

BI系统里的数据赋能与业务决策:问题诊断篇
source link: https://www.niaogebiji.com/article-70334-1.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

一、什么是问题诊断?
今天我们来谈谈BI系统里数据决策很常见的一个场景应用——问题诊断。
所谓问题诊断,就是找到在什么环节出现了问题,即定位问题,他有两层含义:
第一,有没有问题?
第二,问题出现在什么地方?
第一个问题好理解,第二个问题,大家的看法则会有差异,下面我将用例子来说明自己的理解,欢迎大家留言探讨。
举个例子:
在观测网站活跃用户数的过程中,发现本周的活跃用户数比上周的活跃用户数有了一个较大幅度的下降,通过分析数据后,发现原来是某1天的活跃用户数下降引起的,询问了IT部门后发现这一天网站有问题,某几个重要的页面有2个小时不能访问。
在这个案例中,『某1天的活跃用户数下降』就是问题诊断,而页面出现问题不能访问则是问题产生的原因。
问题诊断绝对不是简单看数据指标的表现,简单的数据增减幅度、趋势展示,是属于传统BI看板的范围,只能回答第一个问题——有没有问题,但是并不能回答哪里出了问题。
二、问题诊断的种类
问题诊断的场景一般可以分为两类:
第一类是数据统计量的异常问题诊断;
第二类是独立个体的异常问题诊断。
下面分别这对两种类型的问题诊断,结合具体事例来进一步讲解。
01 、数据统计量的异常问题诊断
如在文章开头提到的那个例子,数据统计量的问题诊断,是指问题会通过指标统计值反应出来,我们通过数据本身的增减幅度、趋势变化、逐层拆解,最后可以发现数据变化是在哪个环节发生。这种问题一般都是由于数据之外的原因产生的,这类问题诊断,可以帮助业务用户缩小问题的范围,大家感受一下,你和朋友讨论去哪吃饭,是在全城的5星餐馆中做出选择,和在公司附近5公里的餐馆中做出选择,哪一个更容易?
要实现与数据统计量相关的问题诊断,一个比较常见方法,就是选择出数据观察的各个维度,通过度量值在各个维度上的变化情况(与历史比较、与平均值比较等),找到变化的那个维度的值。
这种处理方法在BI系统里面最典型的案例就是tableau的explain data功能,这个功能会自动针对所选值提供由 AI 驱动的解释。
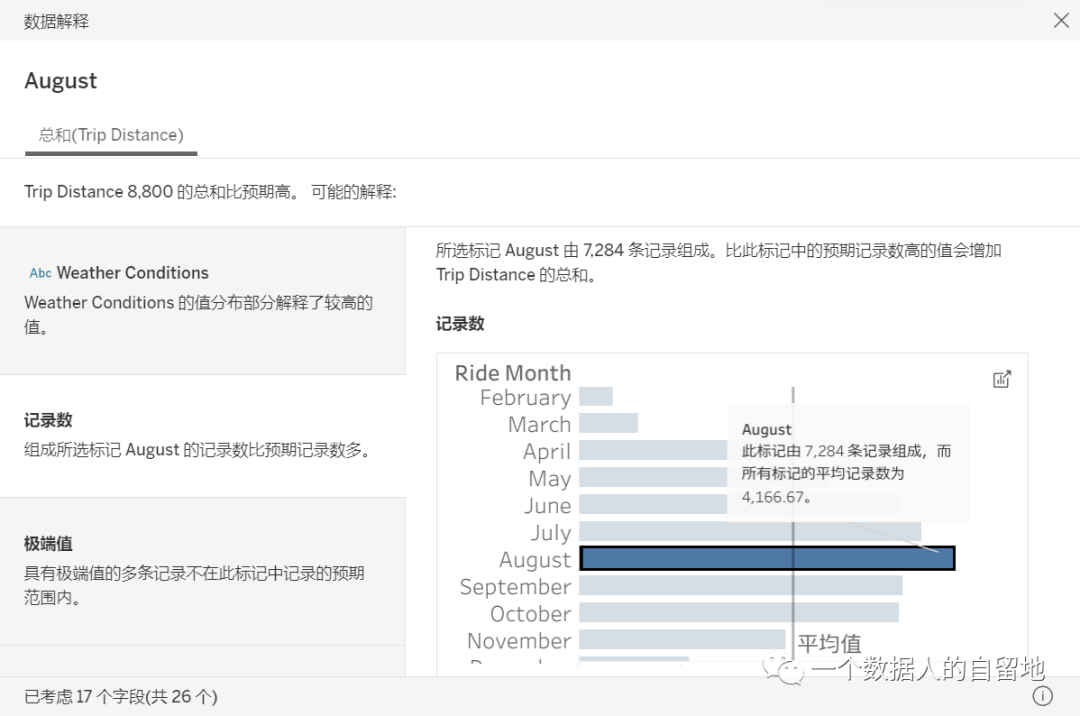
图1 tableau的explain Data功能
在tableau的2020.2 new feature网络研讨会上对explain data性能增强的介绍下让可以大概知道运行原理:
当你点击某个数据值进行explain data时,系统会自动对数据集的每一个维度、每一个度量都进行交叉计算,判断需要解释的数据值是高于还是低于预期(均值)。
以高于预期为例,explain data会尝试做以下几类解释:
先去扫描所有的维度信息,看是否有显著的维度(这个维度的值普遍偏高);
然后去考察记录数(数据条数),是否是由于数据记录数较高导致;
再次,考虑极端值的情况,是否是因为某个极端值造成了偏高。
但是这种处理方法,需要较大的计算资源,数据集较大或者维度偏多explain data会比较慢的问题。并且很有可能,大部分的计算都未必是必须的。
在新版的explain data中,对计算的维度范围进行了限制(不再对所有维度进行解析,有一些明显值过多的维度、包含了平均值的维度都会默认被忽略)。在数据集较大的情况下或者维度较多的情况,计算速度有了改进。
这就是通用BI的处理办法,面对多种多样的数据集,内容和业务都各异的情况下,剔除掉出那些不太可能导致异常,或者值本身并不能定位问题的情况。
如果你在做一些垂直领域的BI,引入业务理解会是更好的办法,通过业务逻辑,将你的维度排上优先级,关联下钻策略,避免从最小维度开始遍历,都是不错的办法。
还是用文章开头的案例,本周的活跃用户数比上周的活跃用户数有了一个较大幅度的下降的问题定位:通过两种类型维度的切分,第一种:时间维度下钻,计算下一层维度上(在这个案例中,是天)的活跃用户数的变化;第二种,计算对重要维度的度量值的变化,在这个案例中,与活跃用户数相关的重要维度可能是:用户注册渠道、用户访问页面等。
在这个案例中,通过第一种维度切分,发现原来是某1天的活跃用户数下降引起的。经验上,一般来说,会优先进行第一种维度计算,再进行第二种。
02 、独立个体的异常问题诊断
下面谈一谈独立个体的异常问题诊断。
这种异常的特点是,并不一定能通过数据统计值的宏观变化来发现,这有2个原因:
第一,这种异常的表现大部分并不会影响到整体数据,从整体上看数量占比上很少;
第二,这种异常是非数据的,是从流程上定义的异常(SOP规范之外的)。
不管是第一种还是第二种原因的异常问题,如果一旦发生了,影响会比较大,我们应该及时定位到。
这种独立个体的问题,一般在智能制造(智慧工厂)的场景见到的比较多,比如某机器宕机了,影响到了生产线;机器上某个关键部件磨损了,造成产品的良品率下降;日常业务也会有这种场景,比如入库环节的延迟造成了后续流程整体延后;在公司内部公共空间分享的文档明文密码增加了安全风险。

图2 智能制造
这类问题诊断的解决方案挺多,我们介绍下在日常业务场景中两种比较常见的方案。
第一,规则策略。
如果是由于流程上定义的异常,可以通过抽象出非正常的数据表现,形成规则集,用策略的方法识别出问题。比如,在公司内部公共空间分享的文档明文密码识别,可以通过常见的密码出现场景,整理成规则集合,扫描所有文档内容与这个规则集合进行匹配。
举例:一般密码出现都会以”密码”/“pw”一串英文数字字符的一形式,这个就是一条规则,列出多个规则形成规则集合。
这种方案相对比较简单,特别适合产品0到1阶段。
第二,知识图谱。
知识图谱的方案适合流程分支比较多、环节与环节之间的影响关系复杂的情况(这种情况也可以用规则策略,但规则会特别多,效果未必好)。
比如,最近我们常用的健康码,背后识别机制,就可以通过知识图谱方式来做。
用户申请健康码时,会授权app调取你得个人信息(包括手机号、社交账号、出行信息、定位信息等),通过大数据挖掘可以构造出一个『人-时间-地理位置』的关系,用户数量多了,这个关系交织在一起就成了一张巨大的网络。不管是人还是地理位置,某个属性发生了更新(异常)后,产生的影响会在图谱中蔓延。
图3 知识图谱
再举一个例子:
大数据平台的各类表生产任务有很多上下游依赖,当其中有一个任务故障或者变更时,可能会对众多下游任务产生影响,一般来说,生产者最多会通知自己的下游任务,而很难去主动去通知下游的下游,更别说在庞大的数据集市中,还有更多层次的引用和依赖了。
我们把各个数据开发任务之间的关系制作出【数据表-数据字段】的元数据知识图谱,通过元数据之间的图谱关系,这样可以很快定位到受影响的表及其任务,如果多个下游任务出现异常了,也可以通过知识图谱找到影响自己的上游。
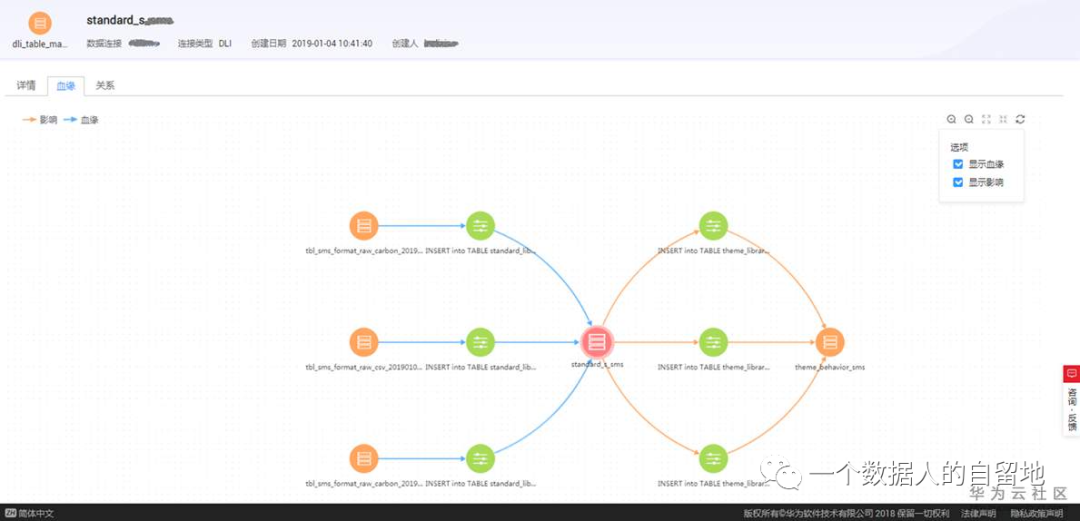
图4 血缘关系
关于智能制造(智慧工厂)场景下的问题诊断,方案会更具备垂直领域的特点,也会比日常运营中遇到的场景更复杂一些。
-END-
本文为作者独立观点,不代表鸟哥笔记立场,未经允许不得转载。
《鸟哥笔记版权及免责申明》 如对文章、图片、字体等版权有疑问,请点击 反馈举报
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK