

实战-Mongo优化
source link: https://blog.zhaoweiguo.com/2020/10/21/db-mongo-optimize-index/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

实战-Mongo优化
Mongo集群CPU报警,查看现象是那一小段突然有一个请求小高峰,经过分析把问题定位到一个新增的接口上,这个接口中有一个Mongo的慢查询,这个慢查询对应的相关信息有:
- 集合总文档数超过 6 亿条
- 按条件查询后获取的数据也有几万条
- 之前已经加了几个索引,但效果不是特别理想
总数据量:
> db.zwg_log.count()
[693090136] // 6.9亿
查看文档结构:
> db.zwg_log.find().limit(3)
{
_id: "add6a2c545fb389a96fed19730772e24",
source_id: "xxxx",
user_id: "zhaoweiguo",
is_delete: "0",
is_read: "0",
time_created: ISODate("2018-03-11T04:47:14.621Z"),
time_updated: ISODate("2018-03-11T04:47:14.621Z")
...
},
{
_id: "add93f066c0e3e4c07f2962884799da4",
source_id: "xxxx",
user_id: "zhaoweiguo",
is_read: "0",
is_delete: "0",
time_created: ISODate("2017-03-29T23:40:50.485Z"),
time_updated: ISODate("2017-03-29T23:40:50.485Z")
...
},
相关索引主要有:
[
{
v: 2,
key: {
source_id: 1.0,
is_delete: 1.0,
time_created: -1.0
},
name: "source_id_1.0_is_delete_1.0_time_created_-1.0"
}
{
v: 2,
key: {
is_delete: 1.0,
user_id: 1.0,
time_created: -1.0
},
name: "is_delete_1_user_id_1_time_created_-1"
},
{
v: 2,
key: {
source_id: 1,
user_id: 1,
is_delete: 1,
is_read: 1
},
name: "source_id_1_user_id_1_is_delete_1_is_read_1"
}
]
使用默认索引
使用explain命令验证慢查询的请求,发现
默认使用的是isdelete_1_user_id_1_time_created-1索引
执行语句:
> db.zwg_log.explain("executionStats").find({
"source_id": "XXXXXXXX85877cc4ada3217c7dff2627e11064d8",
"user_id": "XXXXXXXX79441a98e6952befe5db9148",
"is_delete": "0",
"is_read": "0"
}).sort({"time_created":-1}).limit(3)
执行结果:
executionStages: {
stage: "SINGLE_SHARD",
nReturned: 3,
executionTimeMillis: 180,
totalKeysExamined: 22387,
totalDocsExamined: 22387,
totalChildMillis: NumberLong(175),
shards: [
{
shardName: "d-XXXXXXXXe0a5c484",
executionSuccess: true,
executionStages: {
stage: "LIMIT",
nReturned: 3,
executionTimeMillisEstimate: 117,
works: 22388,
inputStage: {
stage: "FETCH",
nReturned: 3,
executionTimeMillisEstimate: 117,
works: 22387,
docsExamined: 22387,
inputStage: {
stage: "IXSCAN",
nReturned: 22387,
executionTimeMillisEstimate: 12,
works: 22387,
indexName: "is_delete_1_user_id_1_time_created_-1",
isMultiKey: true,
multiKeyPaths: {
is_delete: [
],
user_id: [
"user_id"
],
time_created: [
]
},
keysExamined: 22387,
}
}
}
}
]
}
使用指定索引 source_id_1_user_id_1_is_delete_1_is_read_1
指定使用使用source_id_1_user_id_1_is_delete_1_is_read_1索引
执行语句:
> db.zwg_log.explain("executionStats").find({
"source_id": "XXXXXXXX85877cc4ada3217c7dff2627e11064d8",
"user_id": "XXXXXXXX79441a98e6952befe5db9148",
"is_delete": "0",
"is_read": "0"
}).sort({"time_created":-1}).limit(3).hint({
"source_id": 1,
"user_id": 1,
"is_delete": 1,
"is_read": 1
})
返回结果:
executionStages: {
stage: "SINGLE_SHARD",
nReturned: 3,
executionTimeMillis: 1272,
totalKeysExamined: 5856,
totalDocsExamined: 5856,
totalChildMillis: NumberLong(1263),
shards: [
{
shardName: "d-XXXXXXXXe0a5c484",
executionSuccess: false,
executionStages: {
stage: "SORT",
nReturned: 0,
executionTimeMillisEstimate: 1290,
works: 5858,
sortPattern: {
time_created: -1
},
memUsage: 5806,
memLimit: 33554432,
inputStage: {
stage: "SORT_KEY_GENERATOR",
nReturned: 5856,
executionTimeMillisEstimate: 1266,
works: 5857,
inputStage: {
stage: "FETCH",
nReturned: 5856,
executionTimeMillisEstimate: 1209,
works: 5856,
inputStage: {
stage: "IXSCAN",
nReturned: 5856,
executionTimeMillisEstimate: 26,
works: 5856,
indexName: "source_id_1_user_id_1_is_delete_1_is_read_1",
keysExamined: 5856,
}
}
}
}
}
]
}
使用索引
is_delete_1_user_id_1_time_created_-1请求时间是180;而使用索引source_id_1_user_id_1_is_delete_1_is_read_1的请求时间是1272ms。所以Mongo使用这个索引作为最佳索引没有问题。第2个索引时间主要消耗在排序上面了。
如果不按时间排序,则使用 source_id_1_user_id_1_is_delete_1_is_read_1 索引只需要扫描3条记录,时间会是几毫秒。参见:
> db.zwg_log.explain("executionStats").find({
"source_id": "XXXXXXXX85877cc4ada3217c7dff2627e11064d8",
"user_id": "XXXXXXXX79441a98e6952befe5db9148",
"is_delete": "0",
"is_read": "0"
}).limit(3).hint({
"source_id": 1,
"user_id": 1,
"is_delete": 1,
"is_read": 1
})
executionStats: {
nReturned: 3,
executionTimeMillis: 2,
totalKeysExamined: 3,
totalDocsExamined: 3,
executionStages: {
stage: "SINGLE_SHARD",
nReturned: 3,
executionTimeMillis: 2,
totalKeysExamined: 3,
totalDocsExamined: 3,
totalChildMillis: NumberLong(1),
shards: [
{
shardName: "d-2ze07ec75d921fa4",
executionSuccess: true,
executionStages: {
stage: "LIMIT",
nReturned: 3,
executionTimeMillisEstimate: 0,
limitAmount: 3,
inputStage: {
stage: "FETCH",
nReturned: 3,
executionTimeMillisEstimate: 0,
docsExamined: 3,
inputStage: {
stage: "IXSCAN",
nReturned: 3,
executionTimeMillisEstimate: 0,
works: 3,
indexName: "source_id_1_user_id_1_is_read_1_is_delete_1"
}
}
}
}
]
}
}
原因找到了,优化就比较容易了。
根据上面分析,优化方法就显而易见了:增加一个联合索引
db.zwg_log.createIndex({
"source_id": 1,
"user_id": 1,
"is_delete": 1,
"is_read": 1,
time_created:-1
}, {background: true})
优化后,执行:
> db.zwg_log.explain("executionStats").find({
"source_id": "XXXXXXXX85877cc4ada3217c7dff2627e11064d8",
"user_id": "XXXXXXXX79441a98e6952befe5db9148",
"is_delete": "0",
"is_read": "0"
}).sort({"time_created":-1}).limit(3)
结果如下:
executionStats: {
nReturned: 3,
executionTimeMillis: 2,
totalKeysExamined: 3,
totalDocsExamined: 3,
executionStages: {
stage: "SINGLE_SHARD",
nReturned: 3,
executionTimeMillis: 2,
totalKeysExamined: 3,
totalDocsExamined: 3,
totalChildMillis: NumberLong(2),
shards: [
{
shardName: "d-XXXXXXXXe0a5c484",
executionSuccess: true,
executionStages: {
stage: "LIMIT",
nReturned: 3,
executionTimeMillisEstimate: 0,
inputStage: {
stage: "FETCH",
filter: {
is_read: {
$eq: "0"
}
},
nReturned: 3,
executionTimeMillisEstimate: 0,
inputStage: {
stage: "IXSCAN",
nReturned: 3,
executionTimeMillisEstimate: 0,
keyPattern: {
source_id: 1,
user_id: 1,
is_delete: 1,
time_created: -1
},
indexName: "source_id_1_user_id_1_is_delete_1_time_created_-1",
isMultiKey: true,
}
}
}
}
]
}
},
就和不排序的请求使用索引 source_id_1_user_id_1_is_delete_1_is_read_1 效果一样了。
小插曲-特殊数据可能会特别快
在优化完成后,高兴之余遇到下面这么一个奇怪的问题:
在优化完成后强制指定使用索引
is_delete_1_user_id_1_time_created_-1时,
发现它的执行效率居然和使用新增加的索引一样,都是毫秒级
更诡异的是连文档扫描数也一样是3条
指定使用索引 is_delete_1_user_id_1_time_created_-1 :
> db.zwg_log.explain("allPlansExecution").find({
"source_id": "XXXXXXXXdbf62d674a034e982586dcc85ecf4e78",
"user_id": "XXXXXXXX79441a98e6952befe5db9148",
"is_delete": "0",
"is_read": "0"
}).sort({"time_created":1}).limit(3).hint({
is_delete: 1,
user_id: 1,
time_created: -1
})
结果如下:
executionStages: {
stage: "SINGLE_SHARD",
nReturned: 3,
executionTimeMillis: 0,
totalKeysExamined: 3,
totalDocsExamined: 3,
totalChildMillis: NumberLong(0),
shards: [
{
shardName: "d-XXXXXXXXe0a5c484",
executionSuccess: true,
executionStages: {
stage: "LIMIT",
nReturned: 3,
inputStage: {
stage: "FETCH",
nReturned: 3,
executionTimeMillisEstimate: 0,
docsExamined: 3,
inputStage: {
stage: "IXSCAN",
nReturned: 3,
executionTimeMillisEstimate: 0,
indexName: "is_delete_1_user_id_1_time_created_-1",
keysExamined: 3,
}
}
}
}
]
}
看到没有和前面的最优解除了使用的索引不同外,其他几乎完全一样。是什么原因造成的?是缓存吗?是query plans吗?当你对MongoDB不了解时,有很多的可能,你需要一点点排除。
query plans分析
首先不可能是query plans,因为我们使用的是指定索引。
缓存加速现象分析
是缓存造成的吗?
缓存的确能加快查询效率,但下面这种现象才真正是缓存造成的加速效果:
> db.zwg_log.explain("allPlansExecution").find({
"source_id": "XXXXXXXX85877cc4ada3217c7dff2627e11064d8",
"user_id": "XXXXXXXX79441a98e6952befe5db9148",
"is_delete": "0",
"is_read": "0"
}).sort({"time_created":-1}).limit(3).hint({
is_delete: 1,
user_id: 1,
time_created: -1
})
第一次执行时效率如下:
executionStats: {
nReturned: 3,
executionTimeMillis: 1032,
totalKeysExamined: 22387,
totalDocsExamined: 22387,
第二次执行:
executionStats: {
nReturned: 3,
executionTimeMillis: 339,
totalKeysExamined: 22387,
totalDocsExamined: 22387,
第三次执行:
executionStats: {
nReturned: 3,
executionTimeMillis: 180,
totalKeysExamined: 22387,
totalDocsExamined: 22387,
我们看到,3次同样的执行,虽然因为缓存原因,查询速度越来越快,但文档扫描是不变的。而上面的现象文档扫描只有3次,所以排除缓存造成这么快。
真实的原因其实是查询这个数据就是只需要扫描3条记录就能得到想要的数据,因为你下面语句执行
db.zwg_log.find({
"user_id": "XXXXXXXX79441a98e6952befe5db9148",
"is_delete": "0"
}).sort({time_created:-1}).limit(3)
得到的结果是:
[
{
_id: "b5cd1fd5382c403292714f7ceb13e7b9",
source_id: "XXXXXXXXdbf62d674a034e982586dcc85ecf4e78",
user_id: "XXXXXXXX79441a98e6952befe5db9148",
is_delete: "0",
is_read: "0",
...
},{
_id: "518cbb3e9fb6b5c0c53e0d99ef6e0bcf",
source_id: "XXXXXXXXdbf62d674a034e982586dcc85ecf4e78",
user_id: "XXXXXXXX79441a98e6952befe5db9148",
is_delete: "0",
is_read: "0",
...
},{
_id: "c3703d2139a1b2f381eb3690678d7985",
source_id: "XXXXXXXXdbf62d674a034e982586dcc85ecf4e78",
user_id: "XXXXXXXX79441a98e6952befe5db9148",
is_delete: "0",
is_read: "0",
...
}
]
前3条就完全能满足条件,所以这个查询条件下使用索引
is_delete_1_user_id_1_time_created_-1和使用索引source_id_1_user_id_1_is_delete_1_is_read_1_time_created_-1效率是一样的。
使用其他数据证实
上面的原因是数据恰好合适,我使用其他 source_id 的值应该就不会这么快了吧
速度超快的文档扫描了3次:
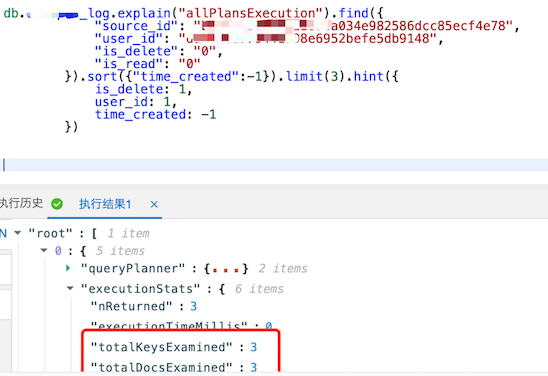
用另一个source_id文档扫描变成了2.2万次:
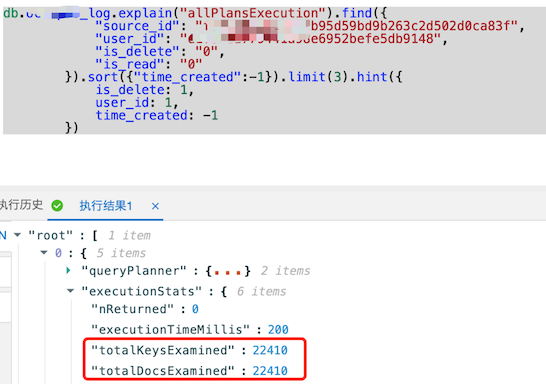
这种只有数据不同,其他都相同的,基本可以判断为『就是数据比较特殊,并没有代表性』
使用正序查询证实
现在再看看如果排序按时间正序,效果如何:
> db.zwg_log.explain("allPlansExecution").find({
"source_id": "XXXXXXXXdbf62d674a034e982586dcc85ecf4e78",
"user_id": "XXXXXXXX79441a98e6952befe5db9148",
"is_delete": "0",
"is_read": "0"
}).sort({"time_created":1}).limit(3).hint({
is_delete: 1,
user_id: 1,
time_created: -1
})
结果如下:
executionStages: {
stage: "SINGLE_SHARD",
nReturned: 3,
executionTimeMillis: 1141,
totalKeysExamined: 9433,
totalDocsExamined: 9433,
totalChildMillis: NumberLong(1138),
shards: [
{
shardName: "d-XXXXXXXXe0a5c484",
executionSuccess: true,
executionStages: {
stage: "LIMIT",
nReturned: 3,
executionTimeMillisEstimate: 1089,
works: 9434,
limitAmount: 3,
inputStage: {
stage: "FETCH",
nReturned: 3,
executionTimeMillisEstimate: 1089,
works: 9433,
docsExamined: 9433,
inputStage: {
stage: "IXSCAN",
nReturned: 9433,
executionTimeMillisEstimate: 47,
works: 9433,
indexName: "is_delete_1_user_id_1_time_created_-1",
keysExamined: 9433,
}
}
}
}
]
}
好了,我们看到,只需把排序从倒序改为正序,时间就从毫秒级变成秒级。
为啥会有这种现象?为啥之前只需要扫描3条记录,现在需要扫描9433条了呢?
更深一步数据分析
> db.zwg_log.count({
"user_id": "XXXXXXXX79441a98e6952befe5db9148",
"is_delete": "0",
})
[22410] // 2.2万条
> db.zwg_log.count({
"source_id": "XXXXXXXXdbf62d674a034e982586dcc85ecf4e78",
"user_id": "XXXXXXXX79441a98e6952befe5db9148",
"is_delete": "0",
"is_read": "0"
})
[12918] // 1.2万条
> db.zwg_log.count({
"source_id": "XXXXXXXX85877cc4ada3217c7dff2627e11064d8",
"user_id": "XXXXXXXX79441a98e6952befe5db9148",
"is_delete": "0",
"is_read": "0"
})
[5856] // 5856条
这个表中有此用户相关数据是2.2万条,而满足
source_id="XXXXXXXXdbf62d674a034e982586dcc85ecf4e78"的数据大都是最新生成的,所以按时间倒序时能快速命中,而按时间正序时,由于前面的数据都不满足source_id="XXXXXXXXdbf62d674a034e982586dcc85ecf4e78"这个条件,所以需要把前面的都扫描完成,才会命中所需要的数据。
如果在表 zwg_log 中按时间倒序前 12918 条数据的 source_id 都等于 XXXXXXXXdbf62d674a034e982586dcc85ecf4e78:
db.zwg_log.find({
"user_id": "XXXXXXXX79441a98e6952befe5db9148",
"is_delete": "0"
}).sort({time_created:-1}).limit(12918)
那么当按时间正序使用索引
is_delete_1_user_id_1_time_created_查询时,需要的文档扫描数为22410-12918+3=9495也就是这种情况需要扫描9495条。而上面的分析文档扫描了9433次,这说明source_id="XXXXXXXXdbf62d674a034e982586dcc85ecf4e78"的数据并不完全是最新的 ,以上。
小插曲-排序与不排序的区别
还有一个问题,如果我查询不指定排序,正常不指定的话应该使用 source_id_1_user_id_1_is_delete_1_is_read_1 索引吧,但很奇怪的是有时使用 source_id_1.0_is_delete_1.0_time_created_-1 这个索引。
db.zwg_log.find({
"source_id": "XXXXXXXXdbf62d674a034e982586dcc85ecf4e78",
"user_id": "XXXXXXXX79441a98e6952befe5db9148",
"is_delete": "0",
"is_read": "0"
}).limit(3).explain()
怀疑是与MongoDB的查询计划(Query Plans)有关
查询计划相关知识
Mongo 自带了一个查询优化器会为我们选择最合适的查询方案:
- 如果一个索引能够精确匹配一个查询,那么查询优化器就会使用这个索引。
- 如果不能精确匹配呢?可能会有几个索引都适合你的查询,那 MongoDB 是怎样选择的呢?
MongoDB 的查询计划会将多个索引并行的去执行,最先返回第 101 个结果的就是胜者,
其他查询计划都会被终止,执行优胜的查询计划;
这个查询计划会被缓存,接下来相同的查询条件都会使用它;
缓存的查询计划在以下条件下会清空并重新评估:
集合收到 1000 次写操作
执行 reindex
添加或删除索引
mongod 进程重启
可能的原因
可能和上面一个小插曲一样,因为数据原因。
因为 user_id 与 souce_id 是一对多的关系。所以按 souce_id 查询与按 source_id + user_id 查询得到的结果相同;并且 is_read 的值都为0。 所以使用索引 source_id_1.0_is_delete_1.0_time_created_-1 和使用索引 source_id_1.0_is_delete_1.0_time_created_-1 都只需要扫描3次。
但这儿和上面说的『如果一个索引能够精确匹配一个查询,那么查询优化器就会使用这个索引。』相悖
现场如下:
1、isread=1时,使用索引 ``source_id_1.0_is_delete_1.0_time_created-1``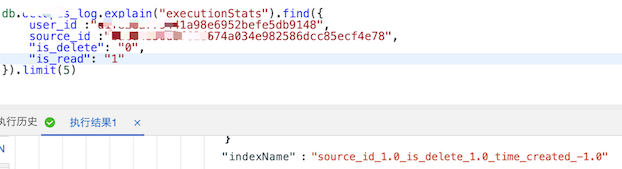
2、is_read=0时,使用索引 source_id_1_user_id_1_is_delete_1_is_read_1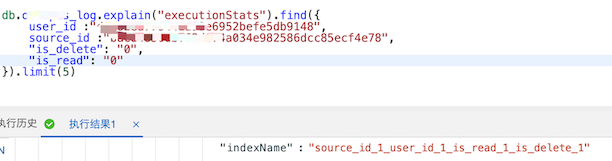
后续待研究确认……
这种表是否合适分片?分片后是否会提高查询效率?
我们DB是分片DB,这个文档目前还不是分片的
后续有时间会研究一下这个文档是否应该分片?分片后是否能按所想提高效率?
- 你真的会用索引么?[Mongo]: https://zhuanlan.zhihu.com/p/77971681
- MongoDB 执行计划获取: https://blog.csdn.net/leshami/article/details/53521990
- MongoDB 查询优化:从 10s 到 10ms: https://developer.aliyun.com/article/74635
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK