

Gcc编译时,链接器安排的【虚拟地址】是如何计算出来的?
source link: https://os.51cto.com/article/702426.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

昨天下午,旁边的同事在学习Linux系统中的虚拟地址映射(经典书籍《程序员的自我修养-链接、装载与库》),在看到6.4章节的时候,对于一个可执行的ELF文件中,虚拟地址的值百思不得其解!
例如下面这段C代码:
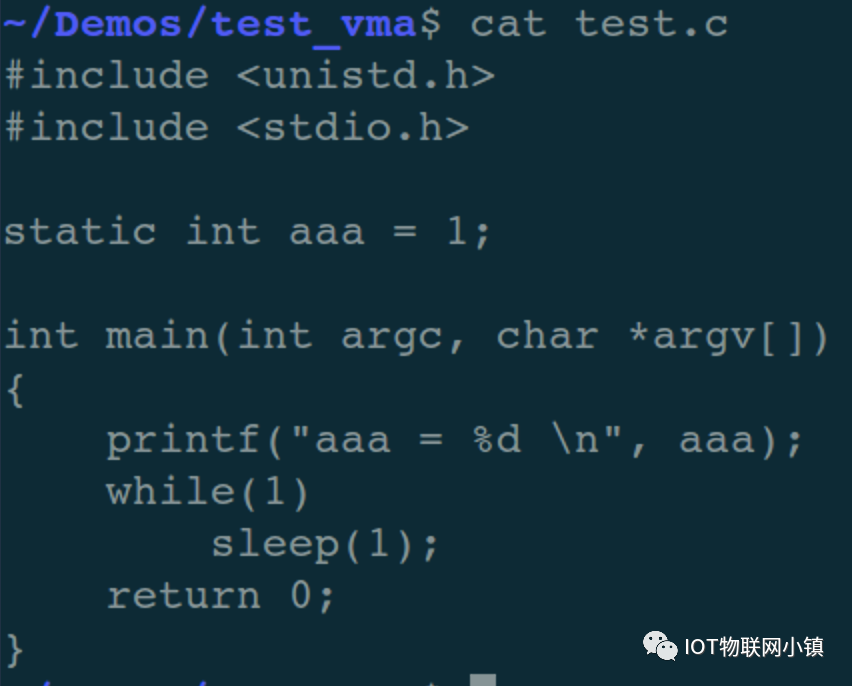
首先编译出32位的可执行程序(为了避开一些与主题无关的干扰因素,采用了静态链接):
gcc -m32 -static test.c -o test
编译得到ELF格式的可执行文件:test。
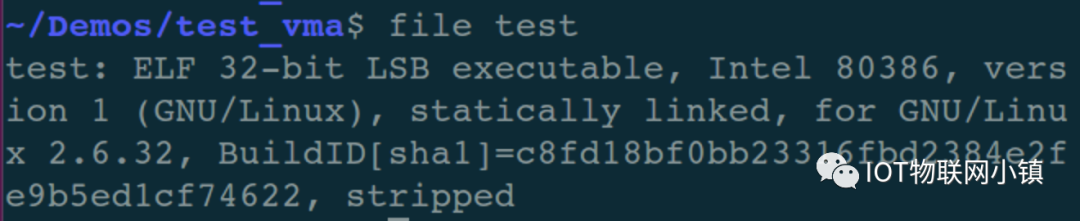
这个时候,使用readelf工具来查看这个可执行文件中的段信息(segment):
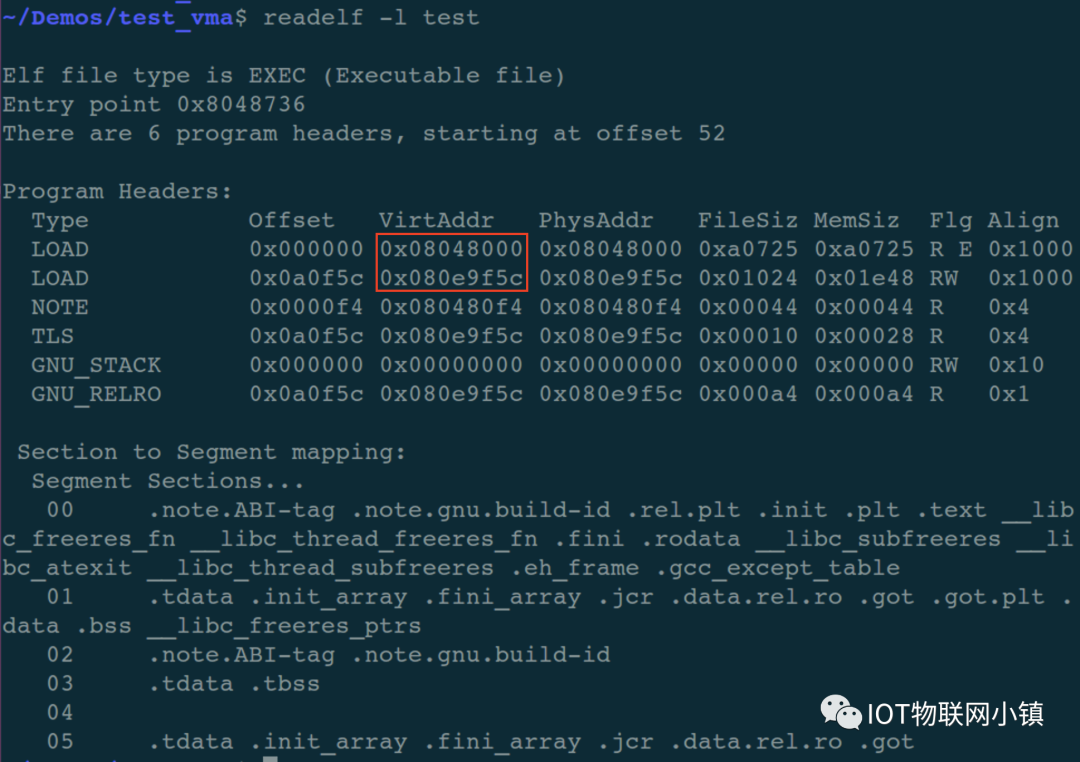
上图中的红色矩形框中,第二个段的地址为什么是0x080e_9f5c?
这篇文章主要根据书中的解释,来具体的分析这个值的来龙去脉。
ELF 文件格式
在Linux系统中,有4种类型的文件都是ELF格式,包括:目标文件,可执行文件,动态链接库文件、核心转储文件。
如果想系统掌握Linux系统中的底层知识,研究ELF的格式是避免不了的事情。
这里就不再赘述了,只要记住2点:
从编译器的角度看,ELF 文件是由很多的节(Section)组成的;
从程序加载器的角度看,ELF 文件是又很多的段(Section)组成的;
其实它俩没有本质区别,只不过是链接器在链接阶段,把不同目标文件中相同的section组织在一起,形成一个 segment。
对于刚才编译出的test可执行文件,其加载视图如下:
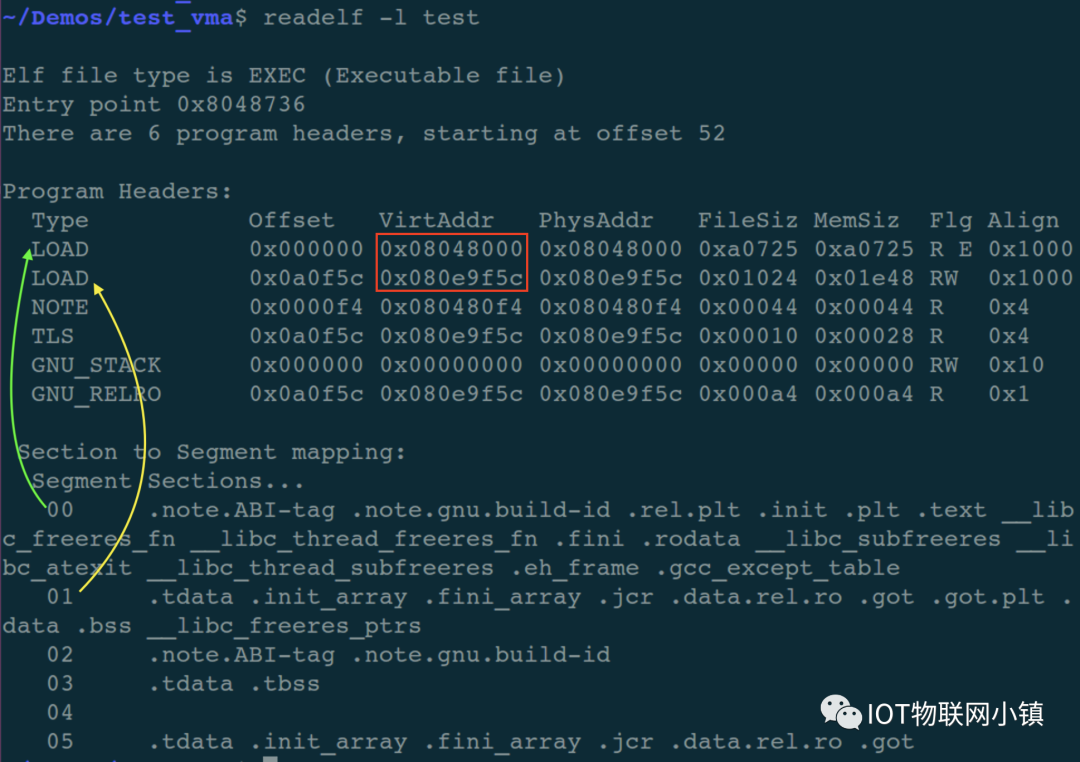
可以看到该文件一共有5个段(segment),前2个需要LOAD到内存的段,它们属性分别是:读、执行(R E) 和 读、写(RW),它们分别是代码段和数据段。
绿色的箭头反映出:代码段中包含了很多的 section;黄色的箭头反映出数据段也包含了很多的 section。
地址转换和内存映射
从地址转换的角度来看:
Linux 系统中CPU中使用的都是虚拟地址,该虚拟地址在寻址的时候,需要经过MMU地址转换,得到实际的物理地址,然后才能在物理内存中读取指令,或者读取、写入数据。
在现代操作系统中,MMU地址转换单元基本上都是通过页表来进行地址转换的:
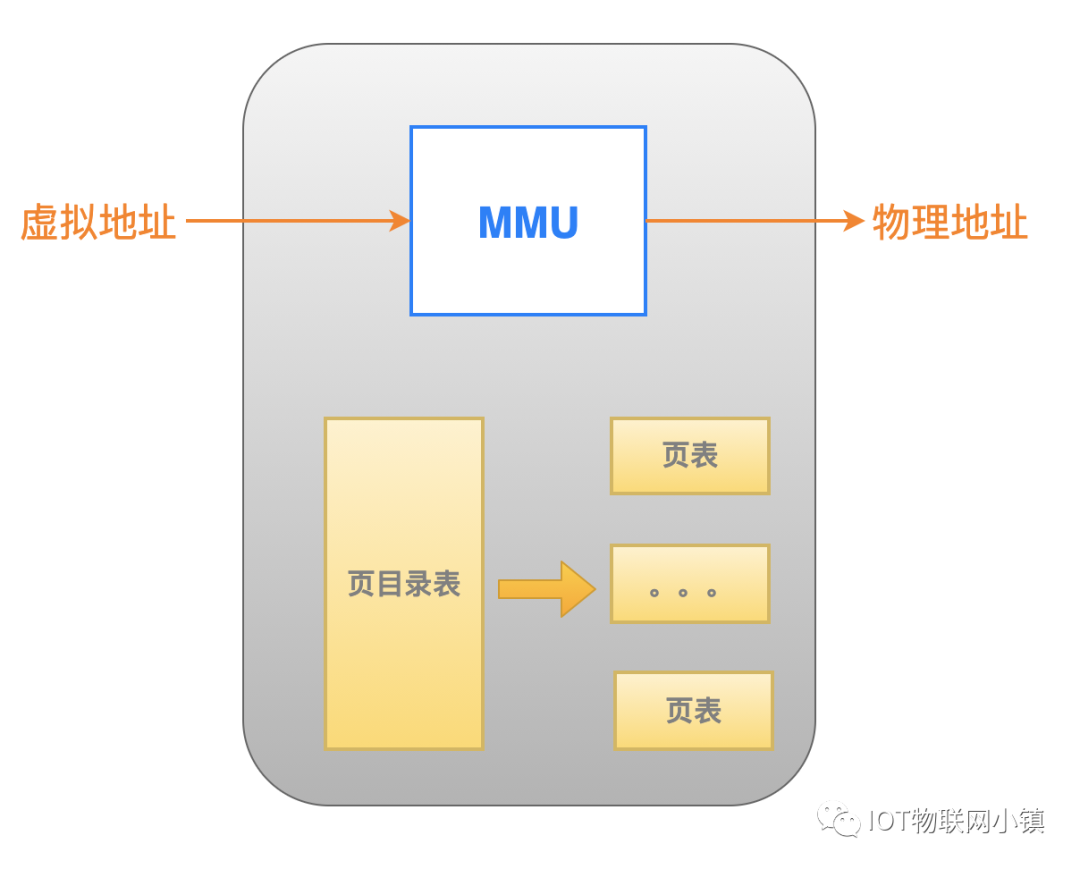
当然了,有些系统是两级转换(页目录、页表),有些系统是三级或者四级页表。
从内存映射的角度来看:
操作系统在把一个可执行程序加载到系统中时,把ELF文件中每个段的内容读取到物理内存中,然后把这个物理内存映射到该段对应的虚拟地址上(VirtAddr)。
假设一个可执行程序中的代码段长度是1.2K字节, 数据段长度是1.3K字节。
操作系统在把它俩读取到内存中时,需要 2 个物理内存页来分别存储它们(每 1 个物理页的长度是4K):
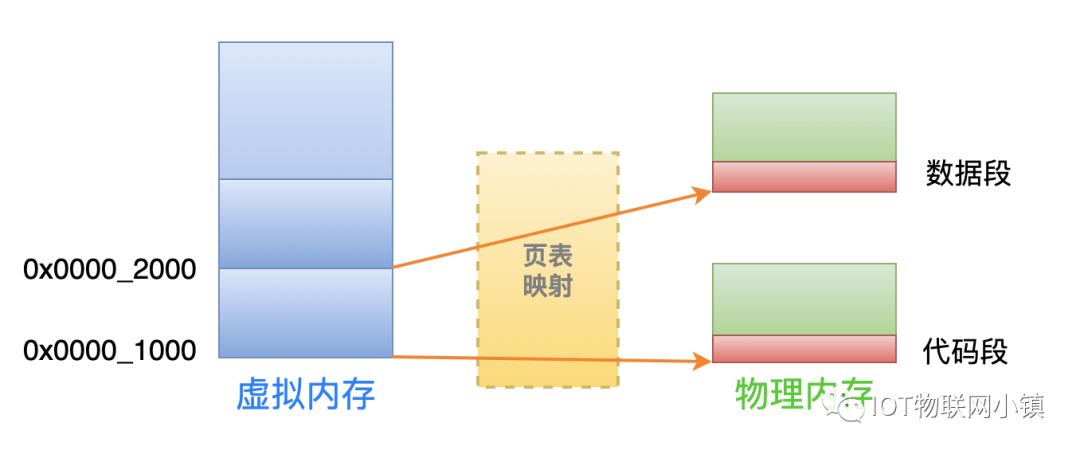
虽然每一个物理内存页的大小是 4K,但是代码段和数据段实际上只使用了每个页面刚开始的一段空间。
当CPU中需要读取物理内存上代码段中的指令时,使用的虚拟地址是 0x0000_1000 ~ 0x0000_1000 +1.2K这个区间的地址,MMU单元经过页表转换之后,就会得到这个存放着代码段的物理页的物理地址。
数据段的寻址方式也是如此:当CPU中需要读写物理内存上数据段中的数据时,使用的虚拟地址是 0x0000_2000 ~ 0x0000_2000 + 1.3K这个区间的地址。
MMU单元经过页表转换之后,就会得到存放着数据段的物理页的物理地址。
可以看出在这样的安排下,每一个段的虚拟地址,都是按照4K(0x1000)对齐的。
如果操作系统都是这样简单映射的话,那么事情就简单多了。
如果按照这样的安排,来分析一下文章开头的 test 可执行程序中的虚拟地址安排:
代码段安排的开始虚拟地址是 0x0804_8000,这是 4K 对齐的;
代码段的结束虚拟地址就应该是 0x0804_8000 + 0xa0725 = 0x080e_8725;
那么数据段的开始地址就可以安排在 0x080e_8725 之后的下一个 4K 对齐的边界地址,即:0x080e_9000。
但是这样的地址安排,严重浪费了物理内存空间!
1.2K 字节的代码段加上1.3K字节的数据段,本来只需要1个物理页就够了(4KB),但是这里却消耗掉2个物理页(8KB)。
为了减少物理内存的浪费,Linux操作系统就采用了一些巧妙的办法来减少物理内存的浪费,那就是:把文件中接壤部分的代码段和数据段,读取到同一个物理内存页中,然后在虚拟地址空间中映射两次,详述如下。
Linux 中的内存重复映射
先来看一下test文件的结构:
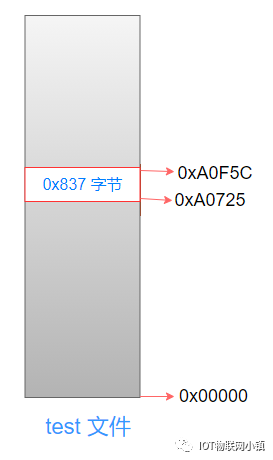
代码段在文件中的开始位置是:0x00000,长度是0xa0725。
数据段的开始位置是:0xa0f5c,长度是0x1024。
可以看到它俩之间有一个空白区间,长度是: 0xa0f5c - 0xa0725 = 0x837(十进制:2103字节)。
由于操作系统在把test文件读取到物理内存的时候,从文件开始代码段的0x00000地址开始读取,按照4KB为一个单位存放到一个物理页中。
文件中代码段的 0x00000 ~ 0x00FFF 读取到一个物理页中;
文件中代码段的 0x01000 ~ 0x01FFF 读取到物理页中;
下面的内容都是如此分割、复制;
也就是说:相当于把test文件从开始位置,按照4KB为一个单位进行"切割",然后复制到不同的物理内存页中,如下所示:
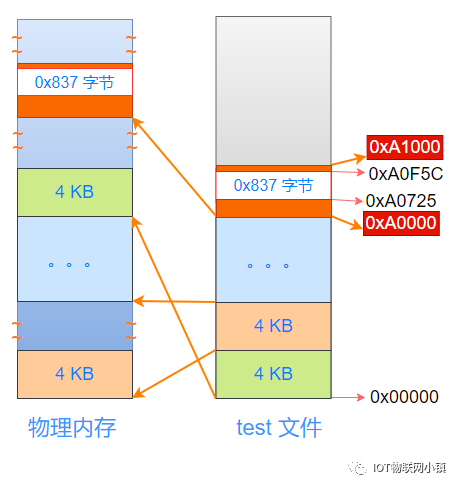
注意:这些物理页的地址很可能是不连续的。
这里有意思的是:代码段与数据段接壤的这个4KB的空间,它的开始地址是0xA0000,结束地址是0xA0FFF,被复制到物理内存中最上面的橙色物理页中。
再来看一下代码段的虚拟地址:在执行gcc指令的的时候,链接器把代码段的虚拟地址安排在0x0804_8000处:
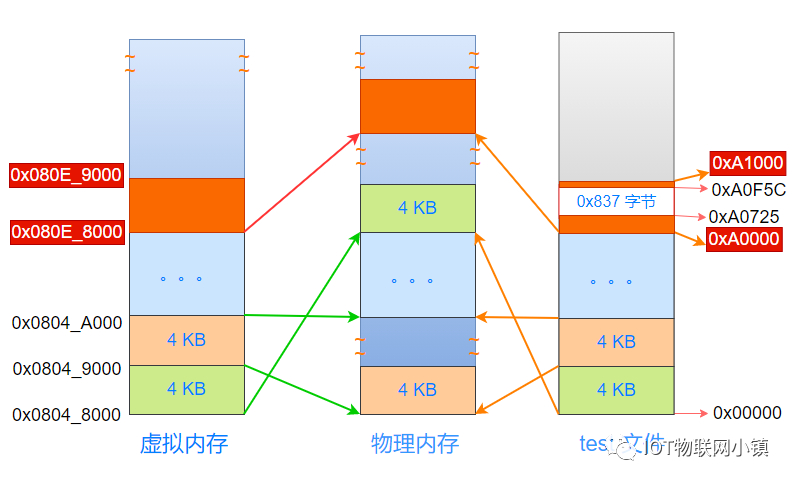
也就是说:当CPU中(或者说程序代码中),使用0x0804_8000 ~ 0x0804_7FFF 这个区间的地址时,经过地址映射,就会找到物理内存中浅绿色的物理页,而这个物理页也对应着test可执行文件开始的第一个4KB的空间。
而且,从虚拟地址的角度看,它的地址都是连续的,对应着test文件中连续的内容,这也是虚拟地址映射的本质。
把代码段的开始位置安排在 0x0804_8000 地址,这是 Linux 操作系统确定的。
那么考虑一下:代码段的最后一部分指令相应的4K页面,其对应的开始虚拟地址是多少呢?
上图中已经标记出来了,就是虚拟地址中橙色部分:0x080e_8000,计算如下:
通过代码段的开始地址0x0804_8000,再加上代码段在内存中的长度0xa0725,结果就是 0x080e_8725。
按照4K (0x1000)对齐之后,最后一个虚拟页就应该是0x080e_8000。
也就是说:虚拟地址中0x080e_8000 ~ 0x080e_8724 这个区间就对应着test文件中代码段的最后一部分指令(0x725个字节)。
此外,上图中最右侧:test文件结构中的2个红色地址:0xA0000, 0xA1000,是如何计算得到的?
代码段的长度是 0xA0725,按照4K为一个单位来进行分割,也就是把0xA0725对0x1000进行整除,就得到这个4KB的开始地址0xA0000。
同理,下一个4KB的开始地址就是0xA1000。
把文件中这部分4K的数据(包括:一部分代码段内容 + 0x837 字节空洞 + 一部分数据段内容),复制到上图中物理内存中最上面的橙色物理页中。
又因为虚拟地址空间中,0x080E_8000开始的这个4KB空间映射到这个物理页中,所以:在这个虚拟地址空间中,也有一个0x837字节的空洞,如下所示:
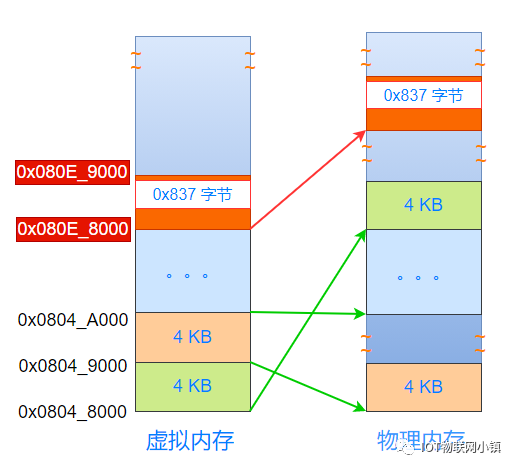
空洞的下方,是代码段的指令;空洞的上方,是数据段的数据。
现在,这个物理页中即存放了代码,又存放了数据。
那么CPU中在查找部分的代码和数据的时候,必须都能够找得到才行!
对于代码段比较好理解:从这个物理页开始的前0x725个字节是有效的,从虚拟地址的角度看,就是从0x080e_8000开始的前0x725个字节是有效的。
因此,对于这部分代码的寻址,使用的虚拟地址处于0x080e_8000 ~ 0x080e_8724这个区间中。
那么数据段呢?
重点来了:Linux系统把虚拟地址空间 0x080e_9000 ~ 0x080e_9FFF 也映射到图中物理内存中最上面的橙色物理页上!
如下所示:
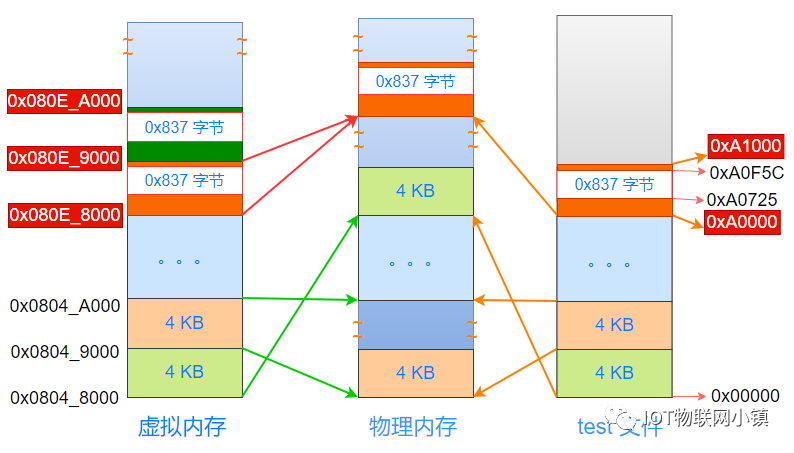
因为物理页中,是从0x837个字节空洞的上面开始,才是真正的数据段内容,那么相应的: 虚拟地址0x080e_9000 ~ 0x080e_9FFF空间中,0x837字节上面的内容才是数据段内容。
那么在虚拟地址空间中,这个数据段的开始地址应该是多少呢?
只要计算出0x837字节空洞的上方,距离这个4K页面开始地址的偏移量就可以了,然后再加上这个4K页面的起始地址 0x080E_9000,就得到了数据段的开始地址(虚拟地址)。
因为虚拟地址、物理地址、test文件中,都是按照4K的单位进行划分的,因此这个偏移量就等于:test文件中数据段的开始地址(0xA0F5C) 距离 这个页面的开始地址(0xA0000) 的偏移量。
0xA0F5C - 0xA0000 = 0xF5C 。
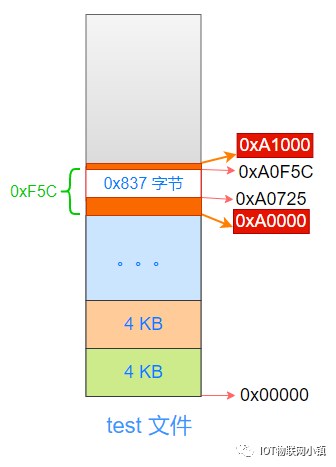
即:从这个4K页面的开始地址,偏移量为0xF5C的地方,才是数据段内容的开始。
因此对于虚拟地址来说,从0x080e_9000地址开始,偏移量为0xF5C之后的内容才是数据段的内容,这个地址值就是:0x080e_9000 + 0xF5C = 0x080e_9F5C,如下所示:
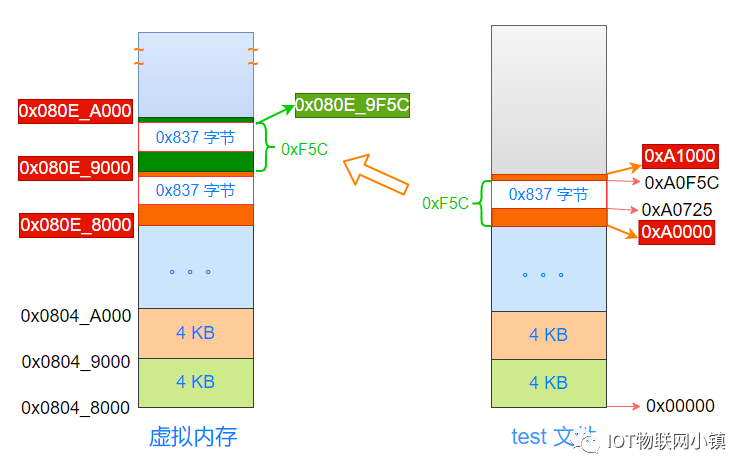
这个地址正是readelf工具读所显示的:数据段加载到虚拟地址空间中的开始地址,如下所示:

至此,就解释了文章开头提出的问题!
再来看一下整个数据段的内容:在内存中数据段占据的空间是 0x01e48(readelf 工具读取到的 MemSiz),那么数据段的结束地址就是(虚拟地址):
0x080e_9F5C + 0x01e48 = 0x080e_bda4
如下所示:
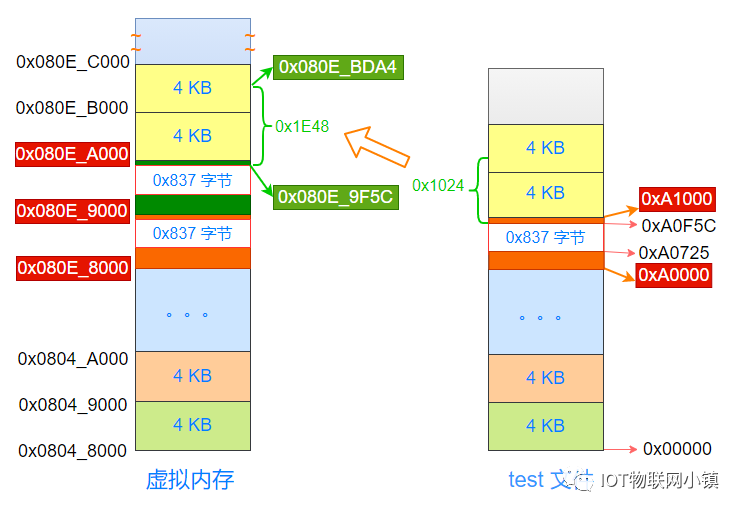
Linux系统中的这个操作:对属于不同段的内容进行重复映射,有点类似于共享内存的味道了。
只不过这里重复映射之后,每个段的虚拟地址还是需要修正为该段的合法地址。
经过这样的操作之后,在虚拟地址中每一个段的界限是泾渭分明的,但是映射到的物理内存页,则有可能是同一个。


 分享到微信
分享到微信  分享到微博
分享到微博Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK