

ModelMesh and KServe bring eXtreme scale standardized model inferencing on Kuber...
source link: https://developer.ibm.com/blogs/kserve-and-watson-modelmesh-extreme-scale-model-inferencing-for-trusted-ai/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Blog Post
ModelMesh and KServe bring eXtreme scale standardized model inferencing on Kubernetes
Learn how ModelMesh intelligently loads and unloads AI models to and from memory to strike a tradeoff between responsiveness to users and the computational footprint
Written by IBM on behalf of ModelMesh and KServe contributors.
One of the most fundamental parts of an AI application is model serving, which is responding to a user request with an inference from an AI model. With machine learning approaches becoming more widely adopted in organizations, there is a trend to deploy a large number of models. For internet-scale AI applications like IBM Watson Assistant and IBM Watson Natural Language Understanding, there isn’t just one AI model, there are literally hundreds or thousands that are running concurrently. Because AI models are computationally expensive, it’s cost prohibitive to load them all at once or to create a dedicated container to serve every trained model. Also, many are rarely used or are effectively abandoned.
When dealing with a large number of models, the ‘one model, one server’ paradigm presents challenges on a Kubernetes cluster to deploy hundreds of thousands of models. To scale the number of models, you must scale the number of InferenceServices, something that can quickly challenge the cluster’s limits:
- Compute Resource limitation (for example, one model per server typically averages to 1 CPU/1 GB overhead per model)
- Maximum pod limitation (for example, Kubernetes recommends at most 100 pods per node)
- Maximum IP address limitation (for example, a cluster with 4096 IP can deploy about 1000 to 4000 models)
Announcing ModelMesh: A core model inference platform in open source
Enter ModelMesh, a model serving management layer for Watson products. Now running successfully in production for several years, ModelMesh underpins most of the Watson cloud services, including Watson Assistant, Watson Natural Language Understanding, and Watson Discovery. It is designed for high-scale, high-density, and frequently changing model use cases. ModelMesh intelligently loads and unloads AI models to and from memory to strike an intelligent trade-off between responsiveness to users and their computational footprint.
We are excited to announce that we are contributing ModelMesh to the open source community. ModelMesh Serving is the controller for managing ModelMesh clusters through Kubernetes custom resources. Below we list some of the core components of ModelMesh.
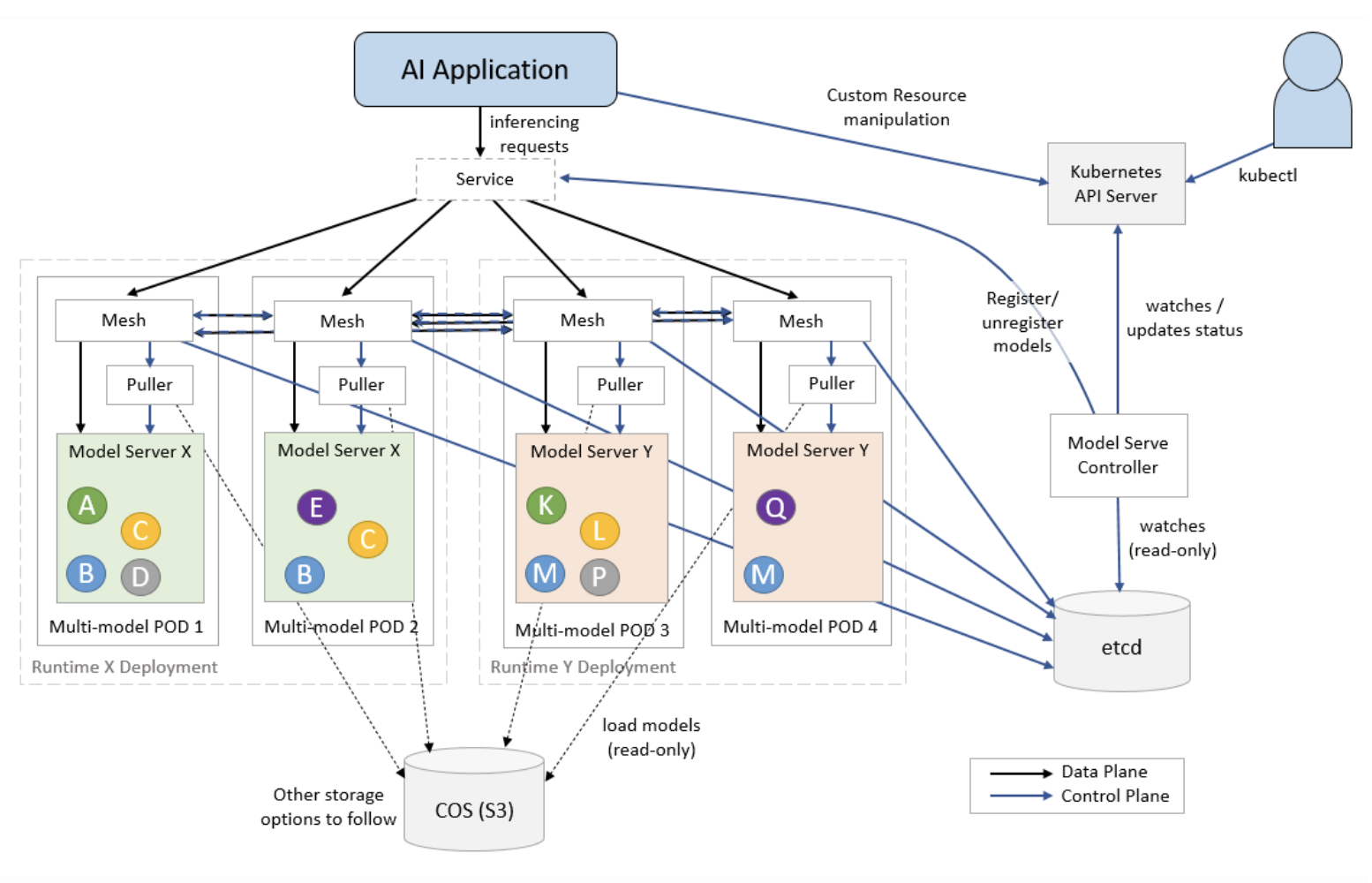
Core components
- ModelMesh Serving: The model serving controller
- ModelMesh: The ModelMesh containers that are used for orchestrating model placement and routing
Runtime adapters
- modelmesh-runtime-adapter: The containers that run in each model-serving pod and act as an intermediary between ModelMesh and third-party model-server containers. It also incorporates the “puller” logic that is responsible for retrieving the models from storage
Model-serving runtimes
ModelMesh Serving provides out-of-the-box integration with the following model servers:
- triton-inference-server: Nvidia’s Triton Inference Server
- seldon-mlserver: Python MLServer that is part of KServe
You can use ServingRuntime custom resources to add support for other existing or custom-built model servers. See the documentation on implementing a custom serving runtime.
ModelMesh features
Cache management and HA
The clusters of multi-model server pods are managed as a distributed LRU cache, with available capacity automatically filled with registered models. ModelMesh decides when and where to load and unload copies of the models based on usage and current request volumes. For example, if a particular model is under heavy load, it will be scaled across more pods.
It also acts as a router, balancing inference requests between all copies of the target model, coordinating just-in-time loads of models that aren’t currently in memory, and retrying/rerouting failed requests.
Intelligent placement and loading
Placement of models into the existing model-server pods is done in such a way to balance both the “cache age” across the pods as well as the request load. Heavily used models are placed on less-utilized pods and vice versa.
Concurrent model loads are constrained/queued to minimize impact to runtime traffic, and priority queues are used to allow urgent requests to jump the line (that is, cache misses where an end-user request is waiting).
Resiliency
Failed model loads are automatically retried in different pods and after longer intervals to facilitate automatic recovery, for example, after a temporary storage outage.
Operational simplicity
ModelMesh deployments can be upgraded as if they were homogeneous – it manages propagation of models to new pods during a rolling update automatically without any external orchestration required and without any impact to inference requests.
There is no central controller involved in model management decisions. The logic is decentralized with lightweight coordination that makes use of etcd.
Stable “v-model” endpoints are used to provide a seamless transition between concrete model versions. ModelMesh ensures that the new model has loaded successfully before switching the pointer to route requests to the new version.
Scalability
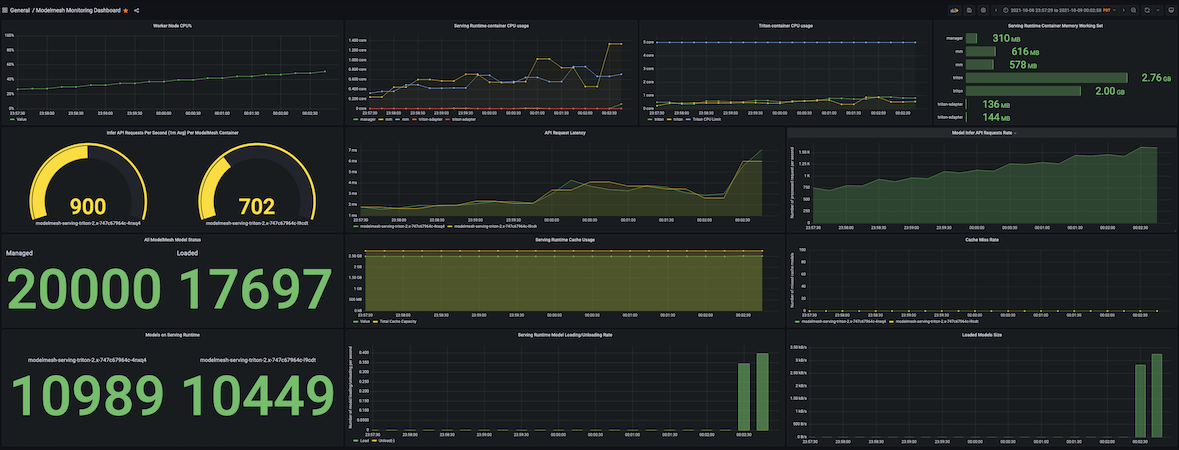
ModelMesh supports hundreds of thousands of models in a single production deployment of 8 pods by over-committing the aggregate available resources and intelligently keeping a most-recently-used set of models loaded across them in a heterogeneous manner. We did some sample tests to determine the density and scalability for ModelMesh on an instance deployed on a single worker node (8vCPU x 64GB) Kubernetes cluster. The tests were able to pack 20K simple-string models into only two serving runtime pods, which were load tested by sending thousands of concurrent inference requests to simulate a high-traffic scenario. All loaded models responded with single-digit millisecond latency.
ModelMesh and KServe: Better together
Developed collaboratively by Google, IBM, Bloomberg, NVIDIA, and Seldon in 2019, KFServing was published as open source in early 2019. Recently, we announced the next chapter for KFServing. The project has also been renamed from KFServing to KServe, and the KFServing GitHub repository has been transferred to an independent KServe GitHub organization under the stewardship of the Kubeflow Serving Working Group leads.
With both ModelMesh and KServe sharing a mission to create highly scalable model inferencing on Kubernetes, it made sense to bring these two projects together. We are excited to announce that ModelMesh will be evolving in the KServe GitHub organization. KServe v0.7 has been released with ModelMesh integrated as the back end for Multi-Model Serving.
“ModelMesh addresses the challenge of deploying hundreds or thousands of machine learning models through an intelligent trade-off between latency and total cost of compute resources. We are very excited about ModelMesh being contributed to the KServe project and look forward to collaboratively developing the unified KServe API for deploying both single model and ModelMesh use cases.”
Dan Sun, KServe co-creator/Senior Software Engineer at Bloomberg
Join us to build a trusted and scalable model inference platform on Kubernetes
Please join us on the ModelMesh and KServe GitHub repositories, try it out, give us feedback, and raise issues. Additionally:
Trust and responsibility should be core principles of AI. The LF AI & Data Trusted AI Committee is a global group that is working on policies, guidelines, tools, and projects to ensure the development of trustworthy AI solutions, and we have integrated LFAI AI Fairness 360, AI Explainability 360, and Adversarial Robustness 360 in KServe to provide trusted AI capabilities.
To contribute and build an enterprise-grade, end-to-end machine learning platform on OpenShift and Kubernetes, please join the Kubeflow community, and reach out with any questions, comments, and feedback.
If you want help deploying and managing Kubeflow on your on-premises Kubernetes platform, OpenShift, or on IBM Cloud, please connect with us.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK