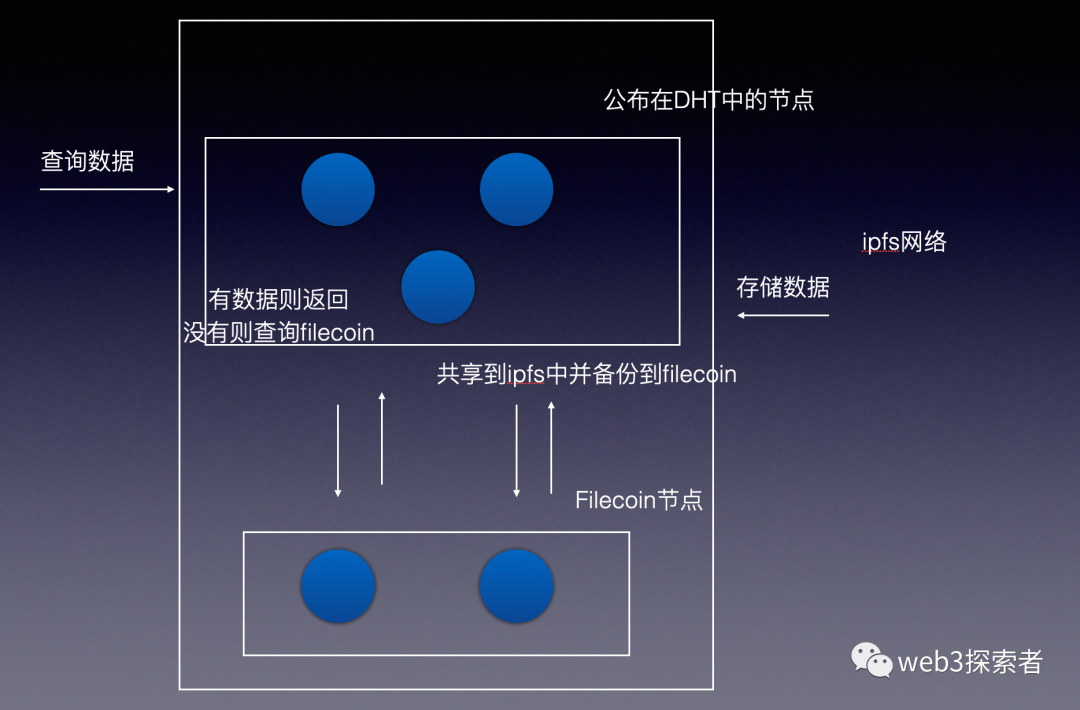
filecoin也是基于ipfs架构,节点类型也都属于ipfs节点,只是在构建ipfs DHC的时候filecoin不参与,在filecoin中寻找数据,filecoin提供了检索交易的方式但比较麻烦。所以很多架构都是二者结合使用,将数据存在ipfs中方便分发,同时也向filecoin存储一份作为冗余备份。
如下图所示,存储数据时先到ipfs查询,找到则直接返回,没有找到则在filecoin中进行检索交易。存储数据时共享数据到ipfs网络中,并进行存储交易备份到filecoin中。
filecoin虽然提供了分布式存储,但本身并未实现存储冗余,让我们试想一下,如果你将数据存储到filecoin中的某个存储提供商中后,如果这个存储提供商机器故障存储丢失了,那么除了扣除这个存储提供商质押之外并无其他办法。而arweave从机制上避免了此类问题,实现了永久存储,下一篇文章我们将介绍arweave相关。
本文从中心化存储的缺点开始论述,介绍了ipfs和filecoin各自的工作原理以及解决的问题。ipfs解决了去中心化存储的分发问题,filecoin解决了去中心化存储的存储问题。两者并非竞争关系而是互补关系,要进行结合使用。最后提到filecoin是去中心化存储方式,但未从技术方案上避免解决存储丢失的问题。
本文参与登链社区写作激励计划 ,好文好收益,欢迎正在阅读的你也加入。
- 发表于 5小时前
- 阅读 ( 27 )
- 学分 ( 0 )
- 分类:IPFS
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK