

人肉计算(1): 众包与群众智慧
source link: https://changkun.de/blog/posts/human-computation-1/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

这篇文章我们来聊聊几个学术界很时髦的几个概念:
- Crowdsourcing (众包)
- Human Computation (人肉计算)
- Wisdom of crowds (群众智慧)
首先,解释一下我将 「Human Computation」译为「人肉计算」的原因:
- 「Human Computation」这一词在中文界尚无公认的标准议法;
- 主流译法为「人计算」、「人本计算」、「人类计算」均欠妥,「人计算」没有译出人为核心的概念,「人本计算」多用于「Human-Centred Computation」,强调以人为本的想法,并未实际替代计算,而「人类计算」则显得概念过于庞大,一个「Human Computation」的系统通常没有涉及「人类」如此之大的范畴。
其次,我们将在下面的内容详细阐述为什么「人肉计算」应当受到重视。
下图给出了本文谈及的几个重要概念的韦恩图分类[1]:
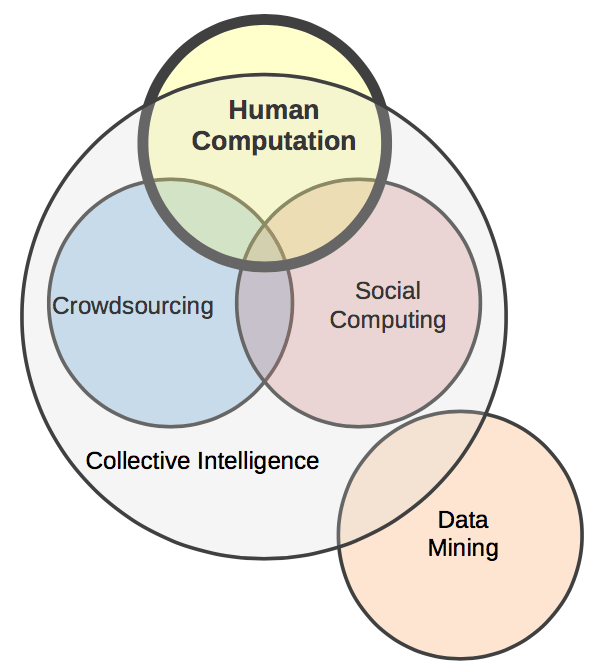
什么是众包(Crowdsourcing)?
什么是众包? 组织招募各种有偿或无偿的自由职业者从事特定任务或问题的做法被称之为众包(Crowdsourcing)。
- 通过征求大群人(尤其是在线社区)而不是传统员工或供应商的贡献来获得所需的服务、想法或内容的做法。
- 在 2003 年向硬度和中国发送工作。新的廉价劳动力池:日常人使用它们的备用周期创造内容、解决问题,甚至是企业研究开发,这被称之为外包。
案例:众包的兴起
- iStockphoto: 市场的业余摄影师的工作比专业摄影师或代理低得多的价格来销售图片
- 在线频道的制作人要求观众为节目制作视频:「回复率很高,但大部分都是垃圾,只有 20 个候选者」
- InnoCentive: 「seekers」发布技术问题,「solvers」提出解决方案。许多解决者都是爱好者或学生,解决者成功的几率在没有正式专业知识的领域有所增加
- iConclude: 调试:支付 $2000 给技术支持工作者为修理流程、步骤解决问题,但实际上却是由一个土耳其人只花了五美元解决的。
上面的四个案例中,每一种案例都具有下面的驱动因素:
- 媒体技术(从相机到社交媒体)
- 搜索引擎(以及随后的数据分析)
什么是人肉计算(Human Computation)?
人肉计算系统是将人和计算机结合起来解决不能解决的大规模问题的系统。
- 将人和及其相互联系起来,将信息作为另一个系统进行处理,并达到目的的系统;
- 系统「采取一群人,并将它们变成思维系统,一种高级有机体」;
- 软件系统与人在循环中:作为数据或计算的显式(主动)贡献者
定义:人肉计算系统能够被看做是以物易物、替代货币的众包市场。
案例:隐式人肉计算系统
- Google 地图导航系统
- 协同过滤系统(Amazon 搜索引擎和推荐系统)
- 搜索引擎(Google)
案例:显式人肉计算系统
- Wikipedia 维基百科
- 天文图像分析
- 灾难实时监控系统
- Google 地图
- Google 翻译
- Duolingo
- 创意市场(Incentive,YouEncore)
- 微任务市场(Amazon Mechanical Turk)
什么是群众智慧(Wisdom of crowds)?
- 将信息聚集在组中,导致决策通常比组中任何单个成员做出的决策更好。
James Surowiecki 的论文:「群众智慧:为什么许多人比几个人更聪明,集体智慧如何形成商业、经济、社会和国家」
Surowiecki 定义群众智慧的四个方面:
- 意见分歧 (Diversity of opinion): 每个人都有私人信息
- 独立自主 (Independence): 一个人的意见不是由他人的意见决定的
- 去中心化 (Decentralization): 人们能够专门化利用具体的知识
- 内容聚合(Aggregation): 有一个机制能够将独立的意见转化为集体意见
注:Hari Oinas-Kukkonen 的论文: 「网络分析和人群作为新组织知识的来源」。但可惜的是,Surowiecki 和 Onias 没用(使用统计学或其他方式)证明自己的说法。
案例:满足群众智慧
- Wikipedia 满足 Surowiecki 提出的群众智慧所需的四个条件
- 意见分歧:参与编辑维基百科的人对于同一事实产生不同的内容
- 独立自主:每个人都具有独自理解的内容
- 去中心化:最终落实的结论并非以某一个人的观点为标准
- 内容聚合:Wikipedia 聚合了所有人的观点
- PageRank 是满足 Surowiecki 对于群众智慧的四个条件的:
- 意见分歧:每个网站对其他网站的排名都是不同的
- 独立自主:每个网站都是独立于其他网站存在的
- 去中心化:最终结果整体收敛,不以某一个网站为中心
- 内容聚合:PageRank 本身就是一个聚合的过程
但是,Google 搜索引擎是否总能满足这四个条件是值得怀疑的。
- 市场满足 「Wisdom of Crowd」的四个方面,市场通过代理人的行为向(市场)代理商分配商品或者服务。
- 意见分歧:具有不同的意见
- 独立自主:彼此独立竞争,互相对抗这些商品或服务
- 去中心化:不是集中控制
- 内容聚合:市场价格和在市场上实现的货物或服务重新分配可以被看做是聚合的形式
- Surowiecki 对于群众智慧的前三个条件
都是一个良好运作的民主制度的前提条件。但一个民主还需要 Surowiecki 的第四个关于群众智慧的条件:具有聚合形式的集体决策系统。
群众智慧的陷阱
Wikipedia, PageRank, 市场, 民主人士都具有反身性(Reflexivity),所谓反身性指满足下面条件:
- 个人意见或者价格的供求都是需要提交的
- 集体意见或市场价格是作为个人意见或者价格供求的汇总而产生的
- 集体意见或市场价格影响着个人意见或价格的供求
- 过程是循环重复的
反身性可能导致局部或全局的恶性循环:
案例:反身性恶性循环
- 市场泡沫
- 17 世纪郁金香市场泡沫
- 2000~2001 年 Dot-com 泡沫
- 2007~2008 年次贷危机
- 泡沫之前:价格持续上涨的时间比平时要长
- 「繁荣」:越来越多的交易者被意想不到的收益引发,因为他们希望稍后以更高的价格出售,因此放松了风险和购买意愿,进而有助于保持价格上涨。
- 「破产」:在某种程度上,交易者有足够的理由来停止购买,是的价格飙升而大幅度下滑。
案例:反身性的良性循环
- 维基百科的文章是稳定保持不变的
- 如果一个观点占大多数,那么就应该容易参考普遍接受的参考文献来证实它
- 如果一个观点只有少数人认同,那么很容易标注冲突的观点
- 如果一个观点由一个极小(或极少数)的人支持,它不属于维基百科,无论其真实性是否可以被证明,除非给出一些辅助文章加以说明
这对于一个百科全书来说是可接受的。
群众智慧、众包以及设计人肉计算系统的反思
众包中对于反身性的两个陷阱:
- 反身性的恶性循环
- 与社会从众行为(Social conformism)相悖(艺术、伦理、科学)
反身性的恶性循环可以通过这两点避免:
- 提供信息(比如泡沫的风险)
- 调节个人行为(排除银行挤兑)
社群可以规避从众行为,如果:
- 价值创造力
就像经常(但不总是)在艺术和科学中的情况。
进一步阅读的参考文献
[1] Human Computation: A Survey and Taxonomy of a Growing Field, Alexander J. Quinn, Benjamin Bederson, CHI 2011 [2] Human Computation in the Wild, H. Hirsh - Handbook of Human Computation, 2013 [3] Segaran T, 莫映, 王开福. 集体智慧编程. 電子工業出版社; 2009.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK