

Vitalik Buterin:如何使用内积参数 (IPA) 进行数据可用性抽样(DAS)
source link: https://www.8btc.com/article/6731088
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Vitalik Buterin:如何使用内积参数 (IPA) 进行数据可用性抽样(DAS)
原文作者:Vitalik Buterin
当前的数据可用性抽样(DA 抽样或 DAS)计划使用 KZG commitments(KZG 承诺)完成。 KZG 承诺的优点是它们非常易于使用,并且具有一些非常好的代数性质:
- 一个评估证明具有恒定的大小,并且可以在恒定的时间内进行验证。
- 这里存在一种算法来计算所有证明,这些证明在 O(N∗log(N)) 时间内在N 个单位根的每一个都会评估 deg<N
- 您可以线性组合承诺以获得这个线性组合的承诺:com(P)+com(Q)=com(P+Q)
- 您可以线性组合证明:Proof(P,x)+Proof(Q,x)+Proof(P+Q,x)
第一点是良好的效率保证。 第二点确保生成可以进行 DA 采样的 blob 很容易:如果生成所有证明需要 O(N2) 这么长的时间,则需要高度中心化的参与者或复杂的分布式算法才能使其准备好 DAS。
第三点和第四点对于 2D 采样非常有价值,并且可以实现分布式区块生产者和高效的自我修复:
- 区块生产者只需要知道原始的 M 承诺即可使用一种按照曲线的FFT(FFT-over-the-curve) 来“扩展列”并生成在同一 deg<M 多项式上的 2M 承诺。
- 您不仅可以进行每行重建,还可以进行每列重建:如果列上的某些值和证明丢失(但仍有一半以上可用),您可以执行 FFT 来恢复丢失的值和证明。
然而,KZG 有一个弱点:它依赖于复杂的配对密码学和受信任的设置。配对密码学已经被研究使用了20 多年,受信任的设置是 N 中的 1 个信任假设,N 是数百名参与者,因此实践中的风险很高,作者认为继续使用 KZG 是完全可以接受的。但是,值得提出一个问题:如果我们不想支付 KZG 的成本,我们可以使用内积参数(IPA)来代替吗?
有关 IPA 的解释,请参阅这篇文章的前半部分。
IPA 具有以下特性:
- 评估证明具有对数大小,可以在线性时间内验证(一个大小为 4096 的多项式大约需要 40 毫秒)
- 没有已知的有效的多重证明生成算法。
- 承诺是椭圆曲线点,您可以像 KZG 承诺一样将它们线性组合
- 没有已知的线性组合证明的方法。
因此,我们保留了一些属性,也丢失了一些属性。 事实上,我们失去的足够多,以至于我们生成、分发和自我修复证明的“当前方法”不再可能。 这篇文章描述了一种替代方法,虽然有点笨拙,但仍然可以实现目标。
一种替代方法
首先,我们生成一棵证明树,而不是为 deg<N 多项式生成 2N 独立证明,这看起来如下:
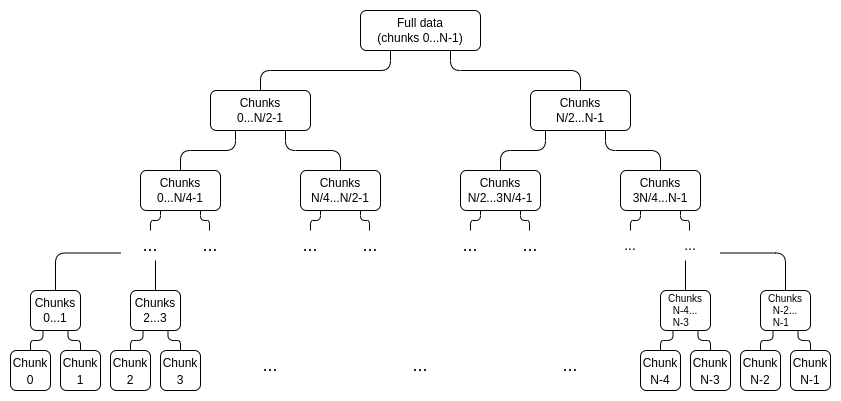
我们以评估形式解释数据,将其视为一个向量:
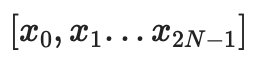
,其中多项式
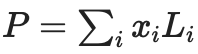
(其中 Li 是在坐标 i 和 0 处等于 1 的 deg<2N 多项式在集合中的其他坐标)。
证明树中的每个节点都是对该部分数据的承诺,以及该承诺实际上“在界限内”的证明。 例如,
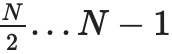
节点将包含承诺
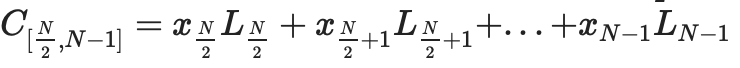
。 将有一个 IPA 证明,
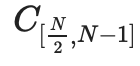
实际上是这些点的线性组合,没有其他点。
我们生成两棵树,第一棵用于
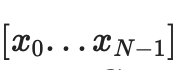
,第二棵用于
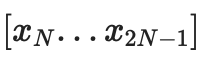
,对一条数据的“完整”承诺由 C[0,N− 1] 和 C[N,2N-1]组成。
为了证明一个特定的值 xi,我们只需提供一个(子承诺,证明)对列表,涵盖整个范围 0...N−1 或 N....2N−1(以包含 i 的为准),不包括 i,以及一个i不属于的顶级承诺是正确构建的证明。例如,如果 N=8 且 i=3,则这个证明将包含C[0,1]、C2、C[4,7] 及其证明,以及一个 C[8,15] 被正确构造的证明。该证明将通过验证各个证明并检查承诺加起来是否构成完整承诺来进行验证。
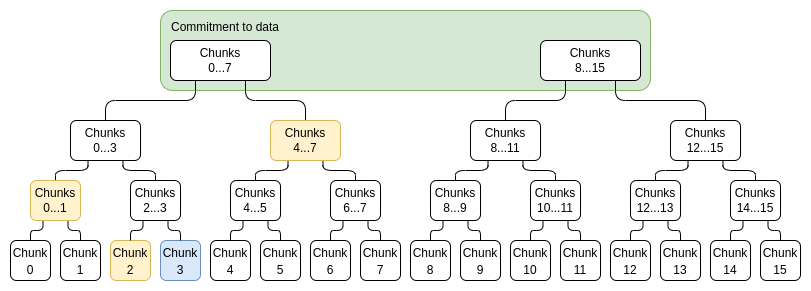
蓝色:chunk 3,黄色:chunk 3 的证明。
注意,为了提高效率,每个chunk不需要是一个单独的评估;相反,我们可以裁剪树,例如一个chunk是一组 16 个评估。鉴于证明的组合大小无论如何都会比这大,像这样使chunk变大,我们损失很少。
生成这些证明需要 O(N∗log(N)) 时间。验证证明需要 O(N) 时间,但请注意,可以批量验证许多证明:验证 IPA 的 O(N) 步骤是椭圆曲线线性组合,我们可以使用随机线性组合检查其中的许多。每个证明仍然需要 O(N) 场域操作,但这只需要 <1 毫秒。
扩展:扇出(fanout)出大于2
我们可以有一个更高的扇出(fanout),而不是每一步都有 2扇出,例如 8扇出。每个承诺我们将有 7 个证明,而不是每个承诺一个证明。例如,在底层,我们将有一个证明 {1,2,3,4,5,6,7},{0,2,3,4,5,6,7},{0,1 ,3,4,5,6,7} 等。这将总证明生成工作增加了
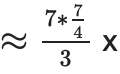
(每个节点 7 个证明,每个证明的大小是原始大小的 1.75 倍,但层数减少了 3 倍,因此 ~4.08 x 更多的努力),但它将证明大小减少了 3 倍。
假设我们正在处理 大小为 32 的N=128 chunk(因此我们有 deg<4096 个多项式)和 一个(4x, 4x, 8x) 的扇出。单个分支证明将包含 3 个 IPA,总大小为 2∗(7+9+12)=56 个曲线点(~1792 字节)加上chunk的 512 字节。今天 256 字节或 512 字节chunk拥有48 字节证明。
生成证明总共需要 2∗8192∗(3∗2+7) 次曲线乘法(两个 fanout-4 层为 3 * 2,fanout-8 层为 7),或总共 ~212992 次乘法。因此,这需要一台功能强大的计算机快速完成(普通计算机可以在约 50 微秒内完成一次乘法运算,因此这需要 10 秒,这有点太长了),或者需要一个分布式过程,其中不同的节点专注于为不同的chunk。
验证证明很容易,因为可以批量验证证明,并且只完成一个椭圆曲线乘法。因此,它不应该比使用 KZG 证明慢很多。
无法逐列有效地进行自我修复。但是我们能否避免要求单个修复拥有所有数据(来自所有 2M 多项式的所有 2N chunks)?
假设单行完全丢失。很容易使用任何列来重建该列中缺失行中的值。但是如何证明呢?
最简单的技术是加密经济学:任何人都可以简单地发布一个声明一个值的债券,然后有人可以将该声明与证明不同值的分支证明一起使用,以削减该验证者。只要有足够的合法声明可用,该行子网上的某个人就可以将声明组合在一起并重建承诺和证明。甚至可能要求验证者针对分配给他们的样本索引发布此类声明。
一种没有加密经济学但在技术上更复杂且速度更慢的替代方案是传递沿该列的值的 M 分支证明,以及证明正确验证的 Halo 式证明。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK